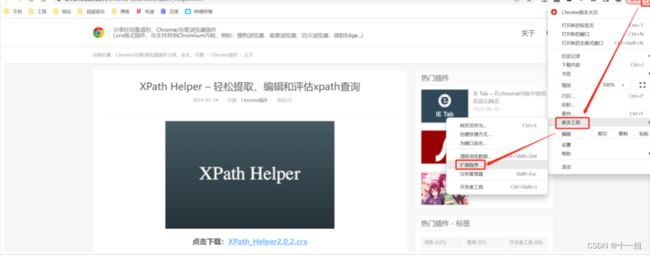
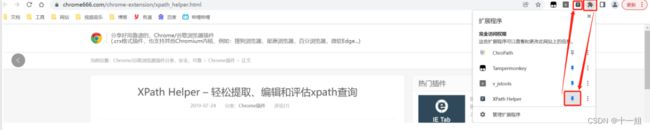
- Long类型前后端数据不一致
igotyback
前端
响应给前端的数据浏览器控制台中response中看到的Long类型的数据是正常的到前端数据不一致前后端数据类型不匹配是一个常见问题,尤其是当后端使用Java的Long类型(64位)与前端JavaScript的Number类型(最大安全整数为2^53-1,即16位)进行数据交互时,很容易出现精度丢失的问题。这是因为JavaScript中的Number类型无法安全地表示超过16位的整数。为了解决这个问
- DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理
STU学生网页设计
网页设计期末网页作业html静态网页html5期末大作业网页设计web大作业
️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程
- 【加密社】Solidity 中的事件机制及其应用
加密社
闲侃区块链智能合约区块链
加密社引言在Solidity合约开发过程中,事件(Events)是一种非常重要的机制。它们不仅能够让开发者记录智能合约的重要状态变更,还能够让外部系统(如前端应用)监听这些状态的变化。本文将详细介绍Solidity中的事件机制以及如何利用不同的手段来触发、监听和获取这些事件。事件存储的地方当我们在Solidity合约中使用emit关键字触发事件时,该事件会被记录在区块链的交易收据中。具体而言,事件
- 关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript
二挡起步
web前端期末大作业javascripthtmlcss旅游风景
⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip
- HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业web设计网页规划与设计htmlcssjavascriptdreamweaver前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
- node.js学习
小猿L
node.jsnode.js学习vim
node.js学习实操及笔记温故node.js,node.js学习实操过程及笔记~node.js学习视频node.js官网node.js中文网实操笔记githubcsdn笔记为什么学node.js可以让别人访问我们编写的网页为后续的框架学习打下基础,三大框架vuereactangular离不开node.jsnode.js是什么官网:node.js是一个开源的、跨平台的运行JavaScript的运行
- springboot+vue项目实战一-创建SpringBoot简单项目
苹果酱0567
面试题汇总与解析springboot后端java中间件开发语言
这段时间抽空给女朋友搭建一个个人博客,想着记录一下建站的过程,就当做笔记吧。虽然复制zjblog只要一个小时就可以搞定一个网站,或者用cms系统,三四个小时就可以做出一个前后台都有的网站,而且想做成啥样也都行。但是就是要从新做,自己做的意义不一样,更何况,俺就是专门干这个的,嘿嘿嘿要做一个网站,而且从零开始,首先呢就是技术选型了,经过一番思量决定选择-SpringBoot做后端,前端使用Vue做一
- JavaScript 中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)
跳房子的前端
前端面试javascript开发语言ecmascript
在JavaScript中,深拷贝(DeepCopy)和浅拷贝(ShallowCopy)是用于复制对象或数组的两种不同方法。了解它们的区别和应用场景对于避免潜在的bugs和高效地处理数据非常重要。以下是对深拷贝和浅拷贝的详细解释,包括它们的概念、用途、优缺点以及实现方式。1.浅拷贝(ShallowCopy)概念定义:浅拷贝是指创建一个新的对象或数组,其中包含了原对象或数组的基本数据类型的值和对引用数
- 博客网站制作教程
2401_85194651
javamaven
首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java
- JavaScript `Map` 和 `WeakMap`详细解释
跳房子的前端
JavaScript原生方法javascript前端开发语言
在JavaScript中,Map和WeakMap都是用于存储键值对的数据结构,但它们有一些关键的不同之处。MapMap是一种可以存储任意类型的键值对的集合。它保持了键值对的插入顺序,并且可以通过键快速查找对应的值。Map提供了一些非常有用的方法和属性来操作这些数据对:set(key,value):将一个键值对添加到Map中。如果键已经存在,则更新其对应的值。get(key):获取指定键的值。如果键
- 最简单将静态网页挂载到服务器上(不用nginx)
全能全知者
服务器nginx运维前端html笔记
最简单将静态网页挂载到服务器上(不用nginx)如果随便弄个静态网页挂在服务器都要用nignx就太麻烦了,所以直接使用Apache来搭建一些简单前端静态网页会相对方便很多检查Web服务器服务状态:sudosystemctlstatushttpd#ApacheWeb服务器如果发现没有安装web服务器:安装Apache:sudoyuminstallhttpd启动Apache:sudosystemctl
- 补充元象二面
Redstone Monstrosity
前端面试
1.请尽可能详细地说明,防抖和节流的区别,应用场景?你的回答中不要写出示例代码。防抖(Debounce)和节流(Throttle)是两种常用的前端性能优化技术,它们的主要区别在于如何处理高频事件的触发。以下是防抖和节流的区别和应用场景的详细说明:防抖和节流的定义防抖:在一段时间内,多次执行变为只执行最后一次。防抖的原理是,当事件被触发后,设置一个延迟定时器。如果在这个延迟时间内事件再次被触发,则重
- 微信小程序开发注意事项
jun778895
微信小程序小程序
微信小程序开发是一个融合了前端开发、用户体验设计、后端服务(可选)以及微信小程序平台特性的综合性项目。这里,我将详细介绍一个典型的小程序开发项目的全过程,包括项目规划、设计、开发、测试及部署上线等各个环节,并尽量使内容达到或超过2000字的要求。一、项目规划1.1项目背景与目标假设我们要开发一个名为“智慧校园助手”的微信小程序,旨在为学生提供一站式校园生活服务,包括课程表查询、图书馆座位预约、食堂
- 切换淘宝最新npm镜像源是
hai40587
npm前端node.js
切换淘宝最新npm镜像源是一个相对简单的过程,但首先需要明确当前淘宝npm镜像源的状态和最新的镜像地址。由于网络环境和服务更新,镜像源的具体地址可能会发生变化,因此,我将基于当前可获取的信息,提供一个通用的切换步骤,并附上最新的镜像地址(截至回答时)。一、了解npm镜像源npm(NodePackageManager)是JavaScript的包管理器,用于安装、更新和管理项目依赖。由于npm官方仓库
- 字节二面
Redstone Monstrosity
前端面试
1.假设你是正在面试前端开发工程师的候选人,面试官让你详细说出你上一段实习过程的收获和感悟。在上一段实习过程中,我获得了宝贵的实践经验和深刻的行业洞察,以下是我的主要收获和感悟:一、专业技能提升框架应用熟练度:通过实际项目,我深入掌握了React、Vue等前端框架的使用,不仅提升了编码效率,还学会了如何根据项目需求选择合适的框架。问题解决能力:在实习期间,我遇到了许多预料之外的技术难题。通过查阅文
- 前端代码上传文件
余生逆风飞翔
前端javascript开发语言
点击上传文件import{ElNotification}from'element-plus'import{API_CONFIG}from'../config/index.js'import{UploadFilled}from'@element-plus/icons-vue'import{reactive}from'vue'import{BASE_URL}from'../config/index'i
- uniapp实现动态标记效果详细步骤【前端开发】
2401_85123349
uni-app
第二个点在于实现将已经被用户标记的内容在下一次获取后刷新它的状态为已标记。这是什么意思呢?比如说上面gif图中的这些人物对象,有一些已被该用户添加为关心,那么当用户下一次进入该页面时,这些已经被添加关心的对象需要以“红心”状态显现出来。这个点的难度还不算大,只需要在每一次获取后端的内容后对标记对象进行状态更新即可。II.动态标记效果实现思路和步骤首先,整体的思路是利用动态类名对不同的元素进行选择。
- 高性能javascript--算法和流程控制
海淀萌狗
-for,while和do-while性能相当-避免使用for-in循环,==除非遍历一个属性量未知的对象==es5:for-in遍历的对象便不局限于数组,还可以遍历对象。原因:for-in每次迭代操作会同时搜索实例或者原型属性,for-in循环的每次迭代都会产生更多开销,因此要比其他循环类型慢,一般速度为其他类型循环的1/7。因此,除非明确需要迭代一个属性数量未知的对象,否则应避免使用for-i
- 360前端星计划-动画可以这么玩
马小蜗
动画的基本原理定时器改变对象的属性根据新的属性重新渲染动画functionupdate(context){//更新属性}constticker=newTicker();ticker.tick(update,context);动画的种类1、JavaScript动画操作DOMCanvas2、CSS动画transitionanimation3、SVG动画SMILJS动画的优缺点优点:灵活度、可控性、性能
- Vue + Express实现一个表单提交
九旬大爷的梦
最近在折腾一个cms系统,用的vue+express,但是就一个表单提交就弄了好久,记录一下。环境:Node10+前端:Vue服务端:Express依赖包:vueexpressaxiosexpress-formidableelement-ui(可选)前言:axiosget请求参数是:paramsaxiospost请求参数是:dataexpressget接受参数是req.queryexpresspo
- JavaScript中秋快乐!
Q_w7742
javascript开发语言ecmascript
我们来实现一个简单的祝福网页~主要的难度在于使用canvas绘图当点击canvas时候,跳出“中秋节快乐”字样,需要注册鼠标单击事件和计时器。首先定义主要函数:初始化当点击canvas之后转到onCanvasClick函数,绘图生成灯笼。functiononCanvasClick(){//事件处理函数context.clearRect(0,0,canvas1.width,canvas1.heigh
- Nginx从入门到实践(三)
听你讲故事啊
动静分离动静分离是将网站静态资源(JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问。动静分离的一种做法是将静态资源部署在nginx上,后台项目部署到应用服务器上,根据一定规则静态资源的请求全部请求nginx服务器,达到动静分离的目标。rewrite规则Rewrite规则常见正则表达式Rewrite主要的功能就是实现URL的重写,Ngin
- Nginx的使用场景:构建高效、可扩展的Web架构
张某布响丸辣
nginx前端架构
Nginx,作为当今最流行的Web服务器和反向代理软件之一,凭借其高性能、稳定性和灵活性,在众多Web项目中扮演着核心角色。无论是个人博客、中小型网站,还是大型企业级应用,Nginx都能提供强大的支持。本文将探讨Nginx的几个主要使用场景,帮助读者理解如何在实际项目中充分利用Nginx的优势。1.静态文件服务对于包含大量静态文件(如HTML、CSS、JavaScript、图片等)的网站,Ngin
- 前端知识点
ZhangTao_zata
前端javascriptcss
下面是一个最基本的html代码body{font-family:Arial,sans-serif;margin:20px;}//JavaScriptfunctionthatdisplaysanalertwhencalledfunctionshowMessage(){alert("Hello!Youclickedthebutton.");}MyFirstHTMLPageWelcometoMyPage
- 第三十一节:Vue路由:前端路由vs后端路由的了解
曹老师
1.认识前端路由和后端路由前端路由相对于后端路由而言的,在理解前端路由之前先对于路由有一个基本的了解路由:简而言之,就是把信息从原地址传输到目的地的活动对于我们来说路由就是:根据不同的url地址展示不同的页面内容1.1后端路由以前咱们接触比较多的后端路由,当改变url地址时,浏览器会向服务器发送请求,服务器根据这个url,返回不同的资源内容后端路由的特点就是前端每次跳转到不同url地址,都会重新访
- 华雁智科前端面试题
因为奋斗超太帅啦
前端笔试面试问题整理javascript开发语言ecmascript
1.var变量的提升题目:vara=1functionfun(){console.log(b)varb=2}fun()console.log(a)正确输出结果:undefined、1答错了,给一个大嘴巴子,错误答案输出结果为:2,1此题主要考察var定义的变量,作用域提升的问题,相当于varaa=1functionfun(){varbconsole.log(b)b=2}fun()console.l
- 如何建设数据中台(五)——数据汇集—打破企业数据孤岛
weixin_47088026
学习记录和总结中台数据中台程序人生经验分享
数据汇集——打破企业数据孤岛要构建企业级数据中台,第一步就是将企业内部各个业务系统的数据实现互通互联,打破数据孤岛,主要通过数据汇聚和交换来实现。企业采集的数据可以是线上采集、线下数据采集、互联网数据采集、内部数据采集等。线上数据采集主要载体分为互联网和移动互联网两种,对应有系统平台、网页、H5、小程序、App等,可以采用前端或后端埋点方式采集数据。线下数据采集主要是通过硬件来采集,例如:WiFi
- 分布式锁和spring事务管理
暴躁的鱼
锁及事务分布式springjava
最近开发一个小程序遇到一个需求需要实现分布式事务管理业务需求用户在使用小程序的过程中可以查看景点,对景点地区或者城市标记是否想去,那么需要统计一个地点被标记的人数,以及记录某个用户对某个地点是否标记为想去,用两个表存储数据,一个地点表记录改地点被标记的次数,一个用户意向表记录某个用户对某个地点是否标记为想去。由于可能有多个用户同时标记一个地点,每个用户在前端点击想去按钮之后,后台接收到请求,从数据
- 前端CSS面试常见题
剑亦未配妥
前端面试前端css面试
边界塌陷盒模型有两种:W3C盒模型和IE盒模型,区别在于宽度是否包含边框定义:同时给兄弟/父子盒模型设置上下边距,理论上边距值是两者之和,实际上不是注意:浮动和定位不会产生边界塌陷;只有块级元素垂直方向才会产生margin合并margin计算方案margin同为正负:取绝对值大的值一正一负:求和父子元素边界塌陷解决父元素可以通过调整padding处理;设置overflowhidden,触发BFC子
- 【JS】前端文件读取FileReader操作总结
程序员-张师傅
前端前端javascript开发语言
前端文件读取FileReader操作总结FileReader是JavaScript中的一个WebAPI,它允许web应用程序异步读取用户计算机上的文件(或原始数据缓冲区)的内容,例如读取文件以获取其内容,并在不将文件发送到服务器的情况下在客户端使用它。这对于处理图片、文本文件等非常有用,尤其是当你想要在用户界面中即时显示文件内容或进行文件预览时。创建FileReader对象首先,你需要创建一个Fi
- 安装数据库首次应用
Array_06
javaoraclesql
可是为什么再一次失败之后就变成直接跳过那个要求
enter full pathname of java.exe的界面
这个java.exe是你的Oracle 11g安装目录中例如:【F:\app\chen\product\11.2.0\dbhome_1\jdk\jre\bin】下的java.exe 。不是你的电脑安装的java jdk下的java.exe!
注意第一次,使用SQL D
- Weblogic Server Console密码修改和遗忘解决方法
bijian1013
Welogic
在工作中一同事将Weblogic的console的密码忘记了,通过网上查询资料解决,实践整理了一下。
一.修改Console密码
打开weblogic控制台,安全领域 --> myrealm -->&n
- IllegalStateException: Cannot forward a response that is already committed
Cwind
javaServlets
对于初学者来说,一个常见的误解是:当调用 forward() 或者 sendRedirect() 时控制流将会自动跳出原函数。标题所示错误通常是基于此误解而引起的。 示例代码:
protected void doPost() {
if (someCondition) {
sendRedirect();
}
forward(); // Thi
- 基于流的装饰设计模式
木zi_鸣
设计模式
当想要对已有类的对象进行功能增强时,可以定义一个类,将已有对象传入,基于已有的功能,并提供加强功能。
自定义的类成为装饰类
模仿BufferedReader,对Reader进行包装,体现装饰设计模式
装饰类通常会通过构造方法接受被装饰的对象,并基于被装饰的对象功能,提供更强的功能。
装饰模式比继承灵活,避免继承臃肿,降低了类与类之间的关系
装饰类因为增强已有对象,具备的功能该
- Linux中的uniq命令
被触发
linux
Linux命令uniq的作用是过滤重复部分显示文件内容,这个命令读取输入文件,并比较相邻的行。在正常情 况下,第二个及以后更多个重复行将被删去,行比较是根据所用字符集的排序序列进行的。该命令加工后的结果写到输出文件中。输入文件和输出文件必须不同。如 果输入文件用“- ”表示,则从标准输入读取。
AD:
uniq [选项] 文件
说明:这个命令读取输入文件,并比较相邻的行。在正常情况下,第二个
- 正则表达式Pattern
肆无忌惮_
Pattern
正则表达式是符合一定规则的表达式,用来专门操作字符串,对字符创进行匹配,切割,替换,获取。
例如,我们需要对QQ号码格式进行检验
规则是长度6~12位 不能0开头 只能是数字,我们可以一位一位进行比较,利用parseLong进行判断,或者是用正则表达式来匹配[1-9][0-9]{4,14} 或者 [1-9]\d{4,14}
&nbs
- Oracle高级查询之OVER (PARTITION BY ..)
知了ing
oraclesql
一、rank()/dense_rank() over(partition by ...order by ...)
现在客户有这样一个需求,查询每个部门工资最高的雇员的信息,相信有一定oracle应用知识的同学都能写出下面的SQL语句:
select e.ename, e.job, e.sal, e.deptno
from scott.emp e,
(se
- Python调试
矮蛋蛋
pythonpdb
原文地址:
http://blog.csdn.net/xuyuefei1988/article/details/19399137
1、下面网上收罗的资料初学者应该够用了,但对比IBM的Python 代码调试技巧:
IBM:包括 pdb 模块、利用 PyDev 和 Eclipse 集成进行调试、PyCharm 以及 Debug 日志进行调试:
http://www.ibm.com/d
- webservice传递自定义对象时函数为空,以及boolean不对应的问题
alleni123
webservice
今天在客户端调用方法
NodeStatus status=iservice.getNodeStatus().
结果NodeStatus的属性都是null。
进行debug之后,发现服务器端返回的确实是有值的对象。
后来发现原来是因为在客户端,NodeStatus的setter全部被我删除了。
本来是因为逻辑上不需要在客户端使用setter, 结果改了之后竟然不能获取带属性值的
- java如何干掉指针,又如何巧妙的通过引用来操作指针————>说的就是java指针
百合不是茶
C语言的强大在于可以直接操作指针的地址,通过改变指针的地址指向来达到更改地址的目的,又是由于c语言的指针过于强大,初学者很难掌握, java的出现解决了c,c++中指针的问题 java将指针封装在底层,开发人员是不能够去操作指针的地址,但是可以通过引用来间接的操作:
定义一个指针p来指向a的地址(&是地址符号):
- Eclipse打不开,提示“An error has occurred.See the log file ***/.log”
bijian1013
eclipse
打开eclipse工作目录的\.metadata\.log文件,发现如下错误:
!ENTRY org.eclipse.osgi 4 0 2012-09-10 09:28:57.139
!MESSAGE Application error
!STACK 1
java.lang.NoClassDefFoundError: org/eclipse/core/resources/IContai
- spring aop实例annotation方法实现
bijian1013
javaspringAOPannotation
在spring aop实例中我们通过配置xml文件来实现AOP,这里学习使用annotation来实现,使用annotation其实就是指明具体的aspect,pointcut和advice。1.申明一个切面(用一个类来实现)在这个切面里,包括了advice和pointcut
AdviceMethods.jav
- [Velocity一]Velocity语法基础入门
bit1129
velocity
用户和开发人员参考文档
http://velocity.apache.org/engine/releases/velocity-1.7/developer-guide.html
注释
1.行级注释##
2.多行注释#* *#
变量定义
使用$开头的字符串是变量定义,例如$var1, $var2,
赋值
使用#set为变量赋值,例
- 【Kafka十一】关于Kafka的副本管理
bit1129
kafka
1. 关于request.required.acks
request.required.acks控制者Producer写请求的什么时候可以确认写成功,默认是0,
0表示即不进行确认即返回。
1表示Leader写成功即返回,此时还没有进行写数据同步到其它Follower Partition中
-1表示根据指定的最少Partition确认后才返回,这个在
Th
- lua统计nginx内部变量数据
ronin47
lua nginx 统计
server {
listen 80;
server_name photo.domain.com;
location /{set $str $uri;
content_by_lua '
local url = ngx.var.uri
local res = ngx.location.capture(
- java-11.二叉树中节点的最大距离
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class MaxLenInBinTree {
/*
a. 1
/ \
2 3
/ \ / \
4 5 6 7
max=4 pass "root"
- Netty源码学习-ReadTimeoutHandler
bylijinnan
javanetty
ReadTimeoutHandler的实现思路:
开启一个定时任务,如果在指定时间内没有接收到消息,则抛出ReadTimeoutException
这个异常的捕获,在开发中,交给跟在ReadTimeoutHandler后面的ChannelHandler,例如
private final ChannelHandler timeoutHandler =
new ReadTim
- jquery验证上传文件样式及大小(好用)
cngolon
文件上传jquery验证
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="jquery1.8/jquery-1.8.0.
- 浏览器兼容【转】
cuishikuan
css浏览器IE
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:CSS里 *{margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设
- Shell特殊变量:Shell $0, $#, $*, $@, $?, $$和命令行参数
daizj
shell$#$?特殊变量
前面已经讲到,变量名只能包含数字、字母和下划线,因为某些包含其他字符的变量有特殊含义,这样的变量被称为特殊变量。例如,$ 表示当前Shell进程的ID,即pid,看下面的代码:
$echo $$
运行结果
29949
特殊变量列表 变量 含义 $0 当前脚本的文件名 $n 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个
- 程序设计KISS 原则-------KEEP IT SIMPLE, STUPID!
dcj3sjt126com
unix
翻到一本书,讲到编程一般原则是kiss:Keep It Simple, Stupid.对这个原则深有体会,其实不仅编程如此,而且系统架构也是如此。
KEEP IT SIMPLE, STUPID! 编写只做一件事情,并且要做好的程序;编写可以在一起工作的程序,编写处理文本流的程序,因为这是通用的接口。这就是UNIX哲学.所有的哲学真 正的浓缩为一个铁一样的定律,高明的工程师的神圣的“KISS 原
- android Activity间List传值
dcj3sjt126com
Activity
第一个Activity:
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import android.app.Activity;import android.content.Intent;import android.os.Bundle;import a
- tomcat 设置java虚拟机内存
eksliang
tomcat 内存设置
转载请出自出处:http://eksliang.iteye.com/blog/2117772
http://eksliang.iteye.com/
常见的内存溢出有以下两种:
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Java heap space
------------
- Android 数据库事务处理
gqdy365
android
使用SQLiteDatabase的beginTransaction()方法可以开启一个事务,程序执行到endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到endTransaction()之前调用了setTransactionSuccessful() 方法设置事务的标志为成功则提交事务,如果没有调用setTransactionSuccessful() 方法则回滚事务。事
- Java 打开浏览器
hw1287789687
打开网址open浏览器open browser打开url打开浏览器
使用java 语言如何打开浏览器呢?
我们先研究下在cmd窗口中,如何打开网址
使用IE 打开
D:\software\bin>cmd /c start iexplore http://hw1287789687.iteye.com/blog/2153709
使用火狐打开
D:\software\bin>cmd /c start firefox http://hw1287789
- ReplaceGoogleCDN:将 Google CDN 替换为国内的 Chrome 插件
justjavac
chromeGooglegoogle apichrome插件
Chrome Web Store 安装地址: https://chrome.google.com/webstore/detail/replace-google-cdn/kpampjmfiopfpkkepbllemkibefkiice
由于众所周知的原因,只需替换一个域名就可以继续使用Google提供的前端公共库了。 同样,通过script标记引用这些资源,让网站访问速度瞬间提速吧
- 进程VS.线程
m635674608
线程
资料来源:
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001397567993007df355a3394da48f0bf14960f0c78753f000 1、Apache最早就是采用多进程模式 2、IIS服务器默认采用多线程模式 3、多进程优缺点 优点:
多进程模式最大
- Linux下安装MemCached
字符串
memcached
前提准备:1. MemCached目前最新版本为:1.4.22,可以从官网下载到。2. MemCached依赖libevent,因此在安装MemCached之前需要先安装libevent。2.1 运行下面命令,查看系统是否已安装libevent。[root@SecurityCheck ~]# rpm -qa|grep libevent libevent-headers-1.4.13-4.el6.n
- java设计模式之--jdk动态代理(实现aop编程)
Supanccy2013
javaDAO设计模式AOP
与静态代理类对照的是动态代理类,动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java 反射机制可以生成任意类型的动态代理类。java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
&
- Spring 4.2新特性-对java8默认方法(default method)定义Bean的支持
wiselyman
spring 4
2.1 默认方法(default method)
java8引入了一个default medthod;
用来扩展已有的接口,在对已有接口的使用不产生任何影响的情况下,添加扩展
使用default关键字
Spring 4.2支持加载在默认方法里声明的bean
2.2
将要被声明成bean的类
public class DemoService {