基于PyTorch构建手写识别
使用PyTorch构建神经网络模型进行手写识别
PyTorch是一种基于Torch库的开源机器学习库,应用于计算机视觉和自然语言处理等应用,本章内容将从安装以及通过Torch构建基础的神经网络,计算梯度为主要内容进行学习。
How can we install Torch?
Torch在Linux,Windows,Mac等开发环境下都有特定的安装方法,首先搜索官方网页https://pytorch.org/,由下图所示我们可以根据自己适合的环境进行选择,我使用的是1.9.0版本Windows环境下conda包Python语言,CPU计算平台的安装。
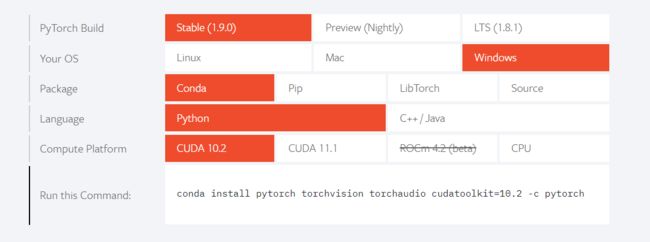
安装过程需要打开Anaconda命令行输入下方所给提示命令指引,
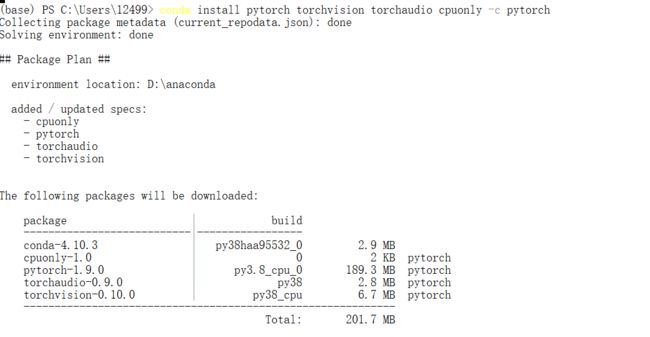
安装好Torch后打开常用的编辑器进行测试
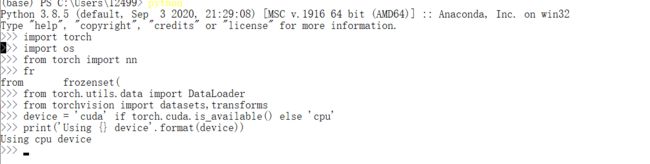
OK,我们可以看到已经成功的在电脑上安装了Torch
下列代码均在Jupyter NoteBook编辑,conda等安装方式不在此文章说明
在“PYTORCH”中定义神经网络
深度学习算法即为神经网络算法,它是由多层互连计算单元组成的计算系统。通过这些相互连接的单元传递数据,神经网络能够学习如何近似将输入转换位输出所需的计算。在Torch中可以使用torch.nn包构建神经网络。
最常听说的也是最基础的MNIST数据集也就是手写识别数据,定义用于MNIST数据集的神经网络需要如下步骤
1.导入库
2.定义初始化神经网络
3.指定数据集构建模型
4.通过模型传递数据进行测试
将从应用角度出发,下述内容神经网络名词定义不做过多叙述。
导入相关库加载数据
构建神经网络所需库为torch.nn以及torch.nn.functional
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
通过上述模块和类,torch.nn帮助我们创建和训练神经网络,包含forward(input),返回output。
定义,初始化神经网络
我们定义的神经网络将帮助我们识别图像,将使用PyTorch内置的卷积。卷积过程将图像的每个元素添加到local neighbors,由内核或小型矩阵权重配比,将有助于我们从输入图像中提取某些特征(边缘检测,锐度,模糊度等)。
定义Net模型的类有两个要求。第一个是编写一个__init__引用nn.Moudle。这个函数是你在你神经网络中定义全连接层的地方。
使用卷积,我们从构建的神经网络模型输出一个图像通道,输出匹配数字从0到9的10个标签的目标,下列构建传统的MNIST算法
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# First 2D convolutional layer, taking in 1 input channel (image),
# outputting 32 convolutional features, with a square kernel size of 3
self.conv1 = nn.Conv2d(1, 32, 3, 1)
# Second 2D convolutional layer, taking in the 32 input layers,
# outputting 64 convolutional features, with a square kernel size of 3
self.conv2 = nn.Conv2d(32, 64, 3, 1)
# Designed to ensure that adjacent pixels are either all 0s or all active
# with an input probability
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
# First fully connected layer
self.fc1 = nn.Linear(9216, 128)
# Second fully connected layer that outputs our 10 labels
self.fc2 = nn.Linear(128, 10)
my_nn = Net()
print(my_nn)
如代码所示,构建的三层神经网络,第一个二维接收层,输入图像数据,输出32个特征,平方核大小为3,第二个二维convolutional 层输入32组数据得到64个特征平方核大小为3
通过指定数据传递进行训练
我们已经完成了神经网络的定义,下面将使用数据进行训练,在使用PyTorch构建模型只需要定义foward函数,将数据传递到计算图中,将代表我们的前馈算法。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
# x represents our data
def forward(self, x):
# Pass data through conv1
x = self.conv1(x)
# Use the rectified-linear activation function over x
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
# Run max pooling over x
x = F.max_pool2d(x, 2)
# Pass data through dropout1
x = self.dropout1(x)
# Flatten x with start_dim=1
x = torch.flatten(x, 1)
# Pass data through fc1
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
# Apply softmax to x
output = F.log_softmax(x, dim=1)
return output
通过模型传递数据进行测试
完成了手写识别的训练,最后的步骤将测试我们的模型
推荐阅读
- 微分算子法
- 使用PyTorch构建神经网络模型进行手写识别
- 使用PyTorch构建神经网络模型以及反向传播计算
- 如何优化模型参数,集成模型
- TORCHVISION目标检测微调教程
