Hadoop集群---方便的脚本
目录
为什么编写脚本?
myhadoop.sh 群起集群、关闭集群脚本
1、配置
2、启用
jpsall 查看三台主机进程脚本
1、配置
2、启用
xsync 分发脚本
1、配置
2、启用
-
为什么编写脚本?
方便
-
myhadoop.sh 群起集群、关闭集群脚本
1、配置
在 root/bin 目录下创建脚本 (在这个目录下方便全局使用)
vim myhadoop.sh
把以下代码粘贴进去,一定要修改主机名,按照自己的需求修改,比如我的NameNode在第二台主机上启动,那启动hdfs时主机名就填第二台主机
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop02 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop01 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop01 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop01 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop01 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop02 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
2、启用

脚本保存退出后并不是绿色的可执行文件,要给脚本加上执行权限
chmod +x /root/bin/myhadoop.sh变成绿色后就可以执行了:
myhadoop.sh start #启动集群
myhadoop.sh stop #关闭集群
-
jpsall 查看三台主机进程脚本
想查看每台主机上的进程,不用再来回切换,jpsall可以同时列出三台主机进程
1、配置
在 root/bin 目录下创建脚本 (在这个目录下方便全局使用)
vim jpsall粘贴以下代码:
#!/bin/bash
for host in hadoop01 hadoop02 hadoop03
do
echo =============== $host ===============
ssh $host jps
done
2、启用
脚本保存退出后并不是绿色的可执行文件,要给脚本加上执行权限
chmod +x jpsall
#在jpsall的上级目录执行如果报错:jps找不到命令....
可能缺少依赖,三台主机执行命令:
sudo yum install java-1.8.0-openjdk-devel.x86_64如果还是报错可能是java版本低或者软连接问题,可自行搜索解决。
完成后可试验一下jpsall能展示出Hadoop集群的结点:
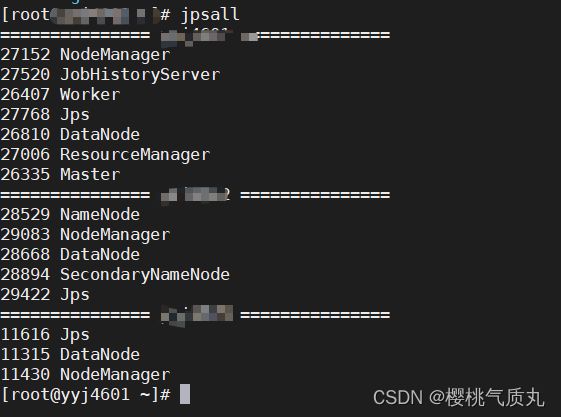
-
xsync 分发脚本
1、配置
在 root/bin 目录下创建脚本 (在这个目录下方便全局使用)
vim xsync
粘贴以下代码:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host hadoop01 hadoop02 hadoop03
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
2、启用
脚本保存退出后并不是绿色的可执行文件,要给脚本加上执行权限
chmod +x xsync
#在xsync的上级目录执行执行命令:
#比如要分发 /opt/module/abc.txt
xsync /opt/module/abc.txt如果报错:bash:rsync找不到命令
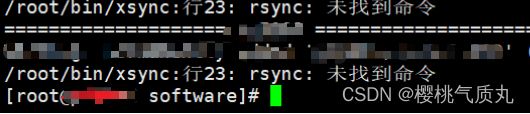
在三台主机上安装rsync:
yum -y install rsyncover!!!!