Box-level Segmentation Supervised Deep Neural Networks for Accurate and Real-time Multispectral Pede
Box-level Segmentation Supervised Deep Neural Networks for Accurate and Real-time Multispectral Pedestrian Detection
Zhejiang University 11 ISPRS Journal of Photogrammetry and Remote Sensing(一区,top) 2019/04/01
贡献:将anchor-free方法和利用bounding box做分割引入多光谱行人检测领域,并有着较好的表现。由于最后是预测热图,所以对于小目标有着较好的检测效果。投到这个期刊上,感觉也是个不错的选择。
views:融合策略是后融合,方式是concatenate,整个网络结构十分简单,新的网络结构其实和baseline一样,就是加了个多尺度。主要work的原因还是在于anchor-free和box-level segmentation,这个想法的确挺有意义,可以理解为粗糙的语义分割技术。
ideas:显著性图,bounding box segmentation之间是否也存在某种联系。
Abstract
通过多模态传感器(visible and infrared cameras)捕获的互补信息的有效融合,可在各种监控情况下(daytime and nighttime)对行人进行可靠检测。提出一种结合可见光和红外特征的高精度和实时的多光谱行人检测的box-level segmentation supervised learning framework。具体,将容易获得bbox的成对(对齐)的可见光和红外图像作为深入,并估计准确的预测图以突出显示行人的存在。对比anchor box based methods,第一,不需要anchor box的超参,对小目标和拥挤目标有更好的处理效果。其次,使用小尺寸的输入图生成准确的检测结果,提高实时的自动驾驶应用效率。在KASIT上达到SOTA。

图一 (d)即使输入很小,依然可以产生准确的检测结果。
1.Introduction
多光谱VS纯视觉
大多数现有多光谱行人检测方法都建立于anchor box based detectors,eg:region proposal networks(RPN)or Faster R-CNN。大量anchor box,导致FP较高,在正负anchor box间存在在严重的不平衡,减慢训练过程。小尺寸图像表现很差,因为很难生成positive anchor box。
为了克服上述问题, 提出一种新颖的 box-level segmentation supervised learning framework
图1展示了效果,本文方法产生更准确的检测结果,即使是小尺寸图像,也可以成功定位远距离的人类目标。提出方法在Titan X GPU上达到实时,1s处理30多帧图。
贡献:
1>box-level segmentation supervised framework消除了现有基于anchor box探测器所需的复杂超参数设置(eg,box size,aspect ratio,stride,and interesection-over-union thershold)。首次在多光谱行人检测中尝试不使用anchor box。(不就是anchor-free方法的嫁接嘛,这脸皮有点厚,hhh。)
2>相比anchor based boxes,box-level segmentation masks提供更好的监督信息训练two-stream神经网络来区分行人和背景,尤其是small human target。即使小尺寸的输入图,仍有准确检测结果。
3>相比SOTA,我们方法有更高的检测精度。此外,在Titan X上每秒处理30张图以上,达到实时。
2.Related Works
Guan et al. [15] presented a unified multispectral fusion framework for joint training of semantic
segmentation and target detection.(关注下数据集)
首先,利用groud Truth bbox生成粗糙的框级分割模板,用于替换anchor bounding boxes,以训练two-stream deep neural networks学习人类的相关识别特征。第二,估计一个prediction heat map而不是用多个边界框定位行人。大量的语义分割技术,在不适用anchor box的情况下在foreground和background之间生成准确的边界。但是这些方法需要pixel-level的精确mask,标注很费时。许多研究尝试仅使用容易获得的bbox annotation来实现有竞争力精度的语义分割[6,45](有点兴趣)。这些方法迭代更新,实现高精度的语义分割,但是进展很慢 且不适用于autonomous driving applications(Wow,通过bbox做分割这个想法好)。
3.Our Approach
给定成对的visible and infrared images,使用two-steam deep networks提取 individual channel(单独通道)中的语义特征。Visible和infrared feature map通过concatenate进行融合,然后被用于估计heat maps去预测行人存在,如图2所示。注意,与人类目标相关的图像区域会有着较高的置信度得分(大于0.5)。(预测结果是heat map,通过设置阈值找到人类区别,可理解为粗糙的语义分割技术)
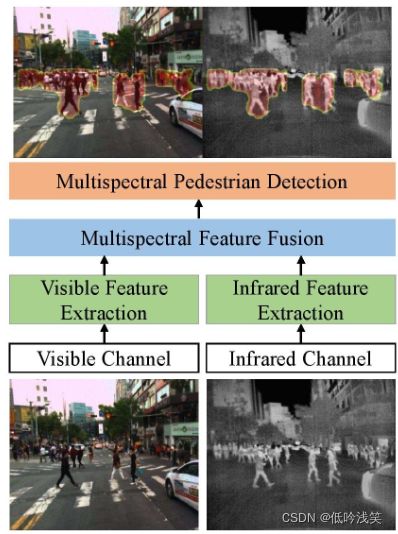
Fig.2. 提出用于多光谱行人检测的box-level segmentation supervised神经网络。注意,方法生成预测热图(0.5 score threshold 用于显示检测的行人区域)而不是标记行人位置的bbox。

图3 绿色:conv,黄色:pooling,蓝色:fusion layer,灰色:deconvolutional layer,橙色:softmax layer
3.1 Network Architecture
Fig.3(a)展示了提出用于行人检测的多光谱特征融合网络(MFFN)的baseline[25](后融合,融合方式很concatenate,粗糙)。每个feature extraction stream由五个卷积层和池化层组成(VGG-16去除FC部分)。使用concatenate融合两个独立特征图,后接1x1 conv(Conv-Mul)来学习two-channel多光谱行人特征。使用softmax layer估计热图(Det-Mul),以预测行人的位置。
受top-down结构启发,它具有用于目标检测和分割的横向连接(lateral connection),我们设计另一种分层的多光谱特征融合网络(HMFFN),如图(b)所示。部署反卷积层(Deconv5-V/I)将high-level feature map的spatial resolution提高2倍。上采样特征图与中级特征图(经过1x1conv Conv4x-V/I减少channel dimension,?怎么是减少呢)通过element-wsie addition合并。深层输出high-level semantic information,浅层输出丰富的spatial pattern。因此,HMFFN结合不同级别的特征图,获得了更准确的检测结果。
3.2 Box-level segmentation for Supervised Training

图4 使用anchor box(a)生成training label;(b)box-level segmentation masks。
Anchor based method生成大量具有各种尺寸和纵横比的anchor box(涉及复杂超参)作为潜在的候选框。将容易获得的annotation作为input,生成box-level segmentation mask学习行人的相关特征。在实现中,通过双线性插值将box-level segmentation masks按比例缩小,与final feature map(concatenate layer的输出)大小匹配。获得可见光和红外图像对的像素级注释是一项艰难的任务,因为完美同步的多光谱数据很难得。因此,利用容易获得的box annotation替代进行学习。
Let (X,Y)表示training image X={xi,i=1 M}(M pixels) with box-level approximate segmentation masks Y={yi,i=1 M},其中yi=1为前景像素,yi=0为背景像素。θ通过最小化cross-entropy loss,定义为:
ℒ=−∈+logPr=1∣;−∈−logPr=0∣; (1)![]()
其中,Y+和Y-分别表示前foreground和background pixel,Pr∣;表示是行人区域的confidence score,利用softmax function计算为![]()
Pr=1∣;=10+1Pr=0∣;=00+1 (2)(3)![]()
其中,s0和s1是two-channel feature map中的计算值。
Proposed method输出是一个预测热图,其中人类目标区域产生较高的置信度(大于0.5),而背景区域产生较低的置信度。这种感知信息对于许多自动驾驶应用很有用,如路径规划或避免碰撞。相比之下,使用大量bbox来识别拥挤城市场景中的单个行人是困难的。
5.Conclusion
首次尝试不使用锚框训练多光谱检测器,box-level segmentation masks可提供有用信息区分人和背景。此外,设计了一种分层的多光谱融合方案,其中结合了middle-level feature map(small-scale image characteristics)和高级特征图(semantic information)以实现更准确的检测结果,尤其是远距离行人。实时处理。提出的方法可推广到具有多光谱输入的其他检测任务中。