大数据-玩转数据-MaxCompute SQL
一、说明
本文为您介绍MaxCompute SQL常见使用场景,让您快速掌握SQL的写法。
二、准备数据集
本文以emp表和dept表为示例数据集。您可以自行在MaxCompute项目上创建表并上传数据。数据导入请参见概述。
下载emp表数据文件和dept表数据文件。
创建emp表。
CREATE TABLE IF NOT EXISTS emp (
EMPNO STRING,
ENAME STRING,
JOB STRING,
MGR BIGINT,
HIREDATE DATETIME,
SAL DOUBLE,
COMM DOUBLE,
DEPTNO BIGINT);
创建dept表。
CREATE TABLE IF NOT EXISTS dept (
DEPTNO BIGINT,
DNAME STRING,
LOC STRING);
三、SQL示例
示例1:查询员工人数大于零的所有部门。
为了避免数据量太大,此场景下建议您使用JOIN子句。
SELECT d.*
FROM dept d
JOIN (
SELECT DISTINCT deptno AS no
FROM emp
) e
ON d.deptno = e.no;
示例2: 查询薪金比SMITH高的所有员工。
此场景为MAPJOIN的典型场景。
SELECT /*+ MapJoin(a) */ e.empno
, e.ename
, e.sal
FROM emp e
JOIN (
SELECT MAX(sal) AS sal
FROM `emp`
WHERE `ENAME` = 'SMITH'
) a
ON e.sal > a.sal;
MAPJION会把小表全部加载到内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在map端是进行了join操作,省去了reduce运行的时间,算是一种优化
前提b表是一张小表,默认25m的表是小表
注意事项
使用mapjoin时,一次性加载到内存中的表最多是8张,如果超过8张小表,应该嵌套一层子循环,将多余的表在外层中写入mapjion里面,代码实现如下:
select /*+ mapjoin(b1,b2)*/
b.*
from
(select /*+ mapjoin(a1,a2,a3,a4,a5,a6,a7,a8)*/
a.*
from a
join a1 on a.id1=a1.id1
join a2 on a.id2=a2.id2
join a3 on a.id3=a3.id3
join a4 on a.id4=a4.id4
join a5 on a.id5=a5.id5
join a6 on a.id6=a6.id6
join a7 on a.id7=a7.id7
join a8 on a.id8=a8.id8) b
join b1 on b.id11=b1.id11
join b2 on b.id11=b2.id12
示例3: 查询所有员工的姓名及其直接上级的姓名。
此场景为等值连接。
SELECT a.ename
, b.ename
FROM emp a
LEFT OUTER JOIN emp b
ON b.empno = a.mgr;
示例4:查询基本薪金大于1500的所有工作。
此场景下需要使用HAVING子句。
SELECT emp.`JOB`
, MIN(emp.sal) AS sal
FROM `emp`
GROUP BY emp.`JOB`
HAVING MIN(emp.sal) > 1500;
示例5: 查询在每个部门工作的员工数量、平均工资和平均服务期限。
此场景为使用内建函数的典型场景。
SELECT COUNT(empno) AS cnt_emp
, ROUND(AVG(sal), 2) AS avg_sal
, ROUND(AVG(datediff(getdate(), hiredate, 'dd')), 2) AS avg_hire
FROM `emp`
GROUP BY `DEPTNO`;
示例6: 查询每个部门的薪水前3名的人员的姓名以及其排序。
此场景为典型的Top N场景。
SELECT *
FROM (
SELECT deptno
, ename
, sal
, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS nums
FROM emp
) emp1
WHERE emp1.nums < 4;
**示例7:**查询每个部门的人数以及该部门中办事员(CLERK)人数的占比。
SELECT deptno
, COUNT(empno) AS cnt
, ROUND(SUM(CASE
WHEN job = 'CLERK' THEN 1
ELSE 0
END) / COUNT(empno), 2) AS rate
FROM `EMP`
GROUP BY deptno;
四、注意事项
- 使用GROUP BY时,SELECT部分必须是分组项或聚合函数。
- ORDER BY后面必须加LIMIT N。
- SELECT表达式中不能用子查询,可以改写为JOIN。
- JOIN不支持笛卡尔积,可以使用MAPJOIN替代。
- UNION All需要改成子查询的格式。
- IN/NOT IN语句对应的子查询只能有一列,而且返回的行数不能超过1000,否则也需要改成JOIN操作执行。
五、与标准SQL的主要区别及解决方法
MaxCompute SQL与标准SQL的基本区别


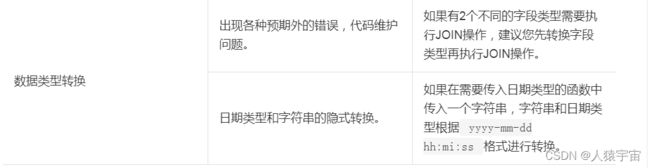
DDL与DML的区别及解决方法
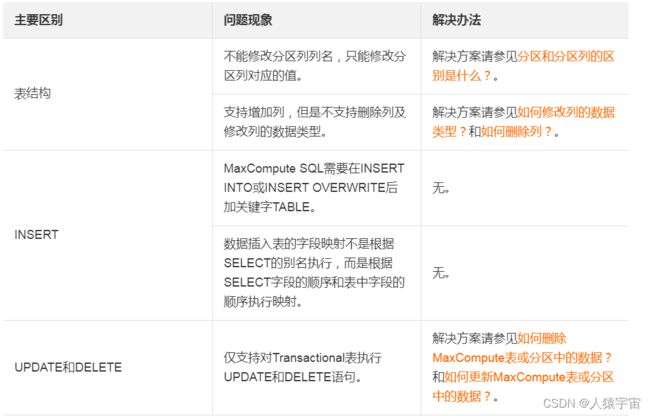


六、不兼容SQL重写
背景信息
MaxCompute 2.0完全拥抱开源生态,支持更多的语言功能,拥有更快的运行速度。但是MaxCompute 2.0会执行更严格的语法检测,一些在旧版本编译器下正常执行的不严谨的语法在MaxCompute 2.0下执行会报错。
group.by.with.star
说明:即select * …group by…语句。
MaxCompute 2.0版本中,要求Group By列表是源表中所有的列,否则执行报错。
旧版MaxCompute中,即使Group By列表不覆盖源表中所有的列,也支持select * from group by key语法。
示例
场景1:Group By Key中不包含所有列。
错误写法
select * from t group by key;
报错信息
FAILED: ODPS-0130071:[1,8] Semantic analysis exception - column reference t.value should appear in GROUP BY key
正确写法
select distinct key from t;
场景2:group by key包含所有列。
如下写法不推荐。
select * from t group by key, value; -- t has columns key and value
虽然MaxCompute2.0不会报错,但推荐改为如下。
select distinct key, value from t;
bad.escape
说明:错误的escape序列问题。
按照MaxCompute规定,在String literal中应该用反斜线加三位8进制数字表示从0到127的ASCII字符。例如:使用“\001”、“\002”表示0、1。但\01、\0001也被当作\001处理了。
这种方式会给新用户带来困扰,比如需要用“\0001”表示“\000”+“1”,便没有办法实现。同时对于从其他系统迁移而来的用户而言,会导致正确性错误。
说明 \000后面再加数字,如\0001 - \0009或\00001的写法可能会返回错误。
MaxCompute 2.0会解决此问题,对脚本中错误的序列进行修改。
错误写法
select split(key, "\01"), value like "\0001" from t;
报错信息
FAILED: ODPS-0130161:[1,19] Parse exception - unexpected escape sequence: 01
ODPS-0130161:[1,38] Parse exception - unexpected escape sequence: 0001
正确改法
select split(key, "\001"), value like "\001" from t;
column.repeated.in.creation
说明:如果创建表时列名重复,MaxCompute 2.0将会报错。
示例
错误写法
create table t (a BIGINT, b BIGINT, a BIGINT);
报错信息
FAILED: ODPS-0130071:[1,37] Semantic analysis exception - column repeated in creation: a
正确写法
create table t (a BIGINT, b BIGINT);
string.join.double
说明:写JOIN条件时,等号的左右两边分别是STRING和DOUBLE类型。
旧版MaxCompute会把两边都转成BIGINT类型,会导致严重的精度损失问题,例如:1.1=“1”在连接条件中会被认为是相等的。
MaxCompute 2.0会与Hive兼容转为DOUBLE类型。
示例
不推荐写法
select * from t1 join t2 on t1.double_value = t2.string_value;
Warning信息
WARNING:[1,48] implicit conversion from STRING to DOUBLE, potential data loss, use CAST function to suppress
推荐改法
select * from t1 join t2 on t.double_value = cast(t2.string_value as double);
window.ref.prev.window.alias
说明:Window Function引用同级select List中的其他Window Function Alias的问题。
示例
如果rn在t1中不存在,错误写法如下。
select row_number() over (partition by c1 order by c1) rn,
row_number() over (partition by c1 order by rn) rn2
from t1;
报错信息
FAILED: ODPS-0130071:[2,45] Semantic analysis exception - column rn cannot be resolved
正确改法
select row_number() over (partition by c1 order by rn) rn2
from
(select c1, row_number() over (partition by c1 order by c1) rn
from t1
) tmp;
select.invalid.token.after.star
说明:select列表里面允许用户使用星号(*)代表选择某张表的全部列,但星号(*)后面不允许加alias,即使星号(*)展开之后只有一列也不允许,新一代编译器将会对类似语法进行报错。
示例
错误写法
select * as alias from table_test;
报错信息
FAILED: ODPS-0130161:[1,10] Parse exception - invalid token 'as'
正确改法
select * from table_test;
agg.having.ref.prev.agg.alias
说明:有Having子句的情况下,select List可以出现前面Aggregate Function Alias的问题。
示例
错误写法
select count(c1) cnt,
sum(c1) / cnt avg
from t1
group by c2
having cnt > 1;
报错信息
FAILED: ODPS-0130071:[2,11] Semantic analysis exception - column cnt cannot be resolved
ODPS-0130071:[2,11] Semantic analysis exception - column reference cnt should appear in GROUP BY key
其中s、cnt在源表t1中都不存在,但因为有Having子句,旧版MaxCompute并未报错,MaxCompute 2.0则会提示column cannot be resolve,并报错。
正确改法
select cnt, s, s/cnt avg
from
(
select count(c1) cnt,
sum(c1) s
from t1
group by c2
having count(c1) > 1
) tmp;
order.by.no.limit
说明:MaxCompute默认order by后需要增加limit限制数量,因为order by是全量排序,没有limit时执行性能较低。
示例
错误写法
select * from (select *
from (select cast(login_user_cnt as int) as uv, '3' as shuzi
from test_login_cnt where type = 'device' and type_name = 'mobile') v
order by v.uv desc) v
order by v.shuzi limit 20;
报错信息
FAILED: ODPS-0130071:[4,1] Semantic analysis exception - ORDER BY must be used with a LIMIT clause
在子查询order by v.uv desc中增加limit。
另外,MaxCompute 1.0对于view的检查不够严格。比如在一个不需要检查limit的Project(odps.sql.validate.orderby.limit=false)中,创建了一个View。
create view table_view as select id from table_view order by id;
若访问此View:
select * from table_view;
MaxCompute 1.0不会报错,而MaxCompute 2.0会报如下错误信息:
FAILED: ODPS-0130071:[1,15] Semantic analysis exception - while resolving view xdj.xdj_view_limit - ORDER BY must be used with a LIMIT clause
generated.column.name.multi.window
说明:使用自动生成的alias的问题。
旧版MaxCompute会为select语句中的每个表达式自动生成一个alias,这个alias会最后显示在Console上。但是,它并不承诺这个alias的生成规则,也不承诺这个alias的生成规则会保持不变,所以不建议用户使用自动生成的alias。
MaxCompute 2.0会对使用自动生成alias的情况给予警告,由于牵涉面较广,暂时无法直接给予禁止。
对于某些情况,MaxCompute的不同版本间生成的alias规则存在已知的变动,但因为已有一些线上作业依赖于此类alias,这些查询在 MaxCompute版本升级或者回滚时可能会失败,存在此问题的用户,请修改您的查询,对于感兴趣的列,显式地指定列的别名。
示例
不推荐写法
select _c0 from (select count(*) from table_name) t;
建议改法:
select c from (select count(*) c from table_name) t;
non.boolean.filter
使用了非BOOLEAN过滤条件的问题。
MaxCompute不允许布尔类型与其他类型之间的隐式转换,但旧版MaxCompute会允许用户在某些情况下使用BIGINT作为过滤条件。MaxCompute 2.0将不再允许,如果您的脚本中存在这样的过滤条件,请及时修改。示例如下:
错误写法:
select id, count(*) from table_name group by id having id;
报错信息:
FAILED: ODPS-0130071:[1,50] Semantic analysis exception - expect a BOOLEAN expression
正确改法:
select id, count(*) from table_name group by id having id <> 0;
post.select.ambiguous
在order by、cluster by、distribute by、sort by等语句中,引用了名字冲突的列的问题。
旧版MaxCompute中,系统会默认选取Select列表中的后一列作为操作对象,MaxCompute 2.0将会进行报错,请及时修改。示例如下:
错误写法:
select a, b as a from t order by a limit 10;
报错信息:
FAILED: ODPS-0130071:[1,34] Semantic analysis exception - a is ambiguous, can be both t.a or null.a
正确改法:
select a as c, b as a from t order by a limit 10;
本次推送修改会包括名字冲突但语义一样的情况,虽然不会出现歧义,但是考虑到这种情况容易导致错误,作为一个警告,希望用户进行修改。
duplicated.partition.column
在query中指定了同名的partition的问题。
旧版MaxCompute在用户指定同名partition key时并未报错,而是后一个的值直接覆盖了前一个,容易产生混乱。MaxCompute2.0将会对此情况进行报错,示例如下:
错误写法一:
insert overwrite table partition (ds = '1', ds = '2')select ... ;
实际上,在运行时ds = ‘1’被忽略。
正确改法:
insert overwrite table partition (ds = '2')select ... ;
错误写法二:
create table t (a bigint, ds string) partitioned by (ds string);
正确改法:
create table t (a bigint) partitioned by (ds string);
order.by.col.ambiguous
select list中alias重复,之后的order by子句引用到重复的alias的问题。
错误写法:
select id, id
from table_test
order by id;
正确改法:
select id, id id2
from table_name
order by id;
需要去掉重复的alias,order by子句再进行引用。
in.subquery.without.result
colx in subquery没有返回任何结果,则colx在源表中不存在的问题。
错误写法:
select * from table_name
where not_exist_col in (select id from table_name limit 0);
报错信息:
FAILED: ODPS-0130071:[2,7] Semantic analysis exception - column not_exist_col cannot be resolved
ctas.if.not.exists
目标表语法错误问题。
如果目标表已经存在,旧版MaxCompute不会做任何语法检查,MaxCompute 2.0则会做正常的语法检查,这种情况会出现很多错误信息,示例如下:
错误写法:
create table if not exists table_name
as
select * from not_exist_table;
报错信息:
FAILED: ODPS-0130131:[1,50] Table not found - table meta_dev.not_exist_table cannot be resolved
worker.restart.instance.timeout
旧版MaxCompute UDF每输出一条记录,便会触发一次对分布式文件系统的写操作,同时会向Fuxi发送心跳,如果UDF 10分钟没有输出任何结果,会得到如下错误提示:
FAILED: ODPS-0123144: Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance.
MaxCompute 2.0的Runtime框架支持向量化,一次会处理某一列的多行来提升执行效率。但向量化可能导致原来不会报错的语句(2条记录的输出时间间隔不超过10分钟),因为一次处理多行,没有及时向Fuxi发送心跳而导致超时。
遇到这个错误,建议首先检查UDF是否有性能问题,每条记录需要数秒的处理时间。如果无法优化UDF性能,可以尝试手动设置batch row大小来绕开(默认为1024):
set odps.sql.executionengine.batch.rowcount=16;
divide.nan.or.overflow
旧版MaxCompute不会做除法常量折叠的问题。
比如如下语句,旧版MaxCompute对应的物理执行计划如下:
explain
select if(false, 0/0, 1.0)
from table_name;
in task M1_Stg1:
Data source: meta_dev.table_name
TS: alias: table_name
SEL: If(False, Divide(UDFToDouble(0), UDFToDouble(0)), 1.0)
FS: output: None
由此可以看出,IF和Divide函数仍然被保留,运行时因为IF第一个参数为false,第二个参数Divide的表达式不需要求值,所以不会出现除零异常。
而MaxCompute 2.0支持除法常量折叠,所以会报错。如下所示:
错误写法:
select IF(FALSE, 0/0, 1.0)
from table_name;
报错信息:
FAILED: ODPS-0130071:[1,19] Semantic analysis exception - encounter runtime exception while evaluating function /, detailed message: DIVIDE func result NaN, two params are 0.000000 and 0.000000
除了上述的错误,还可能遇到overflow错误,比如:
错误写法:
select if(false, 1/0, 1.0)
from table_name;
报错信息:
FAILED: ODPS-0130071:[1,19] Semantic analysis exception - encounter runtime exception while evaluating function /, detailed message: DIVIDE func result overflow, two params are 1.000000 and 0.000000
正确改法:
建议去掉/0的用法,换成合法常量。
CASE WHEN常量折叠也有类似问题,比如:CASE WHEN TRUE THEN 0 ELSE 0/0,MaxCompute 2.0常量折叠时所有子表达式都会求值,导致除0错误。
CASE WHEN可能涉及更复杂的优化场景,比如:
select case when key = 0 then 0 else 1/key end
from (
select 0 as key from src
union all
select key from src) r;
优化器会将除法下推到子查询中,转换类似于:
M (
select case when 0 = 0 then 0 else 1/0 end c1 from src
UNION ALL
select case when key = 0 then 0 else 1/key end c1 from src) r;
报错信息:
FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: java.lang.ArithmeticException: DIVIDE func result overflow, two params are 1.000000 and 0.000000
其中UNION ALL第一个子句常量折叠报错,建议将SQL中的 CASE WHEN挪到子查询中,并去掉无用的CASE WHEN和去掉/0用法:
select c1 end
from (
select 0 c1 end from src
union all
select case when key = 0 then 0 else 1/key end) r;
small.table.exceeds.mem.limit
旧版MaxCompute支持Multi-way Join优化,多个Join如果有相同Join Key,会合并到一个Fuxi Task中执行,比如下面例子中的J4_1_2_3_Stg1:
explain
select t1.*
from t1 join t2 on t1.c1 = t2.c1
join t3 on t1.c1 = t3.c1;
旧版MaxCompute物理执行计划:
In Job job0:
root Tasks: M1_Stg1, M2_Stg1, M3_Stg1
J4_1_2_3_Stg1 depends on: M1_Stg1, M2_Stg1, M3_Stg1
In Task M1_Stg1:
Data source: meta_dev.t1
In Task M2_Stg1:
Data source: meta_dev.t2
In Task M3_Stg1:
Data source: meta_dev.t3
In Task J4_1_2_3_Stg1:
JOIN: t1 INNER JOIN unknown INNER JOIN unknown
SEL: t1._col0, t1._col1, t1._col2
FS: output: None
如果增加MapJoin hint,旧版MaxCompute物理执行计划不会改变。也就是说对于旧版MaxCompute优先应用Multi-way Join优化,并且可以忽略用户指定MapJoin hint。
explain
select /* +mapjoin(t1) */ t1.*
from t1 join t2 on t1.c1 = t2.c1
join t3 on t1.c1 = t3.c1;
旧版MaxCompute物理执行计划同上。
MaxCompute 2.0 Optimizer会优先使用用户指定的MapJoin hint,对于上述例子,如果t1比较大的话,会遇到类似错误:
FAILED: ODPS-0010000:System internal error - SQL Runtime Internal Error: Hash Join Cursor HashJoin_REL… small table exceeds, memory limit(MB) 640, fixed memory used …, variable memory used …
对于这种情况,如果MapJoin不是期望行为,建议去掉MapJoin hint。
sigkill.oom
同small.table.exceeds.mem.limit,如果用户指定了MapJoin hint,并且用户本身所指定的小表比较大。在旧版MaxCompute下有可能被优化成Multi-way Join从而成功。但在MaxCompute 2.0下,用户可能通过设定odps.sql.mapjoin.memory.max来避免小表超限的错误,但每个MaxCompute worker有固定的内存限制,如果小表本身过大,则MaxCompute worker会由于内存超限而被杀掉,错误类似于:
Fuxi job failed - WorkerRestart errCode:9,errMsg:SigKill(OOM), usually caused by OOM(outof memory).
这里建议您去掉MapJoin hint,使用Multi-way Join。
wm_concat.first.argument.const
聚合函数中关于WM_CONCAT的说明,一直要求WM_CONCAT第一个参数为常量,旧版MaxCompute检查不严格,比如源表没有数据,就算WM_CONCAT第一个参数为ColumnReference,也不会报错。
函数声明:
string wm_concat(string separator, string str)
参数说明:
separator:String类型常量,分隔符。其他类型或非常量将引发异常。
MaxCompute 2.0会在plan阶段便检查参数的合法性,假如WM_CONCAT的第一个参数不是常量,会立即报错。示例如下:
错误写法:
select wm_concat(value, ',') FROM src group by value;
报错信息:
FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: com.aliyun.odps.lot.cbo.validator.AggregateCallValidator$AggregateCallValidationException: Invalid argument type - The first argument of WM_CONCAT must be constant string.
pt.implicit.convertion.failed
srcpt是一个分区表,并有两个分区:
create table srcpt(key STRING, value STRING) partitioned by (pt STRING);
alter table srcpt add partition (pt='pt1');
alter table srcpt add partition (pt='pt2');
对于以上SQL,String类型pt列,INT类型常量,都会转为DOUBLE进行比较。即使Project设置了odps.sql.udf.strict.mode=true,旧版MaxCompute不会报错,所有pt都会过滤掉,而MaxCompute 2.0会直接报错。示例如下:
错误写法:
select key from srcpt where pt in (1, 2);
报错信息:
FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: java.lang.NumberFormatException: ODPS-0123091:Illegal type cast - In function cast, value 'pt1' cannot be casted from String to Double.
建议避免STRING分区列和INT类型常量比较,将INT类型常量改成STRING类型。
having.use.select.alias
SQL规范定义Group by + Having子句是Select子句之前阶段,所以Having中不应该使用Select子句生成的Column alias。
示例
错误写法:
select id id2 from table_name group by id having id2 > 0;
报错信息:
FAILED: ODPS-0130071:[1,44] Semantic analysis exception - column id2 cannot be resolvedODPS-0130071:[1,44] Semantic analysis exception - column reference id2 should appear in GROUP BY key
其中id2为Select子句中新生成的Column alias,不应该在Having子句中使用。
dynamic.pt.to.static
说明:MaxCompute2.0动态分区某些情况会被优化器转换成静态分区处理。
示例
insert overwrite table srcpt partition(pt) select id, 'pt1' from table_name;
会被转化成
insert overwrite table srcpt partition(pt='pt1') select id from table_name;
如果用户指定的分区值不合法,比如错误地使用了’${bizdate}’,MaxCompute 2.0语法检查阶段便会报错。详情请参见分区。
错误写法:
insert overwrite table srcpt partition(pt) select id, '${bizdate}' from table_name limit 0;
报错信息:
FAILED: ODPS-0130071:[1,24] Semantic analysis exception - wrong columns count 2 in data source, requires 3 columns (includes dynamic partitions if any)
旧版MaxCompute因为LIMIT 0,SQL最终没有输出任何数据,动态分区不会创建,所以最终不报错。
lot.not.in.subquery
说明:In subquery中NULL值的处理问题。
在标准SQL的IN 运算中,如果后面的值列表中出现NULL,则返回值不会出现false,只可能是NULL或者true。如1 in (null, 1, 2, 3) 为true,而1 in (null, 2, 3) 为NULL,null in (null, 1, 2, 3) 为NULL。同理not in操作在列表中有NULL的情况下,只会返回false或者NULL,不会出现true。
MaxCompute 2.0会用标准的行为进行处理,收到此提醒的用户请注意检查您的查询,IN操作中的子查询中是否会出现空值,出现空值时行为是否与您预期相符,如果不符合预期请做相应的修改。
示例
select * from t where c not in (select accepted from c_list);
若accepted中不会出现NULL值,则此问题可忽略。若出现空值,则c not in (select accepted from c_list)原先返回true,则新版本返回NULL。
正确写法
select * from t where c not in (select accepted from c_list where accepted is not null)
七、导出SQL的运行结果
您可以通过以下方法导出SQL的运行结果:
- 如果数据比较少,请使用SQL Task得到全部的查询结果。
- 如果需要导出某个表或者分区,请使用Tunnel直接导出查询结果。
- 如果SQL比较复杂,请使用Tunnel和SQL相互配合导出查询结果。
DataWorks 可以方便地帮您运行SQL,同步数据,并支持定时调度,配置任务依赖的功能。
开源工具DataX可以帮助您方便地把MaxCompute中的数据导出到目标数据源,详情请参见DataX概述。
(1) 、 SQLTask方式导出 SQLTask使用SDK方法,直接调用MaxCompute
SQL的接口SQLTask.getResult(i),可以很方便地运行SQL并获得其返回结果。使用方法请参见SQLTask。
使用SQLTask时,请注意: SQLTask.getResult(i)用于导出SELECT查询结果,不适用于导出show tables;等其他MaxCompute命令操作结果。
SELECT语句返回给客户端的数据条数可以通过READ_TABLE_MAX_ROW进行设置,详情请参见设置项目空间属性。
SELECT语句最多返回1万条数据至客户端。即如果在客户端(包括SQLTask)直接执行SELECT语句,相当于在SELECT语句最后加了Limit N。
如果使用CREATE TABLE XX AS SELECT或者INSERT INTO/OVERWRITE TABLE把结果固化到具体的表里则不受此限制。
(2)、Tunnel方式导出
如果您需要导出的查询结果是某张表的全部内容(或者是具体的某个分区的全部内容),可以通过Tunnel来实现,详情请参见命令行工具 和基于SDK编写的Tunnel SDK。
此处提供一个Tunnel命令行导出数据的简单示例,Tunnel SDK的编写适用于Tunnel命令行无法支持的场景,详情请参见批量数据通道概述。
tunnel d wc_out c:\wc_out.dat;
2016-12-16 19:32:08 - new session: 201612161932082d3c9b0a012f68e7 total lines: 3
2016-12-16 19:32:08 - file [0]: [0, 3), c:\wc_out.dat
downloading 3 records into 1 file
2016-12-16 19:32:08 - file [0] start
2016-12-16 19:32:08 - file [0] OK. total: 21 bytes
download OK
(3)、SQLTask配合Tunnel方式导出
SQLTask不能处理超过1万条数据,而Tunnel方式可以,两者可以互补,因此可以基于两者实现超过1万条数据的导出。
代码实现的示例如下。
private static final String accessId = "userAccessId";
private static final String accessKey = "userAccessKey";
private static final String endPoint = "http://service.cn-shanghai.maxcompute.aliyun.com/api";
private static final String project = "userProject";
private static final String sql = "userSQL";
private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//用随机字符串作为临时表的名称。
private static final Odps odps = getOdps();
public static void main(String[] args) {
System.out.println(table);
runSql();
tunnel();
}
/*
* 下载SQLTask的结果。
* */
private static void tunnel() {
TableTunnel tunnel = new TableTunnel(odps);
try {
DownloadSession downloadSession = tunnel.createDownloadSession(
project, table);
System.out.println("Session Status is : "
+ downloadSession.getStatus().toString());
long count = downloadSession.getRecordCount();
System.out.println("RecordCount is: " + count);
RecordReader recordReader = downloadSession.openRecordReader(0,
count);
Record record;
while ((record = recordReader.read()) != null) {
consumeRecord(record, downloadSession.getSchema());
}
recordReader.close();
} catch (TunnelException e) {
e.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
/*
* 保存数据。
* 数据量少时直接打印后拷贝也是可行的。实际场景可以用Java.io写到本地文件,或者写到远端存储上保存起来。
* */
private static void consumeRecord(Record record, TableSchema schema) {
System.out.println(record.getString("username")+","+record.getBigint("cnt"));
}
/*
* 运行SQL,把查询结果保存成临时表。
* 此处保存数据的生命周期为1天,即使删除步骤出了问题,也不会太浪费存储空间。
* */
private static void runSql() {
Instance i;
StringBuilder sb = new StringBuilder("Create Table ").append(table)
.append(" lifecycle 1 as ").append(sql);
try {
System.out.println(sb.toString());
i = SQLTask.run(getOdps(), sb.toString());
i.waitForSuccess();
} catch (OdpsException e) {
e.printStackTrace();
}
}
/*
* 初始化MaxCompute的连接信息。
* */
private static Odps getOdps() {
Account account = new AliyunAccount(accessId, accessKey);
Odps odps = new Odps(account);
odps.setEndpoint(endPoint);
odps.setDefaultProject(project);
return odps;
}
(4)、DataWorks数据同步方式导出
DataWorks支持运行SQL并配置数据同步任务,以完成数据生成和导出需求。
- 登录DataWorks控制台。
- 在左侧导航栏,单击工作空间列表。
- 单击相应工作空间后的进入数据开发。
- 新建业务流程。
- 右键单击业务流程,选择新建业务流程
- 输入业务名称。
- 单击新建。
- 创建SQL节点。
- 右键单击业务流程,选择新建 > MaxCompute > ODPS SQL。
- 填写节点名称为runsql,单击提交。
- 配置ODPS SQL节点,配置完成后单击保存。
- 创建数据同步节点。
- 右键单击业务流程,选择新建 > 数据集成 > 离线同步。
- 填写节点名称为sync2mysql,单击提交。
- 选择数据来源以及去向。
- 配置字段映射。
- 配置通道控制。
- 单击保存。
- 将数据同步节点和ODPS SQL节点连线配置成依赖关系,ODPS SQL节点作为数据的产出节点,数据同步节点作为数据的导出节点。
- 工作流调度配置完成后(可以直接使用默认配置),单击运行。数据同步的运行日志,如下所示。
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer -
任务启动时刻 : 2016-12-17 23:43:34
任务结束时刻 : 2016-12-17 23:43:46
任务总计耗时 : 11s
任务平均流量 : 31.36KB/s
记录写入速度 : 1668rec/s
读出记录总数 : 16689
读写失败总数 : 0
执行如下SQL语句查看数据同步的结果。
select count(*) from result_in_db;
八、分区剪裁合理性评估
本文为您介绍如何评估分区剪裁合理性。
MaxCompute分区表是指在创建表时指定分区空间,即指定表内的几个字段作为分区列。使用数据时,如果指定了需要访问的分区名称,则只会读取相应的分区,避免全表扫描,提高处理效率,降低费用。
分区剪裁是指对分区列指定过滤条件,使得SQL执行时只用读取表分区的部分数据,避免全表扫描引起的数据错误及资源浪费。但是分区失效的情况会经常发生。
本文将从以下两方面介绍分区剪裁:
- 判断分区剪裁是否生效。
- 分区剪裁失效的场景分析。
- 判断分区剪裁是否生效
- 通过EXPLAIN命令查看SQL执行计划,用于判断SQL中的分区剪裁是否生效。
(1)、 分区剪裁未生效。
explain
select seller_id
from xxxxx_trd_slr_ord_1d
where ds=rand();
从执行计划中可见,SQL读取了表的1344个分区,即该表的所有分区。
(2)、分区剪裁生效
explain
select seller_id
from xxxxx_trd_slr_ord_1d
where ds='20150801';
从执行计划中可见,SQL只读取了表的20150801分区。
(3)、分区剪裁失效的场景分析
自定义函数导致分区剪裁失效
当分区剪裁的条件中使用了用户自定义函数(或者部分内建函数)时,分区剪裁失效。所以,对于分区值的限定,如果使用了非常规函数,建议您使用Explain命令查看执行计划,确定分区剪裁是否生效。
explain
select ...
from xxxxx_base2_brd_ind_cw
where ds = concat(SPLIT_PART(bi_week_dim(' ${bdp.system.bizdate}'), ',', 1), SPLIT_PART(bi_week_dim(' ${bdp.system.bizdate}'), ',', 2))
说明 UDF已支持分区裁剪,详情请参见WHERE子句过滤(where_condition)文中的说明。
使用JOIN时分区剪裁失效
在SQL语句中使用JOIN进行关联时:
如果分区剪裁条件放在WHERE子句中,则分区剪裁会生效。
如果分区剪裁条件放在ON子句中,从表的分区剪裁会生效,主表则不会生效。
下面针对三种JOIN具体说明:
LEFT OUTER JOIN
分区剪裁条件均放在ON子句中
set odps.sql.allow.fullscan=true;
explain
select a.seller_id
,a.pay_ord_pbt_1d_001
from xxxxx_trd_slr_ord_1d a
left outer join
xxxxx_seller b
on a.seller_id=b.user_id
and a.ds='20150801'
and b.ds='20150801';
由上图可见,左表进行了全表扫描,只有右表的分区裁剪有效果。
分区剪裁条件均放在WHERE子句中
set odps.sql.allow.fullscan=true;
explain
select a.seller_id
,a.pay_ord_pbt_1d_001
from xxxxx_trd_slr_ord_1d a
left outer join
xxxxx_seller b
on a.seller_id=b.user_id
where a.ds='20150801'
and b.ds='20150801';
由上图可见,两张表的分区裁剪都有效果。
RIGHT OUTER JOIN
与LEFT OUTER JOIN类似,如果分区剪裁条件放在ON子句中则只有RIGHT OUTER JOIN的左表生效。如果分区剪裁条件放在WHERE中,则两张表都会生效。
FULL OUTER JOIN
分区剪裁条件只有都放在WHERE子句中才会生效,放在ON子句中都不会生效。
注意事项
分区剪裁如果失效影响较大,且不容易发现。因此,建议在代码提交时关注分区剪裁失效问题。
自定义函数中使用分区剪裁时,需要修改类或者在SQL语句前设置set odps.sql.udf.ppr.deterministic = true;。详情请参见WHERE子句过滤(where_condition)。
九、分组取出每组数据的前N条
示例数据
目前的数据,如下表所示。
empno ename job sal
7369 SMITH CLERK 800.0
7876 SMITH CLERK 1100.0
7900 JAMES CLERK 950.0
7934 MILLER CLERK 1300.0
7499 ALLEN SALESMAN 1600.0
7654 MARTIN SALESMAN 1250.0
7844 TURNER SALESMAN 1500.0
7521 WARD SALESMAN 1250.0
实现方法
您可以通过以下两种方法实现:
取出每条数据的行号,再用 where 语句进行过滤。
SELECT * FROM (
SELECT empno
, ename
, sal
, job
, ROW_NUMBER() OVER (PARTITION BY job ORDER BY sal) AS rn
FROM emp
) tmp
WHERE rn < 10;
使用 UDTF 实现 Split 函数。
详情请参见 MaxCompute 学习计划 中最后的示例。此例可以更迅速地判断当前的序号,如果是已经超过预定的条数(例如10 条),便不再处理,从而提高计算效率。
十、多行数据合并为一行数据
示例数据
class gender name
1 M LiLei
1 F HanMM
1 M Jim
1 M HanMM
2 F Kate
2 M Peter
使用示例
示例1:将class相同的names合并为一行,并对names去重。去重操作可通过嵌套子查询实现。
SELECT class, wm_concat(distinct ',', name) FROM students GROUP BY class;
说明 wm_concat是字符拼接函数,详情请参见WM_CONCAT。
输出结果如下。
class names
1 LiLei,HanMM,Jim
2 Kate,Peter
示例2:统计不同class对应的男女人数。
SELECT
class
,SUM(CASE WHEN gender = 'M' THEN 1 ELSE 0 END) AS cnt_m
,SUM(CASE WHEN gender = 'F' THEN 1 ELSE 0 END) AS cnt_f
FROM students
GROUP BY class;
输出结果如下。
class cnt_m cnt_f
1 2 1
2 1 1
十一、行转列及列转行最佳实践
本段基于示例为您介绍如何使用SQL实现行转列、列转行需求。
将多行数据转换成一行显示,或将一列数据转换成多列显示。
列转行
将一行数据转换成多行显示,或将多列数据转换成一列显示。
示例数据
创建用于实现行转列的源表并插入数据,命令示例如下。
create table rowtocolumn (name string, subject string, result bigint);
insert into table rowtocolumn values
('张三' , '语文' , 74),
('张三' , '数学' , 83),
('张三' , '物理' , 93),
('李四' , '语文' , 74),
('李四' , '数学' , 84),
('李四' , '物理' , 94);
创建用于实现列转行的源表并插入数据,命令示例如下。
create table columntorow (name string, chinese bigint, mathematics bigint, physics bigint);
insert into table columntorow values
('张三' , 74, 83, 93),
('李四' , 74, 84, 94);
行转列示例
您可以通过如下两种方法实现行转列:
方法一:使用case when表达式,灵活提取各科目(subject)的值作为单独的列,命令示例如下。
select name as 姓名,
max(case subject when '语文' then result end) as 语文,
max(case subject when '数学' then result end) as 数学,
max(case subject when '物理' then result end) as 物理
from rowtocolumn
group by name;
返回结果如下。
+--------+------------+------------+------------+
| 姓名 | 语文 | 数学 | 物理 |
+--------+------------+------------+------------+
| 张三 | 74 | 83 | 93 |
| 李四 | 74 | 84 | 94 |
+--------+------------+------------+------------+
方法二:借助MaxCompute提供的内建函数实现,先基于CONCAT和WM_CONCAT函数合并科目和成绩为一列,然后通过KEYVALUE函数解析科目(subject)的值作为单独的列。命令示例如下。
select name as 姓名,
keyvalue(subject, '语文') as 语文,
keyvalue(subject, '数学') as 数学,
keyvalue(subject, '物理') as 物理
from(
select name, wm_concat(';',concat(subject,':',result))as subject
from rowtocolumn
group by name);
返回结果如下。
+--------+------------+------------+------------+
| 姓名 | 语文 | 数学 | 物理 |
+--------+------------+------------+------------+
| 张三 | 74 | 83 | 93 |
| 李四 | 74 | 84 | 94 |
+--------+------------+------------+------------+
列转行示例
您可以通过如下两种方法实现列转行:
方法一:使用union all,将各科目(chinese、mathematics、physics)整合为一列,命令示例如下。
–解除order by必须带limit的限制,方便列转行SQL命令对结果按照姓名排序。
set odps.sql.validate.orderby.limit=false;
–列转行SQL。
select name as 姓名, subject as 科目, result as 成绩
from(
select name, '语文' as subject, chinese as result from columntorow
union all
select name, '数学' as subject, mathematics as result from columntorow
union all
select name, '物理' as subject, physics as result from columntorow)
order by name;
返回结果如下。
+--------+--------+------------+
| 姓名 | 科目 | 成绩 |
+--------+--------+------------+
| 张三 | 语文 | 74 |
| 张三 | 数学 | 83 |
| 张三 | 物理 | 93 |
| 李四 | 语文 | 74 |
| 李四 | 数学 | 84 |
| 李四 | 物理 | 94 |
+--------+--------+------------+
方法二:借助MaxCompute提供的内建函数实现,先基于CONCAT函数拼接各科目和成绩,然后基于TRANS_ARRAY和SPLIT_PART函数逐层拆解科目和成绩作为单独的列。命令示例如下。
select name as 姓名,
split_part(subject,':',1) as 科目,
split_part(subject,':',2) as 成绩
from(
select trans_array(1,';',name,subject) as (name,subject)
from(
select name,
concat('语文',':',chinese,';','数学',':',mathematics,';','物理',':',physics) as subject
from columntorow)tt)tx;
返回结果如下。
+--------+--------+------------+
| 姓名 | 科目 | 成绩 |
+--------+--------+------------+
| 张三 | 语文 | 74 |
| 张三 | 数学 | 83 |
| 张三 | 物理 | 93 |
| 李四 | 语文 | 74 |
| 李四 | 数学 | 84 |
| 李四 | 物理 | 94 |
+--------+--------+------------+
十二、MaxCompute SQL中的关联操作
本文为您介绍MaxCompute SQL中的关联(JOIN)操作。
类型 说明
- INNER JOIN 输出符合关联条件的数据。
- LEFT JOIN 输出左表的所有记录,以及右表中符合关联条件的数据。右表中不符合关联条件的行,输出NULL。
- RIGHT JOIN 输出右表的所有记录,以及左表中符合关联条件的数据。左表中不符合关联条件的行,输出NULL。
- FULL JOIN 输出左表和右表的所有记录,对于不符合关联条件的数据,未关联的另一侧输出NULL。
- LEFT SEMI JOIN 对于左表中的一条数据,如果右表存在符合关联条件的行,则输出左表。
- LEFT ANTI JOIN 对于左表中的一条数据,如果右表中不存在符合关联条件的数据,则输出左表。
SQL语句中,同时存在JOIN和WHERE子句时,如下所示。
(SELECT * FROM A WHERE {subquery_where_condition} A) A
JOIN
(SELECT * FROM B WHERE {subquery_where_condition} B) B
ON {on_condition}
WHERE {where_condition}
计算顺序如下:
- 子查询中的WHERE子句(即{subquery_where_condition})。
- JOIN子句中的关联条件(即{on_condition})。
- JOIN结果集中的WHERE子句(即{where_condition})。
因此,对于不同的JOIN类型,过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}中时,查询结果可能一致,也可能不一致。详情请参见场景说明。
示例数据
表A
建表语句如下。
CREATE TABLE A AS SELECT * FROM VALUES (1, 20180101),(2, 20180101),(2, 20180102) t (key, ds);
示例数据如下。
key ds
1 20180101
2 20180101
2 20180102
表B
建表语句如下。
CREATE TABLE B AS SELECT * FROM VALUES (1, 20180101),(3, 20180101),(2, 20180102) t (key, ds);
示例数据如下。
key ds
1 20180101
3 20180101
2 20180102
表A和表B的笛卡尔乘积如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
1 20180101 3 20180101
1 20180101 2 20180102
2 20180101 1 20180101
2 20180101 3 20180101
2 20180101 2 20180102
2 20180102 1 20180101
2 20180102 3 20180101
2 20180102 2 20180102
场景说明
INNER JOIN
INNER JOIN对左右表执行笛卡尔乘积,然后输出满足ON表达式的行。
结论:过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}中时,查询结果是一致的。
情况1:过滤条件在子查询{subquery_where_condition}中。
SELECT A.*, B.*
FROM
(SELECT * FROM A WHERE ds='20180101') A
JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key;
结果如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
情况2:过滤条件在JOIN的关联条件{on_condition}中。
SELECT A.*, B.*
FROM A JOIN B
ON a.key = b.key and A.ds='20180101' and B.ds='20180101';
笛卡尔积结果为9条,满足关联条件的结果只有1条,如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
情况3:过滤条件在JOIN结果集的WHERE子句中。
SELECT A.*, B.*
FROM A JOIN B
ON a.key = b.key
WHERE A.ds='20180101' and B.ds='20180101';
笛卡尔积的结果为9条,满足关联条件的结果有3条,如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180102 2 20180102
2 20180101 2 20180102
对上述结果执行JOIN结果集中的过滤条件A.ds=‘20180101’ and B.ds=‘20180101’,结果只有1条,如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
LEFT JOIN
LEFT JOIN对左右表执行笛卡尔乘积,输出满足ON表达式的行。对于左表中不满足ON表达式的行,输出左表,右表输出NULL。
结论:过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}中时,查询结果不一致。
左表的过滤条件在{subquery_where_condition}和{where_condition}中时,查询结果是一致的。
右表的过滤条件在{subquery_where_condition}和{on_condition}中时,查询结果是一致的。
情况1:过滤条件在子查询
{subquery_where_condition}中。
SELECT A.*, B.*
FROM
(SELECT * FROM A WHERE ds='20180101') A
LEFT JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key;
结果如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 NULL NULL
情况2:过滤条件在JOIN的关联条件{on_condition}中。
SELECT A.*, B.*
FROM A LEFT JOIN B
ON a.key = b.key and A.ds='20180101' and B.ds='20180101';
笛卡尔积的结果有9条,满足关联条件的结果只有1条。左表输出剩余不满足关联条件的两条记录,右表输出NULL。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 NULL NULL
2 20180102 NULL NULL
情况3:过滤条件在JOIN结果集的WHERE子句中。
SELECT A.*, B.*
FROM A LEFT JOIN B
ON a.key = b.key
WHERE A.ds='20180101' and B.ds='20180101';
笛卡尔积的结果为9条,满足ON条件的结果有3条。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 2 20180102
2 20180102 2 20180102
对上述结果执行JOIN结果集中的过滤条件A.ds=‘20180101’ and B.ds=‘20180101’,结果只有1条。
a.key a.ds b.key b.ds
1 20180101 1 20180101
RIGHT JOIN
RIGHT JOIN和LEFT JOIN是类似的,只是左右表的区别。
过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}时,查询结果不一致。
右表的过滤条件,在{subquery_where_condition}和{where_condition}中时,查询结果一致。
左表的过滤条件,放在{subquery_where_condition}和{on_condition}中时,查询结果一致。
FULL JOIN
FULL JOIN对左右表执行笛卡尔乘积,然后输出满足关联条件的行。对于左右表中不满足关联条件的行,输出有数据表的行,无数据的表输出NULL。
结论:过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}时,查询结果不一致。
情况1:过滤条件在子查询{subquery_where_condition}中。
SELECT A.*, B.*
FROM
(SELECT * FROM A WHERE ds='20180101') A
FULL JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key;
结果如下。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 NULL NULL
NULL NULL 3 20180101
情况2:过滤条件在JOIN的关联条件{on_condition}中。
SELECT A.*, B.*
FROM A FULL JOIN B
ON a.key = b.key and A.ds='20180101' and B.ds='20180101';
笛卡尔积的结果有9条,满足关联条件的结果只有1条。对于左表不满足关联条件的两条记录输出左表数据,右表输出NULL。对于右表不满足关联条件的两条记录输出右表数据,左表输出NULL。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 NULL NULL
2 20180102 NULL NULL
NULL NULL 3 20180101
NULL NULL 2 20180102
情况3:过滤条件在JOIN结果集的WHERE子句中。
SELECT A.*, B.*
FROM A FULL JOIN B
ON a.key = b.key
WHERE A.ds='20180101' and B.ds='20180101';
笛卡尔积的结果有9条,满足关联条件的结果有3条。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 2 20180102
2 20180102 2 20180102
对于不满足关联条件的表输出数据,另一表输出NULL。
a.key a.ds b.key b.ds
1 20180101 1 20180101
2 20180101 2 20180102
2 20180102 2 20180102
NULL NULL 3 20180101
对上述结果执行JOIN结果集中的过滤条件A.ds=‘20180101’ and B.ds=‘20180101’,结果只有1条。
a.key a.ds b.key b.ds
1 20180101 1 20180101
LEFT SEMI JOIN
LEFT SEMI JOIN将左表的每一条记录,和右表进行匹配。如果匹配成功,则输出左表。如果匹配不成功,则跳过。由于只输出左表,所以JOIN后的WHERE条件中不涉及右表。
结论:过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}中时,查询结果是一致的。
情况1:过滤条件在子查询{subquery_where_condition}中。
SELECT A.*
FROM
(SELECT * FROM A WHERE ds='20180101') A
LEFT SEMI JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key;
结果如下。
a.key a.ds
1 20180101
情况2:过滤条件在JOIN的关联条件{on_condition}中。
SELECT A.*
FROM A LEFT SEMI JOIN B
ON a.key = b.key and A.ds='20180101' and B.ds='20180101';
结果如下。
a.key a.ds
1 20180101
情况3:过滤条件在JOIN结果集的WHERE子句中。
SELECT A.*
FROM A LEFT SEMI JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key
WHERE A.ds='20180101';
符合关联条件的结果如下。
a.key a.ds
1 20180101
对上述结果执行JOIN结果集中的过滤条件A.ds=‘20180101’,结果如下。
a.key a.ds
1 20180101
LEFT ANTI JOIN
LEFT ANTI JOIN将左表的每一条记录,和右表进行匹配。如果右表中的记录不匹配,则输出左表。由于只输出左表,所以JOIN后的WHERE条件中不能涉及右表。LEFT ANTI JOIN常常用来实现NOT EXISTS语义。
结论:过滤条件在{subquery_where_condition}、{on_condition}和{where_condition}中时,查询结果不一致。
左表的过滤条件在{subquery_where_condition}和{where_condition}中时,查询结果是一致的。
右表的过滤条件在{subquery_where_condition}和{on_condition}中时,查询结果是一致的。
情况1:过滤条件在子查询{subquery_where_condition}中。
SELECT A.*
FROM
(SELECT * FROM A WHERE ds='20180101') A
LEFT ANTI JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key;
结果如下。
a.key a.ds
2 20180101
情况2:过滤条件在JOIN的关联条件{on_condition}中。
SELECT A.*
FROM A LEFT ANTI JOIN B
ON a.key = b.key and A.ds='20180101' and B.ds='20180101';
结果如下。
a.key a.ds
2 20180101
2 20180102
情况3:过滤条件在JOIN结果集的WHERE子句中。
SELECT A.*
FROM A LEFT ANTI JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key
WHERE A.ds='20180101';
左表中符合关联条件的数据如下。
a.key a.ds
2 20180101
2 20180102
对上述结果执行JOIN结果集中的过滤条件A.ds=‘20180101’,结果如下。
a.key a.ds
2 20180101
注意事项
- INNER JOIN/LEFT SEMI JOIN左右表的过滤条件不受限制。
- LEFT JOIN/LEFT ANTI
JOIN左表的过滤条件需放在{subquery_where_condition}或{where_condition}中, - 右表的过滤条件需放在{subquery_where_condition}或{on_condition}中
- RIGHT JOIN和LEFT
JOIN相反,右表的过滤条件需放在{subquery_where_condition}或{where_condition}中,左表的过滤条件需放在{subquery_where_condition}或{on_condition}。 - FULL OUTER JOIN的过滤条件只能放在{subquery_where_condition}中。
阿里云参考文档:
https://help.aliyun.com/product/27797.html