【ELK系列四】肝了两晚,你想要的elasticsearch内容放在这了
文章目录
-
- ES的核心概念及使用
-
- 一、概述
- 二、Elasticsearch核心概念
-
- 索引 index
- 类型 type
- 映射 mapping
- 文档 document
- 字段Field
- 接近实时 NRT
- 集群 cluster
- 节点 node
- 分片和复制 shards&replicas
- 三、Elasticsearch操作
-
- 1、使用XPUT创建索引
- 2、插入文档
- 3、查询文档
- 4、更新文档
- 5、搜索文档
- 6、删除文档
- 7、删除索引
- 8、条件查询
-
- 8.1 使用match_all做查询
- 8.2 关键字段进行查询
- 8.3 bool的复合查询
- 8.4 term、terms匹配
- 8.5 Range过滤
- 8.6 exists和 missing过滤
- 8.7 查询与过滤条件合并
- 四、定义字段类型mappings
-
- 1、基本用法
- 2、管理索引库分片数以及副本数settings
- 3、分页解决方案
-
- 3.1 from和size浅分页
- 3.2、scroll深分页
- 4、ES的中文分词器IK
注意:文章比较长,你忍一下
ES的核心概念及使用
一、概述
Elasticsearch是面向文档(document oriented)的,可以存储整个对象或文档(document)、索引(index)每个文档的内容,可以快速搜索。Elasticsearch中,可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
Elasticsearch和传统关系型数据库类比如下:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
二、Elasticsearch核心概念
索引 index
一个索引就是很多文档的集合。比如说,你可以有客户数据的索引、产品目录的索引、订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),当要对于这个索引中的文档进行查询、搜索、更新和删除的时候,都要使用到这个名字。一个集群中,可以定义任意多的索引。
类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,可以为用户数据定义一个类型、为博客数据定义一个类型、评论数据定义一个类型等。
映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。一个节点也是由一个名字来标识的,名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做elasticsearch的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做elasticsearch的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做elasticsearch的集群。
分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能和吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制的重要性,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变你分片的数量。
在7.0.0版本之前默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
注意:在7.0.0版本之后默认只有1个分片
三、Elasticsearch操作
curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用curl可以简单实现常见的get/post请求。简单的认为是可以在命令行下面访问url的一个工具。在centos的默认库里有curl工具的,如果没有请yum安装即可。
curl
-X 指定http的请求方法 有HEAD GET POST PUT DELETE
-d 指定要传输的数据
-H 指定http请求头信息
在下面的内容里,我们先使用curl在shell中实验,后面的例子为了看的更清楚,使用kibana来操作。
1、使用XPUT创建索引
在我们的kibana的dev tools当中执行以下语句
curl -XPUT http://companynode01:9200/book/?pretty

2、插入文档
前面的命令使用 PUT 动词将一个文档添加到 /journal(文档类型),并为该文档分配 ID 为1。URL 路径显示为index/doctype/ID(索引/文档类型/ID)。指定内容类型,可以防止es严格内容类型检查报错。
curl -XPUT http://companynode01:9200/book/journal/1?pretty -d '{"id": 1, "title": "Solr is a search engine", "num": "200", "is_start": "yes", "pub_date": "2017-02-08"}' -H "Content-Type: application/json"
3、查询文档
curl -XGET http://companynode01:9200/book/journal/1?pretty -H "Content-Type: application/json"
对返回的内容部分字段进行解释:
- took: 值告诉我们执行整个搜索请求耗费了多少毫秒
- _shards: 告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个
- timed_out: 告诉我们查询是否超时。默认情况下,搜索请求不会超时
4、更新文档
curl -XPUT http://companynode01:9200/book/journal/1?pretty -d '{"id": 1, "title": "Elasticsearch is a search engine", num": "200", "is_start": "yes", "pub_date": "2017-02-08"}' -H "Content-Type: application/json"
5、搜索文档
curl -XGET "http://companynode01:9200/book/journal/_search?q=title:elasticsearch" -H "Content-Type: application/json"
6、删除文档
curl -XDELETE "http://companynode01:9200/book/journal/1?pretty" -H "Content-Type: application/json"
7、删除索引
curl -XDELETE "http://companynode01:9200/book?pretty" -H "Content-Type: application/json"
8、条件查询
使用post请求插入数据:
curl -XPOST "http://companynode01:9200/book/journal/1?pretty" -d '{"id": 1, "title": "Lunce is a search engine", "num": "1000", "is_start": "yes", "pub_date": "2018-01-08"}' -H "Content-Type: application/json"
curl -XPOST "http://companynode01:9200/book/journal/2?pretty" -d '{"id": 2, "title": "Elasticsearch is a search engine", "num": "200", "is_start": "yes", "pub_date": "2017-02-08"}' -H "Content-Type: application/json"
curl -XPOST "http://companynode01:9200/book/journal/3?pretty" -d '{"id": 3, "title": "Solr is a search engine", "num": "300", "is_start": "no", "pub_date": "2017-12-05"}' -H "Content-Type: application/json"
curl -XPOST "http://companynode01:9200/book/journal/4?pretty" -d '{"id": 4, "title": "search is good", "num": "200", "is_start": "yes", "pub_date": "2017-08-05"}' -H "Content-Type: application/json"
curl -XPOST "http://companynode01:9200/book/journal/5?pretty" -d '{"id": 5, "title": "This is a search engine", "num": "800", "is_start": "no", "pub_date": "2021-02-05"}' -H "Content-Type: application/json"
8.1 使用match_all做查询
curl -XGET "http://companynode01:9200/book/journal/_search?pretty" '{"query": {"match_all": {}}}' -H "Content-Type: application/json"
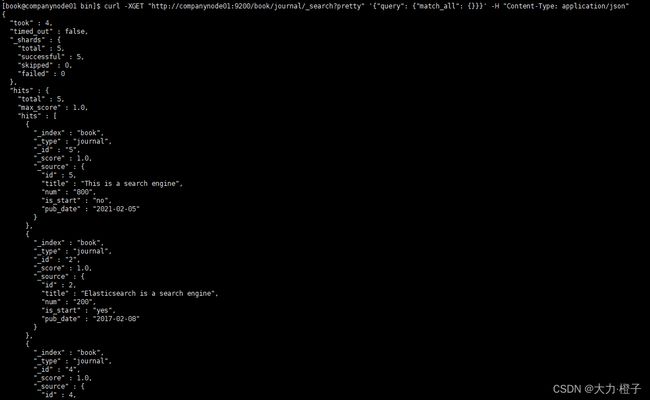
注意:通过match_all匹配后,会把所有的数据检索出来,但是往往真正的业务需求并非要找全部的数据,而是检索出自己想要的;并且对于es集群来说,直接检索全部的数据,很容发生GC,所以我们要学会如何进行高效的检索数据
为了方便,使大家看的更清晰,我下面使用的语句格式都是在kibana中展示的,格式会更清晰一些
8.2 关键字段进行查询
GET /book/journal/_search?pretty
{
"query": {
"match": {"title": "search"}
}
}
查询title中匹配到search的数据

注意:match不能多条件查询,即不能使用match查询num大于300,且is_start是no的数据,这样的查询需要使用复合查询
8.3 bool的复合查询
当出现多个查询语句组合的时候,可以用bool来查询。
1、must (must字段对应的是个列表,也就是说可以有多个并列的查询条件,一个文档满足各个子条件后才最终返回)
2、should (只要符合其中一个条件就返回)
3、must_not (与must相反,也就是说可以有多个并列的查询条件,一个文档各个子条件后才最终的结果都不满足)
4、filter(条件过滤查询,过滤条件的范围用range表示gt表示大于、lt表示小于、gte表示大于等于、lte表示小于等于)
例子1:查询title匹配到search字符串内容的,且is_start是yes的数据
GET /book/journal/_search?pretty
{
"query": {
"bool": {
"must": [
{"match": {"title": "search"}},
{"match": {"is_start": "yes"}}
]
}
}
}

例子2:查询title匹配到search字符串内容的,且is_start不是no的数据
GET /book/journal/_search?pretty
{
"query": {
"bool": {
"must": {"match": {"title": "search"}},
"must_not": {"match": {"is_start": "no"}}
}
}
}
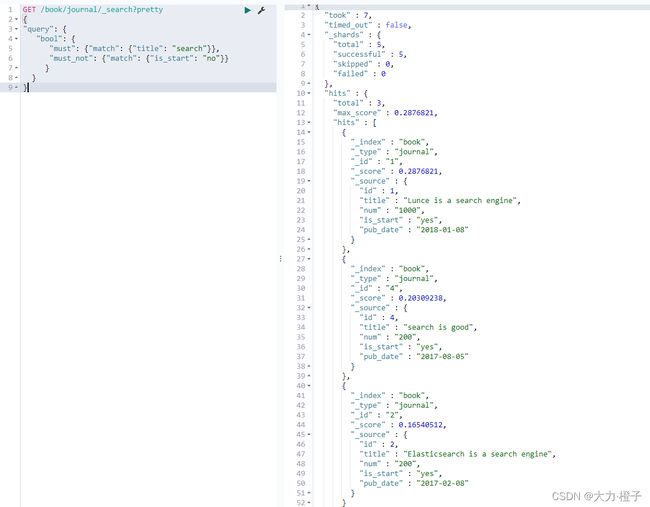
例子3:查询title匹配到search字符串内容的,或者is_start是no的数据。
GET /book/journal/_search?pretty
{
"query": {
"bool": {
"should": [
{"match": {"title": "search"}},
{"match": {"is_start": "no"}}
]
}
}
}

例子4:获取num大于200,且is_start是yes的数据。
8.4 term、terms匹配
使用term进行精确匹配(比如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据类型),和match做区分,match是经过分析的文本数据类型匹配(非精确匹配))
语法:
{"term": {"id": 2}}
{"term": {"pub_date": "2021-02-05"}}
{"term": {"is_start": "yes"}}
{"term": {"num": "200" }}
{"terms": {"num": ["200", "300"]}}
例子1:获取title字段精确匹配到search字符串,且is_start为no的数据
GET /book/journal/_search?pretty
{
"query": {
"bool": {
"must": [
{"term": {"title": "search"}},
{"term": {"is_start": "no"}}
]
}
}
}
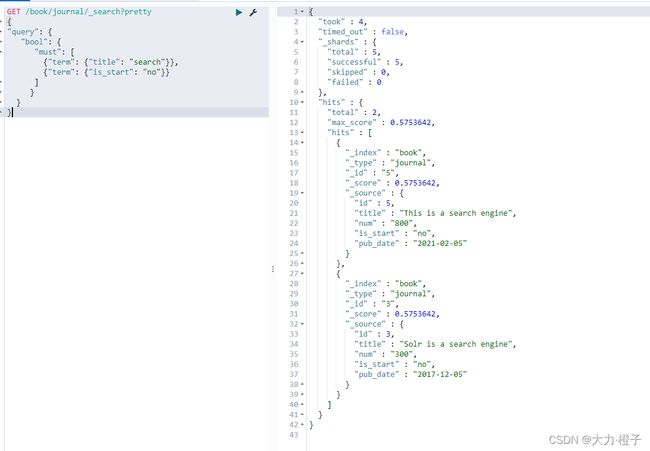
例子2:获取num为200、300的数据
GET /book/journal/_search?pretty
{
"query": {
"bool": {
"must": {"terms": {"num": ["200", "300"]}}
}
}
}

8.5 Range过滤
Range过滤允许我们按照指定的范围查找一些数据:操作范围:gt::大于,gte::大于等于,lt::小于,lte::小于等于
例子:找出id大于2,小于5的数据
GET /book/journal/_search?pretty
{
"query": {
"range": {
"id": {"gt":2, "lt": 5}
}
}
}

8.6 exists和 missing过滤
exists和missing过滤可以找到文档中是否包含某个字段或者是没有某个字段
例子:查找字段中包含title的文档
GET /book/journal/_search?pretty
{
"query": {
"exists": {"field": "title"}
}
}
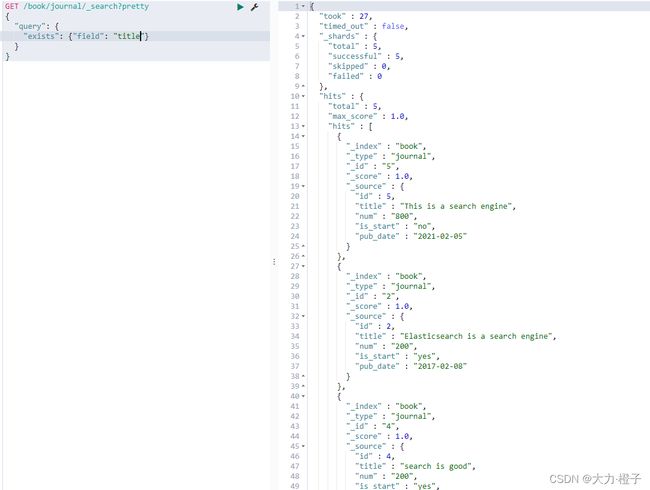
8.7 查询与过滤条件合并
通常复杂的查询语句,我们也要配合过滤语句来实现缓存,用filter语句就可以来实现
例子:查询title匹配到search字符串的,并且id为5的数据
GET /book/journal/_search?pretty
{
"query": {
"bool": {
"must": {"match": {"title": "search"}},
"filter": [{"term":{"id": 5}}]
}
}
}

四、定义字段类型mappings
在es当中,每个字段都会有默认的类型,根据我们第一次插入数据进去,es会自动帮我们推断字段的类型,当然我们也可以通过设置mappings来提前自定义我们字段的类型
使用mappings来提前定义字段类型使用mapping的映射管理,提前指定字段的类型,防止后续的程序问题。
1、基本用法
DELETE book
PUT book
{
"mappings": {
"journal" : {
"properties": {"title" : {"type": "text"}}
}
}
}
添加索引:book,文档类型分类为journal,索引字段为title ,字段的类型为text
获取对应的字段类型mappings
GET /book/_mapping/journal
继续添加字段
POST /book/_mapping/journal
{
"properties": {
"id": {"type": "integer"},
"num": {"type": "text"},
"is_start": {"type": "text"},
"pub_date": {"type": "date"}
}
}
查看所有的mappings
GET /book/_mapping/journal

查看指定field的mapping
GET /book/_mapping/journal/field/title
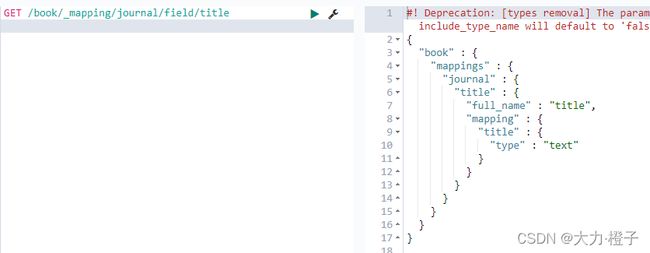
2、管理索引库分片数以及副本数settings
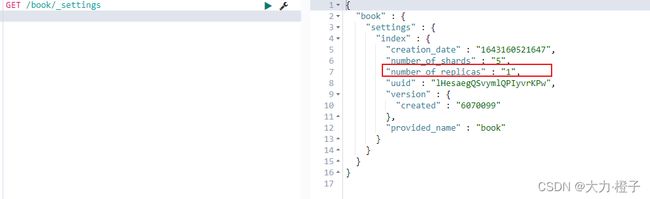
所谓的settings就是用来修改索引分片和副本数的;
比如有的重要索引,副本数很少甚至没有副本,那么我们可以通过setting来添加副本数
查看settings,红框内代表的是副本数
GET /book/_settings
把副本数修改为2
PUT /book/_settings
{
"number_of_replicas": 2
}
查看
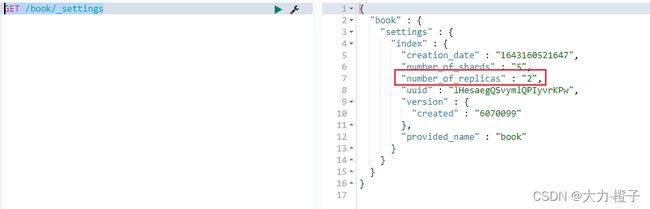
注意:副本可以改,分片不能改

3、分页解决方案
导入数据
DELETE us
POST /_bulk
{ "create": { "_index": "us", "_type": "tweet", "_id": "1" }}
{ "email" : "[email protected]", "name" : "John Smith", "username" : "@john" }
{ "create": { "_index": "us", "_type": "tweet", "_id": "2" }}
{ "email" : "[email protected]", "name" : "Mary Jones", "username" : "@mary" }
{ "create": { "_index": "us", "_type": "tweet", "_id": "3" }}
{ "date" : "2014-09-13", "name" : "Mary Jones", "tweet" : "Elasticsearch means full text search has never been so easy", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "4" }}
{ "date" : "2014-09-14", "name" : "John Smith", "tweet" : "@mary it is not just text, it does everything", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "5" }}
{ "date" : "2014-09-15", "name" : "Mary Jones", "tweet" : "However did I manage before Elasticsearch?", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "6" }}
{ "date" : "2014-09-16", "name" : "John Smith", "tweet" : "The Elasticsearch API is really easy to use", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "7" }}
{ "date" : "2014-09-17", "name" : "Mary Jones", "tweet" : "The Query DSL is really powerful and flexible", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "8" }}
{ "date" : "2014-09-18", "name" : "John Smith", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "9" }}
{ "date" : "2014-09-19", "name" : "Mary Jones", "tweet" : "Geo-location aggregations are really cool", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "10" }}
{ "date" : "2014-09-20", "name" : "John Smith", "tweet" : "Elasticsearch surely is one of the hottest new NoSQL products", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "11" }}
{ "date" : "2014-09-21", "name" : "Mary Jones", "tweet" : "Elasticsearch is built for the cloud, easy to scale", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "12" }}
{ "date" : "2014-09-22", "name" : "John Smith", "tweet" : "Elasticsearch and I have left the honeymoon stage, and I still love her.", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "13" }}
{ "date" : "2014-09-23", "name" : "Mary Jones", "tweet" : "So yes, I am an Elasticsearch fanboy", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "14" }}
{ "date" : "2014-09-24", "name" : "John Smith", "tweet" : "How many more cheesy tweets do I have to write?", "user_id" : 1 }
3.1 from和size浅分页
理解集群分页大概如何运行
按照一般的查询流程来说,如果我想查询前5条数据:
1、客户端请求发给某个节点
2、节点转发给各个分片,查询每个分片上的前5条
3、结果返回给节点,整合数据,提取前5条
4、返回给请求客户端
示例:
from定义了目标数据的偏移值,size定义当前返回数目
1、获取第一页的5个结果
GET /us/_search?pretty
{
"from" : 0 , "size" : 5
}
2、获取第二页的5个结果
GET /us/_search?pretty
{
"from" : 5 , "size" : 5
}
这种方法只适合少量数据,随着from增大,查询的时间就会越大,而且数据量越大,查询的效率指数下降
优点:from+size在数据量不大的情况下,效率比较高
缺点:在数据量非常大的情况下,from+size分页会把全部记录加载到内存中,这样做会导致es内存不足挂掉。
3.2、scroll深分页
上面的浅分页,当Elasticsearch响应请求时,它必须确定docs的顺序,排列响应结果。
如果请求的页数较少(假设每页10个docs), Elasticsearch不会有什么问题,但是如果页数较大时,比如请求第20页,Elasticsearch不得不取出第1页到第20页的所有docs,再去除第1页到第19页的docs,得到第20页的docs。
如果使用scroll,scroll就是维护了当前索引段的一份快照信息–缓存(这个快照信息是你执行这个scroll查询时的快照)。
可以把 scroll 分为初始化和遍历两步:
- 初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照。
初始化的时候就像是普通的search一样,其中的scroll=3m代表当前查询的数据缓存3分钟,Size:4 代表遍历时每次查询4条数据
GET us/_search?scroll=3m
{
"query": {"match_all": {}},
"size": 4
}
- 遍历时,从这个快照里取数据。在遍历时候,拿到上一次遍历中的scroll_id,然后带scroll参数,重复上一次的遍历步骤,知道返回的数据为空,就表示遍历完成
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "初始化的_scroll_id"
}
【注意】:每次都要传参数scroll,刷新搜索结果的缓存时间,另外不需要指定index和type(不要把缓存的时时间设置太长,占用内存)
比较:
浅分页,每次查询都会去索引库(本地文件夹)中查询pageNum*page条数据,然后截取掉前面的数据,留下最后的数据。 这样的操作在每个分片上都会执行,最后会将多个分片的数据合并到一起,再次排序,截取需要的分页数据。
深分页,可以一次性将所有满足查询条件的数据,都放到内存中。分页的时候,在内存中查询。相对浅分页,就可以避免多次读取磁盘。
4、ES的中文分词器IK
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器。那么我们接下来就来安装IK分词器,以实现中文的分词
第1步:对之前安装配置的es安装IK分词器
之前的安装在这篇文章中:https://blog.csdn.net/Chenftli/article/details/122614838
将安装包上传到companynode01机器的/book/soft(谁便,这只是我自己规划的路径)路径下
cd /book/soft
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.7.0/elasticsearch-analysis-ik-6.7.0.zip
# 将ik分词器的插件,解压到对应路径下
mkdir -p /book/install/elasticsearch-6.7.0/plugins/analysis-ik
unzip elasticsearch-analysis-ik-6.7.0.zip -d /book/install/elasticsearch-6.7.0/plugins/analysis-ik/
将安装包分发到集群其他机器上
cd /book/install/elasticsearch-6.7.0/plugins
scp -r analysis-ik/ companynode02:$PWD
scp -r analysis-ik/ companynode03:$PWD
集群所有机器重启es服务,执行以下命令停止es服务并重启es服务
ps -ef|grep elasticsearch | grep bootstrap | awk '{print $2}' |xargs kill -9
nohup /book/install/elasticsearch-6.7.0/bin/elasticsearch 2>&1 &
第2步、创建索引库并配置IK分词器,测试一下效果
创建索引库,这里指定分词方式为ik_max_word,会对中文进行最细粒度的切分
DELETE testik
PUT /testik?pretty
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik_max_word"
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"subject" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
测试:
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "今天的天气是个雨天"
}

示例一:匹配测试效果
POST /iktest/article/_bulk?pretty
{"index": {"_id": "1" }}
{"subject": "打工人的春运破防瞬间" }
{"index": {"_id": "2"}}
{"subject": "科比去世两周年"}
{"index": {"_id": "3"}}
{"subject": "3年后还偷你!本泽马家中被盗" }
{"index": {"_id": "4"}}
{"subject": "最惨购房人称自己损失超千万"}
{"index": {"_id": "5"}}
{"subject": "博物馆称学生打碎展品并非130万"}
查看分词器
对"打工人和购房"进行分词查询并标出
ikmaxword分词后的效果:打工|打|工人|人和|购房
POST /iktest/article/_search?pretty
{
"query": {"match": {"subject": "打工人和购房"}},
"highlight": {
"pre_tags": [""],
"post_tags": [""],
"fields": {
"subject": {}
}
}
}

第3步、配置热词更新、并测试效果
先查看一下没有配置新热词的分词效果
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "老铁,双击屏幕,给个小红心!"
}
分词:老|铁|双击|屏幕|给|个|小红|心
我们会发现,随着时间的推移和发展,有些网络热词我们并不能进行分词,因为网络热词并没有定义在我们的词库里面,这就需要我们经常能够实时的更新我们的网络热词,我们可以通过tomcat来实现远程词库来解决这个问题。
1、companynode03配置Tomcat(找一台配置即可)
使用book用户来进行配置tomcat,此处我们将tomcat装在companynode03机器上面即可,将我们的tomcat安装包上传到node03服务器的/book/soft路径下,然后进行解压
cd /book/soft/
tar -zxvf apache-tomcat-8.5.34.tar.gz -C /book/install/
tomcat当中添加配置hot_word.dic
cd /book/install/apache-tomcat-8.5.34/webapps/ROOT
vim hot_dict.dic
添加:
老铁
小红心
启动tomcat
cd /book/install/apache-tomcat-8.5.34/
bin/startup.sh
访问以验证tomcat是否安装成功,能够访问到,则证明tomcat安装成功
http://companynode03:8080/hot_dict.dic
2、 所有机器修改配置文件
所有机器都要修改es的配置文件(使用book用户来进行修改)
第一台机器companynode01修改es的配置
cd /book/install/elasticsearch-6.7.0/plugins/analysis-ik/config
vim IKAnalyzer.cfg.xml
修改为:
IK Analyzer 扩展配置
http://companynode03:8080/hot_dict.dic
修改完成之后分发到集群其他机器上面去
可以按照下面,companynode01执行以下命令
cd /book/install/elasticsearch-6.7.0/plugins/analysis-ik/config
scp IKAnalyzer.cfg.xml companynode02:$PWD
scp IKAnalyzer.cfg.xml companynode03:$PWD
3、所有机器重新启动es
所有机器执行如下命令,杀死并重新启动es服务
ps -ef|grep elasticsearch | grep bootstrap | awk '{print $2}' |xargs kill -9
nohup /book/install/elasticsearch-6.7.0/bin/elasticsearch 2>&1 &
再次查看分词效果:
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "老铁,双击屏幕,给个小红心!"
}
分词:老铁|双击|屏幕|给|个|小红心|小红|红心