py-19-JTWEB01
京淘1
目录:
day01:京淘- Maven继承聚合
day02:京淘-通用Mapper项目框架搭建
day03:京淘-导入页面,easyUl,实现商品列表查询
day04:京淘-后台系统实现上架下架
day05:京淘-描述表,图片上传, nginx反向代理
day06:京淘-Tomcat集群, Nginx负载均衡,Linux部署
day07:京淘-数据库主从复制amoeba读写分离
day08:京淘-数据库双机热备Mycat读,写分离
day09:京淘-Redis分片,商品类目缓冲,实现
day10:京淘-Redis哨兵
day11:京淘-Redis集群搭建
day12:京淘-实现跨域、商品详情展现
day13:登录、登出、加入购物车
day14:购物车数量修改
day01: 京淘-Maven继承聚合
今日任务:
-
京淘项目,学习意义,业务背景
-
搭建环境,画京淘项目系统架构图(基于注解+Maven构建项目+SSM)
学习意义,就业高薪!
先掌握能快速消化,而且面试官不擅长!
学习高薪4/5/6阶段

网络布局图,22台服务器,能近似当当商城(中型商城)
从后台开始一台服务开始,扩充到6个子系统(后台、前台、单点登录技术、购物车、订单、全文检索)
涉猎技术,层层优化
第四阶段:小京淘(中型项目规模)
-
nginx tomcat(并发数100~150)集群实现负载均衡(配置文件,4句)
-
数据库优化,Mysql主从复制(配置文件),读写分离(amoeba/mycat阿里)(配置xml文件)
-
缓存redis内存的数据库nosql代表。核心代码10行
第五阶段:大京淘(大型项目、超大型项目)
4.全文检索技术 lucene+solr离线/elestaicSerach(es)实时(大数据)支持海量数据(亿条数据 量之上)搜索工程师岗位!
5.消息队列RabbitMQ,软件层面架构优化最后一招 Kakfa MQ大数据
6.2017 DevOpts开发运维一体化 Docker(go谷歌、解决高并发和编译速度)容器化
7.微服务Dubbo(rpc)和springboot+springcloud
第六阶段:大数据,基于网络流量日志分析PV、UV、VV等指标的统计
7天 Hadoop(java)、HDFS、hive、kafka、zookeeper、flume、storm(spark scala编译完java)。。
学习方法:
-
why?(读百文,“走马观花” 碎片学习法:今日头条,百度demo)
-
把应用层先掌握(安装、配置、完成业务模块CRUD)
-
业务(唛头marks 物流)
-
深入底层(高级程序员、架构师,jvm优化,hash工作原理,tomcat优化)
大多数同学初级程序员!
京淘(京东、淘宝一网打尽)
典型电子商务系统,大型互联网架构
典型学习四类技术:分布式(集群)、高并发、高可用、海量数据
系统架构图:

完成业务:User用户表查询
开发步骤:
-
创建数据库,创建User表,录入数据(sql给你,导入)
-
持久层:pojo类User.java,注解JPA
-
Mybatis:基于接口开发 UserMapper.xml,项目引入mybatis自动生成SQL语句(单表CRUD)插件,SysMapper(工具类,写好了)接口UserMapper.java,mybatis-config.xml
-
业务层:UserService接口、UserServiceImpl实现类、配置文件applicationContext*.xml
-
控制层:UserController+Jsp(WEB-INF/views/*.jsp)

怎么导入数据
jtdb.sql
防止中文乱码
练习:
利用备份文件jtdb.sql创建数据库和表和数据
 该文件寻贴主得
该文件寻贴主得
最终检查表中要无乱码
准备工作的环境
-
eclipse创建一个新的工作空间+git(注册账号+外网)

2.项目的编码,默认gbk,修改utf-8

3.配置jdk运行环境,jdk1.7,jdk1.8

4.配置Maven环境,Maven创建工程,高级:继承和聚合



Settings.xml修改内容
-
修改存放路径
-
修改镜像仓库(私服)http://maven.tedu.cn/nexus/content/groups/public/

Maven继承、聚合(大型)
传统项目,大而全,部署也是在一起war。缺点:类多了业务多了,编译时间变长,部署或者发布时间变长。javaWeb项目频繁启动tomcat中间件和停止的时间非常长,debug调试。
团队开发git、svn版本控制(1.0,1.1.。。。)
运行war包变小,tomcatMaven插件,执行速度
主流新的方式,项目拆分,后台、前台
如何拆分我们的项目?
把传统的项目中的业务模块升级为项目,将来就有很多项目,这种分拆形式称为垂直拆分。
把一个项目又进行分层,这种拆分方式称为水平拆分!

把原来一个大项目拆分成多个小项目会发生什么问题呢?
-
原来是我的类之间的调用变成两个系统间的调用,扩展可能会变成两个服务器之间调用(调用jar包)
-
分开后各自项目会调用公用的一些jar包(继承)
-
工具类,多个项目要调用公用工具类(依赖)
-
Jar包版本升级,传统一个项目升级还容易些,很多子项目,每个项目都需要升级。(继承)
-
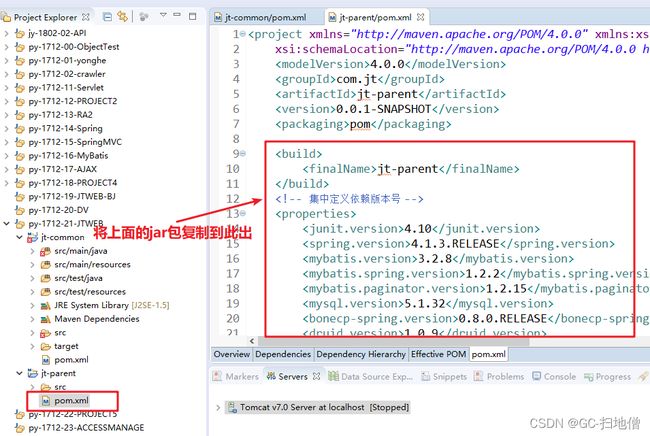
需要一个父工程,统一管理“所有”的jar,但是可以有特殊的 (jt-parent,pom.xml)
-
全局工具类工程,其他项目依赖(jt-common)
后台项目:jt-manage(pojo、mapper、service、controller)
3.水平分拆 jt-manage-pojo、jt-manage-mapper、jt-manage-service、jt-manage-web

总共有:
Jt-parent 父工程
-
Maven工程类型:pom
-
pom.xml管理“所有”的jar
-
版本控制

4.0.0
com.jt
jt-parent
0.0.1-SNAPSHOT
pom
4.10
junit
junit
${junit.version}
Jt-common 工具类工程

浏览文件所在目录

Jt-manage 特殊的父工程,聚合工程



在jt-parent导入jar包
jt-parent
4.10
4.1.3.RELEASE
3.2.8
1.2.2
1.2.15
5.1.32
0.8.0.RELEASE
1.0.9
2.3.2
3.4.2
0.9.1
1.6.4
1.2
2.5
2.0
2.5
3.3.2
2.4
1.3.1
2.4.2
4.3.5
2.6.0
1.0.29
junit
junit
${junit.version}
test
org.springframework
spring-webmvc
${spring.version}
org.springframework
spring-jdbc
${spring.version}
org.springframework
spring-aspects
${spring.version}
org.mybatis
mybatis
${mybatis.version}
org.mybatis
mybatis-spring
${mybatis.spring.version}
com.github.miemiedev
mybatis-paginator
${mybatis.paginator.version}
mysql
mysql-connector-java
${mysql.version}
com.alibaba
druid
${druid.version}
com.github.abel533
mapper
${mapper.version}
com.github.pagehelper
pagehelper
${pagehelper.version}
com.github.jsqlparser
jsqlparser
${jsqlparser.version}
com.jolbox
bonecp-spring
${bonecp-spring.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
com.fasterxml.jackson.core
jackson-databind
${jackson.version}
org.apache.httpcomponents
httpclient
${httpclient.version}
org.apache.httpcomponents
httpmime
4.3.1
com.rabbitmq
amqp-client
3.5.1
org.springframework.amqp
spring-rabbit
1.4.0.RELEASE
jstl
jstl
${jstl.version}
javax.servlet
servlet-api
${servlet-api.version}
provided
javax.servlet
jsp-api
${jsp-api.version}
provided
joda-time
joda-time
${joda-time.version}
org.apache.commons
commons-lang3
${commons-lang3.version}
org.apache.commons
commons-io
${commons-io.version}
commons-fileupload
commons-fileupload
${commons-fileupload.version}
redis.clients
jedis
${jedis.version}
commons-codec
commons-codec
1.9
org.hibernate
hibernate-validator
5.1.3.Final
报错处理

 该文件寻贴主得
该文件寻贴主得
第一步
删除jt-common项目中的报错类

Jt-manage-pojo 后台管理系统的pojo子项目
Jt-manage-mapper 只有映射的接口,映射文件jt-manage-web
Jt-manage-service 业务层
Jt-manage-controller/web controller/jsp/资源文件 三大框架配置文件、Mybatis映射文件、静态资源image/js/css/html。。。

搭建环境:
Maven继承、聚合
-
继承,在子工程有一个出现
标签 -
子工程
消失,它是自动拿父工程的groupId和version -
继承管理整个系统的所有的jar,管理jar版本
-
聚合工程有什么特点?类型pom,聚合工程特殊标签
;一键构建(子工程)
day02:京淘-通用Mapper项目框架搭建
知识回顾:
项目构建:
-
传统项目大而全,所以的业务功能在一个系统中
-
大型项目构建,业务垂直拆分和水平拆分
垂直拆分
-
jt-parent 公用项目,统一全局管理几乎所有的 jar 和版本
-
jt-common 公用工具类,各个项目都可以进行访问
-
jt-manage 后台项目使用聚合,它只管理它的子项目,其他什么都不管,一键构建
水平拆分(后台)
-
jt-manage-pojo 只管理存放 pojo 类
-
jt-manage-mapper 只管理 mapper 接口
-
jt-manage-service 只管理接口和实现类
-
jt-manage-web/controller web 项目管理 controller/jsp/ 静态资源
关系:
-
继承
-
聚合
-
依赖
Maven工程类型:常用下面三种
-
pom 父工程、聚合工程
-
jar java 工程,只有类 jt-common 、 …pojo/mapper/service
-
war javaWeb 工程,有 jsp/controller(request/response)
今天任务:
-
实现框架用户信息查询




-
先要找到 dtd 文件,存放在本地


-
配置 dtd 环境
-
编写 pojo ,增加 JPA 注解
-
实现映射文件和接口文件
-
实现 service 接口和映射文件
-
pom.xml 中增加插件支持
org.apache.tomcat.maven
tomcat7-maven-plugin
8091
/


通用Mapper怎么自动产生sql语句的?
-
如何获得表名 @Table
-
如何获得所有的字段,反射获得所有类的属性(全局驼峰规则配置)

细化问题:
-
包扫描时 com.jt 这样 controller 会不会被扫描到?
2.如何获取数据
业务:后台管理业务,商品分类查询
-
排序
2.不能使用通用Mapper
开发步骤:
-
创建 ItemCat.java+JPA 注解 pojo
package com.jt.manage.pojo;
import java.util.Date;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Table;
importcom.jt.common.po.BasePojo;
@Table(name="tb_item_cat")
public class ItemCat extends BasePojo{
/**
*
*/
private static final long serialVersionUID = -3043860998664994955L;
//类目ID
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
//父类目ID=0时,代表的是一级的类目
private Integer parentId;
//类目名称
private String name;
//状态。可选值:1(正常),2(删除)
private Integer status;
//排列序号,表示同级类目的展现次序,如数值相等则按名称次序排列。取值范围:大于零的整数
private Integer sortOrder;
//该类目是否为父类目,1为true,0为false
private Integer isParent;
//创建时间
private Date created;
//创建时间
private Date updated;
getSet方法。。。
}2、创建映射文件ItemCatMapper.xml,必须写SQL语句
3、创建接口ItemCatMapper.java
package com.jt.manage.mapper;
import java.util.List;
import com.jt.manage.pojo.ItemCat;
public interface ItemCatMapper {
/**
* 查询所有的商品
* @return
*/
public List findAll();
} 4、创建业务层接口ItemCatService和实现类ItemCatServiceImpl
package com.jt.manage.service;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.jt.common.service.BaseService;
import com.jt.manage.mapper.ItemCatMapper;
import com.jt.manage.pojo.ItemCat;
@Service
public class ItemCatServiceImpl extends BaseService implements ItemCatService{
@Autowired
private ItemCatMapper itemCatMapper;
/**
* 查询所有的商品
*/
public List findAll() {
return itemCatMapper.findAll();
}
} 5、创建控制层ItemCatController
package com.jt.manage.controller;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import com.jt.manage.pojo.ItemCat;
import com.jt.manage.service.ItemCatService;
@Controller
@RequestMapping("/item/cat")
public class ItemCatController {
@Autowired
private ItemCatService itemCatService;
@RequestMapping("/all")
@ResponseBody
public List findAll(){
List itemCatList = itemCatService.findAll();
return itemCatList;
}
} 6、直接访问测试
返回json
效果:

mysql分页
不同数据库是不同分页方式
Oracle 分页,虚拟列rownum,通过虚拟列实现分页
SqlServer 分页,top关键字 select top 5 from user
Mysql 分页,select * from user limit 10,20
10代表从第11条记录开始,20每页20条记录
引入PageHelper对象,PageInfo,共同封装分页值,使用mybatis拦截器
-
mybatis-config.xml配置插件
2.改造查询,在service不能直接使用返回列表
/**
* 查询所有的商品
*/
public List findAll(Integer page,Integer rows) {
//return itemCatMapper.findAll();
//分页支持,startPage方法是静态
//内部就调用拦截器,startPage相当于事务开启begin,开启分页操作
//它下面第一条的执行的查询的SQL语句
PageHelper.startPage(page, rows);
//第一条查询SQL被拦截,SQL语句拼接 limit page, rows
List itemCatList = itemCatMapper.findAll();
//返回值不能直接返回必须放在PageInfo对象中
//这里和线程安全有关!直接返回方式它会产生线程安全问题
//怎么解决?利用ThreadLocal,把当前对象和当前线程绑定,每个用户独立线程,
PageInfo pageInfo = new PageInfo(itemCatList);
return pageInfo.getList();
} 效果:

3. 分页参数,page查询哪页数据,rows每页条数
@RequestMapping("/all/{page}/{rows}")
@ResponseBody
public List findAll(@PathVariable Integer page,@PathVariable Integer rows){
List itemCatList = itemCatService.findAll(page,rows);
return itemCatList;
} 小结:
1.整个采用注解方式,JPA注解@Table,@Id,@GeneratedValue=”IDENTITY”自增主键 @Column配置全局setting驼峰规则就无需使用
在Service使用@Service
在Controller使用@Controller
2.使用包扫描方式:
a.pojo jpa注解通用Mapper
b.mapper接口,mybatis调用,spring和mybatis整合,扫描service,注入mapper,
c.service 包扫描@Service。@Controller没用
d.controller 包扫描@Controller
3.过程:
a.Pojo+JPA ItemCat.java
b.映射文件 ItemCatMapper.xml
c.映射接口 ItemCatMapper.java 位置=namespare.ItemCatMapper
d.实现类 ItemCatServiceImpl 注入ItemCatMapper,调用接口方法
e.接口ItemCatService 把实现所有方法声明
f.ItemCatController 注入ItemCatService,调用它的方法
4.配置文件加载过程
a.web.xml 配置DispatcherServlet决中文乱码过滤器filter servlet加载所有的
b.applicationContext*.xml spring框架文件都被加载,springmvc也被加载
c.applicationContext.xml spring核心配置文件,加载数据源,sqlSessionFactoryBean,事务,和mybaits整合
d.mybatis-config.xml 全局配置,插件:通用Mapper插件,分页插件
e.applicationContext-mvc.xml springmvc的整合配置文件,注解方式,包扫描,扫描所有的controller,内部资源视图解析:
prefix(/WEB-INF/views/)+logicName(userList)+suffix(.jsp)
在体系中创建pojo/mapper接口/service/controller都是spring bean,@Autowired这些注解对象都注入到对象当中
怎么访问?在controller中写入@RequestMapping(类/方法名称),用户在浏览器上敲入地址,去匹配系统中对于controller方法,把页面的参数封装到方法到参数中,方法调用service方法。
返回值:
-
普通常见方式,返回对象给jsp页面;Model把结果封装到model对象中,本质创建变量放入request中,转向Jsp页面,Jsp通过jstl标签吧把数据从request中获取。通过el表达式${name}
-
Ajax请求,返回json格式。返回就是业务操作完成数据List
,只要增加一个注解@ResponseBody,springmvc内部支持,它有这个注解标识,调用时自动把java对象转成string字符串,字符串格式json
分页插件
-
mybati-config.xml中声明插件,本质是一个拦截器。在你执行SQL时进行拦截,加上sql关键字 limit page,rows。执行完成后就是一个分页结果了。
-
注意:PageHelper对象,静态方法startPage(page,rows),标识它下面的第一个查询语句增加分页功能。startPage它只是标识开启,并没有实质执行。
-
业务执行查询,实际这个业务查询已经被拦截形成分页查询条件
-
返回值不能直接返回,必须封装到一个PageInfo对象中,为了高并发下线程安全,ThreadLocal
实现线程安全,它把数据没有共享,私有了?把每个请求的数据跟本地线程绑定,就不会线程数据共享,操作系统底层实现是线程各自的隔离的。
ThreadLocal它比加锁方式效率高。
5)PageInfo。Total可以获取页面总数,底层再次发出一个请求
Day03:京淘-导入页面, easyUl,实现商品列表查询
1.京淘架构重构

-
项目拆分
-
修改水平拆分方式
-
在/jt-manager-web/src/main/resources/spring/applicationContext-mvc.xml中添加放行静态资源
问题:
超级大型的项目才会 项目水平拆分.而且项目测试时需要频繁的打包,开发效率太低.
问题2.如果新建项目路径不全 怎么办?
解决办法:修改JDK即可.
2.项目重新构建
-
添加继承和依赖


2.添加tomcat插件
org.apache.tomcat.maven
tomcat7-maven-plugin
8091
/
3.配置tomcat插件启动项


启动测试:

写com.jt.manage.controller类实现index首页访问
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class IndexController {
@RequestMapping("/index")
public String index() {
return "index";
}
}效果:

2.EasyUI介绍
1.介绍


-
文件导入

 该文件寻贴主得
该文件寻贴主得
2.拖拽

打开jt-manages/src/main/webapp/easy-ui/easyui-1.html
-
导入js
2.编辑页面
拖动DIV
测试div
3.进度条
-
页面js
$(function(){
$("#b").click(function(){
onload();
})
/*采用递归的方法实现进度条刷新 */
var i = 0;
function onload(){
$('#p').progressbar({ value:i++});
if(i<=100){
/*js原生提供的函数,延时加载
参数1.延时加载的动作
参数2.延时加载的时间 单位毫秒
*/
setTimeout(function(){
onload();
}, 1)
}
}
})2.页面代码
4.弹出框
搜索
我是一个窗口
关闭
5.表格样式
总结:easyUI中如果需要进行表格数据的展现.则需要将返回值与属性的定义必须一一对应.
Code
Name
Price
回传JSON
-
写死的表格
-
Js动态的获取数据
-
通过js生成完整的表格
6.EasyUI-tree
EasyUI-树形结构
2.商品后台页面展现
-
布局技术
2.树形结构
- 商品管理
- 商品查询
- 商品新增
- 商品更新
- 内容管理
- 内容新增
3.选项卡技术
标签作用: 发起请求.用户页面展现
3.页面通用跳转
-
问题
说明:如果有一个页面请求需要在Controller中需要添加一个requstMapping方法.
新增商品
查询商品
规格参数 2.实现思路
说明:使用restFul结构实现页面的通用跳转
编辑Controller方法
//实现页面的通用跳转
@RequestMapping("/page/{moduleName}")
public String module(@PathVariable String moduleName){
return moduleName;
}4.商品列表展现
-
编辑pojo对象

2.页面请求分析
-
url

2.页面JS
data-options="singleSelect:false,collapsible:true,pagination:true,url:'/item/query',method:'get',pageSize:20,toolbar:toolbar">3.格式要求
说明:因为使用EasyUI的表格用于数据展现.所以返回的数据有特殊的格式要求.返回的数据的属性必须与页面中定义的属性一致,否则数据不能回显

4.封装对象
说明:根据EasyUI返回数据的要求,定义一个vo对象

5.编辑Controller
@Controller
@RequestMapping("/item")
public class ItemController {
@Autowired
private ItemService itemService;
//要求:/find/itemAll要求返回全部商品信息 要求根据修改时间排序
/* @RequestMapping("/find/itemAll")
@ResponseBody
public List- findItem(){
return itemService.findItemAll();
}*/
//http://localhost:8091/item/query?page=1&rows=50
//实现商品分页查询
@RequestMapping("/query")
@ResponseBody
public EasyUIResult findItemByPage(Integer page,Integer rows){
return itemService.findItemByPage(page,rows);
}
}
6.编辑Service
@Override
public EasyUIResult findItemByPage(Integer page, Integer rows) {
/**
* 通用Mapper 查询操作时 如果传入的数据不为null,则会充当where条件
* select count(*) from tb_item
* select * from tb_item limit 0,20
s select * from tb_item limit 20,20
s select * from tb_item limit 40,20
*/
int total = itemMapper.selectCount(null);
int start = (page - 1) * rows;
List- itemList = itemMapper.findItemByPage(start,rows);
EasyUIResult result = new EasyUIResult(total, itemList);
return result;
}
7.编辑Mapper接口
public interface ItemMapper extends SysMapper- {
List
- findItemAll();
/**
* mybatis中不允许多值传参,必须将多值封装为单值
* 1.封装为对象
* 2.封装为Map @Param()
* 3.封装为 array或者List
*
* $符:只有以字段名称为参数时才使用$.除此之外都是用#号因为有预编译的效果
* 防止sql注入攻击.
* 说明: 如果使用#号会给参数添加一对""号
* @param start
* @param rows
* @return
*/
@Select("select * from tb_item order by updated desc limit #{start},#{rows}")
List
- findItemByPage(@Param("start")int start,@Param("rows") int rows);
//暂时不写
}
8.页面效果

3.补充知识
-
关于log4j日志
说明:如果需要打印日志,则可以使用2中方式导入日志配置文件.
-
通过配置文件 导入log4j
-
默认的加载方式 要求必须在根目录中名称必须为log4j.properties

说明:在log4j代码中,通过static静态代码块的形式实现日志的加载.如果需要人为的修改配置文件,则需要单独的赋值.
2.PowerDesigner
-
PD介绍
PowerDesigner最初由Xiao-Yun Wang(王晓昀)在SDP Technologies公司开发完成。PowerDesigner是Sybase的企业建模和设计解决方案,采用模型驱动方法,将业务与IT结合起来,可帮助部署有效的企业体系架构,并为研发生命周期管理提供强大的分析与设计技术。PowerDesigner独具匠心地将多种标准数据建模技术(UML、业务流程建模以及市场领先的数据建模)集成一体,并与 .NET、WorkSpace、PowerBuilder、Java™、Eclipse 等主流开发平台集成起来,从而为传统的软件开发周期管理提供业务分析和规范的数据库设计解决方案。此外,它支持60多种关系数据库管理系统(RDBMS)/版本。PowerDesigner运行在Microsoft Windows平台上,并提供了Eclipse插件。 [1]
总结:
PD是现在企业中使用最广泛的数据库建模工具,可以以图形化界面的形式展现表与表之间的关系,同时可以根据数据库的版本,自动生成建表语句.
2.PD破解
赋值汉化文件,粘贴到PD安装的根目录即可



实现商品查询分页展示


格式要求说明:
因为使用EasyUI的表格用于数据展现,所以返回的数据有特殊的格式要求,返回的数据的属性必须与页面中定义的属性一致,
否则数据无法正常回显。

com.jt.common.vo.EasyUIResult类已做封装。

第一步:
创建com.jt.manage.pojo.Item实体类
package com.jt.manage.pojo;
@Table(name="tb_item")
public class Item {
//商品id,同时也是商品编号
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
//商品标题
private String title;
//商品卖点
private String sellPoint;
//商品价格,单位为:分
private long price;
//库存数量
private Integer num;
//商品条形码
private String barcode;
//商品图片
private String image;
//所属类目,叶子类目
private long cid;
//商品状态,1-正常,2-下架,3-删除
private Integer status;
//创建时间
private Date created;
//更新时间
private Date updated;第二步:
创建com.jt.manage.controller.ItemController类
/**
* 实现商品分页查询
* @param page
* @param rows
* @return
*/
@RequestMapping("/query")
@ResponseBody
public EasyUIResult finItemByPage(Integer page,Integer rows) {
return itemService.finItemByPage(page,rows);
}第三步:
创建com.jt.manage.service.ItemService接口
/**
* 实现商品分页查询
* @param page
* @param rows
* @return
*/
EasyUIResult finItemByPage(Integer page, Integer rows);/**
* 实现商品分页查询
*/
public EasyUIResult finItemByPage(Integer page, Integer rows) {
/**
* 通用Mapper查询操作时如果传入的数据不为null,则会充当where条件
*/
int total = itemMapper.selectCount(null);
int start = (page-1) * rows;
List- itemList = itemMapper.finItemByPage(start, rows);
EasyUIResult result = new EasyUIResult(total,itemList);
return result;
}
第四步:
创建ItemMapper接口并继承 SysMapper
/**
* 实现商品分页查询
* @param page
* @param rows
* @return
*/
@Select("select * from tb_item order by updated desc limit #{start},#{rows}")
List- finItemByPage(@Param("start") int start, @Param("rows") Integer rows);
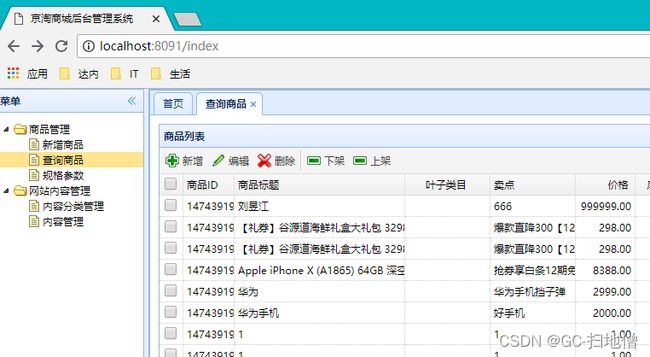
效果:
day04:京淘-后台系统实现上架下架
-
Maven项目构建
-
Maven配置文件
-
说明
-
-
Maven的级别有两种1,用户级别,该级别是默认级别.第二种是全局的配置.一般不生效.但是要求两种级别的配置文件必须相同,否则会有意想不到的异常.
同时.Maven/Nginx等重要的组件不要保存到C盘,因为有的电脑权限不够,导致程序无法运行.
操作:
在用户级别下和全局的Settings必须一致.

2.Maven配置文件介绍
1.本地仓库

2.私服镜像
采用达内的私服镜像
nexus
Tedu Maven
*
http://maven.tedu.cn/nexus/content/groups/public/
3.配置JDK
说明:Maven通过骨架创建项目时默认的JDK版本1.5,所以需要手动修改JDK,但是修改繁琐,所以添加如下的配置
jdk17
true
1.7
1.7
1.7
1.7
2.京淘商品维护
-
实现商品分类目录回显
-
案例
-
-
实现商品价格回显

2.实现商品时间回显

2.将商品分类目录回显
1.需求:将商品的分类的Id转化为具体的名称

2.JS文件
findItemName : function(val,row){
var name;
$.ajax({
type:"post",
url:"/item/cat/queryItemName",
data:{itemId:val},
cache:true, //缓存
async:false, //表示同步 默认的是异步的true
dataType:"text",
success:function(data){
name = data;
}
});
return name;
},3.编辑Controller
/**问题: @ResponseBody 为什么乱码????
*
* 1.如果回传数据是一个对象使用@ResponseBody 返回时默认以utf-8编码
* 2.如果回传字符串,则默认以iso-8859-1编码
*
* @param itemId
* @param response
* @throws IOException
*/
//实现商品分类目录的回显
@RequestMapping(value="/queryItemName",produces="text/html;charset=utf-8")
@ResponseBody
public String findItemCatNameById(Long itemId,HttpServletResponse response) throws IOException{
//String name = itemCatService.findNameById(itemId);
//response.setContentType("text/html;charset=utf-8");
//response.getWriter().write(name);
return itemCatService.findNameById(itemId);
}3.编辑Service
@Override
public String findNameById(Long itemId) {
return itemCatMapper.selectByPrimaryKey(itemId).getName();
}字段对应

效果:

2.商品分类目录实现
-
页面分析

2.js分析

2.数据封装格式
说明:如果需要使用Easy_uitree进行数据展现,则必须
-
Id 唯一标识节点信息
-
Text 节点信息的名称
-
state 节点是否打开/关闭
packagecom.jt.common.vo;
/**
* 为了封装EasyUI树形结构
* @author Administrator
*
*/
public class EasyUITree {
private Long id;
private String text;
private String state;
//get set toString方法
}3.树形结构展现格式要求
树控件读取URL。子节点的加载依赖于父节点的状态。当展开一个封闭的节点,如果节点没有加载子节点,它将会把节点id的值作为http请求参数并命名为'id',通过URL发送到服务器上面检索子节点。
4.编辑Controller
//http://localhost:8091/item/cat/list
/**
* @RequestParam(value="id",defaultValue="0",required=true)
* id表示接收参数的名称
* defaultValue 默认值
* required=true 该参数必须传递,否则SpringMVC校验报错.
* @param parentId
* @return
*/
@RequestMapping("/list")
@ResponseBody
public List findItemCat(@RequestParam(value="id",defaultValue="0")Long parentId){
//1.查询一级商品分类目录
//Long parentId = 0L;
return itemCatService.findItemCatByParentId(parentId);
} 5.编辑Service
/**
* 1.根据条件查询需要的结果 where parent_id = 0
* 2.需要将ItemCat集合转化为List
* 3.通过循环遍历的方式实现List赋值.
*
* state "open"/"closed"
*/
@Override
public List findItemCatByParentId(Long parentId) {
ItemCat itemCat = new ItemCat();
itemCat.setParentId(parentId);
//查询需要的结果
List itemCatList =
itemCatMapper.select(itemCat);
//2.创建返回集合对象
List treeList = new ArrayList();
//3.将集合进行转化
for (ItemCat itemCatTemp : itemCatList) {
EasyUITree easyUITree = new EasyUITree();
easyUITree.setId(itemCatTemp.getId());
easyUITree.setText(itemCatTemp.getName());
//如果是父级则暂时先关闭,用户需要时在展开
String state =
itemCatTemp.getIsParent() ? "closed" : "open";
easyUITree.setState(state);
treeList.add(easyUITree);
}
return treeList;
} 6.页面效果

3.商品新增
-
EasyUI校验
-
必填项
-
数字输入
2.商品新增的页面分析
-
js分析
$.post("/item/save",$("#itemAddForm").serialize(), function(data){
if(data.status == 200){
$.messager.alert('提示','新增商品成功!');
}else{
$.messager.alert("提示","新增商品失败!");
}
});
2.页面分析

3.编辑Controller
@RequestMapping("/save")
@ResponseBody
public SysResult saveItem(Item item){
try {
itemService.saveItem(item);
return SysResult.oK();
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201,"商品新增失败");
}
4.编辑Servic
@Override
public void saveItem(Item item) {
//需要补齐数据
item.setStatus(1); //表示商品上架
item.setCreated(new Date());
item.setUpdated(item.getCreated());
itemMapper.insert(item);
}
4.商品修改
-
页面分析
-
页面JS
$.post("/item/update",$("#itemeEditForm").serialize(), function(data){
if(data.status == 200){
$.messager.alert('提示','修改商品成功!','info',function(){
$("#itemEditWindow").window('close');
$("#itemList").datagrid("reload");
});
}else{
$.message.alert("提示",data.msg);
}
});
2.页面分析

2.编辑Controller
//商品修改
@RequestMapping("/update")
@ResponseBody
public SysResult updateItem(Item item){
try {
itemService.updateItem(item);
return SysResult.oK();
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201, "商品修改失败");
}
3.编辑Service
@Override
public void updateItem(Item item) {
//为数据赋值
item.setUpdated(new Date());
//表示动态更新操作. 只更新不为null的数据
itemMapper.updateByPrimaryKeySelective(item);
}
5.商品删除
-
页面分析
-
js分析
handler:function(){
var ids = getSelectionsIds();
if(ids.length == 0){
$.messager.alert('提示','未选中商品!');
return ;
}
$.messager.confirm('确认','确定删除ID为 '+ids+' 的商品吗?',function(r){
if (r){
var params = {"ids":ids};
$.post("/item/delete",params, function(data){
if(data.status == 200){
$.messager.alert('提示','删除商品成功!',undefined,function(){
$("#itemList").datagrid("reload");
});
}else{
$.messager.alert("提示",data.msg);
}
});
}
});
2.页面分析

2.编辑Controller
@RequestMapping("/delete")
@ResponseBody
public SysResult deleteItem(Long[] ids){
try {
itemService.deleteItems(ids);
//System.out.println("asdfasdf"); //效率太低
logger.info("{我是一个打桩日志}");
return SysResult.oK();
} catch (Exception e) {
//e.printStackTrace();
logger.error("!!!!!!!!!!!!!!!!!"+e.getMessage());
//logger.error("~~~~~~~~~~"+e.getMessage());
}
return SysResult.build(201, "商品删除失败");
}
3.编辑Service
@Override
public void deleteItems(Long[] ids) {
//根据主键删除
itemMapper.deleteByIDS(ids);
}
6.商品下架和上架
-
页面分析

2.编辑Controller
//实现商品上架 /item/reshelf
@RequestMapping("/reshelf")
@ResponseBody
public SysResult reshelf(Long[] ids){
try {
int status = 1; //商品上架
itemService.updateStatus(status,ids);
return SysResult.oK();
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201, "商品上架失败");
}
//商品下架 /item/instock
@RequestMapping("/instock")
@ResponseBody
public SysResult instock(Long[] ids){
try {
int status = 2; //商品下架
itemService.updateStatus(status,ids);
return SysResult.oK();
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201, "商品下架失败");
}
3.编辑Service
@Override
public void updateStatus(int status, Long[] ids) {
//update tb_item set status = #{status},updated = now() where id in (1,2,3,4,5)
itemMapper.updateStatus(status,ids);
}
4.编辑Mapper接口映射文件
void updateStatus(@Param("status")int status,@Param("ids")Long[] ids);
映射文件
update tb_item set status = #{status},updated = now() where
id in (
#{id}
)
day05: 京淘-描述表,图片上传, nginx反向代理
-
富文本编辑器
-
富文本编辑器介绍

-
页面展现
富文本编辑器入门案例
 该文件寻贴主得
该文件寻贴主得

2.富文本编辑器使用
说明:富文本编辑器其实获取的就是页面中的HTMl代码.并且可以直接解析编译.但是一般只获取静态的资源数据.在进行入库操作时 ,也保存的是html信息.

2.实现商品描述新增
-
定义POJO对象

2.定义Mapper接口
public interface ItemDescMapper extends SysMapper{
}
3.编辑Controller
@RequestMapping("/save")
@ResponseBody
public SysResult saveItem(Item item,String desc){
try {
itemService.saveItem(item,desc);
return SysResult.oK();
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201,"商品新增失败");
}
4.编辑Service
@Override
public void saveItem(Item item,String desc) {
//需要补齐数据
item.setStatus(1); //表示商品上架
item.setCreated(new Date());
item.setUpdated(item.getCreated());
itemMapper.insert(item);
//SELECT LAST_INSERT_ID() 获取当前线程内Id的最大值
ItemDesc itemDesc = new ItemDesc();
System.out.println(item.getId());
itemDesc.setItemId(item.getId()); //?????有数据吗???
itemDesc.setItemDesc(desc);
itemDesc.setCreated(item.getCreated());
itemDesc.setUpdated(item.getCreated());
itemDescMapper.insert(itemDesc);
}
3.商品描述回显
-
页面分析
$.getJSON('/item/query/item/desc/'+data.id,function(_data){
if(_data.status == 200){
//UM.getEditor('itemeEditDescEditor').setContent(_data.data.itemDesc, false);
itemEditEditor.html(_data.data.itemDesc);
}
});
2.编辑Controller
//实现商品描述信息回显
@RequestMapping("/query/item/desc/{itemId}")
@ResponseBody
public SysResult findItemDescById(@PathVariable Long itemId){
try {
ItemDesc itemDesc = itemService.findItemDesc(itemId);
return SysResult.oK(itemDesc);
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201, "商品详情查询失败");
}
3.编辑Service
//根据itemId查询商品详情信息
@Override
public ItemDesc findItemDesc(Long itemId) {
return itemDescMapper.selectByPrimaryKey(itemId);
}
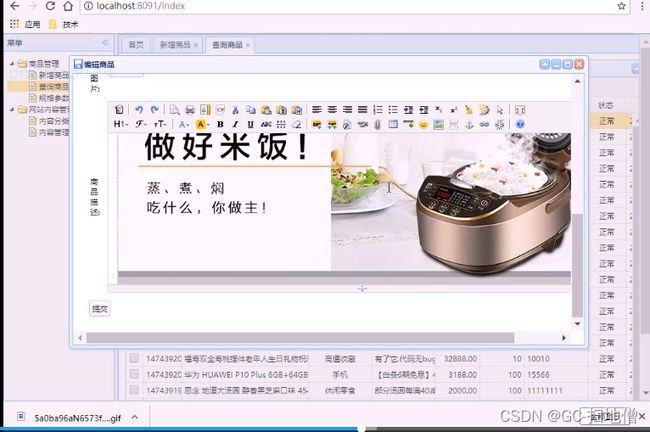
效果点击编辑页面出现效果
4.商品详情修改
-
编辑Controlelr
//商品修改
@RequestMapping("/update")
@ResponseBody
public SysResult updateItem(Item item,String desc){
try {
itemService.updateItem(item,desc);
return SysResult.oK();
} catch (Exception e) {
e.printStackTrace();
}
return SysResult.build(201, "商品修改失败");
}
2.编辑Service
@Override
public void updateItem(Item item,String desc) {
//为数据赋值
item.setUpdated(new Date());
//表示动态更新操作. 只更新不为null的数据
itemMapper.updateByPrimaryKeySelective(item);
//商品描述信息更新
ItemDesc itemDesc= new ItemDesc();
itemDesc.setItemDesc(desc);
itemDesc.setItemId(item.getId());
itemDesc.setUpdated(item.getUpdated());
itemDescMapper.updateByPrimaryKeySelective(itemDesc);
}
5.商品详情删除
-
编辑Service
说明:商品删除需要同时删除2张表数据 tb_item和tb_item_desc表
@Override
public void deleteItems(Long[] ids) {
//根据主键删除
itemMapper.deleteByIDS(ids);
itemDescMapper.deleteByIDS(ids);
}
2.文件上传实现
-
文件上传入门案例
-
配置文件上传视图解析器
在spring/applicationContext-mvc.xml配置文件上传视图解析器
2.定义文件上传form表单
文件上传入门案例
3.通过解析器实现文件上传
package com.jt.manage.controller;
import java.io.File;
import java.io.IOException;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.multipart.MultipartFile;
@Controller
public class FileController {
/**
* 要求文件上传完成后,再次跳转到文件长传页面
* 参数一定要与提交参数保持一致
* @return
* @throws IOException
* @throws IllegalStateException
*/
@RequestMapping
private String file(MultipartFile file) throws IllegalStateException, IOException{
//准备文件上传的路径
String path = "E:/jt-upload";
//判断文件夹是否存在
File filePath = new File(path);
if(!filePath.exists()){
//如果文件夹不存在,需要创建一个文件夹
filePath.mkdirs();
}
//获取文件名称 abc.jpg
String fileName = file.getOriginalFilename();
//实现文件上传 E:/jt-upload/
file.transferTo(new File(path+"/"+fileName));
return "redirect:/file.jsp";
}
2.商品图片上传
-
页面分析


2.定义返回值对象
{"error":0,"url":"图片的保存路径","width":图片的宽度,"height":图片的高度}
packagecom.jt.common.vo;
public class PicUploadResult {
private Integer error=0; //图片上传错误不能抛出,抛出就无法进行jsp页面回调,所以设置这个标识,0表示无异常,1代表异常
private String url;
private String width;
private String height;
//get set 方法
}
3.实现Service数据动态赋值
说明:根据规则,动态获取本地磁盘路径和虚拟路径,方便以后修改.
-
编辑properties
#定义本地磁盘路径
image.localPath = E:/jt-upload/
#定义虚拟路径
image.urlPath = http://image.jt.com/
2.编辑service

4.编辑Controller
编辑Controller
//实现商品的文件上传
@RequestMapping("/pic/upload")
@ResponseBody
public PicUploadResult uploadFile(MultipartFile uploadFile){
return fileService.upload(uploadFile);
}
5.编辑Service
@Service
public class FileServiceImpl implements FileService {
//要求参数应该动态获取???
//定义文件存储的根目录
@Value("${image.localPath}") //通过注解的方式 为属性动态赋值
private String localPath; //= "E:/jt-upload/";
//定义虚拟路径的根目录
@Value("${image.urlPath}")
private String urlPath; //="http://image.jt.com/";
/**
* 问题:
* 1.是否为正确的图片??? jpg|png|gif
* 2.是否为恶意程序???
* 3.不能将图片保存到同一个文件夹下
* 4.图片的重名问题
* 解决策略:
* 1.正则表达式实现图片的判断.
* 2.使用BufferedImage转化图片 height/weight
* 3.使用分文件夹存储 yyyy/MM/dd 并不是唯一的
* 4.UUID+三位随机数区分图片
*/
@Override
public PicUploadResult upload(MultipartFile uploadFile) {
PicUploadResult result = new PicUploadResult();
//1.获取图片的名称 abc.jpg
String fileName = uploadFile.getOriginalFilename();
fileName = fileName.toLowerCase();
//2.判断是否为图片的类型
if(!fileName.matches("^.*(jpg|png|gif)$")){
result.setError(1); //表示不是图片
}
//3.判断是否为恶意程序
try {
BufferedImage bufferedImage =
ImageIO.read(uploadFile.getInputStream());
int height = bufferedImage.getHeight();
int width = bufferedImage.getWidth();
if(height == 0 || width == 0){
result.setError(1);
return result;
}
//4.将图片分文件存储 yyyy/MM-dd
String DatePath =
new SimpleDateFormat("yyyy/MM/dd").format(new Date());
//判断是否有该文件夹 E:/jt-upload/2018/11/11
String picDir = localPath + DatePath;
File picFile = new File(picDir);
if(!picFile.exists()){
picFile.mkdirs();
}
//防止文件重名
String uuid = UUID.randomUUID().toString().replace("-", "");
int randomNum = new Random().nextInt(1000);
//.jpg
String fileType = fileName.substring(fileName.lastIndexOf("."));
//拼接文件的名称
String fileNowName = uuid + randomNum + fileType;
//实现文件上传 e:jt-upload/yyyy/MM/dd/1231231231231231231.jpg
String realFilePath = picDir + "/" +fileNowName;
uploadFile.transferTo(new File(realFilePath));
//将真实数据回显
result.setHeight(height+"");
result.setWidth(width+"");
/**
* 实现虚拟路径的拼接
* E:/jt-upload/2018/07/23/e4d5c2667a174477b2ab59158670bbbe816.jpg
* image.jt.com
*/
String realUrl = urlPath + DatePath + "/" + fileNowName;
result.setUrl(realUrl);
} catch (Exception e) {
e.printStackTrace();
result.setError(1); //文件长传有误
}
return result;
}
}
3.Nginx
-
需求
-
需求分析
说明:应该当用户访问image.jt.com时,应该将我们请求的路径转向到本地磁盘E:/jt-upload
真实的磁盘路径:
E:/jt-upload/2018/07/23/e4d5c2667a174477b2ab59158670bbbe816.jpg
虚拟路径:
Http://image.jt.com/2018/07/23/e4d5c2667a174477b2ab59158670bbbe816.jpg
2.请求实现-Nginx反向代理

调用过程说明:
-
当用户访问数据时,发出请求image.jt.com/1.jpg被Nginx所拦截(监听器方式)
-
之后nginx在内部将请求转化为E:/jt-upload/1.jpg.请求真实的服务器
-
Nginx请求真实的图片消息后.将返回的结果返回给客户端
2.Nginx介绍
-
Nginx介绍
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。
Nginx是一款轻量级的 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
Nginx并发能力:50000次并发/s 真实数据 2-3万之间
2.Nginx下载

说明:将Nginx保存到本地磁盘下 不要放到C盘下和中文路径下.
3.Nginx启动
注意:首先第一次使用时,使用超级管理员权限运行.
说明:Nginx底层是C语言开发的.当以超级管理员权限运行时,会快速的执行,并且在操作系统中开启2个进程.

关于进程说明:
一个是主进程:主要提供Nginx服务
一个是守护进程:防止主进程意外关闭的.如果主进程意外关闭了,则再次启动主进程.
所以关闭nginx的进程应该先关闭守护进程(内存占用少的),之后关闭主进程(内存占用多的)
2.关于Nginx的命令
启动Nginx: start nginx
关闭Nginx: nginx -s stop
重启Nginx: nginx -s reload
注意事项:Nginx的命令的执行必须在Nginx的根目录下执行.

3.Nginx实现反向代理
-
Nginx实现默认跳转
说明:当用户访问localhost:80时,默认跳转的是Nginx首页

问题:如何实现该操作的??
案例分析:
server {
#默认监听80端口
listen 80;
#拦截的请求路径
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
#root表示 将请求转向到具体的文件夹中
root html;
#index 表示默认的访问页面
index index.html index.htm;
}
}
4.Nginx实现图片信息回显
-
编辑Nginx配置文件
#图片服务器
server {
listen 80;
server_name image.jt.com;
location / {
root H:\jt-upload;
}
}
修改完成后,将Nginx重启
2.编辑HOST文件
说明:让image.jt.com访问时,必须访问本机,才能被Nginx所拦截,实现方向代理技术.
# 京淘电商环境
127.0.0.1 image.jt.com
127.0.0.1 manage.jt.com
127.0.0.1 www.jt.com
127.0.0.1 sso.jt.com
127.0.0.1 cart.jt.com
127.0.0.1 order.jt.com
127.0.0.1 solr.jt.com

3.页面效果

day06:京淘-Tomcat集群, Nginx负载均衡,Linux部署
-
Nginx高级
-
Nginx反向代理
-
实现请求路径的代理
要求:
当用户访问manage.jt.com时访问的是localhost:8091
配置文件:
#定义后台管理系统
server {
listen 80;
server_name manage.jt.com;
location / {
proxy_pass http://localhost:8091;
}
}
说明:修改完成后,需要重启Nginx
3个选中clean

右键打包

查看打包路径:

拿到war包复制到tomcat中并改明为ROOT.war

启动tomcat查看效果:

2.页面效果

2.Tomcat集群部署
-
Tomcat服务器搭建
-
准备tomcat服务器
说明:将课前资料中的tomcat导入到本机,支行修改配置文件
-
修改8005端口

2.修改服务端口

3.修改AJP端口

2.发布项目
说明:将项目分别进行打包.打包的顺序jt-parent/jt-common/jt-manage.之后将包名修改为ROOT.war,分别部署到3台tomcat中.最终实现
Localhost:8091
Localhost:8092
Localhost:8093
正常范文京淘后台即可


2.Nginx实现负载均衡
-
轮询
说明:
根据配置文件的顺序,依次访问配置的服务器.达到负载均衡的效果,该配置是Nginx默认的策略.
Nginx配置:
#配置nginx负载均衡 1.轮询
upstream jt {
server localhost:8091;
server localhost:8092;
server localhost:8093;
}
#定义后台管理系统
server {
listen 80;
server_name manage.jt.com;
location / {
proxy_pass http://jt;
}
}
修改完成后重启Nginx
效果:
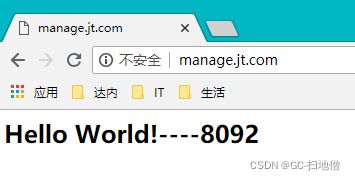
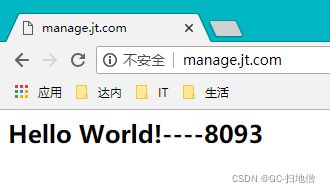
2.权重
说明:根据服务器的性能,让高性能服务器尽量处理多的请求,使用权重的配置.使用weight关键字
#配置nginx负载均衡 1.轮询 2.权重
upstream jt {
server localhost:8091 weight=6;
server localhost:8092 weight=3;
server localhost:8093 weight=1;
}
3.IP_hash(了解)
问题描述:采用集群的部署后,如何实现单点登录是一个典型的问题.因为用户登陆后,需要将用户信息保存到Session中,但是不同的服务器Session不能共享.所以无法实现用户只登陆一次,其他免密登录的效果.
解决方案:
可以通过IP_hash配置,使用用户单点登录,用户访问服务器时,将IP地址经过计算.之后绑定到特定到某一台服务器上,从而实现了单点登录效果.
补充说明:
如果配置IP_hash,那么配置的权重和轮询将不起作用.
风险:
不安全.
4.项目上线的步骤
-
修改Nginx,将需要上线的机器先做下线处理.
-
之后将无服务停止,之后将包进行部署.
-
将服务器启动,启动后先经过测试人员测试
-
如果测试没有问题,则将tomcat上线.部署后续的项目.
问题:
如果nginx在重启过程中,用户发起请求,那么用户访问是否受限???
说明:
Nginx的启动和重启是非常快速的几乎可以实现秒开秒关.
5.Nginx中备用机机制
说明:
在一般的情况下,服务器会配置备用机,该机器正常的情况下,不会处理请求,只有在主服务遇忙时或者主机宕机时,才会访问备用机.
#配置nginx负载均衡 1.轮询 2.备用机
upstream jt {
#实现ip_hash
#ip_hash;
server localhost:8091 weight=6 down;
server localhost:8092 weight=3 down;
server localhost:8093 weight=1 backup;
}
6.Nginx健康检测(基本高可用)
问题:如果服务器出现意外的宕机现象,这时nginx访问会出现问题.
解决方案:
Nginx内部有自己的健康检测机制,在指定的检测周期内,如果发现后台服务器出现宕机的现象.那么在该周期内不会再将请求发往该机器.直到下一个检测周期时,才会再次检查服务器是否宕机,如果依然宕机,则该周期内不会发请求给故障机.
最终实现了tomcat服务器宕机后,自动的实现了故障的迁移.
配置文件介绍:
server localhost:8091 max_fails=1 fail_timeout=300s;
最大的失败的次数允许1次.如果出现宕机那么在60秒内,不会再将请求发往该机器.
Nginx健康检查配置
#配置nginx负载均衡 1.轮询 2.权重
upstream jt {
#实现ip_hash
#ip_hash;
#健康检测 失败的次数允许1次.如果出现宕机那么在60秒内,不会再将请求发往该机器
server localhost:8091 max_fails=1 fail_timeout=60s;
server localhost:8092 max_fails=1 fail_timeout=60s;
server localhost:8093 weight=1 backup;
}
#定义后台管理系统
server {
listen 80;
server_name manage.jt.com;
location / {
proxy_pass http://jt;
#代理连接超时
proxy_connect_timeout 3;
#代理读取超时
proxy_read_timeout 3;
#代理发送超时
proxy_send_timeout 3;
}
}
3.项目Linux部署
-
虚拟机搭建
-
网卡介绍

NAT1:
选择网络模式为仅主机时使用的网络配置
NAT8:
选择网络模式为NAT模式时的网络的配置

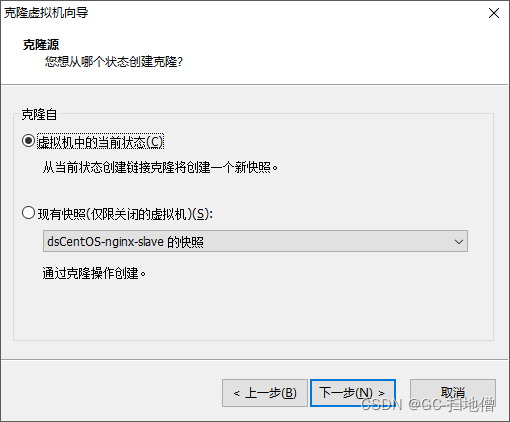
2.克隆虚拟机
-
选择克隆的状态
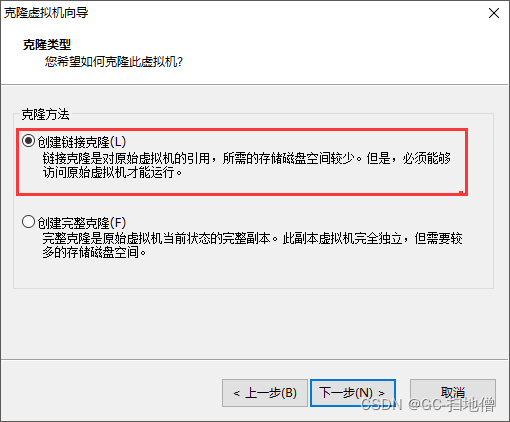
2.选择链接
3.选择路径

3.虚拟机的网络模式
-
桥接模式

让虚拟机Linux操作系统直接接入当前所在的局域网中.简单的方式
特点:
-
相互的通信必须基于交换机/路由器
-
连入局域网的设备可以被其他人访问. Root/root
2.NAT模式
在自己的电脑重新开辟了一块局域网(私网空间192.168).该网络只能允许本机访问,其他的机器不允许访问.
4.虚拟机快照
说明:通过虚拟机启动的操作系统有时由于误操作,可能导致不可逆转的情况,这时通过虚拟机快照的方式恢复现场数据.


5.指定虚拟机IP地
说明:根据自己虚拟机的IP设定为静态IP地址.


6.XShell连接Linux操作系统

连接成功
2.安装JDK部署
-
安装JDK
-
导入安装文件

2.解压JDK
tar -xvf jdk-7u51-linux-x64.tar.gz
3.配置环境变量
3.1复制JDK的根目录
/usr/local/src/java/jdk1.7.0_51
3.2配置JDK的环境变量
vim /etc/profile

4. 让JDK的配置立即生效
source /etc/profile
5.检测JDK安装是否成功

3.部署tomcat
-
上传tomcat安装包
说明:将文件上传后,解压该文件

2.复制多台tomcat
更改文件名:
mv apache-tomcat-7.0.55 tomcat-8091
拷贝:
cp -r tomcat-8091 tomcat-8092

3.修改配置文件

说明:修改tomcat 8005/8080/8009端口

4.启动tomcat
说明:在bin文件夹执行启动命令
sh startup.sh 启动tomcat
sh shutdown.sh 停止tomcat

通过日志检查启动是否成功

5.关闭防火墙

6.虚拟机网络通信规则
1.检查网络通讯的IP地址

2.网络通讯的规则

3.修改JDBC的连接

修改完成后,将项目打包.

7.部署war包
说明:
-
将tomcat关闭

2.将原有的ROOT文件夹删除

3.部署war包

8. 关于Mysql对外访问权限问题
说明:
Mysql中要求,本机访问不需要任何的权限.但是如果是跨系统之间的访问,那么必须开启访问权限.
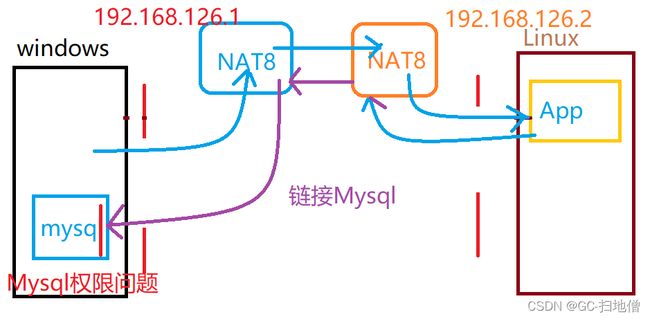
语法:
grant [权限] on [数据库名].[表名] to ['用户名']@['web服务器的ip地址'] identified by ['密码'];
grant all on *.* to 'root'@'%' identified by 'root';
或者指定IP地址
grant all on *.* to 'root'@'192.168.1.103' identified by 'root';

问题的总结:
如果出现数据访问问题:
-
关闭window和linux的防火墙
-
开放mysql对外访问权限.
9.作业:
要求:实现Linux端tomcat的负载均衡.

提示:
修改Nginx配置文件

day07:京淘-数据庄主从复制amoeba读写分离
-
JDK版本统一
-
修改JDK
-
eclipse环境JDK

2.windos环境

3.settings环境配置
将JDK1.7改为1.8后更新maven
jdk18
true
1.8
1.8
1.8
1.8

2.数据库高可用
-
数据备份
-
冷备份
说明:定期将数据库文件进行转储.
缺点:
-
数据库冷备份,则需要手动的人工完成.效率低
-
定期数据备份,不能保证数据的安全的.仅仅能够恢复部分数据.
-
如果数据量比较庞大,导入导出时耗费的时间较多.
-
由于网络传输问题.可能会导致备份多次.
说明:
数据库冷备份,是恢复数据的最后有效的手段.
2.热备份
说明:当主数据库中的数据发生”更新”操作时,数据会自动的同步到slave(从数据库中).该操作可以实现实时备份.

备份步骤:
-
当主库数据发生改变时,会将更新的消息实时的写入二进制日志文件中.
-
从库需要实时的监控主库的二进制日志文件,如果出现更新操作,那么通过IOThread读取更新的内容,将数据写入中继日志中.
-
从库开启SqlThread实时的读取中继日志中的内容,实现从库数据的同步.
-
最终实现主库和从库的数据的实时备份.
2.数据库安装
-
准备工作
说明:克隆新的虚拟机后,将IP地址设置为固定IP

2.上传mysql安装文件
说明:
1.将mysql安装文件上传到指定了文件夹下

2.将mysql安装文件解压
tar -xvf Percona-Server-5.6.24-72.2-r8d0f85b-el6-x86_64-bundle.tar

3.安装mysql数据库
说明:安装的顺序
-
debuginfo 2. Shared 3.client 4.server
命令:
rpm -ivh Percona-Server-56-debuginfo-5.6.24-rel72.2.el6.x86_64.rpm
安装步骤:
1.

2.安装shard
rpm -ivh Percona-Server-shared-56-5.6.24-rel72.2.el6.x86_64.rpm

3.安装client客户端
rpm -ivh Percona-Server-client-56-5.6.24-rel72.2.el6.x86_64.rpm
4.安装数据库服务
rpm -ivh Percona-Server-server-56-5.6.24-rel72.2.el6.x86_64.rpm
4.启动mysql数据库
-
导入sql文件

2.启动mysql服务项
service mysql start 启动命令
service mysql stop 停止命令
service mysql restart 重启命令
启动成功:

3.设定mysql用户名和密码
mysqladmin -u root password root

4.导入 jt 数据库
Mysql 客户端中 :source jt.sql;
或者 source /usr/local/src/mysql/jt.sql;
 检测数据库是否存在
检测数据库是否存在
 5.mysql 远程访问
5.mysql 远程访问
-
关闭防火墙
service iptables stop
 2.开放 mysql 对外访问权限
2.开放 mysql 对外访问权限
grant all on *.* to 'root'@'%' identified by 'root';

3.远程连接 mysql
5.搭建从库
2.实现主从搭建
-
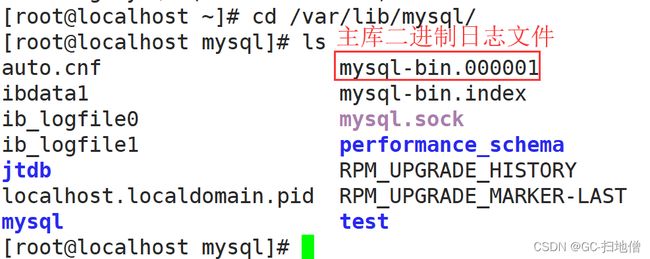
配置主库二进制文件
说明 : 主库的二进制文件默认的是关闭的 . 需要手动开启日志文件
编辑文件 :
vim /etc/my.cnf
配置文件介绍:
数据库文件存储的位置
datadir=/var/lib/mysql
编辑配置文件
说明 : 每个 mysql 数据库的服务的 Id 号应该不同

server-id=1
log-bin=mysql-bin
重启mysql服务:
service mysql restart
 检测日志文件是否启动
检测日志文件是否启动
cd /var/lib/mysql/
ls
2.修改从库的配置文件
 之后重启数据库 . 检测配置文件是否生效
之后重启数据库 . 检测配置文件是否生效

3.关于数据库报错问题
-
my.cnf 文件编辑错误

2.PID或者socket报错
杀死进行后需要将 mysql 服务重启 service mysql start

4.mysql序列号
cat auto.cnf

4.实现数据库主从挂载
-
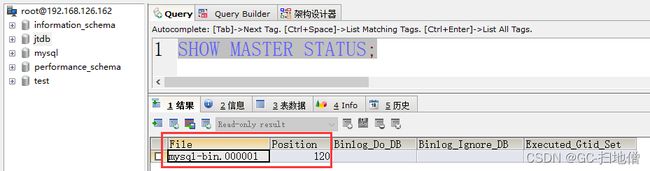
需要检测主库的状态
 2.实现主从的挂载
2.实现主从的挂载
#需要将从库挂载到主库时 ip/端口/用户名/密码/二进制文件名称/二进制文件位置
change MASTER to MASTER_HOST="192.168.126.162",
MASTER_PORT=3306,
MASTER_user="root",
MASTER_PASSWORD="root",
MASTER_LOG_FILE="mysql-bin.000001",
MASTER_LOG_POS=120
#启动主从服务
start slave
#检测主从的状态
show SLAVE status
#重新挂载 1.关闭主从服务 挂载 启动主从服务 检测状态
stop slave
3.检测从库状态

4.主从测试
修改mysql主库后,检测从库是否同步.
5.关于克隆数据库中问题
说明:由于可控的数据库中auto.cnf文件相同,导致主从挂载失败.需要修改序列号.
select UUID();
5ddea06c-8fd7-11e8-ab4d-000c29a792ac

3.数据库读写分析
-
读写分离
-
说明
-
设定读写分离的策略.1主1从
-
指定具体的代理服务器(Amoeba/mycat)
2.Amoeba介绍
Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy。它集中地响应应用的请求,依据用户事先设置的规则,将SQL请求发送到特定的数据库上执行。基于此可以实现负载均衡、读写分离、高可用性等需求。与MySQL官方的MySQL Proxy相比,作者强调的是amoeba配置的方便(基于XML的配置文件,用SQLJEP语法书写规则,比基于lua脚本的MySQL Proxy简单)。
Amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。用户需要结合使用MySQL的 Replication等机制来实现副本同步等功能。amoeba对底层数据库连接管理和路由实现也采用了可插拨的机制,第三方可以开发更高级的策略类来替代作者的实现。这个程序总体上比较符合KISS原则的思想。
补充说明:
Amoeba阿里开源的项目,现在已经停止维护更新了.Amoeba开发时使用JDK1.7

2.Amoeba搭建
-
安装JDK1.8

2.让JDK生效
source /etc/profile
3.检测JDK是否有效

2.安装Amoeba
1.上传安装文件

2.修改文件名称

3.修改dbServer.xml文件
 该文件寻贴主得
该文件寻贴主得
3.修改链接mysql用户名和密码

2.修改主库的IP

3.配置数据库链接

4.修改Amoeba.xml
 该文件寻贴主得
该文件寻贴主得
1.Amoeba端口号

2.定义用户名和密码

3.定义读写策略

5.修改JDK内存
JVM_OPTIONS="-server -Xms256m -Xmx1024m -Xss196k -XX:PermSize=16m -XX:MaxPermSize=96m"
参数说明:
-Xms256m 代表初始化内存.
-Xmx1024m 最大内存
-Xss196k 每个线程占用空间的大小

6.Amoeba读写分离测试
-
启动服务
./launcher


./shutdown

-
测试服务
JDBC:链接代理服务器

测试负载均衡:
修改从库title中的数据.测试成功后,将数据改为一致

3.作业
通过windos中的nginx实现链接Linux中tomcat.
要求Linux中的tomcat链接代理服务器.
切记服务器挂起,不要关机.
day08: 京淘-数据库双机热备Mycat读,写分离
-
Mysql搭建错误集合
-
Mysql服务启动问题
说明:如果mysql启动报错,不能正常的启动,则检查my.cnf文件
1

2.手动的删除日志文件,之后重启mysql

3.删除mysql进程

2.关于mysql关机启动
说明:
如果mysql意外关机,那么重启时需要注意一下的步骤
-
关闭防火墙
-
启动主库服务 service mysql start
-
启动从库服务
-
关于Nginx报错
502
说明:一定是开启了多个nginx导致报错
解决:先关闭所有的Nginx 通过管理器关闭
504:
链接超时.后台的tomcat链接不通.
-
tomcat启动不正常
-
链接tomcat防火墙没关.
-
Nginx配置文件的IP地址写错了.
2.Mysql实现高可用
-
数据库主从问题
-
说明
如果数据库搭建主从的配置,可以实现数据的实时备份.但是如果主数据库如果出现宕机现象.则整个服务都会陷入瘫痪.(雪崩效应)
2.数据库双机热备
-
双机热备的说明
说明:
采用双机热备的形式,如果主库发生宕机现象,那么通过代理服务器访问从库,使得服务可以正常执行.当主库修复完成后,启动时会从另一台mysql数据库中实时的同步数据,从而实现数据的一致性.
2.搭建步骤
主机A:192.168.126.162
从机B:192.168.126.163
昨天:A向B同步数据
今天:B向A同步数据
注意事项:数据同步时不会写入二进制.只有当用户使用sql操作数据库时,才会将数据写入二进制日志文件中.
-
检测B库的状态

2.实现数据库挂载
#实现数据库主从挂载
change MASTER to MASTER_HOST="192.168.126.163",
MASTER_PORT=3306,
MASTER_USER="root",
MASTER_PASSWORD="root",
MASTER_LOG_FILE="mysql-bin.000001",
MASTER_LOG_POS=452
#启动主从服务
start SLAVE
#检测主从状态
show SLAVE status

3.Mycat
-
说明:
说明:各个数据库之间开发时都是基于sql92标准.
不同的:
Mysql:分页 limit
Oracle: rows


4.Mycat搭建
说明:开发Mycat时使用JDK1.7版本.
启动:
./mycat start
关闭:
./mycat stop
重启:
./mycat restart
检查状态信息
./mycat status

表示启动成功

-
关闭Amoeba

2.解压Mycat

3.Usr/local/src/mycat/conf/ 修改server.xml

4.修改schema.xml
select 1
5.Mycat启动
命令:
./mycat start
./mycat stop
./mycat restart

6.检测服务是否启动
命令:
cd ../logs/
ls
cat wrapper.log

7.测试
将主库关闭后,检查程序是否正确执行,之后将主库启动后,检测数据是否同步

service mysql stop 使主库宕机
进行测试
更改数据:

查看从库数据:

service mysql state 启动主机
查看数据

说明实现了主从复制
关于mycat分库分表(面试问题)
-
名称介绍
1.逻辑库
MYCAT中对数据库进行拆分时,指定的数据库的名称,将来需要通过jdbc连接时,必须要与逻辑库的名称一致.
2.逻辑表
3.数据库的垂直拆分
4.数据库的水平拆分
2.数据库垂直拆分
说明:根据业务逻辑,将不同的功能模块的表进行拆分,拆分到多个数据库中,并且具有相同的业务逻辑的表最好保存到一个数据库中.为了关联查询.

3.数据库的水平拆分
说明:由于单表的数据量特别的庞大,直接影响查询效率,所以需要进行分表操作.
根据特定的规则(人为定义),将数据拆分到不同的数据库中,之后查询时根据特定的协议规则,进行数据的查询.

4.数据库如何优化(面试题)
-
优化sql 思想:首先快速定位主表信息
-
创建索引 不经常修改的数据
-
数据库缓存 mybatis中----redis缓存
-
定期进行数据转储 当前表和历史表(减少数据表的量)
-
分库分表(大型项目才会使用)
3.Redis
-
缓存策略
说明:缓存的主要的作用,就是降低用户访问物理设备的访问频次.并且缓存中的数据就是数据库中的数据备份.
2.Redis介绍
-
网站介绍
官网:Redis

2.Redis介绍
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis中存储数据采用K-v结构
Redis底层实现时C语言编辑.并且查询的速度30万/s集合运算
3.Redis下载
说明:官方建议下载redisLinux版本

4.缓存使用的注意事项
-
缓存中的数据和数据库如何保证数据一致性??
-
缓存中的数据如何持久化??
-
缓存中的内存空间应该如何维护??
-
单个缓存节点有宕机风险,如何实现高可用??
总结:以上的问题使用Redis可以全部解决.
3.Redis安装
-
安装redis
-
解压redis
2.编译redis
执行make
3.配置环境变量
make install
2.Redis命令
-
redis-server
-
redis-server &
-
redis-server redis.conf 启动
-
关闭redis命令 redis-cli shutdown
-
redis-cli -p 6379 shutdown

启动ok

3.编辑redis配置文件vim redis.conf
-
注释IP绑定

2.关闭保护模式

3.开启后台启动

4.Redis命令
redis-cli:进入客户端
-
Redis-String
指令
说明
案例
set
设定key的值
set name tom
get
获取指定 key 的值
get name
strlen
获取key值的长度
strlen name
exists
检查给定 key 是否存在
exists name 返回1存在 0不存在
del
删除指定的key/key1 key2
del name1 name2
keys
命令用于查找所有符合给定模式 pattern 的 key
Keys * 查询全部的key值
Keys n?me 占位符
Keys name* 以name开头的key
mset
赋值多个key-value
mset key1 value1 key2 value2 key3 value3
同时赋值多个值
mget
获取多个key
Mget key1 key2 key3
append
对指定的key进行追加
append key 123456 value123456
append key " 123456" value 123456中间多一个空格
Type
查看key的类型
Type key1
127.0.0.1:6379> TYPE key1string
Flushdb
清空当前数据库
Flushdb 清空数据库
Select
切换数据库
Select 0-15 redis一共有16个数据库
FLUSHALL
清空全部数据库数据
flushall
Incr
自动增长1
Incr num 数据会自动加1
Incr string 数据库会报错
Decr
自动减1
Decr name 数据会自动减1
incrby
指定步长自增
Incrby 2 每次自增2
Decrby
指定步长自减
Decrby 2每次减2
Expire
指定key的失效时间单位是秒(s)
EXPIRE name1 5 5秒后数据失效
Ttl
查看key的剩余存活时间
Ttl name
-2表示失效
-1没有失效时间
Pexpire
设置失效时间(毫秒)
Pexpire name 1000 用于秒杀业务
Persist
撤销失效时间
撤销失效时间
2.电商中秒杀如何实现???
使用操作:
1.设定失效时间
2.准备消息队列

实现原理:
1.在后台需要将出售的商品根据数量添加到消息队列中
2.当用户点击购买按钮时,首先通过后台服务器获取redis中key.如果该值不为null.则可以执行后续业务逻辑.如果该值为空.则返回商品已售完信息.
3.如果获取key不为null,那么则获取消息队列中的信息.如果获取的数据不为null.证明该用户可以购买商品,之后跳转订单页面
如果获取队列消息为null.表示商品已经售完,则跳转回用户页面,显示商品已售完.
补充知识:
问题:redis中如何解决线程安全性问题????
说明:因为redis操作是原子性操作,所以不会有线程安全性问题.
3.作业:
1.将数据库切换为jtdb;
2.学习List列表类型
List列表类型(list)是一个存储有序的元素的集合类型.List数据类型底层是一个双端列表.可以从左右分别进行写入操作
双端列表的数据特点:查询两端数据时速度较快,查询中间数据较慢.
指令
说明
案例
lpush
将一个或多个值插入到列表左部插入
LPUSH list1 1 2 3 4
rpush
在列表中添加一个或多个从列表右侧插入
RPUSH list1 5 6 7 8
lpop
从列表左侧移除元素,并且返回结果
LPOP list1
rpop
从列表右侧移除元素,并且返回结果
RPOP list1
llen
获取list集合的元素个数
Llen list1
Lrange
获取指定区间内的片段值
LRANGE list1 0 3
获取从左数第1个到第4个值
LRANGE list1 -3 -1
从右数第三个到第一个数据
Lrange list1 0 -1 查询全部列表数据

Lrem
删除列表中指定的值
Irem key count value
当count>0,从左开始删除前count个值为value的元素
当count<0,从右侧开始删除前count个值为value的元素
当count=0时,删除所有value的元素
LREM list1 2 2
从左数前2个为2的元素
LREM list1 -2 3
从右数前2个为3的元素
LREM list1 0 4
删除全部为4的元素
Lindex
根据指定索引值查询元素
LINDEX list1 0 查找索引值为0的值
LINDEX list1 -1 查询最右边的值
Lset
为指定索引赋值
LSET list1 0 10
LINSERT
LINSERT key before value1 value2
在value1之前插入value2
LINSERT list1 after 1 2
LINSERT list1 before 10 100
从左数第一个为10的元素前插入100
LINSERT list1 after 1 2
从左数第一个为1的值之后插入2
day09:京淘-Redis分片,商品类目缓冲,实现
-
Redis高级用法
-
Redis中队列/栈
-
队列形式
说明:Redis中的链表是双向循环列表.如果使用队列的形式,规则如下.
从一侧压栈,从另外一侧弹栈.
队列的特点:先进先出
2.栈的形式
说明:从同一侧压栈弹栈
特点:先进后出

2.Redis入门案例
-
导入jar包
redis.clients
jedis
${jedis.version}
2.入门案例
/**
* 1.实例化jedis对象(IP:端口)
* 2.实现redis取值赋值操作
*/
@Test
public void test01(){
Jedis jedis = new Jedis("192.168.126.166",6379);
jedis.set("name", "tomcat猫");
System.out.println("获取redis数据:"+jedis.get("name"));
}
3.报错信息

redis.clients.jedis.exceptions.JedisDataException: DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password is requested to clients. In this mode connections are only accepted from the loopback interface. If you want to connect from external computers to Redis you may adopt one of the following solutions: 1) Just disable protected mode sending the command 'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server. 3) If you started the server manually just for testing, restart it with the '--protected-mode no' option. 4) Setup a bind address or an authentication password. NOTE: You only need to do one of the above things in
启动控制台 执行
CONFIG SET protected-mode no 即可
3.Redis实际项目应用
-
需求说明
特点:经常访问的数据,并且变化不大的数据添加缓存
需求说明:将商品分类信息添加到缓存中.
实现思路:
-
当用户点击按钮时,应该先查询缓存
-
如果缓存数据为null,这时应该查询后台数据库,将查询到的结果通过工具类转化为JSON串.之后将数据保存到redis中key:value
之后将查询的结果返回.
3.如果缓存数据不为null,需要通过工具API将JSON串转化为java对象.之后返回数据.
2.编辑配置文件管理jedis对象
-
编辑配置文件
redis.host=192.168.126.166
redis.port=6379
2.编辑spring配置文件
3.编辑Controller
@RequestMapping("/list")
@ResponseBody
public List findItemCat(@RequestParam(value="id",defaultValue="0")Long parentId){
//1.查询一级商品分类目录
//Long parentId = 0L;
//return itemCatService.findItemCatByParentId(parentId);
return itemCatService.findCacheByParentId(parentId);
}
4.编辑Service
@Override
public List findCacheByParentId(Long parentId) {
String key = "ITEM_CAT_"+parentId;
String result = jedis.get(key);
List easyUITreeList = null;
try {
//判断数据是否为null
if(StringUtils.isEmpty(result)){
//表示查询数据库
easyUITreeList =
findItemCatByParentId(parentId);
//将数据转化为JSON串
String jsonData = objectMapper.writeValueAsString(easyUITreeList);
//将数据保存到缓存中
jedis.set(key, jsonData);
return easyUITreeList;
}else{
//表示缓存数据不为null;
EasyUITree[] easyUITrees =
objectMapper.readValue(result,EasyUITree[].class);
easyUITreeList = Arrays.asList(easyUITrees);
return easyUITreeList;
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
5.使用Redis好处
未使用缓存:

使用缓存:

6.作业:
自己测试redis单台的高级测试用法.
4.搭建redis分片
-
分片主要作用
说明:
1.由于单台的redis内存的使用量是有限的,如果需要动态的扩容内存空间,需要搭建redis分片.
2.之前一台redis中保存了服务的全部数据,如果服务器宕机,则会影响整个的内存数据.
2.Redis分片搭建
1.复制配置文件
mkdir shard
cp redis.conf shard/redis-6381.conf
2.文件格式

3.修改端口
分别将6379修改为6380/6381

4.启动redis
[root@localhost shard]# vim redis-6380.conf
[root@localhost shard]# vim redis-6381.conf
[root@localhost shard]# clear
[root@localhost shard]# ls
redis-6379.conf redis-6380.conf redis-6381.conf
[root@localhost shard]# redis-server redis-6379.conf
[root@localhost shard]# redis-server redis-6380.conf
[root@localhost shard]# redis-server redis-6381.conf
5.检测redis启动是否正确

3.Redis分片入门案例
//测试redis分片 实现redis内存动态扩容
@Test
public void test02(){
//定义redis池的配置文件
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(1000);
poolConfig.setMaxIdle(200);
poolConfig.setMinIdle(10);
poolConfig.setTestOnBorrow(true); //链接前校验
//定义jedis分片的节点信息
List shards =
new ArrayList();
shards.add(new JedisShardInfo("192.168.126.166", 6379));
shards.add(new JedisShardInfo("192.168.126.166", 6380));
shards.add(new JedisShardInfo("192.168.126.166", 6381));
ShardedJedisPool jedisPool =
new ShardedJedisPool(poolConfig, shards);
ShardedJedis shardedJedis = jedisPool.getResource();
shardedJedis.set("name", "我是redis分片");
System.out.println
("获取redis信息:"+shardedJedis.get("name"));
}
5.Spring整合redis分片
-
编辑配置文件
redis.host=192.168.126.166
redis.port1=6379
redis.port2=6380
redis.port3=6381
redis.maxTotal=1000
redis.maxIdle=200
2.编辑分片的配置
3.编辑工具类
@Service
public class RedisService {
@Autowired(required=false) //程序启动时暂时不注入,但是如果调用时自动注入
private ShardedJedisPool jedisPool;
public void set(String key,String value){
ShardedJedis shardedJedis = jedisPool.getResource();
shardedJedis.set(key, value);
jedisPool.returnResource(shardedJedis);//将链接还回池中
}
public String get(String key){
ShardedJedis shardedJedis = jedisPool.getResource();
String result = shardedJedis.get(key);
jedisPool.returnResource(shardedJedis);
return result;
}
//为key添加超时时间
public void set(String key,String value,int seconds){
ShardedJedis shardedJedis = jedisPool.getResource();
shardedJedis.setex(key, seconds, value);
jedisPool.returnResource(shardedJedis);//将链接还回池中
}
}
4.客户端调用
1.注入工具类对象

2.工具类对象调用
6.Hash一致算法
-
问题
问题描述:Redis分片时如何保存数据的????.redis获取数据时如何快速检索??
2.Redis中数据存取

总结:
Node节点信息通过ip+端口+算法最终确定了内存的位置.
当要保存key值时,首先经过hash算法计算,确定唯一的一个地址,之后按照顺时针方向绑定最近的一个节点.进行存值操作.
如果取值时,方法类似.
3.均衡性
说明:由于所有的节点进行hash一致性的计算,可能获取的结果在内存中位置相邻.可能会导致数据库分片不均的现象.这样会造成某些节点内存溢出.某些节点内存使用率较少.为了解决这类问题.提出了均衡性.
概念:让节点尽可能保证数据的均匀.每个节点只保存其中1/n的数据.
实现:哈希一致性算法中提出了虚拟节点的概念.如果出现数据存储偏差较大,则会为少的节点添加虚拟节点,共同争抢数据,最终达到1/n

4.单调性
说明:由于节点数量可能会新增,那么保证,新增的节点和之前的节点中的数据实现动态的迁移.再一次保证数据的均衡性.
特点:hash一致性算法要求,尽可能让原有节点数据不变.
缺点:
如果删除节点,那么节点中所保存的数据一并删除.
5.分散性
说明:一个key可能会出现多个位置
前题:由于分布式的开发.可能会导致程序不能看到全部的节点信息.从而导致分散性问题.

6.负载
说明:同一个位置出现多个key.
描述:负载是从另一个角度谈分散性.

总结:
哈希一致算法要求,应该尽可能的降低分散和负载.所以应该操作redis时尽可能操作全部的节点.
7.Redis中数据持久化
-
持久化策略
说明:当数据全部存储到redis中时,如果redis出现宕机的现象.则会丢失内存中的全部数据.所以redis为了保证数据不丢失,redis自身有持久化的策略.
当redis数据操作达到配置的规定,则会将内存中的数据持久化到硬盘中.当redis再次启动时,首先加载持久化的配置文件,恢复内存中的数据.
2.RDB模式
说明:redis中默认的持久化的策略是RDB模式,该模式的持久化的效率是最高的.
命令:
-
Save 特点:redis会立即持久化数据,其他的线程处于阻塞状态.
-
Bgsave 特点:执行该操作,会通知redis进行持久化,不会造成线程阻塞. (类似gc)

1.RDB模式持久化策略
save 900 1 当set操作在900秒内执行1次进行持久化
save 300 10 当set操作在300秒内执行10次 进行持久化
save 60 10000 当set操作在60秒内执行10000次进行持久化
规则:当操作越频繁,持久化的周期越短.
2.RDB配置文件说明

3.RDB使用原则
说明:如果redis能够允许丢失部分数据,则使用RDB模式,因为该模式效率是最高的.
3.AOF模式
说明:AOF模式能够实现实时持久化.AOF模式默认是关闭的.需要手动开启
1.开启AOF模式
说明:如果需要开启AOF则将配置文件改为yes即可.如果开启了AOF模式那么RDB模式将不生效.

2.持久化文件名称

3.AOF的持久化策略
# appendfsync always 每做一次set操作持久化一次,效率最低
appendfsync everysec 每秒持久化一次性能略低于RDB
# appendfsync no
4.Redis中持久化文件保存

day10:京淘Redis哨兵
-
Redis高级-二
-
案例
-
Redis数据被篡改
问题描述:由于多个节点使用相同的配置文件,那么节点启动时会造成一种现象,所有的分片的redis节点数据一致???????
说明:由于使用持久化文件名称一致,所以恢复数据时数据一致.
解决:一个redis对应各自的持久化文件.
2.Redis中内存管理
-
问题
Redis使用内存空间保存数据,如果一致向内存中添加数据,则会导致内存空间不足.直接影响插入的操作.
2.Redis内存设定
1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes

3.内存策略
LRU算法:
内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据.
-
volatile-lru 在设定超时时间的数据中采用LRU算法删除不用的数据.
-
allkeys-lru -> 按照LRU算法在所有key中查找不用的数据进行删除
3.volatile-random -> 随机删除设定了超时时间的数据
4.allkeys-random -> 随机删除所有的key
5.volatile-ttl -> 在已经设定了超时时间的数据中通过ttl排序,将马上要过期的数据进行删除.
6.noeviction -> 不会删除数据,只会返回错误消息
7.Note: 不做操作,返回异常
4.内存规则设定

2.Redis哨兵
-
实现redis主从搭建
-
创建文件夹
说明:创建redis哨兵的文件夹sentinel.并且将之前的redis节点全部关闭.
杀死进程
kill 3282 3286 3510

2.拷贝配置文件
将redis根目录中的redis.conf分别拷贝3份 6379/6380/6381.拷贝到哨兵的文件夹中,并且修改端口号,之后启动服务器.
[root@localhost redis-3.2.8]# cp redis.conf sentinel/redis-6379.conf
[root@localhost redis-3.2.8]# cp redis.conf sentinel/redis-6380.conf
[root@localhost redis-3.2.8]# cp redis.conf sentinel/redis-6381.conf
[root@localhost redis-3.2.8]#
修改端口号

3.启动redis

4.检测节点状态
命令:info replication

5.搭建主从
定义规则:6379当主机 6380/6381当从机
作用:可以实现数据的实时同步(备份).
搭建命令: slaveof 主机IP 主机端口
Redis-cli -p 6380
SLAVEOF 192.168.126.166 6379

6.主从测试
1.检测主机是否能够识别自己的从机
[root@localhost sentinel]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.228.131,port=6380,state=online,offset=393,lag=0
slave1:ip=192.168.228.131,port=6381,state=online,offset=393,lag=0
master_repl_offset:393
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:392
127.0.0.1:6379>
2.当主库set a a时,检测从库是否有数据.表示主从挂载成功.

7.主从配置说明
说明:如果在命令提示行中执行slaveof命令,那么该操作只在内存中生效.当从机重启时,又会变为主机.主从搭建失败. 如果需要长久的保存主从的关系,应该修改配置文件.

2.哨兵工作原理
-
原理说明
1.当搭建哨兵时,首先哨兵会通过心跳检测,检测主机是否正常.如果主机长时间没有响应,则断定主机宕机,那么哨兵会进行推选,从之前主机中的从机中选择一个新的主机.并且把其他的配置文件中的slaveof 配置文件修改为新的主机的IP和端口.
2.对于用户而言,需要通过IP:端口链接哨兵即可.用户不需要了解当前状态谁是主机谁是从机.都通过哨兵作为中转将请求实现.
3.对于哨兵而言,负责新节点的选择,一定要避免偶数个节点,否则会出现”脑裂问题”所以哨兵等选举机制一般都是奇数个.
2.哨兵的配置文件
cp sentinel.conf sentinel/sentinel-6379.conf
-
修改哨兵的端口号

2.关闭保护模式

3.哨兵监控主机的配置
sentinel monitor mymaster 127.0.0.1 6379 2
mymaster:代表主机变量名称.
IP 端口:代表主机的IP和端口
2: 选举的票数 原则(超过哨兵半数即可)

4.修改推选时间
当主机宕机10秒后,哨兵开始推选工作

5.哨兵推选失败的超时时间

3.哨兵启动
redis-sentinel sentinel-6379.conf

哨兵测试:
将redis主机关闭后,检测哨兵是否会选举新的主机.
3.多个哨兵搭建
-
复制配置文件

2.修改哨兵端口号

3.修改哨兵的序列号

说明:将不同的哨兵 修改序列号和端口
4.修改票数

5.多个哨兵测试
将哨兵启动后,将redis主机关闭后,检测3个哨兵是否能够进行正确的推选.
6400:X 27 Jul 23:16:35.383 * +slave slave 192.168.126.166:6381 192.168.126.166 6381 @ mymaster 192.168.126.166 6379
6400:X 27 Jul 23:16:35.383 * +slave slave 192.168.126.166:6380 192.168.126.166 6380 @ mymaster 192.168.126.166 6379
6400:X 27 Jul 23:16:45.423 # +sdown slave 192.168.126.166:6380 192.168.126.166 6380 @ mymaster 192.168.126.166 6379
6400:X 27 Jul 23:17:31.752 # -sdown slave 192.168.126.166:6380 192.168.126.166 6380 @ mymaster 192.168.126.166 6379
6400:X 27 Jul 23:17:41.746 * +convert-to-slave slave 192.168.126.166:6380 192.168.126.166 6380 @ mymaster 192.168.126.166 6379
4.Spring整合哨兵
-
Redis哨兵入门案例
//实现哨兵的测试
@Test
public void test03(){
Set sentinels = new HashSet();
//格式演示
//System.out.println
//(new HostAndPort("192.168.126.166", 26379).toString());
sentinels.add("192.168.126.166:26379");
sentinels.add("192.168.126.166:26380");
sentinels.add("192.168.126.166:26381");
//定义哨兵的连接池
JedisSentinelPool sentinelPool =
new JedisSentinelPool("mymaster", sentinels);
Jedis jedis = sentinelPool.getResource();
jedis.set("name", "我是哨兵的redis");
System.out.println("获取redis数据:"+jedis.get("name"));
}
2.编辑properties文件
redis.host=192.168.126.166
redis.port1=6379
redis.port2=6380
redis.port3=6381
redis.sentinel.mastername=mymaster
redis.sentinel.a=192.168.126.166:26379
redis.sentinel.b=192.168.126.166:26380
redis.sentinel.c=192.168.126.166:26381
redis.maxTotal=1000
redis.maxIdle=200
3.Spring整合哨兵
${redis.sentinel.a}
${redis.sentinel.b}
${redis.sentinel.c}
4.编辑工具类
//是操作redis工具API
@Service
public class RedisService {
@Autowired(required=false) //程序启动时暂时不注入,但是如果调用时自动注入
//private ShardedJedisPool jedisPool;
private JedisSentinelPool sentinelPool;
public void set(String key,String value){
Jedis jedis = sentinelPool.getResource();
jedis.set(key, value)
sentinelPool.returnResource(jedis);
}
public String get(String key){
Jedis jedis = sentinelPool.getResource();
String result = jedis.get(key);
sentinelPool.returnResource(jedis);
return result;
}
}
5.效果展现

6.补充知识-跳过测试类打包
org.apache.maven.plugins
maven-surefire-plugin
true
org.apache.tomcat.maven
tomcat7-maven-plugin
8091
/
day11:京淘-Redis集群搭建
-
Redis-集群搭建
-
Redis分片和哨兵的问题
-
问题说明:
分片的优点:
可以实现内存的动态的扩容.
哨兵的优点:
可以实现redis的高可用.
缺点:
-
如果一台redis节点宕机,则整个redis分片将不能正常运行.
-
由于采用Hash一致性算法,如果分布式的操作,可能会导致 分散性和负载
-
哨兵机制中,如果哨兵出现宕机现象,则直接影响整个服务.
-
如果哨兵宕机,则可能会出现选举的哨兵偶数台.可能会出现脑裂的现象,使整个redis集群陷入错误中.
2.Redis集群的优点
-
总结
Redis集群实际上就是将分片和redis哨兵整合到一起.并且内存不需要启动哨兵的服务,.通过redis管理工具.ruby工具,使得redis内部实现高可用.
-
3.Redis集群搭建步骤
-
搭建规模
主机:3台 端口7000-7002
从机:6台 端口7003-7008
2.创建9个文件夹

3.修改配置文件
说明:将redis根目录中的redis.conf文件复制到7000中后,进行配置文件修改.

修改内容的说明:
-
将ip绑定注释

2.修改端口

3.关闭保护模式

4.开启后台启动

5.修改PID文件位置和名称

6.修改持久化文件的路径

7.修改内存维护策略allkeys-lru

8.开启redis集群的配置
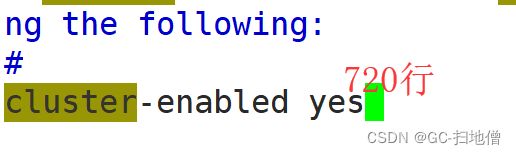
9.启动redis节点的配置信息

10.配置redis集群选举的超时时间

4.复制配置文件
说明:分别将7000/redis.conf复制到7001-7008中.之后采用批量修改命令将7000端口改为各自对应的端口号.
[root@localhost cluster]# cp 7000/redis.conf 7001/redis.conf
[root@localhost cluster]# cp 7000/redis.conf 7002/redis.conf
[root@localhost cluster]# cp 7000/redis.conf 7003/redis.conf
vim 7001/redis.conf
:%s/7000/7001/g
:%s/7000/7002/g
:%s/7000/7003/g
:%s/7000/7004/g
:%s/7000/7005/g
:%s/7000/7006/g
:%s/7000/7007/g
:%s/7000/7008/g

5.Redis脚本启动
说明:在redis/cluster的根目录中创建文件 start.sh
命令: vim start.sh
#!/bin/sh
redis-server 7000/redis.conf &
redis-server 7001/redis.conf &
redis-server 7002/redis.conf &
redis-server 7003/redis.conf &
redis-server 7004/redis.conf &
redis-server 7005/redis.conf &
redis-server 7006/redis.conf &
redis-server 7007/redis.conf &
redis-server 7008/redis.conf &
启动redis节点:
sh start.sh 或./start.sh
关闭redis进程:
pkill -9 redis
-
-
-
实现集群的创建
集群创建命令
要求:该命令必须在redis的根目录下执行
命令介绍: --replicas 2 一个主机下有2个从机
./src/redis-trib.rb create --replicas 2 192.168.228.131:7000 192.168.228.131:7001 192.168.228.131:7002 192.168.228.131:7003 192.168.228.131:7004 192.168.228.131:7005 192.168.228.131:7006 192.168.228.131:7007 192.168.228.131:7008

搭建过程:

搭建成功


7.集群测试
将redis集群中的主机宕机后,检测redis高可用是否正常.之后启动redis主机,检测是否自动实现挂载

8.关于集群启动步骤
说明:如果在以后使用集群的过程中,出现服务器意外宕机的现象,则重启的步骤如下.
-
重启物理机
-
关闭防火墙
-
执行redis启动脚本 sh start.sh
1.Redis集群知识(二)
-
专业名称介绍
1.缓存穿透
条件:访问一个不存在的数据
说明:当访问一个不存在的数据时,因为缓存中没有这个key,导致缓存形同虚设.最终访问后台数据库.但是数据库中没有该数据所以返回null.
隐患:如果有人恶意频繁查询一个不存在的数据,可能会导致数据库负载高导致宕机.
总结:业务系统访问一个不存在的数据,称之为缓存穿透.
2.缓存击穿
条件:当缓存key失效/过期/未命中时,高并发访问该key
说明:如果给一个key设定了失效时间,当key失效时有一万的并发请求访问这个key,这时缓存失效,所有的请求都会访问后台数据库.称之为缓存击穿.
场景:微博热点消息访问量很大,如果该缓存失效则会直接访问后台数据库,导致数据库负载过高.
3.缓存雪崩
前提:高并发访问,缓存命中较低或者失效时
说明:假设缓存都设定了失效时间,在同一时间内缓存大量失效.如果这时用户高并发访问.缓存命中率过低.导致全部的用户访问都会访问后台真实的数据库.
场景:在高并发条件下.缓存动态更新时
1.脑裂
说明:由于推选机制同时选举出多台主机,导致程序不能正常的执行.该问题称之为脑裂.
解决办法:
-
机器的数量是奇数台
-
配置的服务器的量一定要多.
2.关于redis集群说明
-
什么时候集群崩溃
说明:如果主节点在宕机时没有从节点则集群崩溃.
问题:3主6从 宕机几次集群崩溃?????
特点:集群中如果主机宕机,那么从机可以继续提供服务,
当主机中没有从机时,则向其他主机借用多余的从机.继续提供服务.
如果主机宕机时没有从机可用,则集群崩溃.
答案:9台机器,宕机5-7次集群崩溃了.

2.Java程序连接异常
问题描述:
如果java程序链接redis时,报错没有可用的集群节点时.检测虚拟机的IP地址和配置文件的地址是否匹配.
为什么:因为虚拟机的IP地址发生了变化.
9.Redis集群入门案例
/**
* 步骤:
* 1.redis的节点3主6从9个节点
* 2.每个节点需要通过IP:端口的形式进行链接
* 3.创建集群的链接对象API调用
*/
@Test
public void testCluster(){
String host = "192.168.126.166";
//定义集群的集合
Set nodes = new HashSet();
nodes.add(new HostAndPort(host,7000));
nodes.add(new HostAndPort(host,7001));
nodes.add(new HostAndPort(host,7002));
nodes.add(new HostAndPort(host,7003));
nodes.add(new HostAndPort(host,7004));
nodes.add(new HostAndPort(host,7005));
nodes.add(new HostAndPort(host,7006));
nodes.add(new HostAndPort(host,7007));
nodes.add(new HostAndPort(host,7008));
JedisCluster jedisCluster = new JedisCluster(nodes);
jedisCluster.set("1803", "集群搭建终于完成了");
System.out.println("获取数据:"+jedisCluster.get("1803"));
}
4.Spring中的工厂模式
-
为什么使用工厂模式
特点:
-
简化代码
-
提供完善方法
-
某些特殊的对象不能直接实例化,可以使用工厂模式实例化对象
3.1JDK代理
要求:被代理者必须实现接口.否则不能创建代理对象
3.2cglib代理
要求:生成的代理对象是目标对象的子类
3.3选择代理的原则
如果目标对象有接口则使用JDK,如果目标对象没有接口则使用CGLib
3.4spring框架中可以指定代理对象的创建方式.
2.静态工厂模式
说明:在工厂模式中有一个static静态的方法.
调用规则:类名.静态方法
工厂类定义:
public class StaticFactory {
public static Calendar getCalendar(){
return Calendar.getInstance();
}
}
配置文件:
3.实例工厂模式
说明:实例工厂其实就是工厂对象调用工厂方法.
调用规则:对象.方法
工厂类调用:
public class NewInstanceFactory {
public Calendar getCalendar(){
return Calendar.getInstance();
}
}
配置文件:
工具类测试:
@Test
public void testFactory(){
ApplicationContext context =
new ClassPathXmlApplicationContext("/spring/factory.xml");
Calendar calendar1 = (Calendar) context.getBean("calendar1");
Calendar calendar2 = (Calendar) context.getBean("calendar2");
System.out.println("一:"+calendar1.getTime());
System.out.println("二:"+calendar2.getTime());
}
4.Spring工厂模式
规则:必须实现特定的接口FactoryBean.
扩展: implements BeanNameAware
public class SpringFactory implements FactoryBean{
@Override
public Calendar getObject() throws Exception {
System.out.println("spring调用工厂模式创建对象");
return Calendar.getInstance();
}
//获取对象的类型
@Override
public Class getObjectType() {
return Calendar.class;
}
//通过工厂模式创建的对象 是否是单例的
@Override
public boolean isSingleton() {
return false;
}
}
5.Spring整合redis集群
-
编辑properties配置文件
#最小空闲数
redis.minIdle=100
#最大空闲数
redis.maxIdle=300
#最大连接数
redis.maxTotal=1000
#客户端超时时间单位是毫秒
redis.timeout=5000
#最大建立连接等待时间
redis.maxWait=1000
#是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个
redis.testOnBorrow=true
#redis cluster
redis.cluster0=192.168.126.166:7000
redis.cluster1=192.168.126.166:7001
redis.cluster2=192.168.126.166:7002
redis.cluster3=192.168.126.166:7003
redis.cluster4=192.168.126.166:7004
redis.cluster5=192.168.126.166:7005
redis.cluster6=192.168.126.166:7006
redis.cluster7=192.168.126.166:7007
redis.cluster8=192.168.126.166:7008
2.编辑Spring的配置文件
classpath:/property/redis.properties
3.编辑工具类方法
//通过工厂模式创建JedisCluster对象
public class JedisClusterFactory implements FactoryBean{
private Resource propertySource; //表示注入properties文件
private JedisPoolConfig poolConfig; //注入池对象
private String redisNodePrefix; //定义redis节点的前缀
@Override
public JedisCluster getObject() throws Exception {
Set nodes = getNodes(); //获取节点信息
JedisCluster jedisCluster =
new JedisCluster(nodes, poolConfig);
return jedisCluster;
}
//获取redis节点Set集合
public Set getNodes(){
//1.准备Set集合
Set nodes = new HashSet();
//2.创建property对象
Properties properties = new Properties();
try {
properties.load(propertySource.getInputStream());
//2.从配置文件中遍历redis节点数据
for (Object key : properties.keySet()) {
String keyStr = (String) key;
//获取redis节点数据
if(keyStr.startsWith(redisNodePrefix)){
//IP:端口
String value = properties.getProperty(keyStr);
String[] args = value.split(":");
HostAndPort hostAndPort =
new HostAndPort(args[0],Integer.parseInt(args[1]));
nodes.add(hostAndPort);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return nodes;
}
@Override
public Class getObjectType() {
return JedisCluster.class;
}
@Override
public boolean isSingleton() {
return false;
}
public Resource getPropertySource() {
return propertySource;
}
public void setPropertySource(Resource propertySource) {
this.propertySource = propertySource;
}
public JedisPoolConfig getPoolConfig() {
return poolConfig;
}
public void setPoolConfig(JedisPoolConfig poolConfig) {
this.poolConfig = poolConfig;
}
public String getRedisNodePrefix() {
return redisNodePrefix;
}
public void setRedisNodePrefix(String redisNodePrefix) {
this.redisNodePrefix = redisNodePrefix;
}
}
4.程序调用



2.JT-WEB
-
项目搭建
-
选择骨架创建项目
2.添加继承和依赖
1.添加继承
2.依赖

3.添加tomcat插件
org.apache.maven.plugins
maven-surefire-plugin
true
org.apache.tomcat.maven
tomcat7-maven-plugin
8092
/
2. 配置 tomcat 插件
 3. 添加源码
3. 添加源码

4.项目测试
配置完成后 , 启动项目
5.实现nginx反向代理
修改nginx配置文件
#定义前台管理系统
server {
listen 80;
server_name www.jt.com;
location / {
proxy_pass http://localhost:8092;
#代理连接超时
proxy_connect_timeout 3;
#代理读取超时
proxy_read_timeout 3;
#代理发送超时
proxy_send_timeout 3;
}
}
6.修改host文件

7.访问启动:
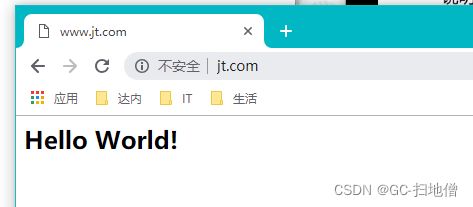
-
添加配置文件
-
配置文件说明
说明:jt-web主要负责与用户进行交互.项目中用到的全部的数据都通过特殊的方式从对应的服务器动态获取.前台只需要配置SpringMVC/Spring/静态资源文件即可.
2.导入静态配置文件
3.Web.xml配置文件说明
-
以监听器的方式启动Spring容器
contextConfigLocation
classpath:spring/applicationContext*.xml
org.springframework.web.context.ContextLoaderListener
对于监听器的说明:
有些就的企业现在一直沿用监听器的方式启动spring容器.该方式其实是一种懒加载的方式.当SpringMVC容器需要实例化Controller对象时,并且内部需要注入业务层Service时,该操作会被监听器所拦截.这时启动Spring容器实例化对象.之后将对象注入注入.整个容器启动完成.
2.前端控制器拦截的策略
springmvc-web
*.html
springmvc-web
/service/*
*.html 该操作拦截所有以.html结尾的请求
/service/* 该配置拦截所有以/Service开头的请求
4.伪静态介绍
静态页面优点:
-
加载速度快
-
容易被搜索引擎收录,增加页面的友好性
静态页面缺点:
-
用户体验感差/交互性差
-
静态页面数据不安全.
动态页面优点:
-
用户交互性强
-
安全性更好AJAX
动态页面缺点:
-
搜索引擎不会收录动态页面 .jsp .asp
伪静态介绍:
伪静态是相对真实静态来讲的,通常我们为了增强搜索引擎的友好面,都将文章内容生成静态页面,但是有的朋友为了实时的显示一些信息。或者还想运用动态脚本解决一些问题。不能用静态的方式来展示网站内容。但是这就损失了对搜索引擎的友好面。怎么样在两者之间找个中间方法呢,这就产生了伪静态技术。就是展示出来的是以html一类的静态页面形式,但其实是用ASP一类的动态脚本来处理的。
总结:以html静态页面展现形式的动态页面技术.
5.修改配置文件
-
修改Spring配置文件


2.修改配置文件后效果
6.展现京淘前台首页
-
编辑Controller
@Controller
public class IndexController {
@RequestMapping("/index")
public String index(){
return "index";
}
}
2.页面效果展现
5.网站跨域问题
-
跨域问题测试
说明:在www.jt.com中调用manage.jt.com时访问不成功.原因该操作是一个跨域请求.
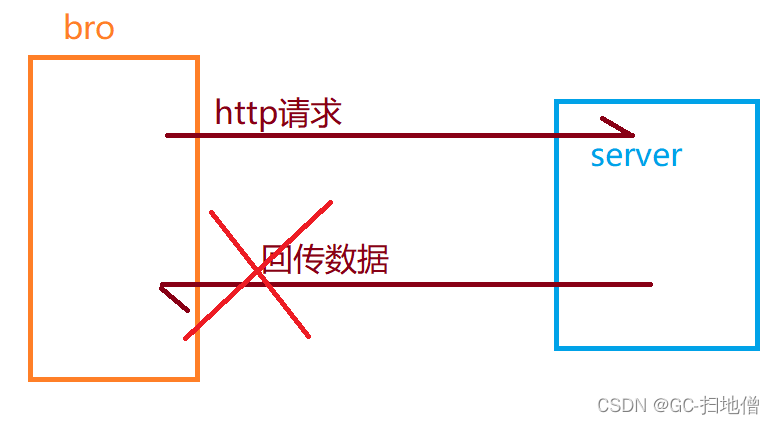
浏览器不允许进行跨域请求.会将成功返回的数据进行拦截.不予显示.一切出于安全性的考虑.
2.什么是同域
规则:
请求协议/域名/-是否相同,如果三者都一致,那么是同域访问.浏览器可以正常执行.除此之外的全部的请求都是跨域请求.
例子1:
Http://mange.jt.com/index
https://manage.jt.com/index
跨域
例子2:
前台网站:http://www.jt.com
访问后台:Http://manage.jt.com/test.json
跨域
例子3:
http://manage.jt.com:8091/index
http://manage.jt.com/index
跨域
案例:
Http://localhost:8091/index http://manage.jt.com/index
跨域

3.作业:
-
复习JSON写法 3种
-
查看课前资料中js跨域解决.
-
根据图中的信息,能否转化为对象 并且考虑用几个对象封装
-
将jt-mangelinux部署

day12:京淘-实现跨域 商品详情展现
-
跨域问题实现
-
用户页面通用跳转
-
业务需求
当用户点击登陆页面或者注册页面时.要跳转到指定的页面中去.
-
/user/register.html
-
/user/login.html
使用RestFul结构实现页面通用跳转
2.编辑Controller
@Controller
@RequestMapping("/user")
public class UserController {
@RequestMapping("/{moduleName}")
public String index(@PathVariable String moduleName){
return moduleName;
}
}
2.跨域和同域的区别
-
跨域测试
2.同源策略
说明:如果请求的协议://域名:端口都相同则是同源访问.可以访问数据.
除此之外的全部的访问都是跨域的,.禁止通信.

3.跨域实现
说明:利用script标签中src属性可以实现跨域.
步骤:
-
利用src属性请求远程的js
-
将返回值的JSON串进行特殊的处理.为返回值添加函数名称 hello(data)格式
-
在客户端定义回调函数 function hello(data){…..}
页面编辑:
定义返回值类型:
hello({"id":"1","name":"tom"})
4.传统的JS中存在的问题
-
如果函数的名称和JSON串的返回值不同则无法跨域.
-
每次跨域请求都需要借用javaScript中的src属性.调用不直观.而且繁琐.
如何解决:
-
发起请求时将函数名称当成参数传递即可
addUser?callback=hello.
后台接收callback参数最终封装为特殊格式的JSON串.hello(Data)
2.将调用的过程抽取为公共的方法.以AJAX的形式进行封装.并且提供良好品参数传值的方式.
Jquery中的JSONP请求格式.
5.JSONP介绍
JSONP(JSON with Padding)是JSON的一种“使用模式”,可用于解决主流浏览器的跨域数据访问的问题。由于同源策略,一般来说位于server1.example.com的网页无法与不是server1.example.com的服务器沟通,而 HTML 的
你可能感兴趣的:(java,redis,nginx)