python基础数据类型
格式化输出
- 旧的格式化方案
%s表示在字符串中占位,稍后会填充字符串(任何内容)
%d表示在字符串中占位,填充整数
%f表示在字符串中占位,填充小数【%.2f保留小数点后两位】
name = input("请输入你的姓名:")
age = input("请输入你的年龄:")
city = input("请输入你的城市:")
str = """---info of %s---
name: %s
age : %s
city: %s
---end---
""" % (name, name, age, city)
- 新的格式化方案 f-string 3.5以上
name = input("请输入你的姓名:")
age = input("请输入你的年龄:")
city = input("请输入你的城市:")
print(f"我叫{name},今年{age},居住在{city}")
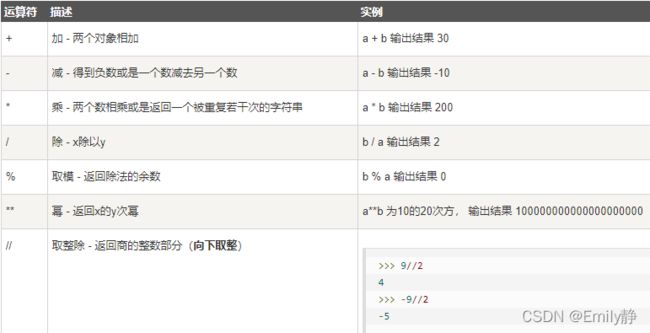
基本运算符
- 算数运算
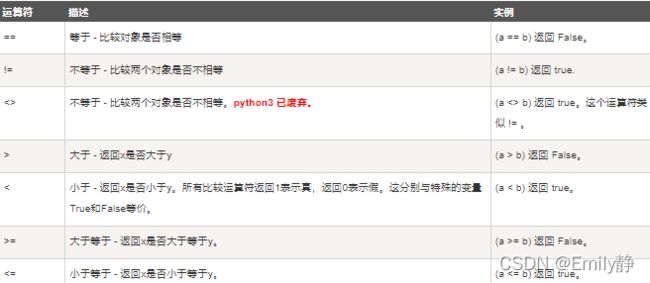
- 比较运算
- 逻辑运算

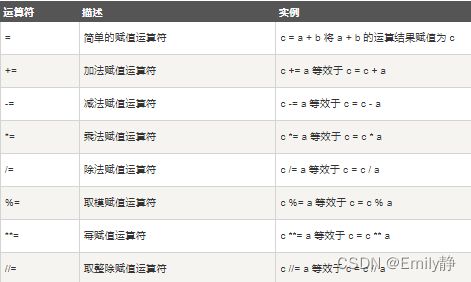
- 赋值运算
- 位运算

- 成员运算

- 身份运算符 : 用于比较两个对象的存储单元
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。

编码
- ASCII:8bit,主要存放的是英文,数字,特殊符号
- GBK:16bit,主要存放中文和亚洲字符,兼容ASCII
- UNICODE:16bit或32bit(平时常用16bit),存放全世界所有国家的文字信息
- UTF-8:可变长度unicode,英文:8bit;欧洲文字:16bit;中文:24bit。一般用于数字传输和存储
bytes类型
python程序运行起来之后,内存中存储的字符串默认使用unicode(定长,好处理),但如果涉及字符串的存储和传输,就需要进行编码成UTF-8或GBK进行传递(unicode太浪费空间)
str = '中国'
b = str.encode('utf-8') # 编码encode(),b的类型为bytes
print(b) # b'\xe4\xb8\xad\xe5\x9b\xbd'
bs = b.decode()
print(bs)
bss = bs.encode('gbk')
print(bss) # b'\xd6\xd0\xb9\xfa'
字符串
- 索引:就是下标,从0开始
str = '北京欢迎你'
print(str[0])
print(str[1])
print(str[-1]) # 倒数第一个字符
print(str[-2])
- 切片:使用下标截取部分字符串的内容
基本语法:str[start : end : step]
start:起始位置
end:结束位置,不包括end位置
step:切片的步数
str = '北京欢迎你everybody'
print(str[0:6])
print(str[1:]) # 取到最后一个值
print(str[-1:-5]) # 从-1到-5取不到任何结果(从-1向右取)
print(str[-5:-1])
print(str[-1:-5:-1]) # 步数是负数,从右往左
print(str[1:8:2]) # 步数是正数,从左往右
print(str[-2:-9:-3]) # 从倒数第2个开始到倒数第9个,每3个取一个
- 大小写
str = 'everYboDy'
str.capitalize()
print(str) # 输出并没有变化,因为字符串是不可变对象,任何操作对于字符串都没有影响,需要重新获取
str1 = str.capitalize() # 首字母大写
str2 = str.upper() # 全部转换成大写
str3 = str.lower() # 全部转换成小写
# str3 = str.casefold() # 转换成小写,比lower()支持的全面
str4 = str.swapcase() #大小写相互转换
s = 'upper_lower swap你ni'
s1 = s.title() # 每个被特殊字符隔开的字母首字母大写
- 切来切去
str = 'everYboDy'
str1 = str.center(15, '-') # 字符串居中 结果:---everYboDy---
str2 = str.center(15) # everYboDy
str0 = ' \n everYboDy \t'
str1 = str0.strip() # 默认是去掉字符串左右两边的空白(空格,\t,\n)
str2 = 'bo_every_bo'
str3 = str2.strip('bo') # 去掉字符串左右两边指定的字符
str = 'i love you'
str1 = str.replace('love', 'like') # replace替换字符串中特定的字符
str = 'i love you'
str1 = str.split(' ') # 字符串切割 (通过空格切割,得到一个列表)
str2 = '_'.join(str1) # 把列表通过下划线合并成一个字符串
- 格式化输出
# 之前旧的写法
str0 = "我叫%s,今年%s,喜欢%s" % ('小美', '18', '周杰伦')
# 按位置格式化
str1 = "我叫{},今年{},喜欢{}".format('小美', '18', '周杰伦')
# 指定位置
str2 = "我叫{0},今年{2},喜欢{1}".format('小美', '周杰伦', '18')
# 指定关键字
str3 = "我叫{name},今年{age},喜欢{idol}".format(name='小美', age='18', idol='周杰伦')
- 查找
str = '不求有结果,不求同行,不求曾经拥有'
# 判断是否以指定的字符串开头
ret0 = str.startswith('不求')
# 判断是否以指定的字符结尾
ret1 = str.endswith('拥有')
# 查找指定字符出现的次数
ret2 = str.count('求')
# 查找特定字符串出现的次数
ret3_0 = str.find('结果')
ret3_1 = str.find('love') # 如果没找到返回-1
ret3_2 = str.find('有', 6, 17) # 切片进行查找
# 查找特定字符索引的位置,没有找到程序会报错
ret4 = str.index('曾经')
- 条件判断
python字符串内建函数: https://www.runoob.com/python/python-strings.html
# isdigit()如果string只包含数字则返回True 否则返回False
str = '1314'
print(str.isdigit())
# isdecimal() 方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象
# 注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可
str1 = u'520'
print(str1.isdecimal())
# isnumeric() 方法检测字符串是否只由数字组成,可以识别中文
str2 = '一二三四五'
print(str2.isnumeric()) #返回ture
- 字符串长度计算
str2 = '一二三四五'
length = len(str2)
- 迭代
使用for循环来获取字符串中的每一个字符
for 变量 in 可迭代对象:
pass
str2 = '一二三四五'
for i in str2:
print(i)
列表List
- 索引和切片
lst = ['Baidu', 'Alibaba', 'Tencent', 'Google']
print(lst[2])
print(lst[-3])
print(lst[0:2])
print(lst[-4::2])
print(lst[-1:-3:-1]) # 倒着取
- 基本操作
- 新增列表元素
lst = ['Baidu', 'Alibaba', 'Tencent', 'Google']
# 在列表后面追加一个元素
lst.append('Bytedance')
# 在指定位置上插入一个新元素
lst.insert(2, 'JD')
# 在列表中迭代新增
tempt = ['Pinduoduo', '小红书']
lst.extend(tempt)
print(lst)
- 删除列表元素
lst = ['Baidu', 'Alibaba', 'JD', 'Tencent', 'Google']
# 删除列表最后一个元素 返回删除掉的元素
lst.pop()
#指定位置进行删除
lst.pop(1)
# 删除列表某个指定元素
lst.remove('JD')
del lst[0]
# 清空列表
lst.clear()
print(lst)
- 修改列表元素
lst = ['Baidu', 'Alibaba', 'JD', 'Tencent', 'Google']
lst[3] = 'Pinduoduo' # 根据索引进行元素修改
- 查询列表元素
lst = ['Baidu', 'Alibaba', 'JD', 'Tencent', 'Google']
for item in lst:
print(item)
# 输出索引加元素
for i in range(len(lst)):
print('列表中第{}个公司是{}'.format(i, lst[i]))
- 其他操作
lst = ['Baidu', 'Alibaba', 'JD', 'Tencent', 'Google', 'JD']
# 元素出现的次数
lst.count('JD')
# 翻转列表元素
lst.reverse()
# 列表排序
lst.sort()
lst.sort(reverse=True) # 从大到小
- 嵌套 :一层一层的去看
lst = ['Baidu', 'Alibaba', ['JD', 'Tencent', 'Google'], 'JD']
print(lst[2][1])
元组Tuple
不可变列表(只读列表),不能修改,用小括号括起来
tu = ('Baidu', 'Alibaba', [])
# 索引和切片
print(tu[0])
print(tu[:2])
# 注意:元组不可修改的意思是子元素不可变,而子元素内部的子元素可以修改
tu[2].append('Tencent')
# 元组迭代
for item in tu:
print(item)
# 注意:元组只有一个元素,需要添加一个括号
tu1 = ('JD',)
字典Dict
字典是映射类型,以{key: value}括起来的键值对组成,保存的时候根据key计算出一个内存地址(hash算法),将key: value保存在这个地址中
key必须是可哈希的,也就是不可变,为了能准确计算内存地址
已知的可哈希(不可变)的数据类型:int,str,tuple,bool
不可哈希(可变)的数据类型:list,dict,set
dic = {10086: 'Ture', 'name': "周杰伦", (1,): 18, True: 10086}
# dict存储的数据不是按照顺序保存的,是按照hash表的顺序保存不连续,所以只能通过key去获取dict的数据
dic[10086]
- 字典的基本操作
- 增加元素
dic = {}
# 直接添加数据
dic['name'] = "Baidu"
# 使用setdefault设置默认值,如果key值存在,则不起作用
dic.setdefault("age", 18)
- 删除元素
dic = {'name': 'Baidu', 'age': 18}
dic.pop('age') # 返回删除key的value
del dic['name']
dic.clear()
- 修改元素
dic = {'name': 'Baidu', 'age': 18}
dic["age"] = 48
- 查询元素
dic = {'name': 'Baidu', 'age': 18}
print(dic['name']) # 如果key不存在,直接报错
print(dic.get('name')) # 如果key不存在,返回None,不报错
print(dic.get('sex', '女')) # 如果key不存在,可以赋默认值
# setdefault在执行新增流程之后,会根据key查询value
lst = [12, 14, 45, 67, 46, 55, 78, 90]
result = {}
for item in lst:
if item > 50:
result.setdefault('bigger', []).append(item)
else:
result.setdefault('smaller', []).append(item)
print(result)
- 字典的循环
dic = {'name': 'Baidu', 'age': 18}
# 直接for循环,拿到key
for key in dic:
print(key)
print(dic[key])
# 返回字典中的keys
for key in dic.keys():
print(dic[key])
# 返回所有的value
for value in dic.values():
print(value)
# 返回字典中的key: value,最直接的拿到key和value
for key, value in dic.items(): # 解构的方法
print(key)
print(value)
- 字典的嵌套:一层一层去看
dic = {
'name': 'Baidu',
'age': 18,
'boss': {
"name": "Mr Li",
"age": 48,
"sex": '男'
},
'partment': ['音乐', '网盘', '搜索']
}
集合Set
set中的元素是不重复的,里面的元素必须是可hash的(int,str,tuple,bool),set用{}表示,保存dict类型中的key
- 操作
s = set()
# 新增
s.add('西安')
s.add('成都')
# 修改:首先把要修改的内容删除,再新增一个
s.remove('成都')
s.add('三亚')
# 去除重复
lst = ['Baidu', 'JD', 'Xiaomi', 'JD']
lst0 = list(set(lst))
print(lst0)
# 交 并 差
lay = {"西安", "丽江", "三亚", "克拉玛依"}
jj = {"三亚", "成都", "长沙", "西安"}
print(lay & jj) # lay和jj都去过的地方
print(lay | jj) # lay和jj一共去过的地方
print(lay - jj) # lay去过jj没去过的地方