让 Spark Streaming 程序在 YARN 集群上长时间运行(二)—— 日志、监控、Metrics
前段时间看到了外国朋友写的一篇文章,觉得还不错,于是就把他翻译一下,供大家参考和学习。
如果没看过第一篇文章,建议先去看一下上一篇文章哈,这里是接着上一篇文章来写的哈~
日志
访问 Spark 应用程序日志的最简单方法是配置 Log4j 控制台 appender,等待应用程序终止并使用 yarn logs -applicationId [applicationId] 命令。 不幸的是,终止长时间运行的 Spark Streaming 作业来访问日志是不可行的。
我建议安装和配置 Elastic,Logstash 和 Kibana(ELK栈)。 ELK 的安装和配置不在此博客文章范围内,但请记住记录以下上下文字段:
- YARN application id
- YARN container hostname
- Executor id (Spark driver 一直是 000001, Spark executors 从 000002 开始)
- YARN attempt (检查 Spark Driver 程序重启的次数)
具有 Logstash 特定 appender 和布局定义的 Log4j 配置应传递给 spark-submit命令:
spark-submit --master yarn --deploy-mode cluster \
--conf spark.yarn.maxAppAttempts=4 \
--conf spark.yarn.am.attemptFailuresValidityInterval=1h \
--conf spark.yarn.max.executor.failures={8 * num_executors} \
--conf spark.yarn.executor.failuresValidityInterval=1h \
--conf spark.task.maxFailures=8 \
--queue realtime_queue \
--conf spark.speculation=true \
--principal user/hostname@domain \
--keytab /path/to/foo.keytab \
--conf spark.hadoop.fs.hdfs.impl.disable.cache=true \
--conf spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties \
--conf spark.executor.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties \
--files /path/to/log4j.properties最后,Spark Job 的 Kibana 仪表板可能如下所示:
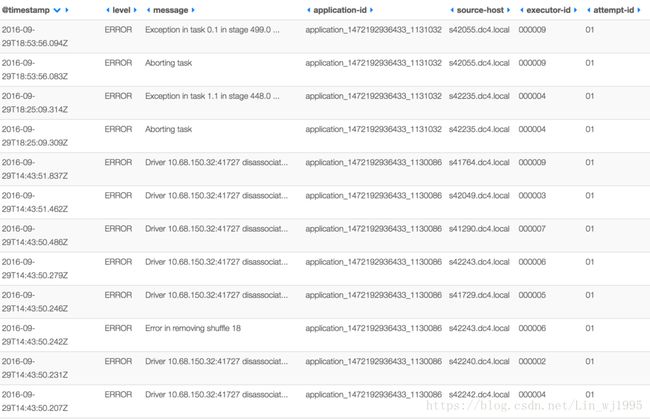
监控
长时间运行的作业 7*24 小时运行,因此了解历史指标非常重要。 Spark UI 只对有限数量的 batch 保持统计信息,并且在重新启动后,所有 metrics 都消失了。 所以需要外部工具。 我建议安装 Graphite 来收集度量标准,Grafana 则用于构建仪表板。
首先,需要配置 Spark 以将 metrics 报告到 Graphite,准备如下metrics.properties文件:
*.sink.graphite.class=org.apache.spark.metrics.sink.GraphiteSink
*.sink.graphite.host=[hostname]
*.sink.graphite.port=[port]
*.sink.graphite.prefix=some_meaningful_name
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource然后配置 spark-submit 命令:
spark-submit --master yarn --deploy-mode cluster \
--conf spark.yarn.maxAppAttempts=4 \
--conf spark.yarn.am.attemptFailuresValidityInterval=1h \
--conf spark.yarn.max.executor.failures={8 * num_executors} \
--conf spark.yarn.executor.failuresValidityInterval=1h \
--conf spark.task.maxFailures=8 \
--queue realtime_queue \
--conf spark.speculation=true \
--principal user/hostname@domain \
--keytab /path/to/foo.keytab \
--conf spark.hadoop.fs.hdfs.impl.disable.cache=true \
--conf spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties \
--conf spark.executor.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties \
--files /path/to/log4j.properties:/path/to/metrics.propertiesMetrics
Spark 会从 Driver 和 executors 生成大量指标。 如果我选择最重要的一个,那将是最后收到的 batch 的信息。 当StreamingMetrics.streaming.lastReceivedBatch_records == 0时,这可能意味着 Spark Streaming 作业已停止或失败。
下面列出了其他重要的 metrics:
- 当总延迟大于批处理间隔时,处理延迟将会增加。
driver.StreamingMetrics.streaming.lastCompletedBatch_totalDelay- 当运行的 task 数低于
number of executors * number of cores时,YARN 分配的资源未充分利用。
executor.threadpool.activeTasks- RDD的缓存使用了多少内存。
driver.BlockManager.memory.memUsed_MB- 当 RDD 缓存没有足够的内存时,有多少数据 spilled 到磁盘。 你应该增加executor 内存或更改
spark.memory.fraction的Spark参数以避免性能下降。
driver.BlockManager.disk.diskSpaceUsed_MB- Spark Driver 上的 JVM 内存利用率是多少
driver.jvm.heap.used
driver.jvm.non-heap.used
driver.jvm.pools.G1-Old-Gen.used
driver.jvm.pools.G1-Eden-Space.used
driver.jvm.pools.G1-Survivor-Space.used- 在Spark Driver上的 GC 花费了多少时间
driver.jvm.G1-Old-Generation.time
driver.jvm.G1-Young-Generation.time- Spark executors 上的 JVM 内存利用率是多少
[0-9]*.jvm.heap.used
[0-9]*.jvm.non-heap.used
[0-9]*.jvm.pools.G1-Old-Gen.used
[0-9]*.jvm.pools.G1-Survivor-Space.used
[0-9]*.jvm.pools.G1-Eden-Space.used- 在Spark executors上的 GC 花费了多少时间
[0-9]*.jvm.G1-Old-Generation.time
[0-9]*.jvm.G1-Young-Generation.time注:本文翻译自:http://mkuthan.github.io/blog/2016/09/30/spark-streaming-on-yarn/