Android面试必问框架原理
Android面试必问框架原理
- volatile的实现原理
- synchronized的实现原理
- join方法实现原理
- CAS无锁编程的原理
- ReentrantLock的实现原理
- AQS的大致实现思路
- AOP理解
- IOC理解
- dagger2注入原理
- hilt原理
- APT技术
- 组件化通信
-
- 使用autoService+ServiceLoader
- ARouter
- Binder
-
- ServiceManager启动
- SM注册流程
- Binder相关类图
- bindService流程图
- 手写Binder实现
- AIDL原理
- Retrofit原理
- OkHttp
-
- 拦截器流程
- Glide原理
-
- 一、简单总结
- 二、with、load、into、都做了什么
- 三、图片加载策略
- 四、缓存流程总结——按场景理解
- 面试准备
- EvenetBus原理
-
- 基本使用
- 源码解析
- okhttp
- Jetpack相关
-
- Lifecycle
- Livedata
-
- LiveData::observe(lifecycleOwner, observer)
- LiveData::setValue VS LiveData::postValue
- viewmodel
- room
- Lifecycle
- Viewmodel相关
- dataBinding
- HTTPS
- TCP和UDP那点事
- DNS解析过程
- 加密
-
- 加密方式和用途
- 如何选择加密方式,怎么加密?
- 如何保证浏览器收到的公钥一定是该网站的公钥
- 什么是数字证书?证书都包含什么?
这些都是一些面试必问的,包括了java一小部分的必问原理知识点,
平时总结出来供自己面试用,也分享给大家,希望我们一起进步,写的不好的地方望指正,有空还在更新中…感谢大家支持~
volatile的实现原理
通过对OpenJDK中的unsafe.cpp源码的分析,会发现被volatile关键字修饰的变量会存在一个“lock:”的前缀。
Lock前缀:Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。
同时该指令会将当前处理器缓存行的数据直接写会到系统内存中,且这个写回内存的操作会使在其他CPU里缓存了该地址的数据无效。
synchronized的实现原理
Synchronized在JVM里的实现都是基于进入和退出Monitor对象来实现方法同步和代码块同步,虽然具体实现细节不一样,但是都可以通过成对的MonitorEnter和MonitorExit指令来实现。
对同步块:
MonitorEnter指令插入在同步代码块的开始位置,当代码执行到该指令时,将会尝试获取该对象Monitor的所有权,即尝试获得该对象的锁,而monitorExit指令则插入在方法结束处和异常处,JVM保证每个MonitorEnter必须有对应的MonitorExit。
对同步方法:
从同步方法反编译的结果来看,方法的同步并没有通过指令monitorenter和monitorexit来实现,相对于普通方法,其常量池中多了ACC_SYNCHRONIZED标示符
join方法实现原理
join方法是通过调用线程的wait方法来达到同步的目的的。
例如A线程中调用了B线程的join方法,则相当于在A线程中调用了B线程的wait方法,当B线程执行完(或者到达等待时间),B线程会自动调用自身的notifyAll方法唤醒A线程,从而达到同步的目的。
CAS无锁编程的原理
CAS的基本思路就是:
如果这个地址上的值和期望的值相等,则给其赋予新值,否则不做任何事儿,但是要返回原值是多少。循环CAS就是在一个循环里不断的做cas操作,直到成功为止。
还可以说说CAS的三大问题。
ABA问题
循环时间长开销大
(⊙o⊙)…第三个暂时忘记了…
ReentrantLock的实现原理
线程可以重复进入任何一个它已经拥有的锁所同步着的代码块,synchronized、ReentrantLock都是可重入的锁。在实现上,就是线程每次获取锁时判定如果获得锁的线程是它自己时,简单将计数器累积即可,每 释放一次锁,进行计数器累减,直到计算器归零,表示线程已经彻底释放锁。
底层则是利用了JUC中的AQS来实现的。
AQS的大致实现思路
AQS内部维护了一个CLH队列来管理锁。线程会首先尝试获取锁,如果失败就将当前线程及等待状态等信息包装成一个node节点加入到同步队列sync queue里。 接着会不断的循环尝试获取锁,条件是当前节点为head的直接后继才会尝试。如果失败就会阻塞自己直到自己被唤醒。而当持有锁的线程释放锁的时候,会唤醒队列中的后继线程。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
AOP理解
在OOP设计中,它导致了大量的代码的重复,而不利于各个模块的重用
将程序中的交叉业务逻辑(比如安全、日志、事务等)封装成一个切面,然后注入到目标对象中去
IOC理解
思想:由主动创建对象变为被动注入
实际上就是一个map,里面存各种对象(在xml里配置的bean节点),项目启动时会读取xml中的bean节点,根据全限定类名使用反射创建对象放到map里
dagger2注入原理
dagger2采用的是APT技术,在编译期间生成java代码,对于注解而言,有效的避免了运行时注解通过反射解析注解信息而影响效率问题。
场景:A类、B类自己写的,A注入B
hilt原理
- 专门面向Android的依赖注入框架
- 相比dagger2,明显特征:1、简单 2、提供了Android专属的API
- 初始化过程原理:
gradlew插件通过字节码插桩。 - 工厂+双重检测的单例
- 目前只支持以下Android类:
Application Activity fragment view service BroadcastReceiver
场景:
presenter注入activity,activity退出时,presenter也可以一起销毁
原理入口:gradlew插件进行字节码插桩
mainActivity extends Hilt_MainActivity
onCreate 中的inject开始,调用InjetMainActivity
APT技术
全称:annotation process tool 一种处理注释的工具,对源代码文件进行检测,找出其中的Annotation,使用Annotation进行额外的处理;
通俗讲:编译期的时候,处理注解,生成Java文件
好处:编译多久不影响界面卡顿
Dagger2
Room
alibaba/ARouter Javapoet来生成java代码
Butterknife
DataBinding
EventBus 早期传统方式一行一行生成java代码
But,for example,XUtils就是通过运行期,注解,反射,一旦耗费2s,就会让界面卡顿
组件化通信
使用autoService+ServiceLoader
缺点:使用反射去实例化对象
优点:易配置,易调试,上手快
ServiceLoader原理:
思考面试题:为啥给一个类能返回一个实现类
谷歌开源用来方便生成符合ServiceLoader规范的开源库,使用非常的简单
首先定义接口,然后使用AutoService注解在实现类声明
然后就轮到ServiceLoader.load方法出场了
思考面试题:使用注解以后会发生什么?
首先会在apk的META-INF文件夹中新建一个service文件夹,然后在下面为我们生成一个配置文件
(app\build\intermediates\javac\debug\compileDebugJavaWithJavac\classes\META-INF\services)
文件名为接口的全包名+类名,里面的内容为实现类的全包名+类名,
一行为实现类,可以同时有多行,这就是AutoService为我做的全部处理
类的加载用的是Java的类加载机制,使用ClassLoader读取META-INF\services下指定文件的内容,然后使用反射实例化对象
参考一下这篇文章:组件化开发新的选择AutoService
ARouter
ARouter 阿里巴巴开源的路由框架,将各组件看成不同的局域网,通过路由做中转站,拦截一些不安全的跳转,或者设定一些拦截服务
ARouter原理:
Arouter.init()
在LogisticsCenter中通过编译时注解,生成三个文件,Group(IRoutGroup) Providers(IproviderGroup),Root(IRouteRoot)
使用Warehouse将文件保存到三个不同的HashMap中,Warehouse相当于路由表,保存着全部模块的跳转关系
通过ARouter.navagation封装postcard对象
通过ARouter索引传递到LogisticsCenter(路由中转站)
询问是否存在跳转对象,如果存在,设置绿色通道开关,判断是否绿色通行和是否能通过拦截服务,
全部通过就会调用ActivityCompat.startActivity方法来跳转到目的Activity
所以Arouter实际还是使用原生的FrameWork机制startActivity,只是通过APT注解的形式制造出跳转规则,并认为的拦截跳转和设置跳转条件
开源路由框架还有哪些?
- ActivityRouter
- 天猫统跳协议
- DeeplinkDispatch
Binder
三个维度来理解Binder
机制:进程间通信的机制
驱动:Binder是一个虚拟物理设备驱动(文件),/dev/binder
应用层:是一个能发起通信的Java类
Binder.java,它实现了IBinder接口,你继承它,就会拥有跨进程的能力
多进程场景
自己创建的进程:webview、视频播放、音乐、大图浏览、推送、进程守护
系统服务:打电话、闹钟等、AMS
多进程优势
内存翻倍:变相增大APP的内存
风险隔离:一个挂了另一个没有影响
Linux进程间通信有哪些?
管道、信号量、共享内存、socket
Binder优势?
拷贝一次
性能仅小于共享内存,优于其他IPC(进程间通信)
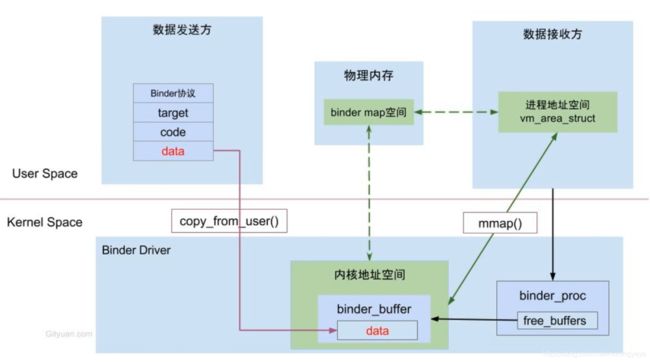
Binder一次拷贝图
面试提问:
如何做到一次拷贝?
内核和接收方用户空间同时映射到一块物理内存
mmap实现
mmap原理
人为指定一块虚拟内存映射到一块已知物理内存
共享内存无需拷贝,怎么实现的?
发送发、接收方、内核空间同时映射到一块物理内存
为什么不用共享内存?
虽然性能好,但不安全
Binder机制如何跨进程的?
数据发送方通过系统调用copy_from_user()拷贝到内核空间,
内核空间有一块虚拟内存和数据接收方虚拟内存共享一块物理内存
- 步骤1:注册服务
Server进程 通过Binder驱动 向 Service Manager进程 注册服务
注册服务后,Binder驱动持有 Server进程创建的Binder实体
- 步骤2:获取服务
Client进程 使用 某个 service前(此处是 相加函数),须通过Binder驱动 向 ServiceManager进程获取相应的Service信息
此时,Client进程与 Server进程已经建立了连接
- 步骤3:使用服务
Client进程 根据获取到的 Service信息(Binder代理对象),通过Binder驱动 建立与 该Service所在Server进程通信的链路,并开始使用服务
对比 Linux (Android基于Linux)上的其他进程通信方式(管道/消息队列/共享内存/信号量/Socket),Binder 机制的优点有:
-
高效
Binder数据拷贝只需要一次,而管道、消息队列、Socket都需要2次
通过驱动在内核空间拷贝数据,不需要额外的同步处理 -
安全性高
Binder 机制为每个进程分配了 UID/PID 来作为鉴别身份的标示,并且在 Binder 通信时会根据 UID/PID 进行有效性检测 -
传统的进程通信方式对于通信双方的身份并没有做出严格的验证
如,Socket通信 ip地址是客户端手动填入,容易出现伪造 -
使用简单
采用Client/Server 架构
实现 面向对象 的调用方式,即在使用Binder时就和调用一个本地对象实例一样
ServiceManager启动
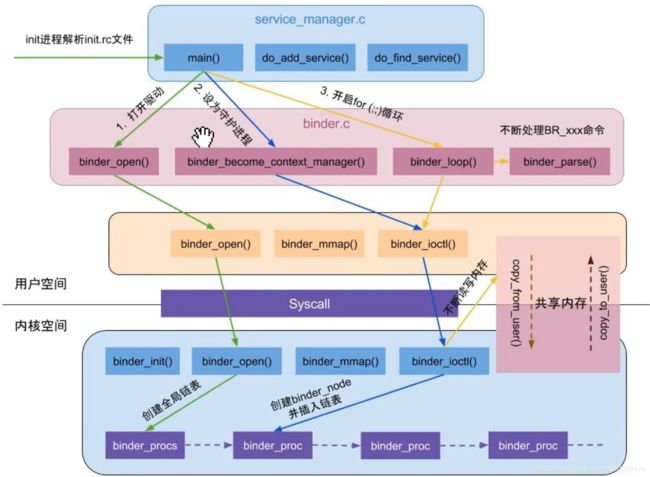
SM注册流程
sm注册
- 打开驱动,内存映射(设置大小 128K)
- 设置 SM 为大管家 — sm 作用 为了管理系统服务
- 创建 binder_node 结构体对象
- proc --> binder_node
- 创建 work 和 todo --> 类似 messageQueue
- BC_ENTER_LOOPER 命令
- 写入状态Loop
- 去读数据:binder_thread_read:ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread)); 进入等待
source code:

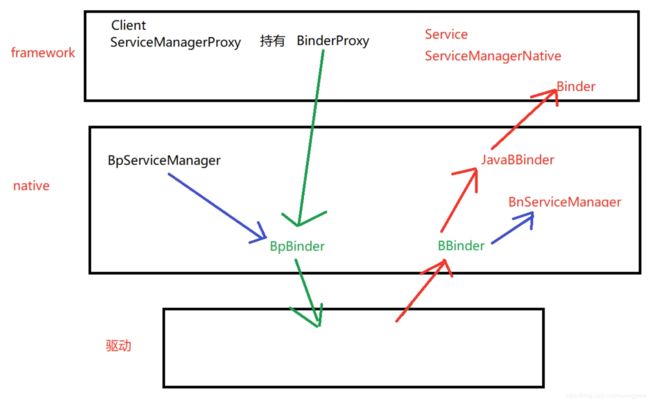
Binder相关类图
bindService流程图
bindService系统如何处理,最后返回到onServiceConnected()
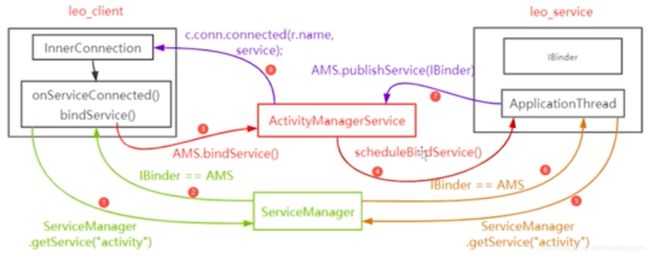
bindService:经历了6次跨进程
图中红色序号:
1、2为一次 1
3、4各一次 3
5、6为一次 4
7、8各一次 6
手写Binder实现
先认识两个接口
Interface source code
public interface IInterface
{
public IBinder asBinder();
}
IInterface接口只有一个方法asBinder()
IBinder source code
public interface IBinder {
public boolean transact(int code, Parcel data, Parcel reply, int flags)
throws RemoteException;
}
IBinder众多接口中有一个重要的方法transact,接收4个参数:
code是处理方法的标记
data是传送数据
reply是服务端响应数据
flags 为0代表成功;1代表失败
定义Person类
public class Person implements Parcelable {
private String name;
private int grade;
public Person(String name, int grade) {
this.name = name;
this.grade = grade;
}
protected Person(Parcel in) {
this.name = in.readString();
this.grade = in.readInt();
}
public static final Creator<Person> CREATOR = new Creator<Person>() {
@Override
public Person createFromParcel(Parcel in) {
return new Person(in);
}
@Override
public Person[] newArray(int size) {
return new Person[size];
}
};
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(name);
dest.writeInt(grade);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", grade=" + grade +
'}';
}
}
定义接口IPersonManager
public interface IPersonManager extends IInterface {
void addPerson(Person person) throws RemoteException;
List<Person> getPersonList() throws RemoteException;
}
定义Proxy类
public class Proxy implements IPersonManager {
private static final String DESCRIPTOR = "com.proxy.binder.common.IPersonManager";
private IBinder mRemote;
public Proxy(IBinder remote) {
mRemote = remote;
}
@Override
public void addPerson(Person person) throws RemoteException {
//1、数据打包
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
try {
//2、数据校验
data.writeInterfaceToken(DESCRIPTOR);
if ((person != null)) {
data.writeInt(1);
person.writeToParcel(data, 0);
} else {
data.writeInt(0);
}
Log.e("Proxy", "Proxy,addPerson: " + Thread.currentThread());
//3、数据传送 mRemote就是Ibinder
mRemote.transact(Stub.TRANSACTION_addPerson, data, reply, 0);
reply.readException();
} finally {
reply.recycle();
data.recycle();
}
}
@Override
public List<Person> getPersonList() throws RemoteException {
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
List<Person> result;
try {
data.writeInterfaceToken(DESCRIPTOR);
mRemote.transact(Stub.TRANSACTION_getPersonList, data, reply, 0);
reply.readException();
result = reply.createTypedArrayList(Person.CREATOR);
} finally {
reply.recycle();
data.recycle();
}
return result;
}
@Override //重写了IInterface接口的asBinder方法
public IBinder asBinder() {
return mRemote;
}
}
Stub类
public abstract class Stub extends Binder implements IPersonManager {
private static final String DESCRIPTOR = "com.proxy.binder.common.IPersonManager";
public Stub() {
this.attachInterface(this, DESCRIPTOR);
}
//判断进程,同进程返回stub,不同进程返回proxy
public static IPersonManager asInterface(IBinder binder) {
if ((binder == null)) {
return null;
}
IInterface iin = binder.queryLocalInterface(DESCRIPTOR);
if ((iin != null) && (iin instanceof IPersonManager)) {
return (IPersonManager) iin;
}
return new Proxy(binder);
}
@Override
public IBinder asBinder() {
return this;
}
@Override
protected boolean onTransact(int code, Parcel data, Parcel reply, int flags) throws RemoteException {
switch (code) {
case INTERFACE_TRANSACTION:
reply.writeString(DESCRIPTOR);
return true;
case TRANSACTION_addPerson:
Log.e("Proxy", "Stub,TRANSACTION_addPerson: " + Thread.currentThread());
data.enforceInterface(DESCRIPTOR);
Person arg0 = null;
if ((0 != data.readInt())) {
arg0 = Person.CREATOR.createFromParcel(data);
}
this.addPerson(arg0);
reply.writeNoException();
return true;
case TRANSACTION_getPersonList:
data.enforceInterface(DESCRIPTOR);
List<Person> result = this.getPersonList();
reply.writeNoException();
reply.writeTypedList(result);
return true;
}
return super.onTransact(code, data, reply, flags);
}
static final int TRANSACTION_addPerson = IBinder.FIRST_CALL_TRANSACTION;
static final int TRANSACTION_getPersonList = IBinder.FIRST_CALL_TRANSACTION + 1;
}
AIDL原理
aidl其实就是利用Binder来实现跨进程调用。而这个系统根据.aidl文件生成的java文件就是对binder的transact方法进行封装。
onTransact方法是提供给server端用的,transact方法(内部类proxy封装了transact方法)和asInterface方法是给client端用的。系统自动生成不知道你要把哪个当做server端哪个当做client端所以就都生成了。
Proxy对应客户端(transact),Stub对应服务端(onTransact)
DESCRIPTION是根据aidl文件位置(包名)来生成的,DESCRIPTION是binder的唯一标识,这也解释了为什么要保证client端和server端.adil文件的包结构一样;
aidl的transact的调用会导致当前线程挂起,因此如果Server端的方法耗时最好另起线程来调用transact方法;
aidl通过Parcel来传递参数和返回值,因为binder只支持Binder对象和parcel对象的跨进程调用;
Binder,IBinder,IInterface三个的关系。Binder是继承自IBinder对象的,IBinder是远程对象的基本接口。另外IBinder的主要API是transact(),与它对应另一方法是Binder.onTransact(),而IInterface主要为aidl服务,里面就一个方法——asBinder,用来获得当前binder对象(方便系统内部调用)。
最后说白了aidl的核心就是client调用binder的transact方法,server通过binder的onTransact方法了来执行相应的方法并返回。
Retrofit原理
1.首先,通过method把它转换成ServiceMethod。
2.然后,通过serviceMethod,args获取到okHttpCall对象。
3.最后,再把okHttpCall进一步封装并返回Call对象。
platform
这个是Retrofit支持的平台,里面有Android和Java8,这里自然是Android
callFactory
执行请求的客户端,这里是OkHttpClient,在创建的时候.client传入
converterFactories
json解析处理工厂数组,这里是GsonConverterFactory。进行请求和响应的解析,将json字符串转换为具体的实体类
callAdapterFactories
请求和响应的具体处理适配器工厂数组,这里没有传的话默认为ExecutorCallAdapterFactory,如果需要使用rxjava,为RxJava2CallAdapterFactory
callbackExecutor
回调处理类,用于对回调数据的处理,这里是Android平台默认的MainThreadExecutor,使用Handler在主线程中处理回调。
OkHttp
拦截器流程
而OkHttp中的getResponseWithInterceptorChain()中经历的流程为
请求会被交给责任链中的一个个拦截器。默认情况下有五大拦截器:
-
RetryAndFollowUpInterceptor第一个接触到请求,最后接触到响应;负责判断是否需要重新发起整个请求
-
BridgeInterceptor补全请求,并对响应进行额外处理
-
CacheInterceptor请求前查询缓存,获得响应并判断是否需要缓存
-
ConnectInterceptor与服务器完成TCP连接
-
CallServerInterceptor与服务器通信;封装请求数据与解析响应数据(如:HTTP报文)
-
一、重试及重定向拦截器
第一个拦截器:RetryAndFollowUpInterceptor,主要就是完成两件事情:重试与重定向。
- 二、桥接拦截器
BridgeInterceptor,连接应用程序和服务器的桥梁,我们发出的请求将会经过它的处理才能发给服务器,
比如设置请求内容长度,编码,gzip压缩,cookie等,获取响应后保存Cookie等操作。这个拦截器相对比较简单。
桥接拦截器的执行逻辑主要就是以下几点
对用户构建的Request进行添加或者删除相关头部信息,以转化成能够真正进行网络请求的Request
将符合网络请求规范的Request交给下一个拦截器处理,并获取Response
如果响应体经过了GZIP压缩,那就需要解压,再构建成用户可用的Response并返回
- 三、缓存拦截器
XXXXXXXXXXXXXXXXXXXXXX - 四、连接拦截器
ConnectInterceptor,这个拦截器中的所有实现都是为了获得一份与目标服务器的连接,在这个连接上进行HTTP数据的收发。
- 五、请求服务器拦截器
CallServerInterceptor,利用HttpCodec发出请求到服务器并且解析生成Response。
Glide原理
一、简单总结
Glide在加载绑定了Activity的生命周期。
在Activity内新建一个无UI的Fragment,这个特殊的Fragment持有一个Lifecycle。通过Lifecycle在Fragment关键生命周期通知RequestManger进行相关的操作。
在生命周期onStart时继续加载,onStop时暂停加载,onDestory是停止加载任务和清除操作。
二、with、load、into、都做了什么

三、图片加载策略
首先从ActivateResource获取,是个值为弱引用的Map
MemoryCache和DiskCache是LruCache
缓存机制加载流程图
- 第一次加载访问
活动缓存,有显示,没有就访问内存缓存 - 内存缓存有,就将内存缓存中的数据
剪切到活动缓存(内存缓存中会删掉),再显示;内存缓存没有,找磁盘缓存; - 磁盘缓存有,
复制一份数据给活动缓存,再显示;磁盘缓存没有,会加载外界资源LoadData数据模型,成功以后,保存到磁盘缓存
四、缓存流程总结——按场景理解
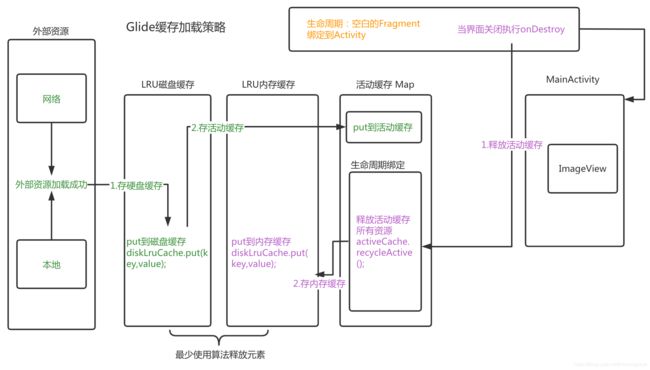
绿色部分:首次加载场景
- 1.第一次加载,去网络下载图片,
保存到磁盘缓存 (/sd/disk_lru_cahe_dir/key),同时存储到活动缓存一份; - 第二次加载,直接在
活动缓存中找到了资源; - 第三次加载,直接在
活动缓存中找到了资源; - 第N次加载,直接在
活动缓存中找到了资源…
紫色部分:Activity销毁场景
把Activity返回时,执行onDestroy,fragment监听到以后,通知进行活动缓存释放(活动缓存 ----> 内存缓存),也就是删除活动缓存,移动到内存缓存中
- 又一次加载时,从
内存缓存中获取到了资源 - 下一次加载时,从
活动缓存获取了资源 - 以后再加载时,从
活动缓存获取了资源 - 第N次加载时,从
活动缓存获取了资源
将APP进程杀死场景
APP杀掉,整个活动缓存,整个内存缓存,都没有了(运行内存缓存)
首次冷启动 所以从磁盘缓存中获取资源
第二次加载时,从活动缓存获取了资源
第三次加载时,从活动缓存获取了资源
第N次加载时,从活动缓存获取了资源
面试准备
Glide的优点
使用简单,链式调用比较方便
Glide.with(context)
.load(uri)
.into(imageView);
- 占用内存较小
- 默认使用
RGB_565格式,是Picasso的内存占用的一半(Picasso使用RGB_8888) - 无代码侵入
- 相对Picasso来说,
接入很简单,无需将ImageView替代为自定义View,也不需要其他配置,只需要将库引入即可 - 支持gif
- ImageLoader不支持gif图片加载
- 缓存优化
1、支持内存分级缓存:正在使用的图片,弱引用缓存;已使用过的图片LruCache缓存
2、Glide会为不同的ImageView尺寸缓存不同尺寸的图片 - 与Activity生命周期绑定,不会出现内存泄露
实现原理
基于在Activity中添加无UI的Fragment,通过Fragment接收Activity传递的生命周期。Fragment和RequestManager基于LifeCycle接口建立联系,并传递生命周期事件,实现生命周期感知。
Glide怎么监听生命周期?
通过无UI的Fragment
如何绑定生命周期?
在调用Glide.with(Activity activity)的时候,总结如下:
- Glide绑定Activity时,生成一个
无UI的Fragment - 将无UI的Fragment的
LifeCycle传入到RequestManager中 - 在RequestManager的构造方法中,将RequestManager存入到之前传入的Fragment的LifeCycle,在回调LifeCycle时会回调到Glide的相应方法
项目中大量使用Glide,偶尔出现内存溢出问题,请说说大概原因?
答:尽量在with的时候,传入有生命周期的作用域(非Application作用域),尽量避免使用Application作用域,因为Application作用域不会对页面绑定生命周期机制
有几种缓存模式?
- DiskCacheStrategy.ALL:原始图片和转换过的图片都缓存
- DiskCacheStrategy.RESOURCE:只缓存原始图片
- DiskCacheStrategy.NONE:不缓存
- DiskCacheStrategy.DATA:只缓存使用过的图片
有几层缓存?
三层,DiskLruCache LruCache ActiveCache
DiskLruCache是硬盘缓存;
LruCache是内存缓存;
ActiveCache是活动缓存
为什么有了 内存缓存 还需要 活动缓存 ?
活动:正在使用的图片,都放在活动缓存 (弱引用 GC 没有使用了 已回收 被动回收) 【资源封装 Key Value】
内存:LRU管理的,临时存放 活动缓存 不使用的Value(LRU最少使用算法) 【资源封装 Key Value】
为什么要活动缓存?
内存:LRU管理的,maxsize,如果最少使用,内部算法会回收(不安全,不稳定)
你正在使用的图片—【活动缓存】如果不用了 才会扫描时回收,[存入 移除 非常快]
活动缓存回收机制:
用弱引用 (GC全盘扫描,判断,弱引用没有被使用,回收)
with
6个重载函数都调用了getRetriever().get()
EvenetBus原理
参考:https://blog.csdn.net/qq_38859786/article/details/80285705
EvenetBus是一种发布-订阅事件总线.代码简洁,开销小,并很好的实现了发送者和接收者的解耦.(是一种观察者模式)
发布者(Publisher)使用post()方法将Event发送到Event Bus,而后Event Bus自动将Event发送到多个订阅者(Subcriber)。
3.0以前订阅者的订阅方法为onEvent()、onEventMainThread()、onEventBackgroundThread()和onEventAsync()。
在Event Bus3.0之后统一采用注解@Subscribe的形式
A,Event:事件,
B,Publisher:发布者,可以在任意线程发布事件
C,Subscrible:订阅者
基本使用
1 添加依赖
compile 'org.greenrobot:eventbus:3.1.1'
2 在接受消息的代码
//注册成为订阅者
EventBus.getDefault().register(this);
//解除注册
EventBus.getDefault().unregister(this);
//订阅方法,当接收到事件的时候,会调用该方法
@Subscribe(threadMode = ThreadMode.MAIN)
public void onEvent(MessageEvent messageEvent){
Log.e("date","receive it");
Toast.makeText(ViewPageStep1Activity.this, messageEvent.getMessage(), Toast.LENGTH_SHORT).show();
}
3 在发送消息的地方
EventBus.getDefault().post(new MessageEvent(“从fragment将数据传递到activity22222222”));
源码解析
- getDefault--------采用单利双重锁模式创建Eventbus对象
static volatile EventBus defaultInstance;
public static EventBus getDefault() {
if (defaultInstance == null) {
synchronized (EventBus.class) {
if (defaultInstance == null) {
defaultInstance = new EventBus();
}
}
}
return defaultInstance;
}
- 构造方法中,粘性事件,保存到ConCurrenHashMap集合
stickyEvents = new ConcurrentHashMap<>(); //线程安全, - register()方法主要做了3件事(过程):
3.1,从缓存中获取订阅方法列表,
3.2,如果缓存中不存在,则通过反射获取到订阅者所有的函数,
3.3,遍历再通过权限修饰符.参数长度(只允许一个参数).注解(@Subscribe)来判断是否是具备成为订阅函数的前提
3.4,具备则构建一个SubscriberMethod(订阅方法,其相当于一个数据实体类,包含方法,threadmode,参数类型,优先级,是否粘性事件这些参数),循环结束订阅函数列表构建完成添加进入缓存
在RunTime期间使用反射对程序运行的性能有较大影响,EventBus3.0中增加了一个新特性:通过在编译期创建索引(SubscriberInfoIndex)就不会用反射获取订阅者方法,而是直接从getSubscriberInfo这个方法里面获取,提高程序运行性能,自己添加索引进行优化。
//通过CopyOnWriteArrayList保存Subscription,Subscription是一个封装类,封装了订阅者、订阅方法这两个类。
//Arraylist效率高,但线程不安全,在多线程的情况下,使用CopyOnWriteArrayList,避免多线程并发异常
- post()
4.1,发送事件:从缓存中获取目标页面接收信息的方法,循环遍历,找到对应的方法,就将信息传递过去.
4.2,post调用后先使用ThreadLocal来存储事件,他可以隔离多个线程对数据的访问冲突(ThreadLocal是每个线程独享的,其数据别的线程是不能访问的,因此是线程安全的。
4.3,根据事件类型(也就是Post参数的类型)为key从subscriptionsByEventType获取订阅方法和订阅者
此时,我们已经具备了订阅者.订阅方法.待发送事件.post线程.threadmode等信息
4.4,根据线程和threadmode来判断
面试题:EventBus 如何实现线程转换的
EventBus 中生产者和消费者模式的实现主要是在 PendingPostQueue里面。
PendingPostQueue 的实现比较简单,主要是通过在 enqueue 和 poll 的时候进行 synchronized 同步来实现的。
EventBus3.0对象池缓存减少了创建对象的开销
okhttp
拦截器就是基于责任链模式,每个节点有自己的职责,同时可以选择是否把任务传递给下一个拦截器
责任链模式,这是Interceptor和Chain的源码以及方法的调用关系,有点像递归,不过两者还是有区别的, 递归函数是不断调用自身,
而这种拦截器的逻辑是两个类(或者说是类内部的方法)不断相互调用,以某个条件作为终结。
面试题:Android类似的设计模式还有什么
- 事件传递机制
- 自定义控件的点击事件拦截
- ClassLoader的双亲委派机制
封装的Chain的内部逻辑
public class MyChain implement Interceptor.Chain{
Arraylist<Interceptor> incpts;
int index = 0;
public MyChain(Arrlist<Interceptor> incpts){
this(incpts, 0);
}
public MyChain(Arrlist<Interceptor> incpts, int index){
this.incpts = incpts;
this.index =index;
}
public void setInterceptors(Arrlist<Interceptor> incpts ){
this.incpts = incpts;
}
@override
Response proceed(Request request) throws IOException{
Response response = null;
...
//取出第一个interceptor来处理
Interceptor incpt = incpts.get(index);
//生成下一个Chain,index标识当前Interceptor的位置。
Interceptor.Chain nextChain = new MyChain(incpts,index+1);
response = incpt.intercept(nextChain);
...
return response;
}
}
public class MyInterceptor implement Intercetpor{
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
//前置拦截逻辑
...
Response response = chain.proceed(request);//传递Interceptor
//后置拦截逻辑
...
return response;
}
}
Jetpack相关
Lifecycle
感知生命周期的组件框架,响应Activity和Fragment生命周期变化并通知观察者,让代码符合生命周期规范,减少内存泄漏。
设计模式:观察者

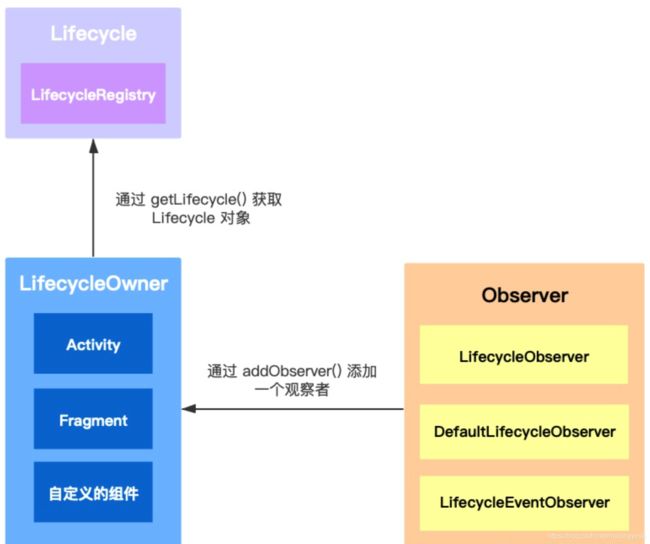
Lifecycle 是一个抽象类。它内部定义了两个枚举;Event 需要分发的事件的类型,State 宿主的状态。
- LifecycleRegistry
它是 Lifecycle 的唯一实现类。主要用来注册观察者(LifecycleObserver),以及分发宿主状态给它们(可以处理多个观察者)。
- LifecycleOwner
AppCompatActivity impl LifeCycleOwer
用来声明它是一个能够提供生命周期事件的宿主,Activity/Fragment 都实现了该接口。内部只有一个 getLifecycle 方法。
public interface LifecycleOwner {
@NonNull
Lifecycle getLifecycle();
}
- LifecycleObserver
用来定义观察者。
看图总结
说明:
- Activity/Fragment 都默认实现了 LifecycleOwner 接口;
- LifecycleRegistry 是 Lifecycle 唯一的实现类;
- 实现观察者(Observer)有三种方式:LifecycleObserver 配合 @OnLifecycleEvent
注解、DefaultLifecycleObserver 拥有宿主所有生命周期事件、LifecycleEventObserver
将宿主生命周期事件封装成 Lifecycle.Event - 在 Activity/Fragment 中通过 getLifecycle() 方法获取到一个 LifecycleRegistry 对象;
- 通过调用 LifecycleRegistry 对象的 addObserver() 添加一个观察者(该观察者通过三种方式实现都可以)。
面试题
-
LifeCycle 是如何监听到 Activity/Fragment 生命周期变化的?
1、在Activity中创建了ReportFragment
2、ReportFragment生命周期中都调用dispatch()方法
3、dispatch中判断Activity是否实现了LifecycleOwer接口,调用LifecycleRegistry的handleLifecycleEvent()
总结:这样生命周期状态就会借由LifecycleRegistry通知各个LifecycleObserver从而调用对应的Lifecycle.Event方法 -
LifeCycle 如何将生命周期变化的事件分发给观察者的?
通过LifecycleRegistry分发,核心代码在dispatch中的 ((LifecycleRegistry) lifecycle).handleLifecycleEvent(event);
@SuppressWarnings("deprecation")
static void dispatch(@NonNull Activity activity, @NonNull Lifecycle.Event event) {
...
if (activity instanceof LifecycleOwner) {
Lifecycle lifecycle = ((LifecycleOwner) activity).getLifecycle();
if (lifecycle instanceof LifecycleRegistry) {
//最终还是通过 LifecycleRegistry 来处理事件的分发
((LifecycleRegistry) lifecycle).handleLifecycleEvent(event);
}
}
}
- Activity 如何实现 LifyCycle?
Activity 实现 Lifecycle 需要借助于 ReportFragment 往 Activity 上添加一个 fragment。ReportFragment 没有任何的页面,它只负责在生命周期变化时利用 LifecycleRegistry 进行相应事件的分发。
之所以需要借助 ReportFragment ,目的是为了兼顾不是继承自 AppCompactActivity 的场景, 同时也支持我们自定义 LifecycleOwner 的场景。
- Fragment 如何实现 LifyCycle
在 Fragment 各个生命周期方法内部会利用 LifecycleRegistry 进行相应的事件分发。
Livedata
LiveData本身是观察者,观察组件的Lifecycle,也是被观察者,数据变化时要通知数据的观察者。
How it works:
- LiveData::observe(lifecycleOwner, observer)
- LiveData::setValue VS LiveData::postValue
LiveData::observe(lifecycleOwner, observer)
在activity/fragment中观察LiveData,我们一般都会创建一个observer实例,调用liveData.observe(lifecycleOwner, observer)方法,在observer的回调方法onChanged中,实现UI的更新,无需再判断当前lifecycle来决定是否要更新。
observe source code
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer<? super T> observer) {
assertMainThread("observe");
if (owner.getLifecycle().getCurrentState() == DESTROYED) {
// ignore
return;
}
LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
owner.getLifecycle().addObserver(wrapper);
}
liveData的成员变量mObservers保存了所有observer和它们各自的相关的lifecycleowner。
在observe方法中,observer和lifecycleOwner包裹成一个新的lifecycleBoundObserver对象,在检查有效性后,observer和包裹后的lifecycleBoundObserver分作为key、value存入mObservers中。
lifecycleBoundObserver实现了LifecycleEventObserver接口。
执行lifecycle.addObserver(lifecycleBoundObserver)后,即可在lifecycle状态(state)变化时,触发lifecycleBoundObserver.onStateChanged,根据lifecycle当前状态,决定observer是否活跃(active), 从而决定是否要接收livedata中的数据更新。
lifeBoundObserver.shouldBeActive方法,定义了lifeCycle至少处于STARTED以及之后状态,observer才是active的。
状态从inactive变成active时,lifeBoundObserver会调用 liveData.dispatchingValue(this) 方法,让liveData把mData中的告知自己,从而通知其包含的observer。
例如,一个在background的activity回到foreground时,其相关的observer也从inactive变成active,也就是onStart后,马上会收到当前livedata中的值。
需要知道的是,lifeCycle不仅会在state真正改变时通知lifecycleBoundObserver。调用 lifecycle.addObserver(lifecycleBoundObserver) 后,它会把达到当前状态前经历的所有LifeCycle.Event都发送给lifecycleBoundObserver。
例如,当前lifeCycle状态为RESUMED, lifecycle.addObserver(lifecycleBoundObserver) 后,
lifeBoundObserver.onStateChanged 马上连续收到ON_CREATE,ON_START,ON_RESUME三个事件。可以想象成“补收”之前的事件。在这种情况下,因为onStateChanged在收到ON_CREATE时,lifecycle已经处于RESUME状态,再STARTED之后,所以observer已是活跃的。所以比如在activity onResume后,onPause前,让一个obsever开始观察livedata,那么这个observer的onChange方法会立马被调用(如果mData已经设置过的情况)。
所以,observer并不只是再数据变化时收到“推送”,也可在lifecycle状态变化时收到通知。
参考 LiveData实现原理
LiveData::setValue VS LiveData::postValue
更新一个MutableLiveData实例中值,需要通过setValue或postValue方法,其中setValue只能在主线程调用。为什么有这样的设计呢?
阅读LiveData(MutableLiveData的父类)源码,其内部使用了俩个volatile修饰的成员变量,mData和mPendingData。
mData保存了最终数据。LiveData实例暴露给外部取值的getValue方法,以及其内部推送数据给观察者时,使用的都是mData。mData只能通过setValue方法更新,即只能由main thread写入,加上volatile的特性(直写main memory而非cpu cache),写入的新值将对所有线程可见。所以不会出现mData更新后,还有线程读取到更新前数据的情况。
那主线程外更新数据怎么实现呢?
就由postValue利用mPendingData完成。
mPendingData中保存了将要但还未被写入mData中的值。postValue方法中,新的数据先被写入mPendingData,然后post一个runnable task到主线程。task中调用setValue方法将mPendingData中的值写入mData,接着清除mPendingData中的值。在postValue和task中,mPendingData的读写都由synchronized block包裹。即postValue中和task中对mPendingData的操作不会并行,避免了postValue对mPendingData的赋值正好被task中mPendingData清除覆盖的情况。
postValue source code
protected void postValue(T value) {
boolean postTask;
synchronized (mDataLock) {
postTask = mPendingData == NOT_SET;
mPendingData = value;
}
if (!postTask) {
return;
}
ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);
}
另外,postValue时,如果当前已有task就不会再post新的task。所以task被执行前,无论postValue被调用多少次,只有最后一次postValue中传入的值,会被更新入mData。也就是说,观察者们不会观察到之前多次postValue中的数据。
task source code
private final Runnable mPostValueRunnable = new Runnable() {
@SuppressWarnings("unchecked")
@Override
public void run() {
Object newValue;
synchronized (mDataLock) {
newValue = mPendingData;
mPendingData = NOT_SET;
}
setValue((T) newValue);
}
};
所以,LiveData 不能直接 被当作 事件线 使用。它的事件是会“丢失”的。它更像是Rx中的BehaviorSubject而非Observerable。除了上述原因,观察者从inActive状态切换到active状态时,会“主动”观察当前LiveData中的值,也是LiveData不可作事件线用的另一个原因。
viewmodel
只是一个容器,数据保存到viewmodel里,当生命周期改变不会丢数据
room
paging 分页组件 recycleview做分页需要自己写代码
做导航 在多fragment,比多个activity跳来跳去好一些
workmanager 管理常见任务,wifi非wifi切换做不同处理,或者一个小时以后上传网络数据
Lifecycle
使用:用一个类作为观察者来观察被观察者MainActivity的生命周期 这个类要实现LifecycleObserver
1)被观察者怎么实现的呢? MainActivity 和fragmentActivity 都 extends ComponentActivity implenments LifecycleOwner
2)被观察者怎么通知观察者,被观察者和观察者怎么绑定在一起? 在被观察者中 getLifecycle().addObserver(presenter)
3) 被观察者生命周期发生变化,观察者在哪里收到消息呢? 类似观察者的update @onLifeCycleEvent注解、反射
原理: getLifecycle().addObserver(presenter)
ComponentActivity的onCreate ReportFragment.injectifNeededIn(this); 不带UI的fragment绑定到activity上面,谷歌抄袭glide源码
反射 状态机
livedata
使用:在ViewModel ViewModelProviders.of(this).get(NamgeViewModel.class);
然后将model和观察者绑定,需要一个观察者来观察数据
Observer observer = new Observer(){
onChanged(String str){
}
}
然后订阅
model.getCurrentName().observe(this,observer);
只要string改变,就会onChanged激活一次
MutableLiveData
LiveDataBus 存放订阅者
需要注册订阅者 提供with方法(key,MutibLivedata)
发送数据 LiveDataBus.getInstance().with("data",String.class).postValue("jett");
接收端怎么接收数据呢? LiveDataBus.getInstance().with("data",String.class).observe(this,new Observer(){
@Override
onChanged(String s){
}
})
Viewmodel相关
在Activity重建时会执行destory生命周期事件,那么为什么ViewModel没有销毁呢?
onRetainNonConfigurationInstance中会存储ViewModelStore实例
fragment之间怎么共享viewmodel?
通过activity的viewmodel
http://www.yanfriends.com/blog/23/
dataBinding
databinding 双向绑定,UI和数据绑定,数据改变,UI一起改变
dataBinding使用了 APT(Annotation Processing Tool)即注解处理器的技术,编译期间会扫描res/layout目录下所有的布局文件,只要有data标签,都会生成两个布局文件:配置文件和带标签的布局文件。
其中配置文件主要是通过tag能够快速定位绑定的控件,生成的布局文件主要是生成控件的tag值
结合生成文件和XML的位置和时间节点,大致可以看出生成的原理是Gradle插件+APT
面试题:dataBinding如何实现双向绑定?
- model->view的过程?
setText
ActivityMainBindlmpl -> executeBindings
android.databinding.adapters.TextViewBindingAdapter.setText(this.mboundView2, userPasswordGet);
用model的属性赋值给控件,这不就是Model到View的过程嘛!model的所有值都会直接刷新控件UI赋值。
- View怎么刷新Model呢?
setTextWatcher
一旦你的view发生了变更,被监听到了,那么它view的值就会被get出来:
android.databinding.adapters.TextViewBindingAdapter.getTextString(mboundView2);拿到这个值之后,就会到model对象赋值,也就是说,View的值输入发生了任何变更,都可以改变Model! 这就是双向绑定!和反射没有任何关系。
ActivityMainBindlmpl.java是通过APT技术自己生成出来的。
HTTPS
可能存在的面试题总结如下:
- 用一段话来总结HTTPS:
HTTPS要使客户端与服务器端的通信过程得到安全保证,必须使用的对称加密算法,但是协商对称加密算法的过程,需要使用非对称加密算法来保证安全,然而直接使用非对称加密的过程本身也不安全,会有中间人篡改公钥的可能性,所以客户端与服务器不直接使用公钥,而是使用数字证书签发机构颁发的证书来保证非对称加密过程本身的安全。这样通过这些机制协商出一个对称加密算法,就此双方使用该算法进行加密解密。从而解决了客户端与服务器端之间的通信安全问题。
- http和https区别?
0.9 1991 get请求
1.0 1996 PUT PATCH HEAD OPTIONS DELETE
1.1 1997 持久连接、节约带宽、HOST域、管道机制、分块传输
2.0 2015 多路复用 一个TCP链接可以请求响应多次
- SSL握手过程?
1、 client请求server 发送信息随机值1+客户端支持的加密算法
2、 server响应握手信息,包括随机值2+匹配好的协商加密算法
3、 server给client发送第二个响应报文是“数字证书”,这套证书就是一对公钥和私钥,传送证书,这个证书就是公钥,只是包含了很多信息,如颁发机构,过期时间,服务端公钥,第三方认证机构的签名,服务端的域名信息
4、 client解析证书,TLS来完成,首先验证公钥是否有效,如果没问题,生成一个随机值(预主密钥)
5、 clinet接下来通过随机值1、随机值2和预主密钥组装会话密钥,然后通过公钥加密会话密钥
6、 client传送加密信息,也就是证书加密的会话秘钥,目的就是让server使用秘钥解密得到随机值1、随机值2和预主秘钥
7、 server解密得到随机值1、随机值2、预主秘钥,然后组装会话秘钥,跟client会话秘钥相同
8、 client通过会话秘钥加密一条消息发送Server,验证server是否正常接收加密的消息
9、 server也会加密一条消息传送client,如果client正常接收,证明SSL层连接建立完成
TCP和UDP那点事
- 灵魂拷问1——TCP和UDP区别?
TCP 是可靠通信协议, 而 UDP 是不可靠通信协议。
TCP 的可靠性含义: 接收方收到的数据是完整, 有序, 无差错的。
UDP 不可靠性含义: 接收方接收到的数据可能存在部分丢失, 顺序也不一定能保证。
- 灵魂拷问2——TCP 协议怎么实现可靠传输?
通信双方需要判断自己已经发送的数据包是否都被接收方收到, 如果没收到, 就需要重发。
为了实现这个需求, 很自然地就会引出序号(sequence number) 和 确认号(acknowledgement number) 的使用。
-
灵魂拷问3——TCP为什么需要握手这个操作, 能不能不握手?
UDP就不用握手,不可靠传输 为了实现可靠传输,发送方和接收方始终需要同步( SYNchronize )序号,所以需要握手确认是否收到消息
三次握手过程
SYN =1 , seq = x
SYN =1, ACK = 1, seq = y , ack = x+1
ACK =1 , seq = x+1, ack = y+1
四次挥手呢?
- 灵魂拷问4——为什么三次握手最后一次握手中, 在上面的示意图中回复的 seq = x+1 。
TCP 协议规定SYN报文虽然不携带数据, 但是也要消耗1个序列号, 所以前两次握手客户端和服务端都需要向对方回复 x+1 或 y+1 。
最后一次握手在默认不携带数据的情况下, 由于SYN 不是 1 , 是不消耗序列号的。 所以三次握手结束后, 客户端下一个发送的报文中 seq 依旧是 x+1
TCP标准规定,ACK报文段可以携带数据,,但如果不携带数据则不消耗序号
-
灵魂拷问5——为什么连接的时候是三次握手,关闭的时候却是四次握手?
关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。
只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送 -
灵魂拷问6——为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
我们必须假象网络是不可靠的,有可以最后一个ACK丢失 lient会设置一个计时器,等待2MSL,如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。 (所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间) -
灵魂拷问7——为什么不能用两次握手进行连接?
3次握手完成两个重要的功能, 既要双方做好发送数据的准备工作(双方都知道彼此已准备好), 也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。 `两次握手,可能发生死锁`
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。 三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤
重点结论:如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认
- 灵魂拷问8——如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,`服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
- 灵魂拷问9——Client为什么要有心跳连接?
如果客户端断线,服务器监听不到吗?
答:能
那为什么要有心跳连接呢?
运营商会定期检查,因为可能出现NAT超时问题
- Https抓包原理
思路:中间人攻击(MITM)
需要考虑:
MITM Server如何伪装成真正的Server;
MITM Client如何伪装成真正的Client。
第一个问题,MITM Server要成为真正的Server,必须能够给指定域名签发公钥证书,且公钥证书能够通过系统的安全校验。比如Client发送了一条https://www.baidu.com/的网络请求,MITM Server要伪装成百度的Server,必须持有www.baidu.com域名的公钥证书并发给Client,同时还要有与公钥相匹配的私钥。
MITM Server的处理方式是从第一个SSL/TLS握手包Client Hello中提取出域名www.baidu.com,利用应用内置的CA证书创建www.baidu.com域名的公钥证书和私钥。创建的公钥证书在SSL/TLS握手的过程中发给Client,Client收到公钥证书后会由系统会对此证书进行校验,判断是否是百度公司持有的证书,但很明显这个证书是抓包工具伪造的。为了能够让系统校验公钥证书时认为证书是真实有效的,我们需要将抓包应用内置的CA证书手动安装到系统中,作为真正的证书发行商(CA),即洗白。这就是为什么,HTTPS抓包一定要先安装CA证书。
第二个问题,MITM Client伪装成Client。由于服务器并不会校验Client(绝大部分情况),所以这个问题一般不会存在。比如Server一般不会关心Client到底是Chrome浏览器还是IE浏览器,是Android App还是iOS App。当然,Server也是可以校验Client的,这个后面分析。
- OkHttp如何防止抓包
1.描述
客户端请求接口数据时,可以使用一些apk完成抓包操作。会获取我们请求的参数和请求成功后的报文。常见的抓包工具有HttpCanary和Fiddler。那么我们在使用OkHttp时,如何防止被这些apk转包呢?其实OkHttp已经为我们提供了相应的方法。
2.原理
OkHttp使ProxySelector来获取代理信息,在构造OkHttpClient时是可以设置的,其默认值是ProxySelector.getDefault(),该默认值会反应出系统的代理信息。
那么我们就可以提供自己的ProxySelector实现来达到绕过系统代理的能力。
3.代码
//配置okHttp的参数
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.connectTimeout(nettimeout, TimeUnit.SECONDS)
//proxySelector方法设置防止抓包
.proxySelector(new ProxySelector() {
@Override
public List<Proxy> select(URI uri) {
return Collections.singletonList(Proxy.NO_PROXY);
}
@Override
public void connectFailed(URI uri, SocketAddress sa, IOException ioe) {
}
})
.build();
DNS解析过程
首先,客户端发出DNS请求翻译IP地址或主机名。DNS 服务器在收到客户机的请求后:
- 检查DNS 服务器的缓存,若查到请求的地址或名字,即向客户机发出应答信息;
- 若没有查到,则在数据库中查找,若查到请求的地址或名字,即向客户机发出应答信息;
- 若没有查到,则将请求发给根域DNS
服务器,并依序从根域查找顶级域,由顶级查找二级域,二级域查找三级,直至找到要解析的地址或名字,即向客户机所在网络的DNS服务器发出应答信息,DNS
服务器收到应答后先在缓存中存储,然后,将解析结果发给客户机。 - 若没有找到,则返回错误信息。
总结:DNS服务器缓存->数据库->根域DNS服务器->顶级域->二级域->三级域->存入缓存
加密
加密方式和用途
1、不可逆加密。比如 MD5、SHA、HMAC
典型用途:
密码总不能明文存到数据库吧,所以一般加密存起来,只要用户的输入经过同样的加密算法 对比一下就知道密码是否正确了,所以没必要可逆。
2、可逆加密。
对称加密。比如:AES、DES、3DES、IDEA、RC4、RC5、RC6
典型用途:
用同一个密码加密和解密,太常见了,我用密码加密文件发给你,你只能用我的密码才能解开。
非对称加密(就是公私钥)。比如:RSA、DSA、ECC
典型用途:
加密(保证数据安全性)使用公钥加密,需使用私钥解密。
认证(用于身份判断)使用私钥签名,需使用公钥验证签名。
如何选择加密方式,怎么加密?
- 用不可逆加密可行吗?
想想目的,这个肯定不可行
- 用对称加密可以行?
不行,秘钥都可能被截获
- 用非对称加密(rsa)可行吗?
试想一下:如果服务器生成公私钥,然后把公钥明文给客户端(有问题,下面说),那客户端以后传数据用公钥加密,服务端用私钥解密就行了,这貌似能保证浏览器到服务端的通道是安全的,那服务端到浏览器的通道
如何保证安全呢?
那既然一对公私钥能保证,那如果浏览器本身也生成一对公私钥匙,然后把公钥明文发给服务端,抛开明文传递公钥的问题,那以后是不是可以安全通信了,的确可以!但https本身却不是这样做的,最主要的原因是非对称加密非常耗时,特别是加密解密一些较大数据的时候有些力不从心,当然还有其他原因。既然非对称加密非常耗时,那只能再考虑对称加密了。
- 用非对称加密 + 对称加密可行吗?(行也得行,不行也得行,因为也没有其他方式了)
上面提到浏览器拥有服务器的公钥,那浏览器生成一个密钥,用服务器的公钥加密传给服务端,然后服务端和浏览器以后拿这个密钥以对称加密的方式通信不就好了!完美!
所以接下来说一下上面遗留的一个问题:服务端的公钥是明文传过去的,有可能导致什么问题呢?
如果服务端在把明文公钥传递给浏览器的时候,被黑客截获下来,然后把数据包中的公钥替换成自己伪造的公钥(当然他自己有自己的私钥),浏览器本身是不知道公钥真假的,所以浏览器还是傻傻的按照之前的步骤,生成对称密钥,然后用假的公钥加密传递给服务端,这个时候,黑客截获到报文,然后用自己的私钥解密,拿到其中的对称密钥,然后再传给服务端,就这样神不知鬼不觉的,对称密钥被黑客截取,那以后的通信其实就是也就全都暴露给黑客了。
公钥不能明文传输,那要怎么办?
淡定的考虑一下,上面的流程到底哪里存在问题,以致使黑客可以任意冒充服务端的公钥!
其实根本原因就是浏览器无法确认自己收到的公钥是不是网站自己的。
如何保证浏览器收到的公钥一定是该网站的公钥
现实生活中,如果想证明某身份证号一定是小明的,怎么办?看身份证。这里国家机构起到了“公信”的作用,身份证是由它颁发的,它本身的权威可以对一个人的身份信息作出证明。互联网中能不能搞这么个公信机构呢?给网站颁发一个“身份证”?当然可以,这就是平时经常说的数字证书。
什么是数字证书?证书都包含什么?
身份证之所以可信,是因为背后是国家,那数字证书如何才可信呢?这个时候找CA(Certificate Authority)机构。办身份证需要填写自己的各种信息,去CA机构申请证书需要什么呢?至少应该有以下几项吧:
1、网站域名
2、证书持有者
3、证书有效期
4、证书颁发机构
5、服务器公钥(最主要)
6、接下来要说的签名时用的hash算法
那证书如何安全的送达给浏览器,如何防止被篡改呢?给证书盖个章(防伪标记)不就好了?这就又引出另外一个概念:数字签名。
未完待续......