Mysql索引分类及其使用实例
Mysql索引
-
- Mysql的索引分类
-
- 单列索引
-
- 创建单列索引的几种方式:
- 唯一索引
-
- 创建唯一索引的几种方式:
- 联合索引(复合索引)
-
- 创建联合索引(复合索引)的方式:
- Mysql的索引类型
-
-
- INDEX | NORMAL 普通索引
- UNIQUE 唯一索引
- PRIMARY KEY 主键索引
- FULLTEXT 全文索引
- SPATIAL 空间索引
-
- Mysql的索引方法
-
-
- BTREE
- HASH
-
- Mysql的索引使用示例
-
-
- 单列索引使用示例
- 复合索引使用示例
-
Mysql的索引分类
MySQL 索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
单列索引
单列索引又可以叫普通索引,一个索引只包含一个列,一个表中可以有多个单列索引.
创建单列索引的几种方式:
- 外部创建
CREATE INDEX indexName ON table_name (column_name)
- 修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
- 创建表的时候直接指定
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
创建唯一索引的几种方式:
- 外部创建
CREATE UNIQUE INDEX indexName ON mytable(username(length))
- 修改表结构(添加索引)
ALTER table mytable ADD UNIQUE [indexName] (username(length))
- 创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
UNIQUE [indexName] (username(length))
);
联合索引(复合索引)
复合索引是索引中功能最强大的一个,索引能够同时覆盖多个数据列,
创建联合索引(复合索引)的方式:
- 外部创建
CREATE INDEX indexName ON mytable(c1,c2,c3...)
Mysql的索引类型
INDEX | NORMAL 普通索引
大多数情况下都可以使用,允许出现相同的索引内容。
UNIQUE 唯一索引
不可以出现相同的值,可以有NULL值,如果该字段信息保证不会重复例如身份证号用作索引时,可以设置为UNIQUE
约束唯一标识数据库表中的每一条记录,即在单表中不能用每条记录是唯一的(例如身份证就是唯一的),UNIQUE(要求列唯一)和Primary Key(primary key = unique + not null 列唯一)约束均为列或列集合中提供了唯一性的保证,Primary Key是拥有自动定义的UNIQUE约束,但是每个表中可以有多个UNIQUE约束,但是只能有一个Primary Key约束。
PRIMARY KEY 主键索引
不允许出现相同的值,且不能为NULL值,一个表只能有一个PRIMARY KEY索引。
FULLTEXT 全文索引
全文索引,可以针对值中的某个单城,比如一篇文章中的某个词,然而并没有什么卵用,因为只有myisam以及英文支持,并且效率让人不敢恭维,但是可以用coreseek和xunsearch等第三方应用来完成这个需求。
SPATIAL 空间索引
空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建。
Mysql的索引方法
BTREE
B树(可以是多叉树),mysql默认使用的方法,通过BTREE算法建立索引的字段,比如扫描20行就能得到未使用BTREE前扫描了2^20行的结果。
HASH
哈希算法,哈希算法通过建立特征值,然后根据特征值来快速查找。这种方式对范围查询支持得不是很好
hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像 BTREE 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 BTREE 索引。
可能很多人又有疑问了,既然 Hash 索引的效率要比 BTREE 高很多,为什么大家不都用 Hash 索引而还要使用 BTREE 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash 索引仅仅能满足”=”,”IN”和”<=>”查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
在实际操作过程中,应该选取表中哪些字段作为索引?
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引,有7大原则:
1.选择唯一性索引
2.为经常需要排序、分组和联合操作的字段建立索引
3.为常作为查询条件的字段建立索引
4.限制索引的数目
5.尽量使用数据量少的索引
6.尽量使用前缀来索引
7.删除不再使用或者很少使用的索引
8. 经常更新修改的字段不要建立索引(针对mysql说,因为字段更改同时索引就要重新建立,排序,而Orcale好像是有这样的机制字段值更改了,它不立刻建立索引,排序索引,而是根据更改个数,时间段去做平衡索引这件事的)
9、不推荐在同一列建多个索引
Mysql的索引使用示例
接下的所有索引操作都围绕这张表进行演示,在演示索引之前,先介绍一下explain,更多内容看菜鸟索引优化
- mysql explain的作用是:
模拟Mysql优化器是如何执行SQL查询语句的,从而知道Mysql是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。(这里只做简单介绍,使用方法,在select语句前加上explain就行了)
单列索引使用示例
1,为monitor_concentration表的site_number字段创建普通索引
-- 创建索引 siteNumber:索引名称唯一,monitor_concentration:表名,site_number:字段名
CREATE INDEX siteNumber ON monitor_concentration(site_number)
成功创建如下:

使用explain 优化查询检测语,查看使用索引和没有使用索引的区别
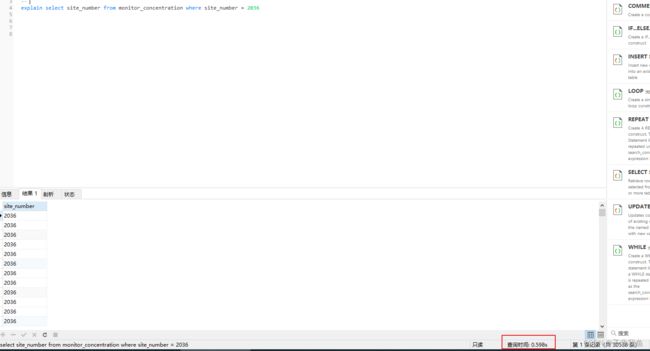
select site_number from monitor_concentration where site_number = 2036
- 没有使用索引前:

可以看到没有使用索引时,查询时间为2.132秒

- 使用索引后:

可以使用了索引在此执行这个语句,查询时间为0.598秒(差距明显)
- 创建的索引不作为条件使用
可以看到返回值用到了索引,在查询该列的时候一样有效,效率比没有索引更高

- 与其他字段配合使用索引
结果一

结果二

结果三

总结单列索引使用方式:可以看出,我们为字段siteNumber创建了索引,通过它来作为条件和返回语句时(作为where条件有它,返回值也有它。不作为where条件,返回值有它即可),查询的时候是能快速的帮助我们实现效果,但是与其他字段在一起使用的时候。起不到效果。所以我们在对单个列作为查询的时候可以使用单列索引。如果想多个字段都能组合使用,下面我使用复合索引来实现(这种方式比单列更常用)
复合索引使用示例
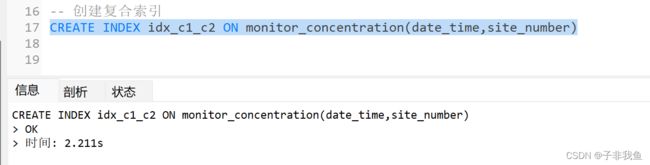
1,为monitor_concentration表的site_number,date_time字段创建复合索引
-- 创建复合索引
CREATE INDEX idx_c1_c2 ON monitor_concentration(date_time,site_number)
成功创建如下:
- 使用
结果一

结果二

结果三

结果四

结果五

结果六

总结复合索引使用方式:从使用几个结果来看,复合索引做到了单列使用方式。在单列索引我们提出想要实现的效果,在复合索引中成功实现。复合索引比较灵活,我们可以根据实际需要来建立复合索引,下面在举一个列子。
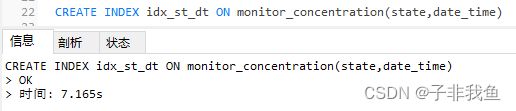
1,给state,date_time创建复合索引
CREATE INDEX idx_st_dt ON monitor_concentration(state,date_time)
- 使用
结果一

结果二

这里就不做过多结果展示了,前面使用复合索引页演示过了(注意之前的结果五和结果六,我这里要做一点更改),我将演示这样的效果
需求,查询monitor_concentration表state=3的最新时间
select max(date_time) date_time from monitor_concentration where state = 3
创建索引后,怎么查询还这么慢,查询时间8.441秒

看到了吗,我们已经为state和date_time建立了复合索引,可是我们这里并没有生效哦!
因为使用聚合函数的列不能使用索引(可是我就是想用到索引怎么办呢。。。可以实现的)

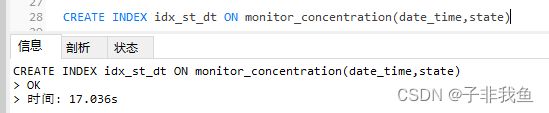
删掉刚才创建的复合索引,重新创建复合索引,这里与上面创建的时候区别在于state和date_time交换了位置
CREATE INDEX idx_st_dt ON monitor_concentration(date_time,state)
- 重新使用
select max(date_time) date_time from monitor_concentration where state = 3
可以看到,比刚才有明显的差距,查询时间1.819

可以看到,这次我们创建的复合索引是有效的

创建复合索引字段顺序总结:通过列子可以看到,如果我们在使用比较特殊的语句,想要使其生效的话,我们对复合索引字段的顺序需要注意一下。从这里得出,作为条件的列应当放在返回使用的列后面