K8S 三种探针ReadinessProbe、LivenessProbe和StartupProbe 之探索
一、事件背景
因为k8s中采用大量的异步机制,以及多种对象关系设计上的解耦,当应用实例数增加/删除、或者应用版本发生变化触发滚动升级时,系统并不能保证应用相关的service、ingress配置总是及时能完成刷新。在一些情况下,往往只是新的pod完成自身初始化,系统尚未完成Endpoint、负载均衡器等对外部可达的访问信息刷新,老的Pod就立即被删除,最终造成服务短暂的不可用,这对于生产来说是不可结束的,所以k8s就加入了一些存活性探针:
StartupProbe,LivenessPorbe、ReadinessProbe。
二、Pod状态
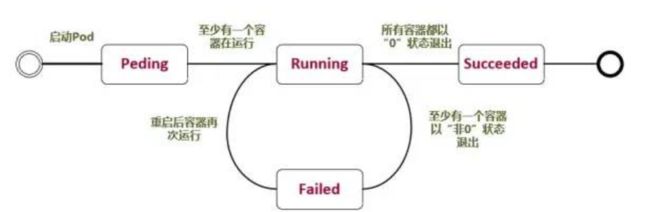
2.1、Pod常见的状态
Pending:挂起,我们在请求创建pod时,条件不满足,调度没有完成,没用任何一个节点满足调度条件。已经创建了但是没用合适它运行的节点叫挂起,这其中也包含集群为容器创建网络,或者下载镜像的过程。
Running:Pod内所有的容器已经被创建,且至少一个容器正在处于运行状态、正在启动状态或者重启状态。
Successed:Pod中所有容器都执行成功后退出,并且没有处于重启的容器。
Failed:Pod中所有容器已退出,但是至少还有一个容器退出时为失败状态。
Unkonw:未知状态,所谓pod是什么状态是apiserver和运行在pod节点的kubelet进行通信获取状态信息的,如果节点之上的kubelet本身出故障,那么apiserver就连不上kubelet,得不到信息了,就会看Unkonw。
2.2、Pod重启策略
Always:只要容器失效退出就重新启动容器。
OnFailure:当容器以非正常(异常)退出后才自动重新启动容器。
Nerver:无论容器状态如何,都不重新启动容器。
Pod常见状态转换场景
Pod中的容器数 |
Pod状态 |
发生事件 |
不同重启策略下的结果状态 |
||
Always |
OnFailure |
Nerver |
|||
包含一个容器 |
Running |
容器成功退出 |
Running |
Succeded |
Succeded |
包含一个容器 |
Running |
容器失败退出 |
Running |
Running |
Failed |
包含两个容器 |
Running |
1个容器失败退出 |
Running |
Running |
Running |
包含两个容器 |
Running |
容器内存溢出挂掉 |
Running |
Running |
Failed |
2.3、探针简介
K8S提供了三种探针
ReadinessProbe
LivenessProbe
StartupProbe
探针存在的目的
在Kubernetes中Pod是最小的计算单元,而一个Pod又由多个容器组成,相当于每个容器就是一个应用,应用在运行期间,可能因为某些意外情况致使程序挂掉,那么如何监控这些容器状态稳定性,保证服务在运行期间不会发生问题,发生问题后进行重启等机制,就成为了重中之重的事情,考虑到这点kubernetes推出了存活性探针机制,有了存活性探针能保证程序在运行之中如果挂掉能够 自动重启,但是还有个检测遇到的问题,比如说,在kubernetes中启动Pod,显示明明Pod启动成功,且能访问里面的端口,但是却返回错误信息。还有就是在执行滚动更新时候,总会出现一段时间,Pod 对外提供网络访问,但是访问却发生 404,这两个原因,都是因为 Pod 已经成功启动,但是 Pod 的的容器中应用程序还在启动中导致,考虑到这点 Kubernetes 推出了就绪性探针机制。
LivenessProbe:存活性探针,用于判断容器是不是健康,如果不满足健康条件,那么 Kubelet 将根据 Pod 中设置的 restartPolicy (重启策略)来判断,Pod 是否要进行重启操作。LivenessProbe 按照配置去探测 ( 进程、或者端口、或者命令执行后是否成功等等),来判断容器是不是正常。如果探测不到,代表容器不健康(可以配置连续多少次失败才记为不健康),则 kubelet 会杀掉该容器,并根据容器的重启策略做相应的处理。如果未配置存活探针,则默认容器启动为通过(Success)状态。即探针返回的值永远是 Success。即 Success 后 pod 状态是 RUNING
ReadinessProb:就绪探针,用于判断容器内的程序是否存活(或者说是否健康),只有程序(服务)正常,容器开始对外提供网络访问(启动完成并就绪)。容器启动后按照ReadinessProb配置进行探测,无问题后结果为成功即状态为Success。Pod的READY状态为true,从0/1变为1/1.如果失败继续为0/1。状态为false。若未配置就绪探针,则默认状态容器启动后为Success。对于此Pod关联的service资源、EndProb的关系也将基于Pod的Read状态进行设置,如果Pod运行过程中Ready状态变为false,则系统自动从 Service 资源 关联的 EndPoint 列表中去除此 pod,届时 service 资源接收到 GET 请求后,kube-proxy 将一定不会把流量引入此 pod 中,通过这种机制就能防止将流量转发到不可用的 Pod 上。如果 Pod 恢复为 Ready 状态。将再会被加回 Endpoint 列表。kube-proxy 也将有概率通过负载机制会引入流量到此 pod 中。
StartupProbe: StartupProbe 探针,主要解决在复杂的程序中 ReadinessProbe、LivenessProbe 探针无法更好地判断程序是否启动、是否存活。进而引入 StartupProbe 探针为 ReadinessProbe、LivenessProbe 探针服务。
(★)ReadinessProbe 与 LivenessProbe 的区别
ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
LivenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
(★) StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
如果三个探针同时存在,先执行StartupProbe探针,其他两个探针将会被暂时禁用,直到pod满足StartupProbe探针配置的条件,其他2个探针启动,如果不满足按照规则重启容器。另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而StartupProbe探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
2.4、正确的ReadinessProbe与LivenessProbe使用方式
LivenessProbe 和 ReadinessProbe 两种探针都支持下面三种探测方法:
ExecAction:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
HTTPGetAction:通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 - 200 且小于 400,则认为容器健康。
TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
探针探测结果有以下值
Success:表示通过检测。
Failure:表示未通过检测。
Unknown:表示检测没有正常进行。
LivenessProbe 和 ReadinessProbe 两种探针的相关属性 探针(Probe)有许多可选字段,可以用来更加精确的控制 Liveness 和 Readiness 两种探针的行为(Probe):
initialDelaySeconds:容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0
periodSeconds:执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1
timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”,最小值是 1
successThreshold:探针检测失败后认为成功的最小连接成功次数,默认为 1s,在 Liveness 探针中必须为 1s,最小值为 1s。
failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod 会被标记为未就绪,默认为 3s,最小值为 1s
Tips:initialDelaySeconds 在 ReadinessProbe 其实可以不用配置,不配置默认 pod 刚启动,开始进行 ReadinessProbe 探测,但那又怎么样,除了 StartupProbe,ReadinessProbe、LivenessProbe 运行在 pod 的整个生命周期,刚启动的时候 ReadinessProbe 检测失败了,只不过显示 READY 状态一直是 0/1,ReadinessProbe 失败并不会导致重启 pod,只有 StartupProbe、LivenessProbe 失败才会重启 pod。而等到多少 s 后,真正服务启动后,检查 success 成功后,READY 状态自然正常
2.5、正确的 StartupProbe 使用方式
StartupProbe 探针支持下面三种探测方法:
ExecAction:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
HTTPGetAction:通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器 健康。
TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
探针探测结果有以下值:
Success:表示通过检测。
Failure:表示未通过检测。
Unknown:表示检测没有正常进行。
StartupProbe 探针属性
initialDelaySeconds:容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0
periodSeconds:执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1
timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”,最小值是 1
successThreshold:探针检测失败后认为成功的最小连接成功次数,默认为 1s,在 Liveness 探针中必须为 1s,最小值为 1s。
failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod 会被标记为未就绪,默认为 3s,最小值为 1s
Tips:在 StartupProbe 执行完之后,其他 2 种探针的所有配置才全部启动,相当于容器刚启动的时候,所以其他 2 种探针如果配置了 initialDelaySeconds,建议不要给太长。
三、使用举例
3.1、LivenessProbe 探针使用示例
通过 exec 方式做健康探测
[root@master ~]# vim liveness-exec.yamlapiVersion: v1
kind: Pod
metadata:
name: liveness-exec
labels:
app: liveness
spec:
containers:
- name: liveness
image: busybox
args: #创建测试探针探测的文件
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
LivenessProbe:
initialDelaySeconds: 10 #延迟检测时间
periodSeconds: 5 #检测时间间隔
exec: #使用命令检查
command: #指令,类似于运行命令sh
- cat #sh 后的第一个内容,直到需要输入空格,变成下一行
- /tmp/healthy #由于不能输入空格,需要另外声明,结果为sh cat"空格"/tmp/healthy思路整理:
容器在初始化后,执行(/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600")首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用 cat 命令输出 healthy 文件的内容,如果能成功执行这条命令一次(默认 successThreshold:1),存活探针就认为探测成功,由于没有配置(failureThreshold、timeoutSeconds),所以执行(cat /tmp/healthy)并只等待 1s,如果 1s 内执行后返回失败,探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
通过 HTTP 方式做健康探测
[root@localhost ~]# vi liveness-http.yamlapiVersion: v1
kind: Pod
metadata:
name: liveness-http
labels:
test: liveness
spec:
containers:
- name: liveness
image: test.com/test-http-prober:v0.0.1
LivenessProbe:
failureThreshold: 5 #检测失败5次表示未就绪
initialDelaySeconds: 20 #延迟加载时间
periodSeconds: 10 #重试时间间隔
timeoutSeconds: 5 #超时时间设置
successThreshold: 2 #检查成功为2次表示就绪
httpGet:
scheme: HTTP
port: 8081
path: /ping思路整理:在 pod 启动后,初始化等待 20s 后,LivenessProbe 开始工作,去请求 http://Pod_IP:8081/ping 接口,类似于 curl -I http://Pod_IP:8081/ping 接口,考虑到请求会有延迟(curl -I 后一直出现假死状态),所以给这次请求操作一直持续 5s,如果 5s 内访问返回数值在>=200 且<=400 代表第一次检测 success,如果是其他的数值,或者 5s 后还是假死状态,执行类似(ctrl+c)中断,并反回 failure 失败。等待 10s 后,再一次地去请求 http://Pod_IP:8081/ping 接口。如果有连续的 2 次都是 success,代表无问题。如果期间有连续的 5 次都是 failure,代表有问题,直接重启 pod,此操作会伴随 pod 的整个生命周期。Tips Http Get 探测方式有如下可选的控制字段:
scheme: 用于连接 host 的协议,默认为 HTTP。host:要连接的主机名,默认为 Pod IP,可以在 Http Request headers 中设置 host 头部。port:容器上要访问端口号或名称。path:http 服务器上的访问 URI。httpHeaders:自定义 HTTP 请求 headers,HTTP 允许重复 headers。
通过 TCP 方式做健康探测
[root@localhost ~]# vi liveness-tcp.yamlapiVersion: v1
kind: Pod
metadata:
name: liveness-tcp
labels:
app: liveness
spec:
containers:
- name: liveness
image: nginx
LivenessProbe:
initialDelaySeconds: 15
periodSeconds: 20
tcpSocket:
port: 80思路整理:TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个 LivenessProbe 探针,尝试连接容器的 80 端口,类似于 telnet 80 端口。每隔 20 秒(periodSeconds)做探测,如果连接失败则将杀死 Pod 重启容器。
3.2ReadinessProbe 探针使用示例
ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。
[root@localhost ~]# vim readiness-exec.yamlapiVersion: v1
kind: Pod
metadata:
name: readiness-exec
labels:
app: readiness-exec
spec:
containers:
- name: readiness-exec
image: busybox
args: #创建测试探针探测的文件
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
LivenessProbe:
initialDelaySeconds: 10
periodSeconds: 5
exec:
command:
- cat
- /tmp/healthy
---
apiVersion: v1
kind: Pod
metadata:
name: readiness-http
labels:
app: readiness-http
spec:
containers:
- name: readiness-http
image: test.com/test-http-prober:v0.0.1
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
ReadinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /ping
---
apiVersion: v1
kind: Pod
metadata:
name: readiness-tcp
labels:
app: readiness-tcp
spec:
containers:
- name: readiness-tcp
image: nginx
LivenessProbe:
initialDelaySeconds: 15
periodSeconds: 20
tcpSocket:
port: 80Tips: terminationGracePeriodSeconds 不能用于 ReadinessProbe,如果将它应用于 ReadinessProbe 将会被 apiserver 接口所拒绝
LivenessProbe:
httpGet:
path: /ping
port: liveness-port
failureThreshold: 1
periodSeconds: 30
terminationGracePeriodSeconds: 30 # 宽限时间30s3.3StartupProbe 探针使用示例
[root@localhost ~]# vim startup.yamlapiVersion: v1
kind: Pod
metadata:
name: startup
labels:
app: startup
spec:
containers:
- name: startup
image: nginx
StartupProbe:
failureThreshold: 3 # 失败阈值,连续几次失败才算真失败
initialDelaySeconds: 5 # 指定的这个秒以后才执行探测
timeoutSeconds: 10 # 探测超时,到了超时时间探测还没返回结果说明失败
periodSeconds: 5 # 每隔几秒来运行这个
httpGet:
path: /test
prot: 80思路整理:在容器启动 initialDelaySeconds (5 秒) 参数设定的时间后,kubelet 将发送第一个 StartupProbe 探针,尝试连接容器的 80 端口。如果连续探测失败没有超过 3 次 (failureThreshold) ,且每次探测间隔为 5 秒 (periodSeconds) 和探测执行时间不超过超时时间 10 秒/每次 (timeoutSeconds),则认为探测成功,反之探测失败,kubelet 直接杀死 Pod。
四、总结
通过对三种探针的探索,我们能够得到一句话的总结:理解底层结构,能够最大程度在可用性、安全性,持续性等方面让 Pod 达到最佳工作状态。凡事没有“银弹”,尤其对重要的业务需要一个案例一个解决方案,希望这次的分析能提供给大家开启一个思路之门。