《Stream流的学习与使用》
文章目录
-
- 实例
- Stream API说明
- 为什么要使用Stream API
- Stream使用流程
- Stream的中间操作 - 筛选与切片
- Stream的中间操作 - 映射
- Stream的中间操作 - 排序
- Stream的终止操作 - 匹配与查找
- Stream的终止操作 - 归约
- Stream的终止操作 - 收集
实例
Java 8新特性:list.stream().map().collect()
Stream
Stream(流)是一个来自数据源的元素队列并支持聚合操作;
map
map 方法用于映射每个元素到对应的结果;
Collectors
Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素。Collectors 可用于返回列表或字符串。
[name=ymw, age=30, name=yh, age=30]
获取其中某个属性的集合:
List collection = list.stream().map(Student::getAge).collect(Collectors.toList());
System.out.println(collection.toString());
返回结果:[30, 30]
集合里过滤数据的方式:
//过滤
List<InfoDto> alarmList = values.stream().filter(alarm -> {
if(objectList.contains(alarm.getUid())){
return true;
}else{
return false;
}
}).collect(Collectors.toList());
https://www.cnblogs.com/_ymw/p/14685878.html
list().stream().collect(Collectors.groupingby(Entity::getFild))的用法
这里的Map的Key类型和实体类字段一致,收集到的就是按照该字段作为KEY,有该字段的实例类的list集合作为value的MAP集合
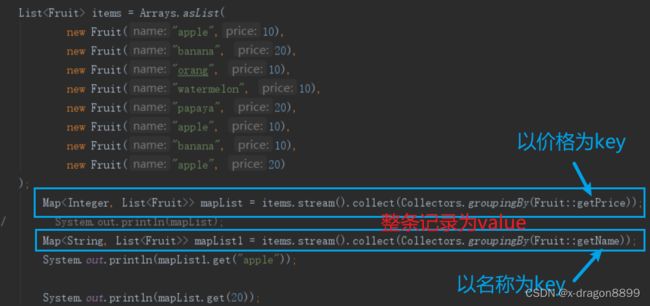

https://blog.csdn.net/m0_47073109/article/details/120906467
集合list使用stream.sorted的方式进行排序
按年龄进行排序,默认升序
List studentsSortName = studentList.stream()
.sorted(Comparator.comparing(StudentInfo::getAge)).collect(Collectors.toList());
以下是先按年龄再按身高,默认不写是升序
reversed是降序
List studentsSortName = studentList.stream()
.sorted(Comparator.comparing(StudentInfo::getAge).reversed().thenComparing(StudentInfo::getHeight))
.collect(Collectors.toList());
Stream API说明


为什么要使用Stream API


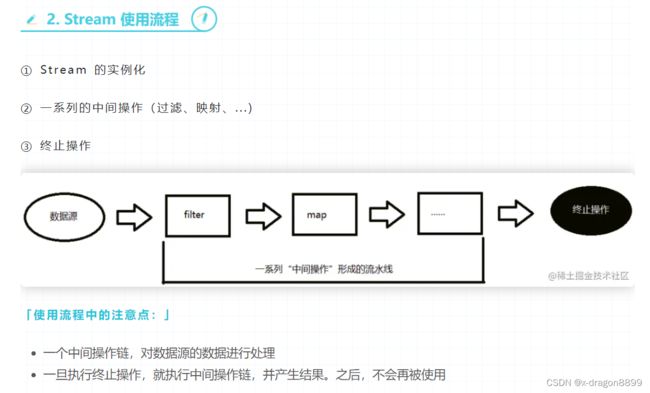
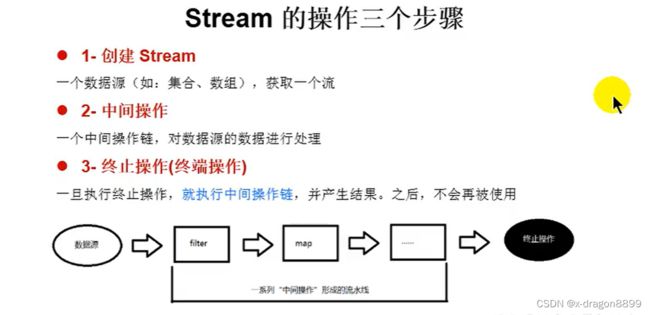
Stream使用流程
Stream的中间操作 - 筛选与切片

1-筛选与切片,注意执行终止操作后,Stream流就被关闭了,使用时需要再次创建Stream流
//1-筛选与切片,注意执行终止操作后,Stream流就被关闭了,使用时需要再次创建Stream流
@Test
public void test1(){
List<Employee> employees = EmployeeData.getEmployees();
//filter(Predicate p)——接收 Lambda , 从流中排除某些元素。
Stream<Employee> employeeStream = employees.stream();
//练习:查询员工表中薪资大于7000的员工信息
employeeStream.filter(e -> e.getSalary() > 7000).forEach(System.out::println);
//limit(n)——截断流,使其元素不超过给定数量。
employeeStream.limit(3).forEach(System.out::println);
System.out.println();
//skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
employeeStream.skip(3).forEach(System.out::println);
//distinct()——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
employees.add(new Employee(1010,"刘庆东",56,8000));
employees.add(new Employee(1010,"刘庆东",56,8000));
employees.add(new Employee(1010,"刘庆东",56,8000));
employees.add(new Employee(1010,"刘庆东",56,8000));
employeeStream.distinct().forEach(System.out::println);
}
Stream的中间操作 - 映射

//2-映射
@Test
public void test2(){
List<String> list = Arrays.asList("aa", "bb", "cc", "dd");
//map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
list.stream().map(str -> str.toUpperCase()).forEach(System.out::println);
//练习1:获取员工姓名长度大于3的员工的姓名。
List<Employee> employees = EmployeeData.getEmployees();
Stream<String> nameStream = employees.stream().map(Employee::getName);
nameStream.filter(name -> name.length() >3).forEach(System.out::println);
System.out.println();
//练习2:使用map()中间操作实现flatMap()中间操作方法
Stream<Stream<Character>> streamStream = list.stream().map(StreamAPITest2::fromStringToStream);
streamStream.forEach(s ->{
s.forEach(System.out::println);
});
System.out.println();
//flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
Stream<Character> characterStream = list.stream().flatMap(StreamAPITest2::fromStringToStream);
characterStream.forEach(System.out::println);
}
//将字符串中的多个字符构成的集合转换为对应的Stream的实例
public static Stream<Character>fromStringToStream(String str){
ArrayList<Character> list = new ArrayList<>();
for (Character c :
str.toCharArray()) {
list.add(c);
}
return list.stream();
}
//map()和flatMap()方法类似于List中的add()和addAll()方法
@Test
public void test(){
ArrayList<Object> list1 = new ArrayList<>();
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
ArrayList<Object> list2 = new ArrayList<>();
list2.add(5);
list2.add(6);
list2.add(7);
list2.add(8);
list1.add(list2);
System.out.println(list1);//[1, 2, 3, 4, [5, 6, 7, 8]]
list1.addAll(list2);
System.out.println(list1);//[1, 2, 3, 4, [5, 6, 7, 8], 5, 6, 7, 8]
}
Stream的中间操作 - 排序
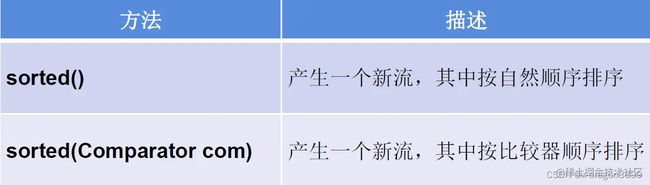
//3-排序
@Test
public void test3(){
//sorted()——自然排序
List<Integer> list = Arrays.asList(12, 34, 54, 65, 32);
list.stream().sorted().forEach(System.out::println);
//抛异常,原因:Employee没有实现Comparable接口
List<Employee> employees = EmployeeData.getEmployees();
employees.stream().sorted().forEach(System.out::println);
//sorted(Comparator com)——定制排序
List<Employee> employees1 = EmployeeData.getEmployees();
employees1.stream().sorted((e1,e2)->{
int ageValue = Integer.compare(e1.getAge(), e2.getAge());
if (ageValue != 0){
return ageValue;
}else {
return -Double.compare(e1.getSalary(),e2.getSalary());
}
}).forEach(System.out::println);
}
Stream的终止操作 - 匹配与查找
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、 Integer,甚至是 void
流进行了终止操作后,不能再次使用。


//1-匹配与查找
@Test
public void test1(){
List<Employee> employees = EmployeeData.getEmployees();
//allMatch(Predicate p)——检查是否匹配所有元素。
//练习:是否所有的员工的年龄都大于18
boolean allMatch = employees.stream().allMatch(e -> e.getAge() > 18);
System.out.println(allMatch);
//anyMatch(Predicate p)——检查是否至少匹配一个元素。
//练习:是否存在员工的工资大于 5000
boolean anyMatch = employees.stream().anyMatch(e -> e.getSalary() > 5000);
System.out.println(anyMatch);
//noneMatch(Predicate p)——检查是否没有匹配的元素。
//练习:是否存在员工姓“雷”
boolean noneMatch = employees.stream().noneMatch(e -> e.getName().startsWith("雷"));
System.out.println(noneMatch);
//findFirst——返回第一个元素
Optional<Employee> first = employees.stream().findFirst();
System.out.println(first);
//findAny——返回当前流中的任意元素
Optional<Employee> employee = employees.parallelStream().findAny();
System.out.println(employee);
}
@Test
public void test2(){
List<Employee> employees = EmployeeData.getEmployees();
// count——返回流中元素的总个数
long count = employees.stream().filter(e -> e.getSalary()>5000).count();
System.out.println(count);
//max(Comparator c)——返回流中最大值
//练习:返回最高的工资
Stream<Double> salaryStream = employees.stream().map(e -> e.getSalary());
Optional<Double> maxSalary = salaryStream.max(Double::compareTo);
System.out.println(maxSalary);
//min(Comparator c)——返回流中最小值
//练习:返回最低工资的员工
Optional<Double> minSalary = employees.stream().map(e -> e.getSalary()).min(Double::compareTo);
System.out.println(minSalary);
//forEach(Consumer c)——内部迭代
employees.stream().forEach(System.out::println);
System.out.println();
//使用集合的遍历操作
employees.forEach(System.out::println);
}
Stream的终止操作 - 归约
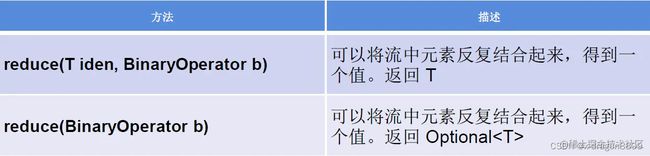
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名.
//2-归约
@Test
public void test3(){
//reduce(T identity, BinaryOperator)——可以将流中元素反复结合起来,得到一个值。返回 T
//练习1:计算1-10的自然数的和
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = list.stream().reduce(0, Integer::sum);
System.out.println(sum);
//reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。返回 OptionalStream的终止操作 - 收集

Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)
Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例具体方法与实例如下表:


//3-收集
@Test
public void test4(){
//collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
//练习1:查找工资大于6000的员工,结果返回为一个List或Set
List<Employee> employees = EmployeeData.getEmployees();
List<Employee> employeeList = employees.stream().filter(e -> e.getSalary() > 6000).collect(Collectors.toList());
employeeList.forEach(System.out::println);
System.out.println();
Set<Employee> employeeSet = employees.stream().filter(e -> e.getSalary() > 6000).collect(Collectors.toSet());
employeeSet.forEach(System.out::println);
}