Spark16:【案例】实战:TopN主播统计:SparkSQL进行实现
一、实战:TopN主播统计
在前面讲Spark core的时候我们讲过一个案例,TopN主播统计,计算每个大区当天金币收入TopN的主播,之前我们使用spark中的transformation算子去计算,实现起来还是比较麻烦的,代码量相对来说比较多,下面我们就使用咱们刚学习的Spark sql去实现一下,你会发现,使用sql之后确实简单多了。
回顾以下我们的两份原始数据,数据都是json格式的
video_info.log 主播的开播记录,其中包含主播的id:uid、直播间id:vid 、大区:area、视频开播时长:length、增加粉丝数量:follow等信息
gift_record.log 用户送礼记录,其中包含送礼人id:uid,直播间id:vid,礼物id:good_id,金币数量:gold 等信
最终需要的结果是这样的
US 8407173251015:180,8407173251012:70,8407173251001:60
1、分析一下具体步骤
1、直接使用SparkSession中的load方式加载json的数据
2、对这两份数据注册临时表
3、执行sql计算TopN主播
4、使用foreach将结果打印到控制台
2、数据准备
主播开播记录数据如下:
video_info.log
{"uid":"8407173251001","vid":"14943445328940001","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":101,"share_num":"21","type":"video_info"}
{"uid":"8407173251002","vid":"14943445328940002","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":201,"share_num":"331","type":"video_info"}
{"uid":"8407173251003","vid":"14943445328940003","area":"CN","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":221,"share_num":"321","type":"video_info"}
{"uid":"8407173251004","vid":"14943445328940004","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":401,"share_num":"311","type":"video_info"}
{"uid":"8407173251005","vid":"14943445328940005","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":31,"share_num":"131","type":"video_info"}
{"uid":"8407173251006","vid":"14943445328940006","area":"CN","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":22,"share_num":"3431","type":"video_info"}
{"uid":"8407173251007","vid":"14943445328940007","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":44,"share_num":"131","type":"video_info"}
{"uid":"8407173251008","vid":"14943445328940008","area":"CN","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":66,"share_num":"131","type":"video_info"}
{"uid":"8407173251009","vid":"14943445328940009","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":32,"share_num":"231","type":"video_info"}
{"uid":"8407173251010","vid":"14943445328940010","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":342,"share_num":"431","type":"video_info"}
{"uid":"8407173251011","vid":"14943445328940011","area":"CN","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":223,"share_num":"331","type":"video_info"}
{"uid":"8407173251012","vid":"14943445328940012","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":554,"share_num":"312","type":"video_info"}
{"uid":"8407173251013","vid":"14943445328940013","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":334,"share_num":"321","type":"video_info"}
{"uid":"8407173251014","vid":"14943445328940014","area":"CN","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":653,"share_num":"311","type":"video_info"}
{"uid":"8407173251015","vid":"14943445328940015","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":322,"share_num":"231","type":"video_info"}
{"uid":"8407173251001","vid":"14943445328940016","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":432,"share_num":"531","type":"video_info"}
{"uid":"8407173251005","vid":"14943445328940017","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":322,"share_num":"231","type":"video_info"}
{"uid":"8407173251008","vid":"14943445328940018","area":"CN","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":564,"share_num":"131","type":"video_info"}
{"uid":"8407173251010","vid":"14943445328940019","area":"ID","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":324,"share_num":"231","type":"video_info"}
{"uid":"8407173251015","vid":"14943445328940020","area":"US","status":"1","start_time":"1494344544","end_time":"1494344570","watch_num":532,"share_num":"331","type":"video_info"}
用户送礼记录数据如下:
gift_record.log
{"uid":"7201232141001","vid":"14943445328940001","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141002","vid":"14943445328940001","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141003","vid":"14943445328940002","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141004","vid":"14943445328940002","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141005","vid":"14943445328940003","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141006","vid":"14943445328940003","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141007","vid":"14943445328940004","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141008","vid":"14943445328940004","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141009","vid":"14943445328940005","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141010","vid":"14943445328940005","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141011","vid":"14943445328940006","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141012","vid":"14943445328940006","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141013","vid":"14943445328940007","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141014","vid":"14943445328940007","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141015","vid":"14943445328940008","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141016","vid":"14943445328940008","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141017","vid":"14943445328940009","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141018","vid":"14943445328940009","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141019","vid":"14943445328940010","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141020","vid":"14943445328940010","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141021","vid":"14943445328940011","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141022","vid":"14943445328940011","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141023","vid":"14943445328940012","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141024","vid":"14943445328940012","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141025","vid":"14943445328940013","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141026","vid":"14943445328940013","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141027","vid":"14943445328940014","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141028","vid":"14943445328940014","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141029","vid":"14943445328940015","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141030","vid":"14943445328940015","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141031","vid":"14943445328940016","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141032","vid":"14943445328940016","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141033","vid":"14943445328940017","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141034","vid":"14943445328940017","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141035","vid":"14943445328940018","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141036","vid":"14943445328940018","good_id":"223","gold":"10","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141037","vid":"14943445328940019","good_id":"223","gold":"20","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141038","vid":"14943445328940019","good_id":"223","gold":"30","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141039","vid":"14943445328940020","good_id":"223","gold":"40","timestamp":1494344574,"type":"gift_record"}
{"uid":"7201232141040","vid":"14943445328940020","good_id":"223","gold":"50","timestamp":1494344574,"type":"gift_record"}
3、scala代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:计算TopN主播
* 1:直接使用sparkSession中的load方式加载json数据
* 2:对这两份数据注册临时表
* 3:执行sql计算TopN主播
* 4:使用foreach将结果打印到控制台
*
*/
object TopNAnchorScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpScala")
.config(conf)
.getOrCreate()
//1:直接使用sparkSession中的load方式加载json数据
val videoInfoDf = sparkSession.read.json("D:\\video_info.log")
val giftRecordDf = sparkSession.read.json("D:\\gift_record.log")
//2:对这两份数据注册临时表
videoInfoDf.createOrReplaceTempView("video_info")
giftRecordDf.createOrReplaceTempView("gift_record")
//3:执行sql计算TopN主播
val sql ="select "+
"t4.area, "+
"concat_ws(',',collect_list(t4.topn)) as topn_list "+
"from( "+
"select "+
"t3.area,concat(t3.uid,':',cast(t3.gold_sum_all as int)) as topn "+
"from( "+
"select "+
"t2.uid,t2.area,t2.gold_sum_all,row_number() over (partition by area order by gold_sum_all desc) as num "+
"from( "+
"select "+
"t1.uid,max(t1.area) as area,sum(t1.gold_sum) as gold_sum_all "+
"from( "+
"select "+
"vi.uid,vi.vid,vi.area,gr.gold_sum "+
"from "+
"video_info as vi "+
"join "+
"(select "+
"vid,sum(gold) as gold_sum "+
"from "+
"gift_record "+
"group by vid "+
")as gr "+
"on vi.vid = gr.vid "+
") as t1 "+
"group by t1.uid "+
") as t2 "+
")as t3 "+
"where t3.num <=3 "+
") as t4 "+
"group by t4.area "
val resDf = sparkSession.sql(sql)
//4:使用foreach将结果打印到控制台
resDf.rdd.foreach(row=>println(row.getAs[String]("area")+"\t"+row.getAs[String]("topn_list")))
sparkSession.stop()
}
}
结果输出如下:
SQL如下:
select
t4.area,
concat_ws(',',collect_list(t4.topn)) as topn_list
from(
select
t3.area,concat(t3.uid,':',cast(t3.gold_sum_all as int)) as topn
from(
select
t2.uid,t2.area,t2.gold_sum_all,row_number() over (partition by area order by gold_sum_all desc) as num
from(
select
t1.uid,max(t1.area) as area,sum(t1.gold_sum) as gold_sum_all
from(
select
vi.uid,vi.vid,vi.area,gr.gold_sum
from
video_info as vi
join
(select
vid,sum(gold) as gold_sum
from
gift_record
group by vid
)as gr
on vi.vid = gr.vid
) as t1
group by t1.uid
) as t2
)as t3
where t3.num <=3
) as t4
group by t4.area
4、java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 需求:计算TopN主播
* 1:直接使用sparkSession中的load方式加载json数据
* 2:对这两份数据注册临时表
* 3:执行sql计算TopN主播
* 4:使用foreach将结果打印到控制台
*
*/
public class TopNAnchorJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("TopNAnchorJava")
.config(conf)
.getOrCreate();
//1:直接使用sparkSession中的load方式加载json数据
Dataset videoInfoDf = sparkSession.read().json("D:\\video_info.log");
Dataset giftRecordDf = sparkSession.read().json("D:\\gift_record.log");
//2:对这两份数据注册临时表
videoInfoDf.createOrReplaceTempView("video_info");
giftRecordDf.createOrReplaceTempView("gift_record");
//3:执行sql计算TopN主播
String sql = "select "+
"t4.area, "+
"concat_ws(',',collect_list(t4.topn)) as topn_list "+
"from( "+
"select "+
"t3.area,concat(t3.uid,':',cast(t3.gold_sum_all as int)) as topn "+
"from( "+
"select "+
"t2.uid,t2.area,t2.gold_sum_all,row_number() over (partition by area order by gold_sum_all desc) as num "+
"from( "+
"select "+
"t1.uid,max(t1.area) as area,sum(t1.gold_sum) as gold_sum_all "+
"from( "+
"select "+
"vi.uid,vi.vid,vi.area,gr.gold_sum "+
"from "+
"video_info as vi "+
"join "+
"(select "+
"vid,sum(gold) as gold_sum "+
"from "+
"gift_record "+
"group by vid "+
")as gr "+
"on vi.vid = gr.vid "+
") as t1 "+
"group by t1.uid "+
") as t2 "+
")as t3 "+
"where t3.num <=3 "+
") as t4 "+
"group by t4.area ";
Dataset resDf = sparkSession.sql(sql);
//4:使用foreach将结果打印到控制台
resDf.javaRDD().foreach(new VoidFunction() {
@Override
public void call(Row row) throws Exception {
System.out.println(row.getString(0)+"\t"+row.getString(1));
}
});
sparkSession.stop();
}
}
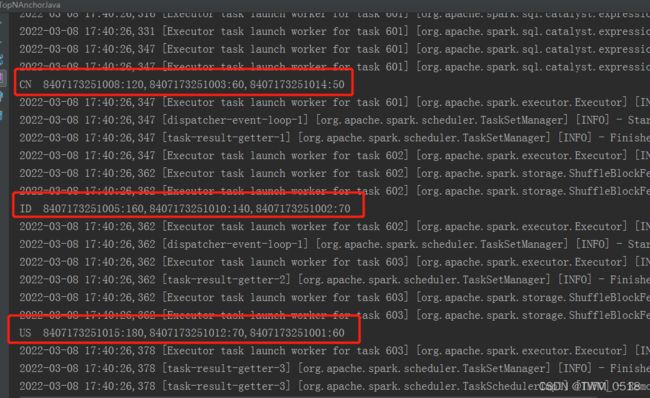
代码执行结果如下:
CN 8407173251008:120,8407173251003:60,8407173251014:50
ID 8407173251005:160,8407173251010:140,8407173251002:70
US 8407173251015:180,8407173251012:70,8407173251001:60
5、提交任务到集群运行
最后我们希望将这个任务提交到集群去执行
新建一个object:TopNAnchorClusterScala,修改代码,将任务的输出数据保存到hdfs上面
代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:计算TopN主播
* 1:直接使用sparkSession中的load方式加载json数据
* 2:对这两份数据注册临时表
* 3:执行sql计算TopN主播
* 4:使用foreach将结果打印到控制台
*
*/
object TopNAnchorClusterScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpScala")
.config(conf)
.getOrCreate()
//1:直接使用sparkSession中的load方式加载json数据
val videoInfoDf = sparkSession.read.json("hdfs://bigdata01:9000/video_info.log")
val giftRecordDf = sparkSession.read.json("hdfs://bigdata01:9000/gift_record.log")
//2:对这两份数据注册临时表
videoInfoDf.createOrReplaceTempView("video_info")
giftRecordDf.createOrReplaceTempView("gift_record")
//3:执行sql计算TopN主播
val sql ="select "+
"t4.area, "+
"concat_ws(',',collect_list(t4.topn)) as topn_list "+
"from( "+
"select "+
"t3.area,concat(t3.uid,':',cast(t3.gold_sum_all as int)) as topn "+
"from( "+
"select "+
"t2.uid,t2.area,t2.gold_sum_all,row_number() over (partition by area order by gold_sum_all desc) as num "+
"from( "+
"select "+
"t1.uid,max(t1.area) as area,sum(t1.gold_sum) as gold_sum_all "+
"from( "+
"select "+
"vi.uid,vi.vid,vi.area,gr.gold_sum "+
"from "+
"video_info as vi "+
"join "+
"(select "+
"vid,sum(gold) as gold_sum "+
"from "+
"gift_record "+
"group by vid "+
")as gr "+
"on vi.vid = gr.vid "+
") as t1 "+
"group by t1.uid "+
") as t2 "+
")as t3 "+
"where t3.num <=3 "+
") as t4 "+
"group by t4.area "
val resDf = sparkSession.sql(sql)
//4:使用foreach将结果打印到控制台
resDf.rdd
.map(row=>row.getAs[String]("area")+"\t"+row.getAs[String]("topn_list"))
.saveAsTextFile("hdfs://bigdata01:9000/out-topn")
sparkSession.stop()
}
}
修改pom中依赖的配置,全部设置为provided
org.apache.spark
spark-core_2.11
2.4.3
provided
com.alibaba
fastjson
1.2.68
provided
org.apache.spark
spark-sql_2.11
2.4.3
provided
针对spark-core和spark-sql在打包的时候是不需要的,针对fastjson有的spark job是需要的,不过建议在这设置为provided,打包的时候不要打进去,在具体使用的时候可以在spark-submit脚本中通过–jar来动态指定这个jar包,最好把这个jar包上传到hdfs上面统一管理和维护。
编译打包,上传到bigdta04上的/data/soft/sparkjars目录
创建spark-submit脚本
[root@bigdata04 sparkjars]# vi topnJob.sh
spark-submit \
--class com.imooc.scala.sql.TopNAnchorClusterScala \
--master yarn \
--deploy-mode cluster \
--executor-memory 1g \
--num-executors 5 \
--executor-cores 2 \
--conf "spark.default.parallelism=10" \
db_spark-1.0-SNAPSHOT-jar-with-dependencies.jar
提交任务
[root@bigdata04 sparkjars]# sh -x topnJob.sh
查看结果
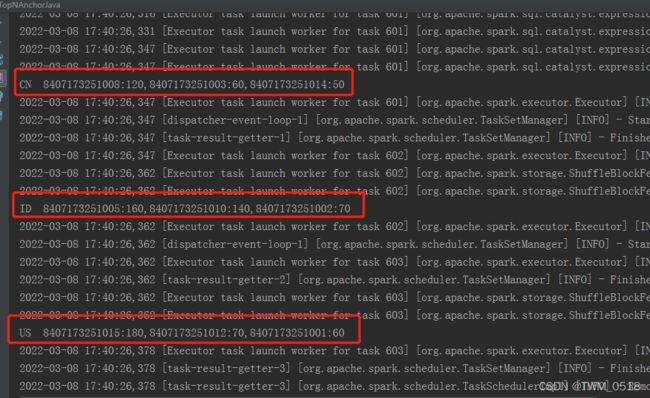
[root@bigdata04 sparkjars]# hdfs dfs -cat /out-topn/*
CN 8407173251008:120,8407173251003:60,8407173251014:50
ID 8407173251005:160,8407173251010:140,8407173251002:70
US 8407173251015:180,8407173251012:70,8407173251001:60