Python MySQL数据库的连接以及基本操作
Python MySQL数据库的连接以及基本操作
- 一、数据库的连接
-
- 1、直接连接
- 2、连接池连接
- 二、 数据库的基本操作
-
- 1、执行函数
- 2、创建数据表
- 3、删除表
- 4、插入函数
- 6、删除函数
- 7、状态判断函数
- 8、修改函数
- 9、查询函数
- 三、全部代码
一、数据库的连接
这里主要介绍python中直接连接MySQL数据库和通过连接池连接数据库的两种连接方式
1、直接连接
直接连接是一种十分基础的连接方式,代码十分简单。DBHOST表示数据库的ip地址
DBUSER和DBPASS分别为安装数据库时使用的账号和密码,DBNAME为数据库的名称
具体代码如下:
import pymysql
DBHOST = "localhost"
DBUSER = "root"
DBPASS = "root"
DBNAME = "xiaogenggou"
try:
conn = pymysql.connect(DBHOST,DBUSER,DBPASS,DBNAME)
print("数据库成功连接")
except pymysql.Error as e:
print("数据库连接失败")
运行结果如下:
数据库成功连接
2、连接池连接
参考博客:https://blog.csdn.net/qq_29113041/article/details/99690070
连接池连接相对于直接连接的优点有:
1、减少连接创建时间;
2、简化的编程模式;
3、受控的资源使用
在连接池连接中要使用到PooledDB()函数,其中所需变量的含义分别为:
‘creator’:使用链接数据库的模块
‘host’:数据库的IP地址
‘port’:MySQL的端口号(安装时默认为3306)
‘user’:登录MYSQL时用的账号
‘password’:登录MYSQL时用的密码
‘db’:所要连接的数据库的名称
‘charset’:编码方式
‘cursorclass’:指针
关于with和__enter__()以及__exit__():
当代码运行时运行数据大致如下:
执行with语句–》执行__enter__()–》with语句的子内容–》执行__exit__()
因此我们可以借助with,enter,exit轻松完成从池中取出数据库,关闭数据库等工作,具体的在下文数据库基本操作会涉及。
具体代码如下:
class MysqlPool():
config = {
'creator': pymysql,
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root',
'db': 'xiaogenggou',
'charset': 'utf8',
'maxconnections': 70, # 连接池最大连接数量
'cursorclass': pymysql.cursors.DictCursor
}
#借助连接池连接数据库
pool = PooledDB(**config)
def __enter__(self):
self.conn = MysqlPool.pool.connection()
self.cursor = self.conn.cursor()
return self
def __exit__(self, type, value, trace):
self.cursor.close()
self.conn.close()
二、 数据库的基本操作
本文对数据库的基本操作编写了部分函数,但仅针对涉及到全部或者单列的函数。多列的同时操作的函数本文并没有给出。
1、执行函数
本文的其余函数将借助执行函数来进行python与数据库的交互。
部分代码含义:
1、db.cursor.execute():此函数有两个变量,第一个为数据库的操作语句其中value值用%s代替,类似于java中的?,第二个为%s所代表的含义。
2、db.conn.commit():将python中数据提交到数据库,如不执行此函数数据库中的内容将不会更新。
3、db.cursor.fetchall():数据的获取,返回的结果为由字典构成的列表即[{},{},{}]
如[{‘user_id’: 11, ‘username’: ‘test6’, ‘sex’: ‘女’, ‘age’: 22, ‘state’: 1}, {‘user_id’: 12, ‘username’: ‘test6’, ‘sex’: ‘女’, ‘age’: 22, ‘state’: 1}]
# 执行函数
def execute(database_commands, s_value=None, i=0):
"""
:param database_commands: 数据库的执行语句
:param s_value: %s代表的变量名称
:param i: 执行判断符,当i为1时执行状态判断 ,默认值为0
"""
# 捕获异常,并报错
try:
with MysqlPool() as db:
#o(* ̄︶ ̄*)o此处调用__enter__()
# 执行操作命令 database_commands:数据库的查询语句 s_value:当查询语句出现%s时%s对应的值,默认为None
db.cursor.execute(database_commands, s_value)
# 向数据库提交命令
db.conn.commit()
# 当执行查询操作时打印并返回查询的数据
if "select" in database_commands and i == 0:
# 打印查询的全部数据,fetchall()的返回值为list格式的字典集
print(db.cursor.fetchall())
# 返回查询的全部数据
return db.cursor.fetchall()
elif i == 1:
return db.cursor.fetchall()
#o(* ̄︶ ̄*)o此处调用__exit__()
except Exception as e:
print("恭喜你,异常了,又可以改bug了,开心吗")
#(ง •_•)ง
2、创建数据表
先把表建好剩下的之后再说(●ˇ∀ˇ●)
这里我们借助IDEA来查看数据库的状态(用命令行和pycharm也行,但命令行太不直观,idea是我之前就配置完的,而pycharm我有点懒得弄)
创建表之前让如下图(其实这是我原来一个作业的,本来有一个表被我不小心删了,幸好里头还没啥数据,改天还要把那个表写回来,心就很累>﹏<)
之后执行我们的创建代码
代码如下:
# 创建表
def test_create():
# 编写创建主表main_test的语句
sql_create_test = "create table test" \
"(user_id int auto_increment primary key," \
"username varchar(11)," \
"sex nvarchar(1)," \
"age int(3)," \
"state int(1) DEFAULT 1 )"
# 创建表test
execute(sql_create_test)
test_create()
test表我一共设置了5个属性:
user_id :设置了从一自动增长,并设置成了主键(从一的自动增长很重要,数据小的时候查询可能感觉不到,数据大了之后借助user_id的值可以进行二分查找等,大大缩小查询时间,减的不是一点半点,真的很重要( o=^•ェ•)o ┏━┓)
username 用户名 11个字符,(一般都用varchar(10),但我一般用户名都用xiaogenggou,这破用户名11个字节,所以我设了varchar(11))
sex 性别(就设了1个字符,记得输汉字,我曾经不知道为啥狂输"man",然后一运行一堆错)
age 年龄
state 插入数据时默认值为1 之后的代码中在0和1之间反复横跳,用来表式状态,是用来回避手一抖,把数据删了找不回来的情况,值为0的时候我们就当这行不存在(删了)。
运行之后的结果:
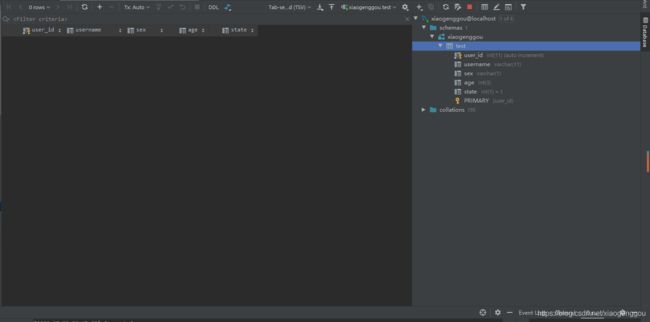
3、删除表
xiaogenggou在这提醒您,慎用,毕竟删了找回来太麻烦了(血的教训)(╬▔皿▔)凸
ps:前文提到的state是针对对表内数据的操作,跟删除表没啥关系
代码如下:
# 删除表
def test_table_drop():
# 编写删除表的语句
sql_test_drop = "drop table test"
# 删除表
execute(sql_test_drop)
test_table_drop()
运行完结果如下:
最后再强调一遍:慎用,慎用!
真就一夜回到解放前,啥都没了,有数据哭都来不及
容我再去创个表>﹏<
4、插入函数
借助for循环插入代码,我还特意引了numpy库来写随机数<(  ̄^ ̄)(θ(θ☆( >_<
代码如下:
import numpy as np
# 向数据表内插入数据
def test_insert(username, sex, age, table="test"):
"""
:param username: 用户名称
:param sex: 用户性别
:param age: 用户年龄
:param table: 数据表的名称
"""
# 编写插入语句,%s表示元素的占位符
sql_insert = "insert into " + table + " (username,sex,age) values(%s,%s,%s)"
# 表示从左到右每个占位符所表示的元素的内容
value = (username, sex, age)
# 插入数据
execute(sql_insert, value)
for i in range(10):
value_username = "test" + str(i + 1)
a = np.random.permutation(2)
if a[1] == 1:
value_sex = "男"
else:
value_sex = "女"
value_age = int(20 + a[0])
test_insert(value_username, value_sex, value_age)
还收获了个意外的知识点:
np.random.permutation(2)返回的矩阵里的数的数据类型是int32,但我们要用的是int类型,所以要记得转换(在调试途中我深刻意识到了我之前写的异常抛出机制有多么欠揍)
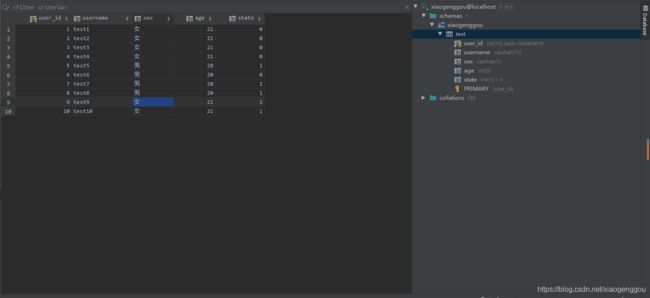
运行完成后结果如下(如果删除了表记得先建回来):

6、删除函数
前面已经提到过很多次了,删除数据和表一定要谨慎,谨慎再谨慎。毕竟有些东西一但放手就再也收回来了(;´д`)ゞ。所以我们这里采用state的0和1来表示行的存在与否。state的值为0,我们就认为是把他给删了。
代码如下:
# 删除user_id对应的元组(用state值为0代替)
def test_delete(user_id):
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0:
print("该行已被删除")
else:
# 编写删除语句
sql_delete = "update test set state = %s where user_id = %s"
# 将state的值改为0,代表删除
value = (0, user_id)
# 执行删除操作
execute(sql_delete, value)
for i in range(1, 11):
u_id = i
a = np.random.permutation(2)
print(a[1])
if a[1] == 0:
test_delete(u_id)
state_judgement()为下文写的状态判断函数
结果如下:
7、状态判断函数
来判断元组是否被删除(state变为0)的函数,刚刚的删除函数以及下文的函数都将用到该函数。
代码如下:
# 进行元组状态的判断,1表示存在,0表示已被删除
def state_judgement(user_id):
"""
:param user_id: 判断状态的元组的主键(id)
:return: 状态判断值
"""
# 当user_id超出范围时报错
try:
# 编写判断的语句,%s表示元素的占位符
sql_state_judgement = "select state from test where user_id = %s"
# 表示从左到右每个占位符所表示的元素的内容
value = user_id
# 存储返回的list
ls = execute(sql_state_judgement, value, 1)
# 返回代表状态的0或1
return ls[0]["state"]
except Exception as e:
print("亲,错了呢")
for i in range(1, 11):
print(state_judgement(i))
结果如下:
0
0
0
0
1
0
1
1
1
1
8、修改函数
实在不知道说啥了(* ̄3 ̄)╭
代码如下:
def test_update(event_attribute, new_value, user_id):
"""
:param event_attribute: 要更改的属性名
:param new_value: 更改后的属性内容
:param user_id: 更改属性的元组的主键(id)
"""
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0 and event_attribute != "state":
print("该行已被删除")
else:
# 编写更新语句,%s表示元素的占位符
sql_update = "update test set " + event_attribute + " = %s where user_id = %s "
# 表示从左到右每个占位符所表示的元素的内容
value = (new_value, user_id)
# 更改数据
execute(sql_update, value)
for i in range(1, 11):
test_update("age", 40 + i, i)
结果如下:
该行已被删除
该行已被删除
该行已被删除
该行已被删除
该行已被删除

可以看到state值为0的行,默认已经删除,不受影响,而通过test_update()函数,我们将state值为1的行的年龄都改变了。
9、查询函数
查询函数我分了两种,一种是查询所选行全部的属性。一种是查询所选行特定的一种属性。
查询全部属性的代码如下:
def test_query_all(user_id=None):
"""
:param user_id: 更改属性的元组的主键(id)
"""
# 当未指定user_id时查询全部元组的数据
if user_id is None:
# 编写查询语句
sql_query_all = "select * from test where state = 1"
# 执行查询
execute(sql_query_all)
else:
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0:
print("该行已被删除")
else:
# 编写查询根据user_id确定的某一元组的全部数据
sql_query_all = "select * from test where user_id = %s"
# 表示从左到右每个占位符所表示的元素的内容
value = user_id
# 执行查询
execute(sql_query_all, value)
test_query_all()
运行结果:
[{'user_id': 5, 'username': 'test5', 'sex': '男', 'age': 45, 'state': 1}, {'user_id': 7, 'username': 'test7', 'sex': '男', 'age': 47, 'state': 1}, {'user_id': 8, 'username': 'test8', 'sex': '男', 'age': 48, 'state': 1}, {'user_id': 9, 'username': 'test9', 'sex': '女', 'age': 49, 'state': 1}, {'user_id': 10, 'username': 'test10', 'sex': '女', 'age': 50, 'state': 1}]
查询特定某一属性的代码如下:
# 查询副表test中某一元组的某一属性的数据
def test_query(event_attribute, user_id=None):
"""
:param event_attribute:查询的属性的名称
:param user_id: 更改属性的元组的主键(id)
"""
# 当未指定user_id时查询全部元组的数据
if user_id is None:
# 编写查询全部元组某一属性的语句
sql_query = "select " + event_attribute + " from test where state = 1"
# 执行查询
execute(sql_query)
else:
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0:
print("该行已被删除")
# 编写查询查询根据user_id确定的某一元组的某一属性的数据
else:
sql_query = "select " + event_attribute + " from test where user_id = %s"
# 表示从左到右每个占位符所表示的元素的内容
value = user_id
# 执行查询
execute(sql_query, value)
test_query("username")
运行结果如下:
[{'username': 'test5'}, {'username': 'test7'}, {'username': 'test8'}, {'username': 'test9'}, {'username': 'test10'}]
三、全部代码
import pymysql
from DBUtils.PooledDB import PooledDB
import numpy as np
class MysqlPool():
config = {
'creator': pymysql,
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root',
'db': 'xiaogenggou',
'charset': 'utf8',
'maxconnections': 70, # 连接池最大连接数量
'cursorclass': pymysql.cursors.DictCursor
}
pool = PooledDB(**config)
def __enter__(self):
self.conn = MysqlPool.pool.connection()
self.cursor = self.conn.cursor()
return self
def __exit__(self, type, value, trace):
self.cursor.close()
self.conn.close()
# 执行函数
def execute(database_commands, s_value=None, i=0):
"""
:param database_commands: 数据库的执行语句
:param s_value: %s代表的变量名称
:param i: 执行判断符,当i为1时执行状态判断 ,默认值为0
"""
# 错误捕获,并报错
try:
with MysqlPool() as db:
# 执行操作命令 database_commands:数据库的查询语句 s_value:当查询语句出现%s时%s对应的值,默认为None
db.cursor.execute(database_commands, s_value)
# 向数据库提交命令
db.conn.commit()
# 当执行查询操作时打印并返回查询的数据
if "select" in database_commands and i == 0:
# 打印查询的全部数据,fetchall()的返回值为list格式的字典集
print(db.cursor.fetchall())
# 返回查询的全部数据
return db.cursor.fetchall()
elif i == 1:
return db.cursor.fetchall()
except Exception as e:
print("恭喜你,有错,又可以改bug了,开心吗")
# 创建表的函数
def test_create():
# 编写创建主表main_test的语句
sql_create_test = "create table test" \
"(user_id int auto_increment primary key," \
"username varchar(11)," \
"sex nvarchar(1)," \
"age int(3)," \
"state int(1) DEFAULT 1 )"
# 创建表test
execute(sql_create_test)
# test_create()
# 删除表
def test_table_drop():
# 编写删除表的语句
sql_test_drop = "drop table test"
# 删除表
execute(sql_test_drop)
# test_table_drop()
# 向数据表内插入数据
def test_insert(username, sex, age, table="test"):
"""
:param username: 用户名称
:param sex: 用户性别
:param age: 用户年龄
:param table: 数据表的名称
"""
# 编写插入语句,%s表示元素的占位符
sql_insert = "insert into " + table + " (username,sex,age) values(%s,%s,%s)"
# 表示从左到右每个占位符所表示的元素的内容
value = (username, sex, age)
# 插入数据
execute(sql_insert, value)
'''
for i in range(10):
value_username = "test" + str(i + 1)
a = np.random.permutation(2)
if a[1] == 1:
value_sex = "男"
else:
value_sex = "女"
value_age = int(20 + a[0])
test_insert(value_username, value_sex, value_age)
'''
# 删除user_id对应的元组(用state值为0代替)
def test_delete(user_id):
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0:
print("该行已被删除")
else:
# 编写删除语句
sql_delete = "update test set state = %s where user_id = %s"
# 将state的值改为0,代表删除
value = (0, user_id)
# 执行删除操作
execute(sql_delete, value)
'''
for i in range(1, 11):
u_id = i
a = np.random.permutation(2)
print(a[1])
if a[1] == 0:
test_delete(u_id)
'''
# 进行元组状态的判断,1表示存在,0表示已被删除
def state_judgement(user_id):
"""
:param user_id: 判断状态的元组的主键(id)
:return: 状态判断值
"""
# 当user_id超出范围时报错
try:
# 编写判断的语句,%s表示元素的占位符
sql_state_judgement = "select state from test where user_id = %s"
# 表示从左到右每个占位符所表示的元素的内容
value = user_id
# 存储返回的list
ls = execute(sql_state_judgement, value, 1)
# 返回代表状态的0或1
return ls[0]["state"]
except Exception as e:
print("亲,错了呢")
'''
for i in range(1, 11):
print(state_judgement(i))
'''
# 更改表test的数据
def test_update(event_attribute, new_value, user_id):
"""
:param event_attribute: 要更改的属性名
:param new_value: 更改后的属性内容
:param user_id: 更改属性的元组的主键(id)
"""
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0 and event_attribute != "state":
print("该行已被删除")
else:
# 编写更新语句,%s表示元素的占位符
sql_update = "update test set " + event_attribute + " = %s where user_id = %s "
# 表示从左到右每个占位符所表示的元素的内容
value = (new_value, user_id)
# 更改数据
execute(sql_update, value)
'''
for i in range(1, 11):
test_update("age", 40 + i, i)
'''
# 查询表test中某一元组的所有的数据
def test_query_all(user_id=None):
"""
:param user_id: 更改属性的元组的主键(id)
"""
# 当未指定user_id时查询全部元组的数据
if user_id is None:
# 编写查询语句
sql_query_all = "select * from test where state = 1"
# 执行查询
execute(sql_query_all)
else:
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0:
print("该行已被删除")
else:
# 编写查询根据user_id确定的某一元组的全部数据
sql_query_all = "select * from test where user_id = %s"
# 表示从左到右每个占位符所表示的元素的内容
value = user_id
# 执行查询
execute(sql_query_all, value)
# test_query_all()
# 查询副表test中某一元组的某一属性的数据
def test_query(event_attribute, user_id=None):
"""
:param event_attribute:查询的属性的名称
:param user_id: 更改属性的元组的主键(id)
"""
# 当未指定user_id时查询全部元组的数据
if user_id is None:
# 编写查询全部元组某一属性的语句
sql_query = "select " + event_attribute + " from test where state = 1"
# 执行查询
execute(sql_query)
else:
# 判断user_id对应的元组的状态
if state_judgement(user_id) == 0:
print("该行已被删除")
# 编写查询查询根据user_id确定的某一元组的某一属性的数据
else:
sql_query = "select " + event_attribute + " from test where user_id = %s"
# 表示从左到右每个占位符所表示的元素的内容
value = user_id
# 执行查询
execute(sql_query, value)
# test_query("username")