Java Stream 底层原理
Stream API
你可能没意识到Java对函数式编程的重视程度,看看Java 8加入函数式编程扩充多少功能就清楚了。Java 8之所以费这么大功夫引入函数式编程,原因有二:
- 代码简洁函数式编程写出的代码简洁且意图明确,使用_stream_接口让你从此告别_for_循环。
- 多核友好,Java函数式编程使得编写并行程序从未如此简单,你需要的全部就是调用一下parallel()方法。
对_stream_的操作分为为两类,中间操作(intermediate operations)和结束操作(terminal operations),二者特点是:- 中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新_stream_,仅此而已。
- 结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以_pipeline_的方式执行,这样可以减少迭代次数。计算完成之后_stream_就会失效。
引用处API教程写得特别好,这里只做一些API记录。
flatMap()
函数原型为` Stream flatMap(Function> mapper)``
它可以把几个列表“压平”成一维,非常像pytorch的fatten操作。
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(i -> System.out.println(i));
reduce()
从列表中计算导出一个值。如果很抽象,参考reduce系的常见函数 sum(), max(), min(), count()
最长的函数原型:
// identity,初始值
// accumulator,reduce的方式,可以是累加,取更大值等等
// combiner,用于并行计算,多结果合并
<U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
示例:
// 找出最长的单词
Stream<String> stream = Stream.of("I", "love", "you", "too");
Optional<String> longest = stream.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
//Optional longest = stream.max((s1, s2) -> s1.length()-s2.length());
System.out.println(longest.get());
// 求单词长度之和
Stream<String> stream = Stream.of("I", "love", "you", "too");
Integer lengthSum = stream.reduce(0, // 初始值 // (1)
(sum, str) -> sum+str.length(), // 累加器 // (2)
(a, b) -> a+b); // 部分和拼接器,并行执行时才会用到 // (3)
// int lengthSum = stream.mapToInt(str -> str.length()).sum();
System.out.println(lengthSum);
collect()
reduce是导出一个值,试想我们想导出一个集合,那该怎么办?这就需要使用collect。
导出集合至少需要声明两件事:
- 集合是什么?
- 如何添加元素?
这刚好就是collect的API完成的内容。
导出集合
// 函数原型
// supplier,提供目标集合获取方式
// accumulator,声明消费方式,即添加方式
// combiner,并行计算,多结果结合方式
<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner)
// 将Stream规约成List
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);// 方式1
//List list = stream.collect(Collectors.toList());// 方式2
System.out.println(list);
// 由于使用Collectors.toList() 无法指定列表类型
// 所以可以使用toCollection()指定规约容器的类型
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));// (3)
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));// (4)
生成map和分组统计
生成map比较复杂一些,需要告知如何生成key和value。在这个基础上,stream的API还可以完成一些类似SQL聚类的强大操作。
// map生成
// 使用toMap()统计学生GPA
Map<Student, Double> studentToGPA =
students.stream().collect(Collectors.toMap(Function.identity(),// 如何生成key
student -> computeGPA(student)));// 如何生成value
// 二分区
// Partition students into passing and failing
Map<Boolean, List<Student>> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
// 分组
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
// 分组统计
// 使用下游收集器统计每个部门的人数
Map<Department, Integer> totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.counting()));// 下游收集器
// 按照部门对员工分布组,并只保留员工的名字
Map<Department, List<String>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.mapping(Employee::getName,// 下游收集器
Collectors.toList())));// 更下游的收集器
处理字符串
python的字符串处理一直让其他语言比较羡慕,collect可以完成部分功能,例如join。
// 使用Collectors.joining()拼接字符串
Stream<String> stream = Stream.of("I", "love", "you");
//String joined = stream.collect(Collectors.joining());// "Iloveyou"
//String joined = stream.collect(Collectors.joining(","));// "I,love,you"
String joined = stream.collect(Collectors.joining(",", "{", "}"));// "{I,love,you}"
引用
https://github.com/CarpenterLee/JavaLambdaInternals/blob/master/4-Streams%20API(I).md
https://github.com/CarpenterLee/JavaLambdaInternals/blob/master/5-Streams%20API(II).md
Stream Pipelines 实现原理
Stream API用起来非常的舒服,以至于我们巴不得将所有的迭代换成stream的形式,而完全不想理可读性问题。而简洁的实现下面似乎隐藏的无尽的秘密,反正对于我来说,从接触stream API开始,我至少有以下的疑惑:
- 流式编程、函数式编程明显是由接口之类的组合实现的,但具体的如何实现的呢?
- stream是否会有效率方面的问题,例如
filter(word -> word.length() < 4).map(String::length),显然包含了两种不同的迭代操作。如果是我来实现,为了效率,我肯定会在一个迭代中去实现多个功能,那么,对于stream API,它是否足够智能,能在一个迭代中完成两种操作,保证效率的问题?
比如下边的一个stream实现的低效版本——在每个阶段都分开地用迭代完成。
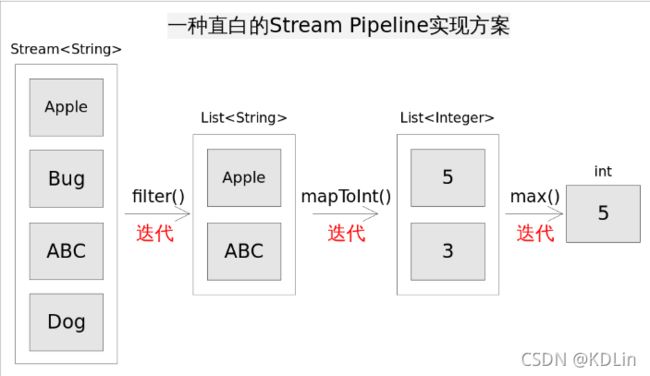
stream API的源码不太好读,它属于那种包含着大量的设计的源码,阅读之前,必须先理解整个的框架,以及常见的概念,类都是干嘛的。
操作分类
Stream上的所有操作分为两类:中间操作和结束操作,中间操作只是一种标记,只有结束操作才会触发实际计算。中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;结束操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如_找到第一个满足条件的元素_。之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。 为了更好的理解流的中间操作和终端操作,可以通过下面的两段代码来看他们的执行过程。
ref: https://github.com/CarpenterLee/JavaLambdaInternals/blob/master/6-Stream%20Pipelines.md
| Stream操作分类 | ||
|---|---|---|
| 中间操作(Intermediate operations) | 无状态(Stateless) | unordered() filter() map() mapToInt() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 有状态(Stateful) | distinct() sorted() sorted() limit() skip() | |
| 结束操作(Terminal operations) | 非短路操作 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 短路操作(short-circuiting) | anyMatch() allMatch() noneMatch() findFirst() findAny() |
操作分类底层分开处理,这对于底层的实现和设计是非常重要的,不过,实际上对于我们理解stream API的最重要的原理的实现,并没有太多帮助,这边可以先做了解。
Pipelines 双向调用链
目前能看到的教程,对stream实现原理的介绍都比较复杂,但实际上我理解的,核心的设计其实挺好理解的。
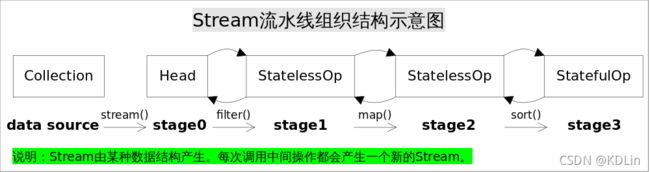
核心的原理就是上图,当前其中会有大量的不认识的名词,这些都不重要,只需要知道每一个节点都是代表一个stage,也可以称作一个pipeline节点。
- stream的API的调用都会生成一个stage,这些stage以双向链表的形式连起来,尽管底层实现并不是直观的双向链表。
- 我们需要的各种操作,通过lambda函数、接口组合的形式被每个stage持有,这些操作形成操作链。
- stream企图通过一次迭代完成我们标记的所有操作,这个迭代中,每次都会调用完整的操作链。
上述说明隐藏了大量细节,但事实整体的原理就是这么回事,其实非常好理解:
- pipline节点和操作串成双向链表
- 在一次迭代中执行所有操作
接下来是一些细节问题,首先是图中涉及到的类实际上都是pipeline的一种,如下图。具体而言,Head(头节点),StatelessOp(无状态操作),StatefulOp(有状态操作),都是继承自pipeline,你可以直接把它们都理解成pipeline的节点。每个Pipline中持有upStream(也叫previousStage)的引用,从而连成本pipelines链表。
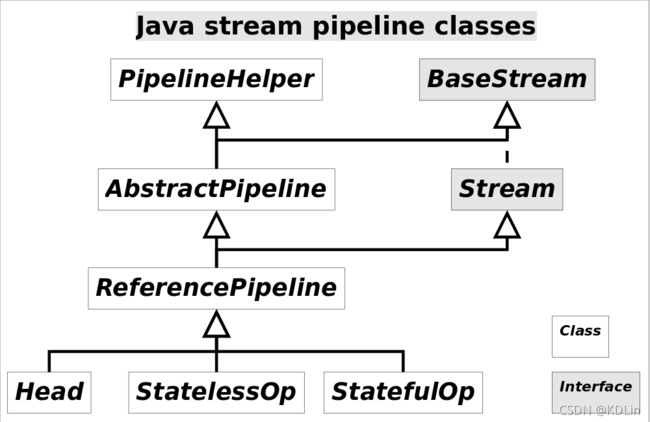
其次操作的串联,操作是通过匿名函数,封装在接口中,最后包装在Sink类中。每个pipeline节点都包含一个Sink,每个Sink包含一个Sink的域,持有下一个Pipline的Sink对象的引用。
从而,Pipeline和Sink构成了宏观上的双向链表。
另外一个细节是Sink链的构建,Sink包装成链是在终结操作调用之后通过Pipeline链,逆向便利包装的,它的代码大致如下,非常好理解。我们可以看到,sink一层套一层,最后返回的sink,实际上就是Pipeline链头节点的Sink操作,从它开始,引用了整个链上的所有sink。这也是它的命名的原因——仿佛是一个水槽,沉淀了整个链上的所有操作,当然这是我自己的理解。
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
最后是stream执行的时候的调用,也非常好理解,Sink继承自Consumer,所以action看成Sink对象就可以。
public void forEachRemaining(Consumer<? super T> action) {
Object[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
// a保存了stream的数据列表,hi是遍历的边界,通常等于数据列表长度
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
do {
// 因为继承自Consumer,通过调用accept可以调用我们的lambda实现,一层一层调用Sink
action.accept((T)a[i]);
} while (++i < hi);
}
}
引用
原文来自https://github.com/CarpenterLee/JavaLambdaInternals/blob/master/6-Stream%20Pipelines.md,这一系列文章质量很高,本文算是我自己学习后的一些总结。