牛客MySQL题库总结(三)
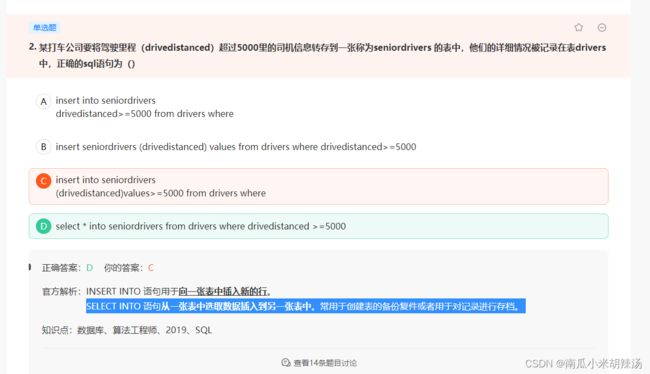
1、select into
SELECT INTO 语句从一张表中选取数据插入到另一张表中。常用于创建表的备份复件或者用于对记录进行存档。
(1)将所有列插入新表
SELECT *
INTO new_table [IN externaldatabase]
FROM old_table
(2)将只希望列插入新表
SELECT column_name1,column_name2...
INTO new_table [IN externaldatabase]
FROM old_table
2、MySQL CASE WHEN用法
case when的正确语法是:
case when …then … then … else … end。
# CASE搜索函数法
CASE
WHEN <bool_condition> THEN <result>
[WHEN <bool_condition> THEN <result>]
[……]
[ELSE <else_result>]
END
注意case和when不能缺少!!
举两个例子:
(1)利用case when判断年龄段
SELECT *,
case
when age<30 then '年轻人'
when (age>30 and age <60) then '中年人'
when age>60 then '老年人' end as stage
FROM `student`

(2)借助casewhen实现行列转换

SELECT stuid ,
sum(case when `subject`= '语文' then score end) as '语文',
sum(case when `subject`= '数学' then score end) as '数学',
sum(case when `subject`= '英语' then score end) as '英语'
FROM `score`
GROUP BY stuid

3、Union
可以将两个毫不相干的表的查询结果拼接在一起输出,前提是两个查询的列数相同。
但是这里需要注意union和union all之间的区别:
union all是把结果集直接合并在一起不做任何处理,而union 是将union all后的结果进行一次distinct,去除重复的记录后的结果。
举个例子:
分别查询学生表中性别分别为男和女学生,利用union关键字将其进行拼接!

代码:
SELECT name,male
from student
where male = '男'
union
SELECT name,male
from student
where male = '女'
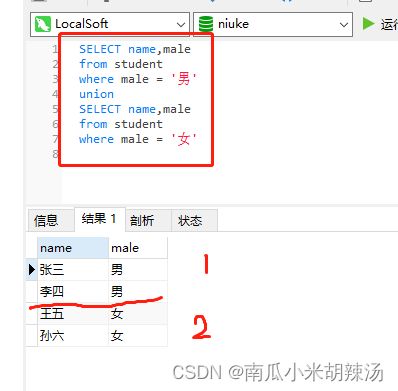
前提条件,一定两张表查询出的列数相同,两张表的内容或者属性值可以不同,这里强调的是列数!!!
4、exists探究
EXISTS
select … from table where exists (subquery)
该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否得以保留。
如果子查询有任意数据返回,exists就返回true,子查询外的查询语句执行。
如果子查询没有数据返回,exists就返回false,子查询外的查询语句就不。
注意exists和in可以互相替换
注意mysql的in与exists优化原则:小表驱动大表
(1)当A表的数据集大于B表的数据集时,用in优于exists。
(2)当A表的数据集小于B表的数据集时,用exists优于in。
5、SQL的合法标识符
== SQL合法标识符 第一个字必须是 字母 、下划线 、@ 、 #开头,不能是数字或其他。==
6、字段名和值的规范写法
(1)字段名写法:
①不可直接写字段名
②用着重号`括起来,不能用单引号‘或双引号“
(2)字段值写法:
正常需要用单引号’或双引号"括起来,数字可以不用括起来

7、Full Join语法探究
首先声明:在MySQL8以下的版本不支持full join对表进行全连接!
但是这一次碰到的问题相当于如何利用左连接和右连接实现full join!
一开始一头雾水,只有当你跑一遍代码,才能对这个问题有更加深入的认识!!
问题原型:

首先你需要知道什么是全连接,说白了,就是你需要将表中的数据全部展示出来!
举个例子:
我们以题目为例,可以看出,通过full join 将所有的数据展示出来,那怎么达到这种效果呢!
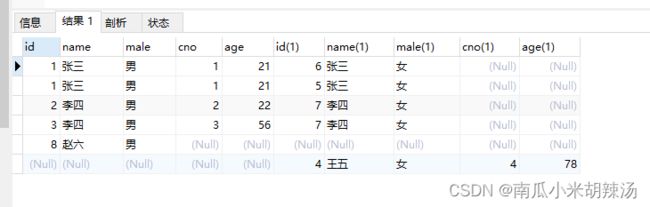
思路:
(1)按照性别和名字对其左连接
select t1.*,t2.*
from (
select * from student where male = '男' ) t1
left join
(select * from student where male = '女')t2
on t1.name = t2.name
(2)按照性别和名字对其右连接,但是此时要注意如果右边值有重复的话,那么就要去掉,所以我们只保留左边值为NULL的即可
select t1.*,t2.*
from (
select * from student where male = '男' ) t1
right join
(select * from student where male = '女')t2
on t1.name = t2.name
where t1.name is null ;
(3)对左连接和右连接的值进行union all联合
select t1.*,t2.*
from (
select * from student where male = '男' ) t1
left join
(select * from student where male = '女')t2
on t1.name = t2.name
union all
select t1.*,t2.*
from (
select * from student where male = '男' ) t1
right join
(select * from student where male = '女')t2
on t1.name = t2.name
where t1.name is null ;
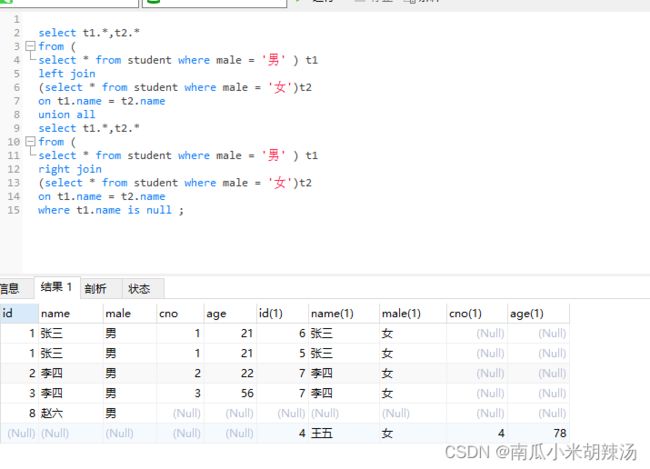
(4)易错点其实就是where,本来以为where的意思是当对union all连接后的所有数据进行过滤,其实不是!
存在优先级:
sql执行顺序:from >> on >> join >> where >> group by >> having >> select >> distinct >> unoin >> order by >> limit
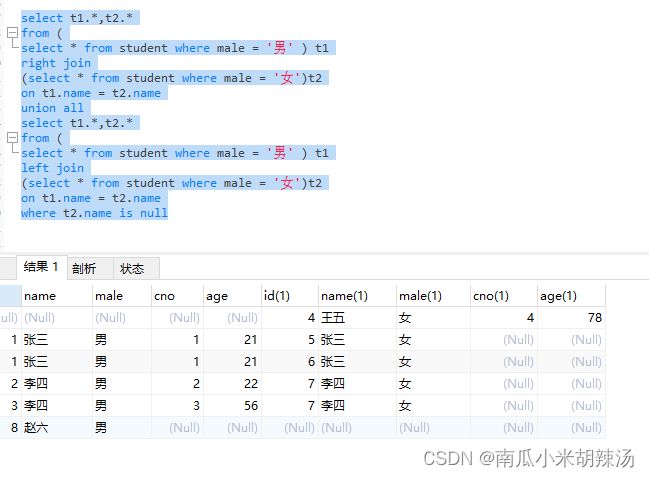
(5)但是还有没有其他办法?
同理也可以先进行右连接,然后在进行左连接,并对右表进行NULL过滤,最后用union all进行连接即可!
select t1.*,t2.*
from (
select * from student where male = '男' ) t1
right join
(select * from student where male = '女')t2
on t1.name = t2.name
union all
select t1.*,t2.*
from (
select * from student where male = '男' ) t1
left join
(select * from student where male = '女')t2
on t1.name = t2.name
where t2.name is null
8、MySQL语言分类
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
(1)数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句。
WHERE子句组成的查询块:SELECT <字段名表>FROM <表或视图名>WHERE <查询条件>
(2)数据操纵语言DML
数据操纵语言DML主要有三种形式:
①插入:INSERT
②更新:UPDATE
③删除:DELETE
(3)数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象-----表、视图、索引、同义词、聚簇等如:CREATE TABLE / VIEW / INDEX / SYN / CLUSTER| 表 视图 索引 同义词 簇。DDL操作是隐性提交的!不能rollback
(4)数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
①GRANT:授权。
②ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。回滚—ROLLBACK回滚命令使数据库状态回到上次最后提交的状态。其格式为:SQL>ROLLBACK;
③COMMIT [WORK]:提交。在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。
(5)总结
①数据定义(SQL DDL)用于定义SQL模式、基本表、视图和索引的创建和撤消操作。
②数据操纵(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。
③数据控制(DCL)包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。
④嵌入式SQL的使用规定(TCL)涉及到SQL语句嵌入在宿主语言程序中使用的规则。

9、ALTER TABLE 修改表结构

