基于Attention机制的轻量级网络架构以及代码实现
点击上方,选择星标或置顶,不定期资源大放送 !
!
阅读大概需要10分钟
Follow小博主,每天更新前沿干货


导读
之前详细介绍了轻量级网络架构的开源项目,详情请看深度学习中的轻量级网络架构总结与代码实现,今日更新了基于注意力机制的轻量级网络架构,主要包括ECANet、SANet、ResNeSt、Triplet attention等.主要将上述即插即用的注意力模块集成到MobileNetv2的框架中,具体代码可查看项目.
Github地址:https://github.com/murufeng/awesome_lightweight_networks
本项目主要提供一个移动端网络架构的基础性工具,避免大家重复造轮子,后续我们将针对具体视觉任务集成更多的移动端网络架构。希望本项目既能让深度学习初学者快速入门,又能更好地服务科研学术和工业研发社区。
(欢迎各位轻量级网络科研学者将自己工作的核心代码整理到本项目中,推动科研社区的发展,我们会在readme中注明代码的作者~)后续将持续更新模型轻量化处理的一系列方法,包括:剪枝,量化,知识蒸馏等.
基于Attention的轻量级网络架构
ECANet
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
-
论文地址:https://arxiv.org/abs/1910.03151
ECANet是一种即插即用的轻量级通道注意力模块,可显著提高CNN性能!ECANet主要对SENet模块进行了一些改进,提出了一种不降维的局部跨信道交互策略(ECA模块)和自适应选择一维卷积核大小的方法,该模块只增加了少量的参数,却能获得明显的性能增益。通过对SENet中通道注意模块的分析,实验表明避免降维对于学习通道注意力非常重要,适当的跨信道交互可以在显著降低模型复杂度的同时保持性能。因此,作者提出了一种不降维的局部跨信道交互策略,该策略可以通过一维卷积有效地实现。进一步,作者又提出了一种自适应选择一维卷积核大小的方法,以确定局部跨通道信息交互的覆盖率。
具体结构如下所示:

-
代码实现
import torch
from light_cnns import mbv2_eca
model = mbv2_eca()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())ResNeSt
ResNeSt: Split-Attention Networks
-
论文地址:https://hangzhang.org/files/resnest.pdf
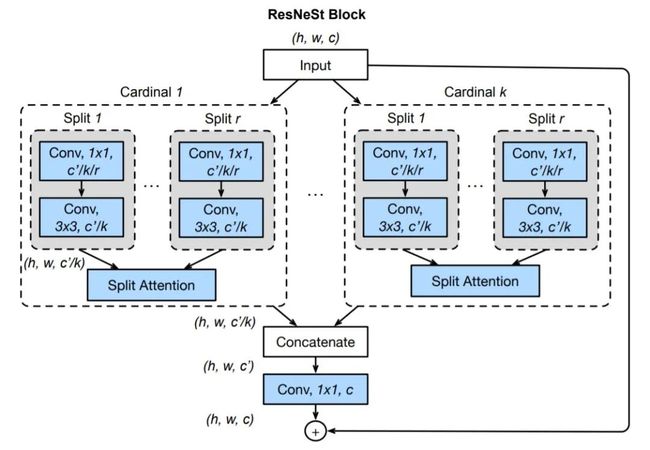
ResNeSt 实际上是站在巨人肩膀上的"集大成者",特别借鉴了:Multi-path 和 Feature-map Attention思想。作者@张航也提到了这篇文章主要是基于 SENet,SKNet 和 ResNeXt,把 attention 做到 group level。另外还引入了Split-Attention块,可以跨不同的feature-map组实现feature-map注意力。和其它网络主要的区别在于:
-
GoogleNet 采用了Multi-path机制,其中每个网络块均由不同的卷积kernels组成。
-
ResNeXt在ResNet bottle模块中采用分组卷积,将multi-path结构转换为统一操作。
-
SE-Net 通过自适应地重新校准通道特征响应来引入通道注意力(channel-attention)机制。
-
SK-Net 通过两个网络分支引入特征图注意力(feature-map attention)。一句话总结就是用multiple scale feature汇总得到feature map information,然后利用Softmax来指导channel-wise的注意力向量从而实现自适应分配不同尺度的表征信息。
网络结构如下:
-
代码实现
import torch
from light_cnns import resnest50_v1b
model = resnest50_v1b()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())SANet
SA-Net: Shuffle Attention for Deep Convolutional Neural Networks
-
论文地址:https://arxiv.org/abs/2102.00240 shuffle attention
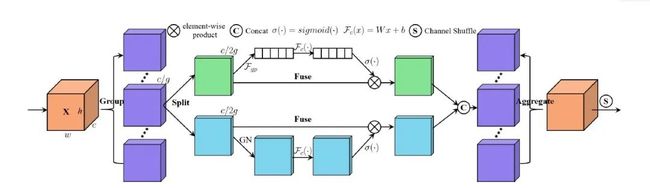
主要在空间注意力(Spatial Attention)与通道注意力(Channel Attention)的基础上,引入了特征分组与通道注意力信息置换这两个操作,得到了一种超轻量型的即插即用注意力模块。具体的说,SA首先将输入沿着通道维度拆分为多组,然后对每一组特征词用Shuffle unit 刻画与建模特征在空间维度与通道维度上的依赖关系,最后所有特征进行集成以及通过通道置换操作进行各组件单元的特征通信。主要结构如下所示:
-
网络结构:
-
代码实现
import torch
from light_cnns import mbv2_sa
model = mbv2_sa()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())Triplet attention
Rotate to Attend: Convolutional Triplet Attention Module
-
论文地址:https://arxiv.org/abs/2010.03045
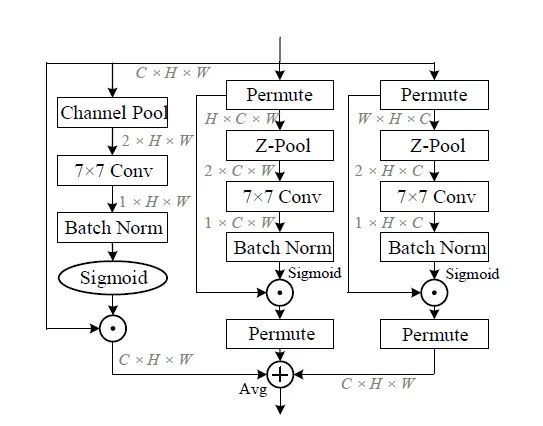
本文中主要提出了Triplet Attention,一种轻量且有效的注意力模块。该注意力机制是一种通过使用Triplet Branch结构捕获跨维度交互信息(cross dimension interaction)来计算注意力权重的新方法。对于输入张量,Triplet Attention通过旋转操作和残差变换建立维度间的依存关系,并以可忽略的计算开销对通道和空间信息进行编码。该方法既简单又有效,并且可以轻松地插入经典Backbone中。本文通过捕捉空间维度和输入张量通道维度之间的交互作用,显著提高了网络的性能.
-
网络结构
-
代码结构
import torch
from light_cnns import mbv2_triplet
model = mbv2_triplet()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())精彩内容待更新
欢迎大家follow和star该项目地址,我们会持续跟踪前沿论文工作,若项目在复现和整理过程中有任何问题,欢迎大家在issue中提出!
Github地址:https://github.com/murufeng/awesome_lightweight_networks
欢迎大家加入DLer-计算机视觉&Transformer群!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

长按识别,邀请您进群!