docker - prometheus+grafana监控与集成到spring boot 微服务
prometheus+grafana监控与集成到spring boot
-
-
-
- 一、Prometheus 介绍
- 二、Grafana 介绍
- 三、Alertmananger 介绍
- 四、监控Java 应用
-
-
- 监控模式
- 如何监控
-
- 五、MicroMeter 介绍
- 六、docker-prometheus、docker-grafana、服务器监控docker-node-exporter 安装
-
-
- 下载镜像包
- prometheus启动前准备
- grafana启动前准备
- 启动
- 使用grafana
-
- 七、spring boot 集成 prometheus
-
-
- 引入依赖
- yml配置
- 访问
- grafana官方JVM视图模板使用
- grafana好用免费的官方模板地址
-
-
-
一、Prometheus 介绍
Prometheus 中文名称为普罗米修斯,受启发于Google 的Brogmon 监控系统,从2012年开始由前Google工程师在Soundcloud 以开源软件的形式进行研发,2016年6月发布1.0版本。Prometheus 可以看作是 Google 内部监控系统Borgmon 的一个实现。
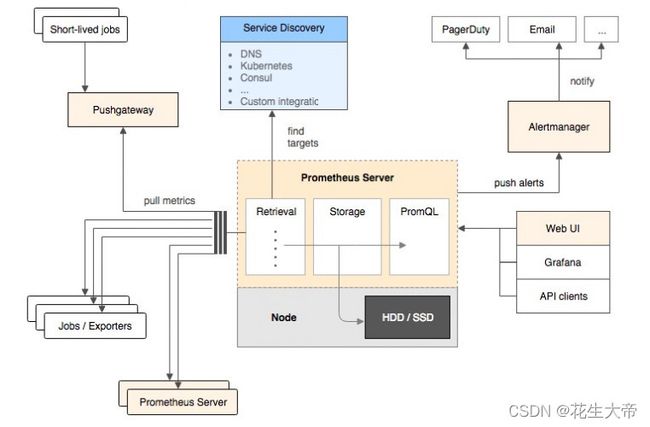
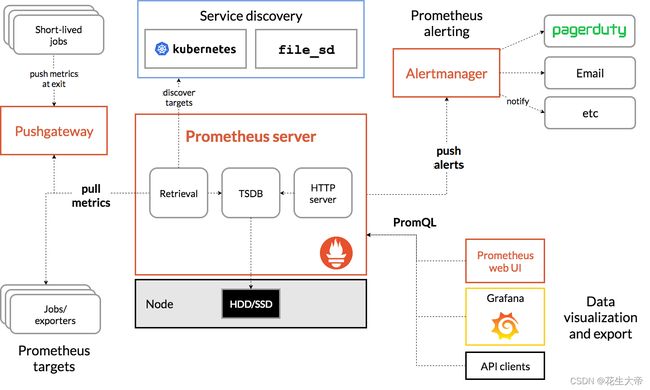
下图说明了Prometheus 的体系结构及其部分生态系统组件。其中 Alertmanager 用于告警,Grafana 用于监控数据可视化,会在文章后面继续提到。
在这里我们了解到Prometheus 这几个特征即可:
1.数据收集器,它以配置的时间间隔定期通过HTTP提取指标数据。
2.一个时间序列数据库,用于存储所有指标数据。
3.一个简单的用户界面,您可以在其中可视化,查询和监视所有指标。
二、Grafana 介绍
Grafana 是一款采用 go 语言编写的开源应用,允许您从Elasticsearch,Prometheus,Graphite,InfluxDB等各种数据源中获取数据,并通过精美的图形将其可视化。
除了Prometheus的AlertManager 可以发送报警,Grafana 同时也支持告警。Grafana 可以无缝定义告警在数据中的位置,可视化的定义阈值,并可以通过钉钉、email等平台获取告警通知。最重要的是可直观的定义告警规则,不断的评估并发送通知。
由于Grafana alert告警比较弱,大部分告警都是通过Prometheus Alertmanager进行告警.
请注意Prometheus仪表板也具有简单的图形。 但是Grafana的图形化要好得多。
三、Alertmananger 介绍
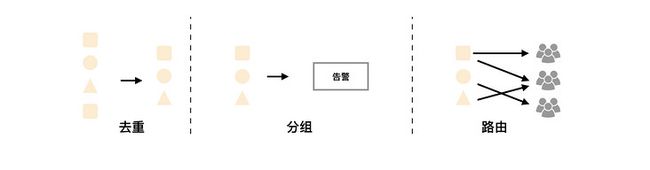
Prometheus 监控平台中除了负责采集数据和存储,还能定制事件规则,但是这些事件规则要实现告警通知的话需要配合Alertmanager 组件来完成。
AlertManager 支持告警分组(将多个告警合并一起发送)、告警抑制以及告警静默(同一个时间段内不发出重复的告警)功能。
四、监控Java 应用
监控模式
目前,监控系统采集指标有两种方式,一种是『推』,另一种就是『拉』:
推的代表有 ElasticSearch,InfluxDB,OpenTSDB 等,需要你从程序中将指标使用 TCP,UDP 等方式推送至相关监控应用,只是使用 TCP 的话,一旦监控应用挂掉或存在瓶颈,容易对应用本身产生影响,而使用 UDP 的话,虽然不用担心监控应用,但是容易丢数据。
拉的代表,主要代表就是 Prometheus,让我们不用担心监控应用本身的状态。而且可以利用 DNS-SRV 或者 Consul 等服务发现功能就可以自动添加监控。
如何监控
Prometheus 监控应用的方式非常简单,只需要进程暴露了一个用于获取当前监控样本数据的 HTTP 访问地址。这样的一个程序称为Exporter,Exporter 的实例称为一个 Target 。Prometheus 通过轮训的方式定时从这些 Target 中获取监控数据样本,对于应用来讲,只需要暴露一个包含监控数据的 HTTP 访问地址即可,当然提供的数据需要满足一定的格式,这个格式就是 Metrics 格式.
metric name>{主要分为三个部分
各个部分需符合相关的正则表达式
1.metric name:指标的名称,主要反映被监控样本的含义 a-zA-Z_:*_
2.label name: 标签 反映了当前样本的特征维度 [a-zA-Z0-9_]*
3.label value: 各个标签的值,不限制格式
需要注意的是,label value 最好使用枚举值,而不要使用无限制的值,比如用户 ID,Email 等,不然会消耗大量内存,也不符合指标采集的意义。
五、MicroMeter 介绍
前面简述了Prometheus 监控的原理。那么我们的Spring Boot 应用怎么提供这样一个 HTTP 访问地址,提供的数据还得符合上述的 Metrics 格式 ?
还记得吗,在Spring Boot Actuator 模块 详解:健康检查,度量,指标收集和监控中,我有提到过Actuator 模块也可以和一些外部的应用监控系统整合,其中就包括Prometheus 。那么Spring Boot Actuator 怎么让 Spring Boot 应用和Prometheus 这种监控系统结合起来呢?
这个桥梁就是Micrometer。Micrometer 为 Java 平台上的性能数据收集提供了一个通用的 API,应用程序只需要使用 Micrometer 的通用 API 来收集性能指标即可。Micrometer 会负责完成与不同监控系统的适配工作。
六、docker-prometheus、docker-grafana、服务器监控docker-node-exporter 安装
下载镜像包
docker pull prom/prometheus
docker pull grafana/grafana
docker pull prom/node-exporter
prometheus启动前准备
mkdir /opt/prometheus
touch /opt/prometheus.yml
cd /opt/prometheus
vim prometheus.yml
prometheus 配置文件如下
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['xxx.xxx.xxx.xxx:9300']
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['xxx.xxx.xxx.xxx:9200']
labels:
instance: localhost
- job_name: web
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['xxx.xxx.xxx.xxx:19007']
labels:
instance: localweb
其中9300为prometheus
其中9200为node-exporter监控服务器的程序
其中19007为测试地址,metrics_path是自定义拉取数据的地址
grafana启动前准备
mkdir /opt/grafana-storage
chmod 777 -R /opt/grafana-storage
启动
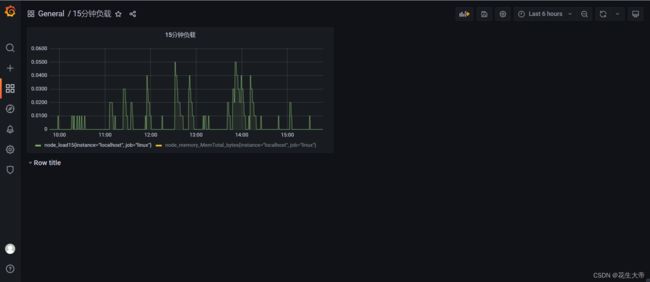
可视化如下

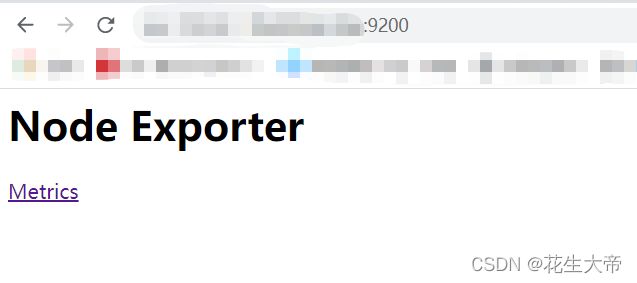
node-exporter启动
docker run -d -p 9200:9100 --name=node-exporter -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter
访问9200端口
prometheus启动
docker run -d --name=prometheus -p 9300:9090 -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
访问9300端口

grafana启动
docker run -d -p 9400:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana
访问9400端口
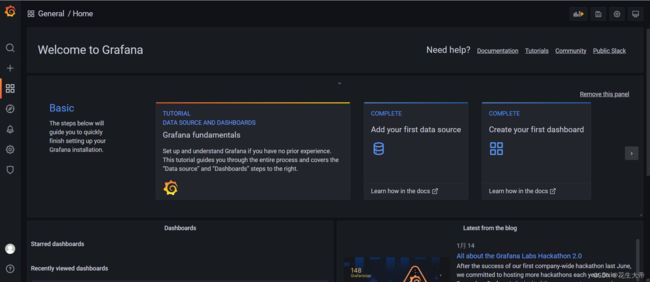
使用grafana
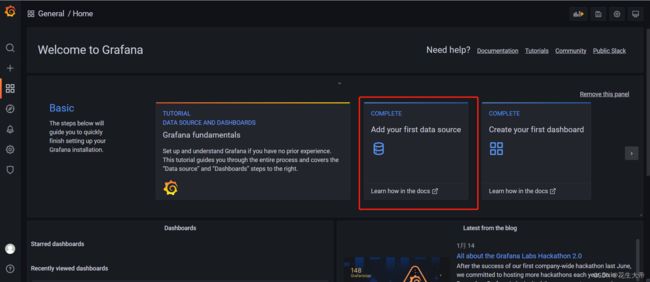
创建数据源
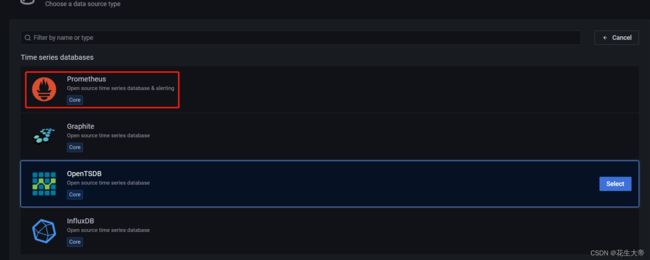

配置视图
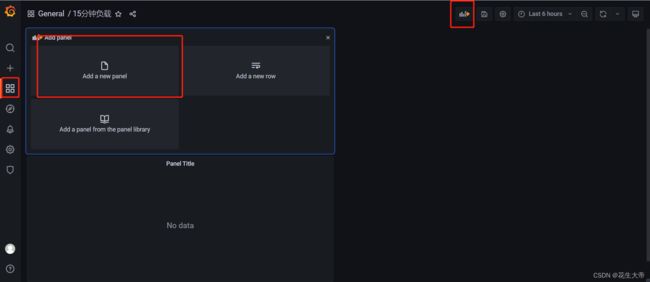
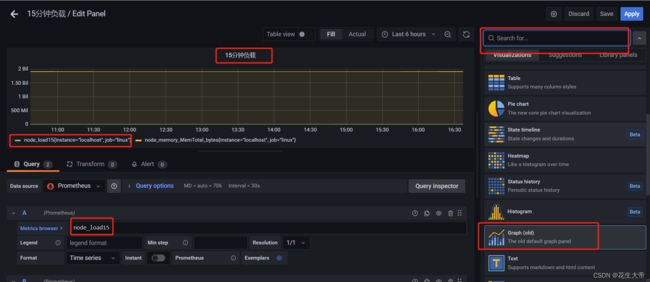
七、spring boot 集成 prometheus
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Micrometer Prometheus registry -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
yml配置
# management-->metrics单机监控的配置 访问路径 项目地址/prometheus
management:
metrics:
binders:
jvm:
enabled: false
files:
enabled: false
integration:
enabled: false
logback:
enabled: false
processor:
enabled: false
uptime:
enabled: false
endpoints:
web:
exposure:
include: ["prometheus"]
base-path: "/"
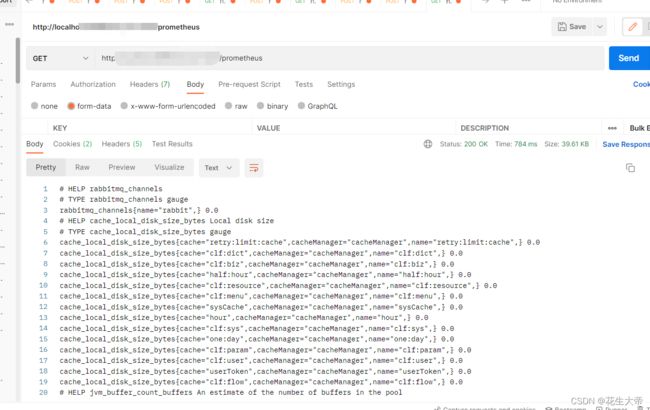
访问
测试时用的是19007端口 上方prometheus.yml配置中的访问地址
下方是获取的指标
grafana官方JVM视图模板使用
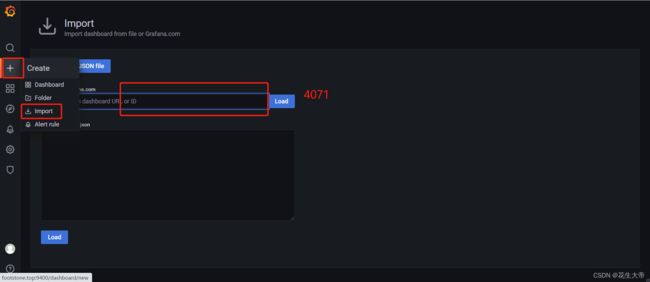
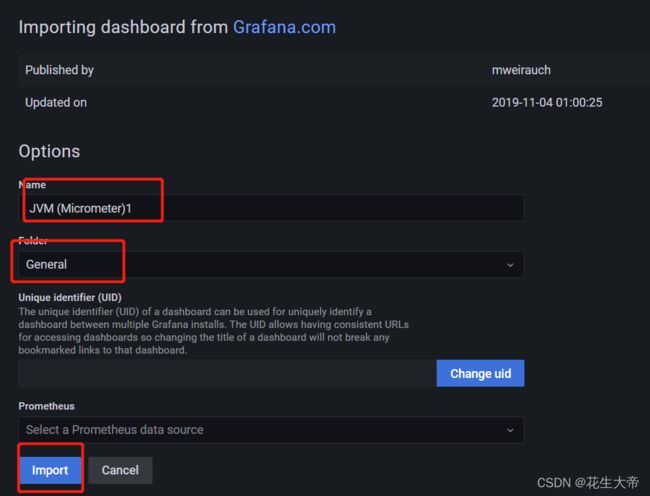
现在是离线情况,19007测试地址在线后在上方会识别出现上方prometheus.yml配置的web测试选项
现在是在线情况展示的数据
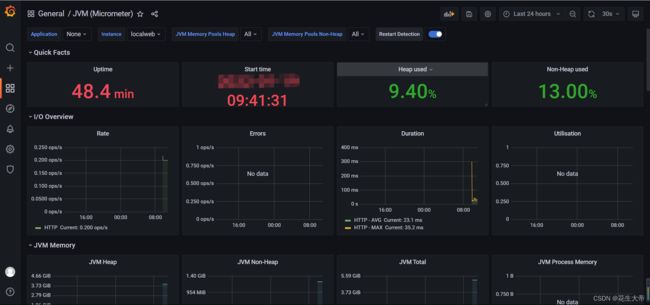
数据在这个视图中展示
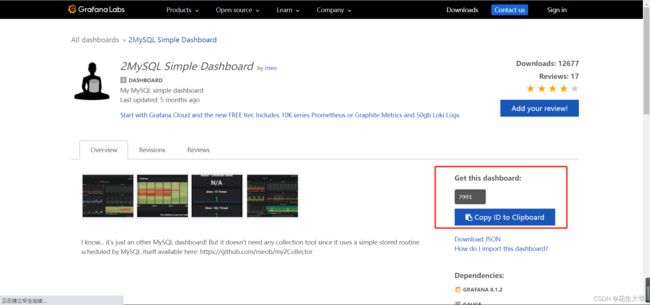
grafana好用免费的官方模板地址
GrafanaLabs模板跳转地址