Python文本分析
字符串操作
# 去空格以及特殊符号
s = ' hello, world!'
print(s.strip()) # hello, world!
print(s.rstrip('!')) # hello, world
# 查找字符( <0 为未找到)
str1 = 'hello'
str2 = 'e'
str3 = 'he'
print(str1.index(str2)) # 1
print(str1.find(str3))
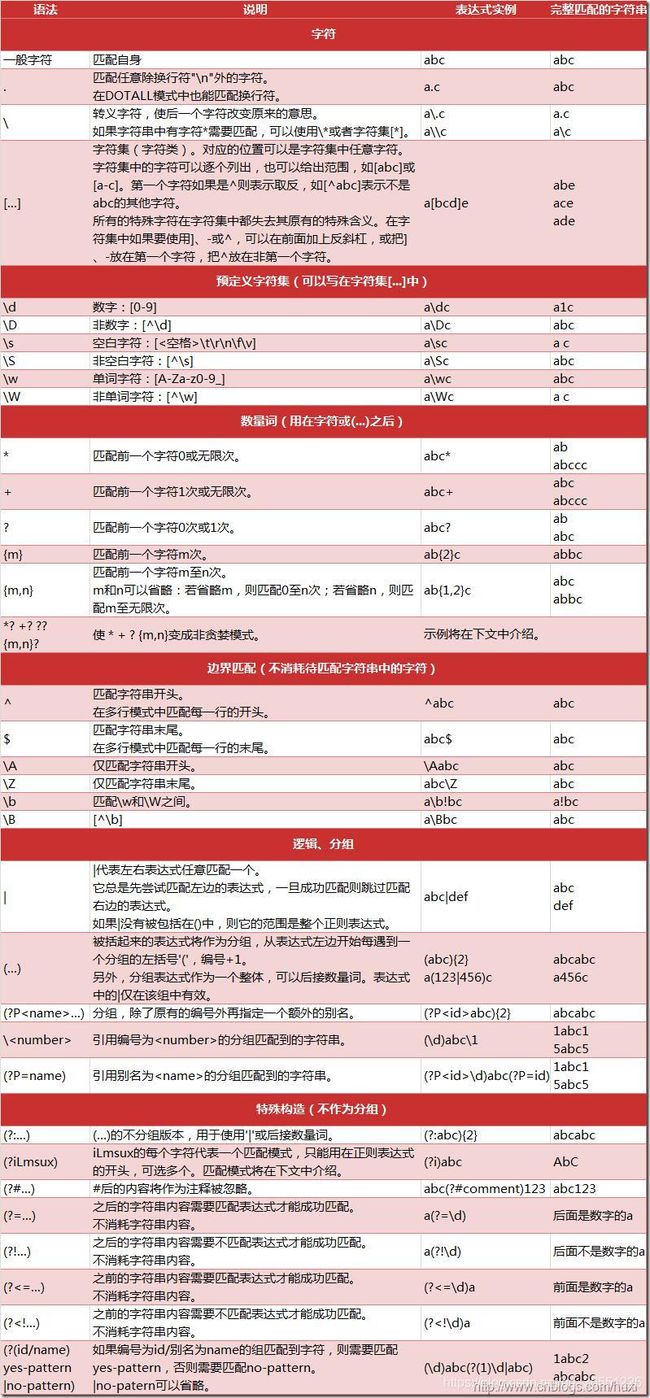
正则表达式
测试网站
练习网站
Python案例
使用re的一般步骤是:
- 将正则表达式的字符串形式编译为Pattern实例
- 使用Pattern实例处理文本并获得匹配结果(一个Match实例)
- 使用Match实例获得信息,进行其他的操作。
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello.*\!') # 匹配hello开头直到!结尾
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello, python! How are you?')
if match:
# 使用Match获得分组信息
print(match.group())
hello, python!
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。
第二个参数flag是匹配模式,取值可以使用按位或运算符’|'表示同时生效,比如re.I | re.M。
当然,你也可以在regex字符串中指定模式,比如re.compile(‘pattern’, re.I | re.M)等价于re.compile(’(?im)pattern’)
flag可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(MULTILINE): 多行模式,改变’^‘和’$'的行为(参见上图)
- re.S(DOTALL): 点任意匹配模式,改变’.'的行为
- re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
regex_1 = re.compile(r"""\d + # 数字部分
\. # 小数点部分
\d * # 小数的数字部分""", re.X)
regex_2 = re.compile(r"\d+\.\d*")
Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
match属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符’0’,只能使用\g<1>0。
Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
使用pattern
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern:- 如果pattern结束时仍可匹配,则返回一个Match对象
- 如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
- pos和endpos的默认值分别为0和len(string)。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符’$’。
- search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法从string的pos下标处起尝试匹配pattern- 如果pattern结束时仍可匹配,则返回一个Match对象
- 若无法匹配,则将pos加1后重新尝试匹配,直到pos=endpos时仍无法匹配则返回None。
- pos和endpos的默认值分别为0和len(string))
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'H.*n') # .* 表示往后匹配任意字符,直到出现g
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = pattern.search('Hello python!')
if match:
# 使用Match获得分组信息
print(match.group())
Hello python
- split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
- 按照能够匹配的子串将string分割后返回列表。
- maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'\d+')
print(p.split('one1two2three3four4'))
['one', 'two', 'three', 'four', '']
- findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
- 搜索string,以列表形式返回全部能匹配的子串。
import re
p = re.compile(r'\d+')
print(p.findall('one1two2three3four4'))
['1', '2', '3', '4']
- finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
- 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print(m.group())
1
2
3
4
- sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
- 使用repl替换string中每一个匹配的子串后返回替换后的字符串。
- 当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
- 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello python!'
print(p.sub(r'\2 \1', s)) # say i, python hello!
def func(m):
return(m.group(1).title() + ' ' + m.group(2).title())
print(p.sub(func, s)) # I Say, Hello Python!
- subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
- 返回 (sub(repl, string[, count]), 替换次数)。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello python!'
print(p.subn(r'\2 \1', s)) # ('say i, python hello!', 2)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(p.subn(func, s)) # ('I Say, Hello Python!', 2)
jieba中文处理
1.基本分词函数与用法
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode)
jieba.cut 方法接受三个输入参数:
- 需要分词的字符串
- cut_all 参数用来控制是否采用全模式
- HMM 参数用来控制是否使用 HMM(隐马尔科夫) 模型
jieba.cut_for_search 方法接受两个参数:
- 需要分词的字符串
- 是否使用 HMM 模型。
该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
# encoding=utf-8
import jieba
seg_list = jieba.cut("我在学习自然语言处理", cut_all=True)
print(seg_list)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式(有重复)
Full Mode: 我/ 在/ 学习/ 自然/ 自然语言/ 语言/ 处理
seg_list = jieba.cut("我在学习自然语言处理", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
Default Mode: 我/ 在/ 学习/ 自然语言/ 处理
seg_list = jieba.cut("他毕业于上海交通大学,在百度深度学习研究院进行研究") # 默认是精确模式
print(", ".join(seg_list))
他/毕业/于/上海交通大学/,/在/百度/深度/学习/研究院/进行/研究
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在哈佛大学深造") # 搜索引擎模式
print(", ".join(seg_list))
小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/哈佛/大学/哈佛大学/深造
jieba.lcut以及jieba.lcut_for_search直接返回 list
result_lcut = jieba.lcut("小明硕士毕业于中国科学院计算所,后在哈佛大学深造")
print(result_lcut)
['小明', '硕士', '毕业', '于', '中国科学院', '计算所', ',', '后', '在', '哈佛大学', '深造']
print("/".join(result_lcut))
小明/硕士/毕业/于/中国科学院/计算所/,/后/在/哈佛大学/深造
print("/".join(jieba.lcut_for_search("小明硕士毕业于中国科学院计算所,后在哈佛大学深造")))
小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/哈佛/大学/哈佛大学/深造
添加用户自定义词典
很多时候我们需要针对自己的场景进行分词,会有一些领域内的专有词汇。
- 1.可以用jieba.load_userdict(file_name)加载用户字典
- 2.少量的词汇可以自己用下面方法手动添加:
- 用 add_word(word, freq=None, tag=None) 和 del_word(word) 在程序中动态修改词典
- 用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
print('/'.join(jieba.cut('如果放到旧字典中将出错。', HMM=False)))
如果/放到/旧/字典/中将/出错/。
jieba.suggest_freq(('中', '将'), True)
jieba.add_word('旧字典')
print('/'.join(jieba.cut('如果放到旧字典中将出错。', HMM=False)))
如果/放到/旧字典/中/将/出错/。
关键词提取
基于 TF-IDF 算法的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
import jieba.analyse as analyse
lines = open('NBA.txt', 'rb').read()
print(" ".join(analyse.extract_tags(lines, topK=20, withWeight=False, allowPOS=())))
韦少 杜兰特 全明星 全明星赛 MVP 威少 正赛 科尔 投篮 勇士 球员 斯布鲁克 更衣柜 NBA 三连庄 张卫平 西部 指导 雷霆 明星队
lines = open(u'西游记.txt', 'rb').read()
print(" ".join(analyse.extract_tags(lines, topK=20, withWeight=False, allowPOS=())))
行者 八戒 师父 三藏 唐僧 大圣 沙僧 妖精 菩萨 和尚 那怪 那里 长老 呆子 徒弟 怎么 不知 老孙 国王 一个
关于TF-IDF 算法的关键词抽取补充
- 关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
自定义语料库示例见这里
用法示例见这里 - 关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
自定义语料库示例见这里
用法示例见这里
- 用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
- 关键词一并返回关键词权重值示例
用法示例见这里
基于 TextRank 算法的关键词抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
算法论文: TextRank: Bringing Order into Texts
基本思想:
- 将待抽取关键词的文本进行分词
- 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
- 计算图中节点的PageRank,注意是无向带权图
lines = open('NBA.txt', 'rb').read()
print(" ".join(analyse.textrank(lines, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))))
全明星赛 勇士 正赛 指导 对方 投篮 球员 没有 出现 时间 威少 认为 看来 结果 相隔 助攻 现场 三连庄 介绍 嘉宾
print(" ".join(analyse.textrank(lines, topK=20, withWeight=False, allowPOS=('ns', 'n'))))
勇士 正赛 全明星赛 指导 投篮 玩命 时间 对方 现场 结果 球员 嘉宾 时候 全队 主持人 照片 全程 目标 快船队 肥皂剧
词性标注
- jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
- 具体的词性对照表参见计算所汉语词性标记集
import jieba.posseg as pseg
words = pseg.cut("我爱自然语言处理")
for word, flag in words:
print('%s %s' % (word, flag))
我 r
爱 v
自然语言 l
处理 v
并行分词
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升 基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
用法:
- jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
- jieba.disable_parallel() # 关闭并行分词模式
实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
注意:并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。
Tokenize:返回词语在原文的起止位置
注意,输入参数只接受 unicode
print "这是默认模式的tokenize"
result = jieba.tokenize(u'自然语言处理非常有用')
for tk in result:
print("%s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
print "\n-----------我是神奇的分割线------------\n"
print "这是搜索模式的tokenize"
result = jieba.tokenize(u'自然语言处理非常有用', mode='search')
for tk in result:
print("%s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
这是默认模式的tokenize
自然语言 start: 0 end:4
Loading model cost 0.950 seconds.
处理 start: 4 end:6
Prefix dict has been built successfully.
非常 start: 6 end:8
有用 start: 8 end:10
-----------我是神奇的分割线------------
这是搜索模式的tokenize
自然 start: 0 end:2
语言 start: 2 end:4
自然语言 start: 0 end:4
处理 start: 4 end:6
非常 start: 6 end:8
有用 start: 8 end:10
ChineseAnalyzer for Whoosh 搜索引擎
from jieba.analyse import ChineseAnalyzer
# -*- coding: UTF-8 -*-
from __future__ import unicode_literals
import sys,os
sys.path.append("../")
from whoosh.index import create_in,open_dir
from whoosh.fields import *
from whoosh.qparser import QueryParser
analyzer = jieba.analyse.ChineseAnalyzer()
schema = Schema(title=TEXT(stored=True), path=ID(stored=True), content=TEXT(stored=True, analyzer=analyzer))
if not os.path.exists("tmp"):
os.mkdir("tmp")
ix = create_in("tmp", schema) # for create new index
#ix = open_dir("tmp") # for read only
writer = ix.writer()
writer.add_document(
title="document1",
path="/a",
content="This is the first document we’ve added!"
)
writer.add_document(
title="document2",
path="/b",
content="The second one 你 中文测试中文 is even more interesting! 吃水果"
)
writer.add_document(
title="document3",
path="/c",
content="买水果然后来世博园。"
)
writer.add_document(
title="document4",
path="/c",
content="工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作"
)
writer.add_document(
title="document4",
path="/c",
content="咱俩交换一下吧。"
)
writer.commit()
searcher = ix.searcher()
parser = QueryParser("content", schema=ix.schema)
for keyword in ("水果世博园","你","first","中文","交换机","交换"):
print(keyword+"的结果为如下:")
q = parser.parse(keyword)
results = searcher.search(q)
for hit in results:
print(hit.highlights("content"))
print("\n--------------我是神奇的分割线--------------\n")
for t in analyzer("我的好朋友是李明;我爱北京天安门;IBM和Microsoft; I have a dream. this is intetesting and interested me a lot"):
print(t.text)
命令行分词
使用示例:python -m jieba news.txt > cut_result.txt
命令行选项(翻译):
使用: python -m jieba [options] filename
结巴命令行界面。
固定参数:
filename 输入文件
可选参数:
-
-h, --help 显示此帮助信息并退出
-
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔词语,而不是用默认的’ / '。
若不指定 DELIM,则使用一个空格分隔。 -
-p [DELIM], --pos [DELIM]
启用词性标注;如果指定 DELIM,词语和词性之间
用它分隔,否则用 _ 分隔 -
-D DICT, --dict DICT 使用 DICT 代替默认词典
-
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作为附加词典,与默认词典或自定义词典配合使用 -
-a, --cut-all 全模式分词(不支持词性标注)
-
-n, --no-hmm 不使用隐含马尔可夫模型
-
-q, --quiet 不输出载入信息到 STDERR
-
-V, --version 显示版本信息并退出
如果没有指定文件名,则使用标准输入。