selenium 自动化测试
Selenium 是一个用于Web应用程序测试的工具,支持多平台、多浏览器、多语言去实现自动化测试。目前在Web自动化领域应用越来越广泛。
selenium 介绍
Selenium的特点如下:
- 开源、免费
- 多浏览器支持:Firefox、Chrome、IE、Opera、Edge
- 多平台支持:Linux、Windows、MAC
- 多语言支持:Python、Java、C++、Javascript
- 对Web页面有良好的支持
- 支持分布式测试用例执行
selenium 的组成
selenium由selenium IDE,selenium Grid、Selenium RC、Webdriver组成。其中,Webdriver是在Selenium2.0加入的,可以将其看作Selenium RC的替代品。
测试环境搭建(略)
1、安装python
2、安装selenium
3、安装对应的浏览器驱动(各个浏览器驱动下载地址)
WebDriver API
Webdriver属于selenium中设计出的操作浏览器的一套API,因为Webdriver针对多种编程语言都实现了一遍这套API,所以它可以支持多种编程语言,在此处我使用python语言进行程序编写。
从定位元素开始
自动化要做的就是模拟鼠标和键盘来操作这些元素,或单击,或输入,或鼠标悬停,拖拽等。
但操作这些元素的前提是需要找到它们,自动化测试工具无法像测试人员一样通过肉眼分辨这些元素,那么如何找到它们呢?通过查看网页代码,我们可以发现每一个元素都是由一行行代码组成的,它们之间有层级地组织起来,每个元素都有自己的标签名和属性值,Webdriver就可以通过这些信息来找到不同元素。
WebDriver提供了八种元素定位方法
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()
id定位
HTML规定id属性在HTML文档中必须是唯一的,这类似于公民的身份证号,具有很强的唯一性。通过id定位百度输入框与百度搜索按钮,用法如下:
find_element_by_id("kw")
find_element_by_id("su")
name定位
HTML规定name来指定元素的名称,因此它的作用更像是人的姓名。可以不唯一。通过name定位百度输入框:
find_element_by_name("wd")
百度搜索按钮并没有提供name属性,因此我们不能通过name属性来定位。
class定位
class指定元素的类名,用法与id、name类似
find_element_by_class_name("s_ipt")
find_element_by_class_name("bg s_btn")
tag定位
HTML的本质就是通过tag来定义实现不同的功能,每一个元素本质上就是一个tag对象。因为一个tag往往用来定义一类功能,所以通过tag来识别某一个元素的概率很低。
通过tag查找百度输入框和百度按钮会发现它们完全相同。
find_element_by_tag_name("input")
link定位
link定位与前面介绍的几种定位方法有所不同,它专门用来定位文本链接,用 find_element_by_link_text 方式定位,标签必须是的元素,才能成功。
partial link 定位
partial link定位是对link定位的一种补充,有些文本链接会比较长,这时候我们可以取文本链接的一部分定位,只需要一部分信息就可以唯一标识这个链接。
XPath 定位
前面介绍的几种定位方式相对来说比较简单,但如果有时候一个元素没有id、name属性,或者多个元素属性值相同,又或者每次刷新页面,id属性值会随机变化,这些情况下,我们如何定位元素?
Xpath是一种在XML文档中定位元素的语言,因为HTML可以看作XML的一种实现,所以可以使用xpath在web应用中定位元素。
绝对路径定位:元素的绝对路径,从最外层html一级一级往下查找,这种方式写出来一般可读性不强,但比较简单。
元素属性定位:即通过结合属性值来定位,一般使用这种方式查找元素(如果不想指定标签名,则可以用星号*代替)
使用逻辑运算符
有时候一个属性不能唯一区分一个元素,我们还可以使用逻辑运算符 and 连接多个条件来查找元素。
find_element_by_xpath('//input[@name="xxx" and @class="xxx"]')
CSS 定位
CSS用来描述HTML文档的表现,CSS使用选择器来为页面元素绑定属性。这些选择器可以被Selenium用作另外的定位策略。一般情况下定位速度比XPath快,但难度稍高。
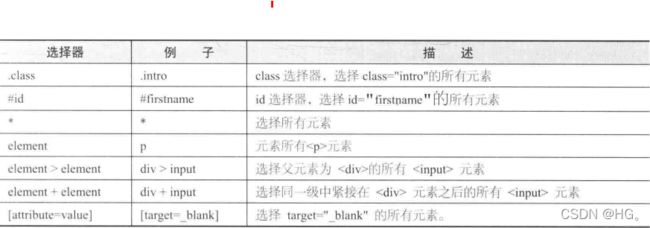
通过 By 来定位元素
针对前面介绍的几种定位方法,WebDriver还提供了另一套写法,即同一调用find_element()方法。通过By来声明定位的方法,并且传入对应定位方法的定位参数。(上面的方法可能被弃用了)
find_element(By.ID, 'xxx')
find_element(By.NAME, 'xxx')
find_element(By.CLASS_NAME, 'xxx')
find_element(By.TAG_NAME, 'xxx')
find_element(By.LINK_TEXT, 'xxx')
find_element(By.PARTIAL_LINK_TEXT, 'xxx')
find_element(By.XPATH, 'xxx')
find_element(By.CSS_SELECTOR, 'xxx')
该方法需要两个参数,第一个是定位的类型,第二个是定位的具体方式,在使用之前需要将By类导入。
from selenium.webdriver.common.by import By
控制浏览器
WebDriver 主要提供的是操作页面上各种元素的方法,但也提供了操作浏览器的一些方法,如控制浏览器大小,操作浏览器前进后退等。
set_window_size() 方法设置浏览器大小
maximize_window() 最大化
back() 后退
forward() 前进
refresh() 刷新当前页面
简单元素操作
定位到元素之后就需要对元素进行操作,或点击或输入,常用方法如下:
clear() 清除文本
send_keys() 模拟输入
click() 单击元素
submit() 提交表单
get_attribute(name) 获取元素属性值
is_displayed() 返回元素是否可见
size 返回1元素尺寸
text 获取元素文本
ActionChains 鼠标事件
在WebDriver中,关于鼠标操作的方法封装在ActionChains类中,我们可以通过ActionChains类来执行这些方法。
click(on_element=None) ——单击鼠标左键
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
对于ActionChains类所提供的鼠标方法与前面学过的click()方法的用法有所不同,首先需要引入ActionChains类,然后将所有的操作按顺序放在一个队列里,在调用perform()方法时,队列中的操作会依次执行。
# 链式写法
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
# 分步写法
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
键盘事件
Keys()类提供了键盘上按键的方法。send_keys()方法不仅可以模拟键盘输入,还可以用来输入键盘上的按键,包括组合键。使用前需引入Keys类。
send_keys(Keys.BACK_SPACE) 删除键
send_keys(Keys.SPACE) 空格键
send_keys(Keys.TAB) 制表符
send_keys(Keys.ENTER) 回车键
send_keys(Keys.CONTROL,'a') 全选
send_keys(Keys.CONTROL,'c') 复制
send_keys(Keys.CONTROL,'x') 剪切
send_keys(Keys.CONTROL,'v') 粘贴
send_keys(Keys.F1) 键盘F1
send_keys(Keys.F12) 键盘F12
元素等待
在浏览器加载页面时,页面上的元素可能并不是同时被加载完成的,会给元素定位增加困难。此时,我们可以通过设置元素等待改善这种问题造成的不稳定。
显式等待
显式等待使WebDriver等待某个条件成立时继续执行,否则在达到最大时长时抛出异常。一般由until()或until_not()方法配合使用。
WebDriverWait(driver, timeout, poll_frequency=0.5,ignore_exception=None)
# driver:浏览器驱动
timeout:最长超时时间,单位默认为秒
poll_frequrncy:检测的间隔,默认0.5S
ignored_exceptions:超时后的异常信息,默认抛出没有元素的异常
excepted_conditions 类提供的与其条件判断方法
隐式等待
WebDriver 提供了implicitly_wait()方法来实现隐式等待。它相对于显式等待并没有明确的条件。
sleep 休眠方式
有时候我们希望脚本在执行到某一位置时做固定时间的休眠,这时可以使用sleep()方法。
多表单切换
在Web应用中经常会用到frame/iframe表单嵌套页面的应用,但WebDriver只能在一个页面上对元素识别与定位。此时就需要通过 switch_to.frame()方法将当前定位的主体切换为 frame/iframe表单的内嵌页面中。
switch_to.frame()默认可以直接取表单的id或name属性,如果没有这两个属性,则可以通过其他方法先定位到元素然后传递给switch_to.iframe()方法进行定位。
多窗口切换
类似于多表单切换,我们可以通过window_handles属性来查看当前所有打开的窗口句柄。current_window_handle 获得当前窗口的句柄。
警告框处理
处理JavaScript所生成的alert、confirm以及prompt 十分简单,可以使用 switch_to_alert() 方法定位到 alert/confirm/prompt,然后使用accept/dismiss/send_keys 等方法进行操作。
text:返回文字信息
accept():接受现有警告框
dismiss:解散现有警告框
send_keys():发送文本至警告框
操作 Cookie
WebDriver 操作 cookie 的方法:
get_cookies() 获取所有cookie信息
get_cookie(name) 返回字典的key为name的cookie信息
add_cookie(cookie_dict) 添加cookie,字典对象
delete_cookie(name) 删除指定cookiexinxi
delete_all_cookies() 删除所有cookie信息
调用 JavaScript(功能强大)
WebDriver 对于浏览器滚动条并没有提供相应的操作方法。在这种情况下,我们可以通过 JavaScript 来控制浏览器滚动条。WebDriver 提供了 execute_script() 方法来执行 JavaScript 代码(最好是了解一下js)。
window.scrollTo('左边距', '上边距') 设置窗口滚动条位置
窗口截图
在自动化测试过程中,我们有时候需要对当前窗口进行截图保存。WebDriver 提供了 get_screenshot_as_file() 来截取当前窗口。
driver.get_screenshot_as_file('文件路径')
验证码处理(机器学习,打码平台)
1、验证码识别技术,例如提供 Python-tesseract 来识别图片验证码(光学字符识别)
2、记录 cookie ,绕过验证码
Selenium IDE(略)
Selenium IDE 结合浏览器提供了脚本的录制、回放以及编辑脚本功能,可以帮助我们学习自动化测试。还可以生成相应代码。
selenium IDE 文档
HTML 测试报告
HTMLTestRunner 是Python 标准库 unittest 单元测试框架的一个扩展,它可以生成易于使用的HTML测试报告。下载地址,并将下载的文件保存到python Lib目录下。
HTMLTestRunner.py 是基于Python 2 开发的,为了使其支持 Python 3 的环境,要对其进行部分修改。
第 94 行改为:import io
第 539 行改为:self.outputBuffer = io.StringIO()
第 631 行:2.x和3.x print()函数的区别
第 642 行改为:if not cls in ramp:
第 766 行改为:uo = e
第 772 行改为:ue = e
具体实例如下:
import unittest
from selenium import webdriver
from HTMLTESTRunner import HTMLTestRunner
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.base_url = "http://www.baidu.com"
def test_baidu_search(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_id("kw").send_keys("HTMLTestRunner")
driver.find_element_by_id("su").click()
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
testunit = unittest.TestSuite()
testunit.addTest(Baidu("test_baidu_search"))
fp = open("./result.html", "wb")
runner = HTMLTestRunner(stream=fp, title='百度搜索测试报告', description='用例执行情况:')
runner.run(testunit)
fp.close()
selenium 项目实战
最近在登录慕课网时发现之前学的网课练习题没刷,就考虑写一个自动化程序作题,代码如下。目前代码功能还不够完善(选择填空),并不能保证正确率。仅供参考。
import time
import random
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
start_time = time.time()
driver = webdriver.Chrome()
driver.get('https://www.icourse163.org/?from=study')
driver.maximize_window()
driver.implicitly_wait(20)
driver.find_element_by_xpath('//div[@class="unlogin"]/a').click()
driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]').click()
driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[2]').click()
time.sleep(2)
driver.switch_to.frame(driver.find_element_by_xpath('//div[@class="ux-login-urs-phone-wrap f-pr"]//iframe'))
driver.find_element_by_xpath('//input[@id="phoneipt"]').send_keys('username')
time.sleep(2)
driver.find_element_by_xpath('//div[@class="m-container"]/div[4]/div[2]/input[2]').send_keys('password')
time.sleep(2)
driver.find_element_by_xpath('//div[@class="f-cb loginbox"]/a').click()
WebDriverWait(driver,10).until(EC.title_is('中国大学MOOC(慕课)_国家精品课程在线学习平台'))
print('登陆成功')
time.sleep(3)
driver.find_element_by_xpath('//div[@class="u-navLogin-myCourse-t"]//a').click()
driver.find_element_by_xpath('//div[@class="course-panel-body-wrapper"]//div[@class="box"]').click()
time.sleep(5)
for _ in driver.window_handles:
if _ != driver.current_window_handle:
driver.switch_to.window(_)
time.sleep(2)
driver.find_element_by_xpath('//ul[@id="j-courseTabList"]/li[4]/a').click()
time.sleep(2)
for xh in driver.find_elements_by_link_text('前往测验'):
xh.click()
time.sleep(2)
try:
driver.find_element_by_link_text('开始测验').click()
except selenium.common.exceptions.NoSuchElementException as e:
print(e)
time.sleep(2)
num = len(driver.find_elements_by_xpath('//div[@class="j-list"]/div[1]/div//ul'))
for i in range(num):
max_num = len(driver.find_elements_by_xpath('//div[@class="j-list"]/div[1]/div[' + str(i+1) + ']//ul/li'))
r = random.randint(1,max_num)
driver.find_element_by_xpath('//div[@class="j-list"]/div[1]/div[' + str(i+1) + ']//ul' + '/li[' + str(r) + ']').click()
time.sleep(0.5)
driver.find_element_by_xpath('//div[@class="m-quizDoing u-learn-modulewidth"]//div[@class="m-quizDoing"]/a').click()
time.sleep(1)
driver.find_element_by_xpath('//span[@class="j-ok-txt"]').click()
time.sleep(1)
driver.back()
time.sleep(0.8)
driver.back()
time.sleep(1)
driver.quit()
end_time = time.time()
print('cost_time:'+str(end_time-start_time))