selenium自动化测试
文章目录
- 1.什么是自动化测试
- 2.UI自动化测试
- 3, webdriver的原理
- 元素的定位
-
- 定位操作示例
- 操作测试对象
- 添加等待
-
- 固定等待
- 智能等待
- 打印信息
- 浏览器的操作
-
- 浏览器最大化
- 设置浏览器宽、高
- 操作浏览器的前进、后退
- 控制浏览器滚动条
- 键盘事件
-
- 键盘按键用法
- 键盘组合键用法
- 鼠标事件
-
- ActionChains 类
- 定位一组元素
- 多层框架/窗口定位
- 层级定位
- 下拉框处理
- alert 弹框处理
- DIV对话框的处理
- 文件上传操作
1.什么是自动化测试
在预设的条件下运行系统,预设的条件包括正常和异常的条件,不需要手工干涉,机器就可以执行。
2.UI自动化测试
(1) 进行大量重复测试,进行回归测试
(2) 减少人为出错几率,创建一个可靠测试过程
(3) 可以进行繁琐测试。(比如测试过程一致,每次输入数据不同)
(4) 进行手工测试很难执行的测试。
(5) 节省资源(人力资源)
(6) 脚本的复用性(价值)
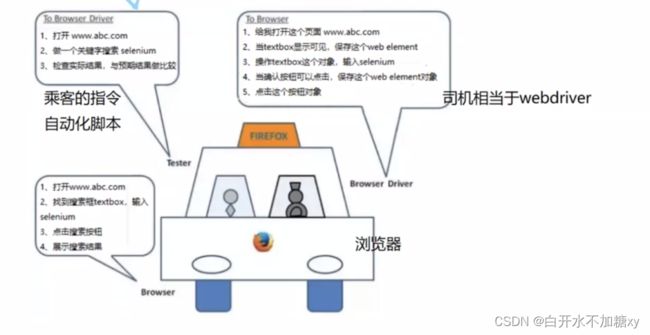
3, webdriver的原理
(1) 运行脚本,把浏览器绑定到一个端口,这个端口就是浏览器端的remote server
(2) 脚本通过commandexecutor,向server发送HTTP请求,控制浏览器进行一系列的操作
(3) server 接收到请求后,把 Web server 命令转为浏览器的native指令,去操作浏览器
元素的定位
selenium要操作浏览器需需要安装相应的驱动:selenium的webdrive驱动安装(谷歌浏览器)
大大前提是要安装python 环境及下载Pycharm
对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。我们可以通过属性找到这对象
注意:不管用那种方式,必须保证页面上该属性的唯一性
webdriver 提供了一系列的对象定位方法,常用的有以下几种:
- id
- name
- class name
- link text
- partial link text
- tag name
- xpath
- css selector
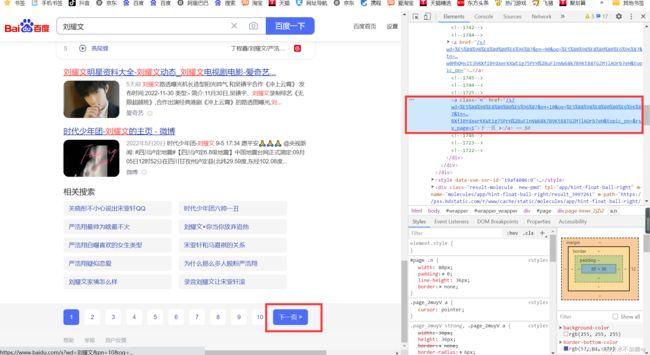
通过 浏览器 中开发者工具,定位页面上的控件,找到其对象的属性(id,class name 等)
找到定位的html语句后,右击copy 可以copy 到selector 、XPath等属性。
定位操作示例
1.浏览器打开百度网页
2.在打开页面中,搜索框输入 想搜索的内容
3.输出搜索结果条数,找到标签并获取文本信息,如下图所示(即打印 百度为您找到相关结果约100,000,000个 这个信息)
4.定位下一页,获取链接地址

代码:
from selenium import webdriver
# 导入时间包的睡眠
from time import sleep
# 创建浏览器对象
from selenium.webdriver.common.by import By
dr = webdriver.Chrome()
# 浏览器打开网页
dr.get("http://www.baidu.com")
# 休眠3秒
sleep(3)
# 在打开页面中,搜索框输入 刘耀文
dr.find_element(By.ID, "kw").send_keys("刘耀文")
dr.find_element(By.ID, "su").click()
sleep(2)
# 输出搜索结果页面的标题
print(dr.title)
# 输出搜索结果条数,找到标签并获取文本信息 #tsn_inner > div:nth-child(2) > span
# 如果class_name 中间有空格的话,说明有多个类,选其中一个就行了
res = dr.find_element(By.CLASS_NAME, 'hint_PIwZX').text
# res = dr.find_element(By.CSS_SELECTOR, '#tsn_inner > div:nth-child(2) > span').text
# res = dr.find_element(By.XPATH, '//*[@id="tsn_inner"]/div[2]/span').text
print(res)
sleep(5)
# 定位下一页,获取链接地址
href = dr.find_element(By.LINK_TEXT, '下一页 >').get_attribute("href")
print(href)
!!!注意:如果class_name 中间有空格的话,说明有多个类,选其中一个就行了 如第一个图中右边红框所圈的地方。
输出结果:

操作测试对象
send_keys() :向元素发送信息
click() :点击元素
clear 清除对象的内容,如果可以的话
submit 清除对象的内容,如果可以的话 type 是submit
text 用于获取元素的文本信息
添加等待
为什么等待如此重要:
当页面中元素没有加载出来的时候,无法定位到元素;添加等待保证元素加载后再去进行后续的操作。
固定等待
添加休眠非常简单,我们需要引入time 包,就可以在脚本中自由的添加休眠时间了
import time
time.sleep(3)
智能等待
通过添加==implicitly_wait() ==方法就可以方便的实现智能等待;implicitly_wait(30)的用法应该比time.sleep() 更智能,后者只能选择一个固定的时间的等待,前者可以在一个时间范围内智能的等待。
等待页面的元素加载出来后立刻去执行下一个相关指令。
# coding = utf-8
from selenium import webdriver
import time #调入time 函数
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
browser.implicitly_wait(30) #智能等待30秒
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
browser.quit()
打印信息
在 上边的定位操作示例已应用了 打印 title 的操作,也可通过下面小的例子操作:
#coding = utf-8
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print driver.title # 把页面title 打印出来
print driver.current_url #打印url
driver.quit()
浏览器的操作
# coding=utf-8
from selenium import webdriver
# 创建浏览器对象
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
time.sleep(2)
# 参数数字为像素点
print("设置浏览器宽480、高800显示")
browser.set_window_size(480, 800)
time.sleep(3)
# 将浏览器最大化显示
browser.maximize_window()
time.sleep(2)
browser.find_element(By.ID, "kw").send_keys("selenium")
browser.find_element(By.ID, "su").click()
time.sleep(10)
# 将页面滚动条拖到底部
js="var q=document.documentElement.scrollTop=10000"
browser.execute_script(js)
time.sleep(3)
#将滚动条移动到页面的顶部
js="var q=document.documentElement.scrollTop=0"
browser.execute_script(js)
time.sleep(3)
# 返回(后退)到百度首页
browser.back()
time.sleep(10)
# browser.find_element(By.CLASS_NAME, 'mnav').click()
# time.sleep(10)
# # 浏览器前进
# browser.back()
# time.sleep(10)
# #前进百度
# second_url = "http://news.baidu.com";
# print ("forward to %s"%(second_url))
browser.forward()
time.sleep(10)
browser.quit()
浏览器最大化
browser.maximize_window()
设置浏览器宽、高
browser.set_window_size(480, 800)
操作浏览器的前进、后退
browser.back()
# 浏览器前进
browser.back()
控制浏览器滚动条
# 将页面滚动条拖到底部
js="var q=document.documentElement.scrollTop=10000"
browser.execute_script(js)
#将滚动条移动到页面的顶部
js="var q=document.documentElement.scrollTop=0"
browser.execute_script(js)
键盘事件
示例
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
from selenium.webdriver.common.by import By
hh = webdriver.Chrome()
hh.get("http://www.baidu.com")
sleep(4)
hh.find_element(By.ID, 'kw').send_keys("seleniumm")
sleep(3)
hh.find_element(By.ID, 'kw').send_keys(Keys.BACK_SPACE)
# 全选文本框中输入内容
hh.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'a')
sleep(3)
hh.find_element(By.ID, 'su').send_keys(Keys.ENTER)
键盘按键用法
要想调用键盘按键操作需要引入keys 包:
from selenium.webdriver.common.keys import Keys
通过send_keys()调用按键:
send_keys(Keys.TAB) # TAB 可以将焦点定位
send_keys(Keys.ENTER) # 回车
键盘组合键用法
#ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
time.sleep(3)
#ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')
time.sleep(3)
鼠标事件
示例:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
wd = webdriver.Chrome()
wd.get("http://www.baidu.com")
sleep(4)
# 定位设置元素
aset = wd.find_element(By.ID, 's-usersetting-top')
# 鼠标移动事件并执行
ActionChains(wd).move_to_element(aset).perform()
sleep(3)
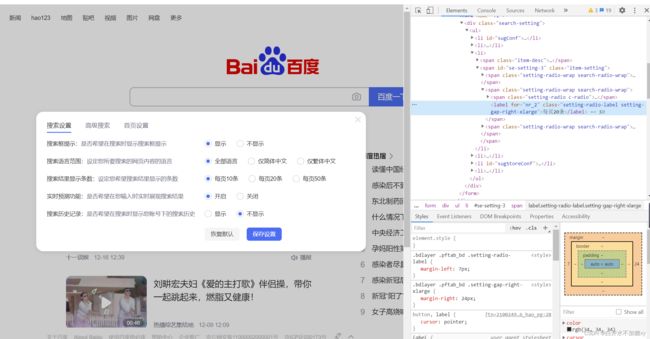
# 点击搜索设置
wd.find_element(By.LINK_TEXT, '搜索设置').click()
sleep(3)
# 设置每页显示结果为20
wd.find_element(By.ID, 'nr_2').click()
sleep(3)
# 保存设置
wd.find_element(By.LINK_TEXT, '保存设置').click()
设置每页显示结果为20
ActionChains 类
- context_click() 右击
- double_click() 双击
- drag_and_drop() 拖动
- move_to_element() 移动
ActionChains(driver).context_click(qqq).perform() #右键
ActionChains(driver).double_click(qqq).perform() #双击
#定位元素的原位置
element = driver.find_element_by_id("s_btn_wr")
#定位元素要移动到的目标位置
target = driver.find_element_by_class_name("btn")
#执行元素的移动操作
ActionChains(driver).drag_and_drop(element, target).perform()
ActionChains(driver)
生成用户的行为。所有的行动都存储在actionchains 对象。通过perform()存储的行为。
move_to_element(menu)
移动鼠标到一个元素中,menu 上面已经定义了他所指向的哪一个元素
perform()
执行所有存储的行为
定位一组元素
1.如何打开本地的HTML页面
拼成一个URL:file: +/// +os.path.abspath(文件绝对路径)
定位一组对象一般用于以下场景:
- 批量操作对象,比如将页面上所有的checkbox 都勾上
- 先获取一组对象,再在这组对象中过滤出需要具体定位的一些对象
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>Checkboxtitle>
head>
<body>
<h3>checkboxh3>
<div class="well">
<form class="form-horizontal">
<div class="control-group">
<label class="control-label" for="c1">checkbox1label>
<div class="controls">
<input type="checkbox" id="c1" />
div>
div>
<div class="control-group">
<label class="control-label" for="c2">checkbox2label>
<div class="controls">
<input type="checkbox" id="c2" />
div>
div>
<div class="control-group">
<label class="control-label" for="c3">checkbox3label>
<div class="controls">
<input type="checkbox" id="c3" />
div>
div>
<div class="control-group">
<label class="control-label" for="r">radiolabel>
<div class="controls">
<input type="radio" id="r1" />
div>
div>
<div class="control-group">
<label class="control-label" for="r">radiolabel>
<div class="controls">
<input type="radio" id="r2" />
div>
div>
form>
div>
body>
html>
通过浏览器打个这个页面我们看到三个复选框和两个单选框。下面我们就来定位这三个复选框。
#coding=utf-8
from selenium import webdriver
# 创建浏览器对象
from selenium.webdriver.common.by import By
import time
import os
dr = webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('D:/PycharmProjects/pythonProject1/checkbox.html')
dr.get(file_path)
# 选择页面上所有的input,然后从中过滤出所有的checkbox 并勾选之
inputs = dr.find_elements(By.TAG_NAME, 'input')
for input in inputs:
if input.get_attribute('type') == 'checkbox':
input.click()
time.sleep(2)
dr.quit()
多层框架/窗口定位
iframe:框架里面嵌套框架
解决不同层框架 上的页面的元素定位
多层框架或窗口的定位:
- switch_to_frame()
- switch_to_window()
有时候我们定位一个元素,定位器没有问题,但一直定位不了,这时候就要检查这个元素是否在一个frame 中,
seelnium webdriver 提供了一个switch_to_frame 方法,可以很轻松的来解决这个问题。
switch_to_frame(name_or_id_or_frame_element):

层级定位
示例:
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>Level Locatetitle>
<script type="text/javascript" src="http://code.jquery.com/jquery-1.9.1.min.js">script>
<link
href="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/css/bootstrap-combined.min.css"
rel="stylesheet" />
head>
<body>
<h3>Level locateh3>
<div class="span3">
<div class="well">
<div class="dropdown">
<a class="dropdown-toggle" data-toggle="dropdown"
href="#">Link1a>
<ul class="dropdown-menu" role="menu"
aria-labelledby="dLabel" id="dropdown1" >
<li><a tabindex="-1" href="#">Actiona>li>
<li><a tabindex="-1" href="#">Another actiona>li>
<li><a tabindex="-1" href="#">Something else herea>li>
<li class="divider">li>
<li><a tabindex="-1" href="#">Separated linka>li>
ul>
div>
div>
div>
<div class="span3">
<div class="well">
<div class="dropdown">
<a class="dropdown-toggle" data-toggle="dropdown"
href="#">Link2a>
<ul class="dropdown-menu" role="menu"
aria-labelledby="dLabel" >
<li><a tabindex="-1" href="#">Actiona>li>
<li><a tabindex="-1" href="#">Another actiona>li>
<li><a tabindex="-1" href="#">Something else herea>li>
<li class="divider">li>
<li><a tabindex="-1" href="#">Separated linka>li>
ul>
div>
div>
div>
body>
<script
src="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/js/bootstrap.min.js">script>
html>
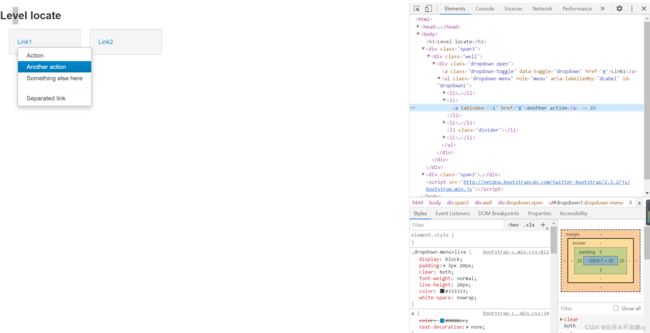
先点击显示出1个下拉菜单,然后再定位到该下拉菜单所在的ul,再定位这个ul 下的某个具体的link
# coding=utf-8
import os.path
from selenium import webdriver
# 创建浏览器对象
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
url = "file:///"+os.path.abspath('D:\\PycharmProjects\\pythonProject1/level_locate.html')
driver.get(url)
driver.maximize_window()
# 定位link 点击
driver.find_element(By.LINK_TEXT, 'Link1').click()
time.sleep(10)
# 找到id 为dropdown1的父元素
WebDriverWait(driver, 10).until(lambda the_driver:
the_driver.find_element(By.ID, 'dropdown1').is_displayed())
# 定位Another action
action = driver.find_element(By.XPATH, '//*[@id="dropdown1"]/li[2]/a')
# Another action高亮显示,把鼠标移动到Another action上
ActionChains(driver).move_to_element(action).perform()
time.sleep(6)
driver.quit()
WebDriverWait(dr, 10)
10秒内每隔500毫秒扫描1次页面变化,当出现指定的元素后结束
is_displayed()
该元素是否用户可以见
下拉框处理
下拉框里的内容需要进行两次定位,先定位到下拉框,再定位到下拉框内里的选项

定位到下拉框内里的选项 可以有多种方式:
如:
- 直接用XPath定位
- 先定位一组元素,然后根据元素的属性进行过滤筛选,再进行具体操作
- 先定位一组元素,再通过数组下标方式定位
#coding=utf-8
from selenium import webdriver
import os,time
# 创建浏览器对象
from selenium.webdriver.common.by import By
driver= webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('drop_down.html')
driver.get(file_path)
time.sleep(2)
# 先定位到下拉框
m = driver.find_element(By.ID, "ShippingMethod")
# # 再点击下拉框下的选项
# m.find_element(By.XPATH, "//option[@value='10.69']").click()
options = driver.find_elements(By.TAG_NAME,'option')
for option in options:
if option.get_attribute('value')=='10.69':
option.click()
time.sleep(3)
driver.quit()
alert 弹框处理
text 返回alert/confirm/prompt 中的文字信息
accept 点击确认按钮
dismiss 点击取消按钮,如果有的话
send_keys 输入值,这个alert\confirm 没有对话框就不能用了
1.定位弹出框、获得弹出框的操作句柄
alert = dr.switch_to.alert()
2.确认取消、输入值 等操作
#接受警告信息
alert = dr.switch_to.alert()
alert.accept()
#得到文本信息打印
alert = dr.switch_to.alert()
print alert.text
#取消对话框(如果有的话)
alert = dr.switch_to.alert()
alert.dismiss()
#输入值
alert = dr.switch_to.alert()
alert.send_keys("hello word")
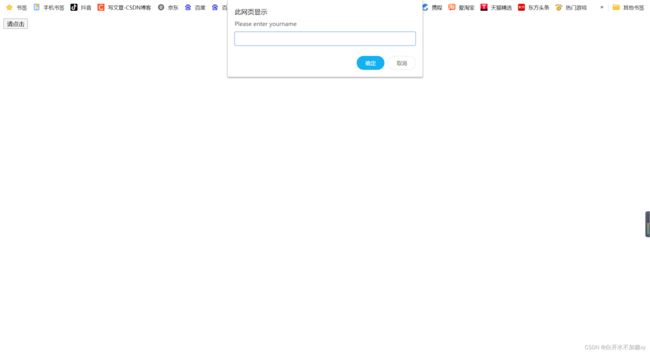
html:
<html>
<head>
<meta charset="UTF-8">
<title>title>
<script type="text/javascript">
function disp_prompt(){
var name=prompt("Please enter yourname","")
if (name!=null &&name!=""){
document.write("Hello " +name + "!")
}
}
script>
head>
<body>
<input type="button" onclick="disp_prompt()"
value="请点击"/>
body>
html>
代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import os
driver=webdriver.Chrome()
driver.implicitly_wait(30)
file_path = 'file:///' + os.path.abspath('D:\\PycharmProjects\\pythonProject1/send.html')
driver.get(file_path)
# driver.get('file:///D:/PycharmProjects/test/send.html')
# 点击“请点击”
driver.find_element(By.XPATH, "html/body/input").click()
sleep(5)
# 输入内容
driver.switch_to.alert.send_keys('webdriver')
driver.switch_to.alert.accept()
sleep(5)
driver.quit()
DIV对话框的处理
处理供更多功能的会话框:
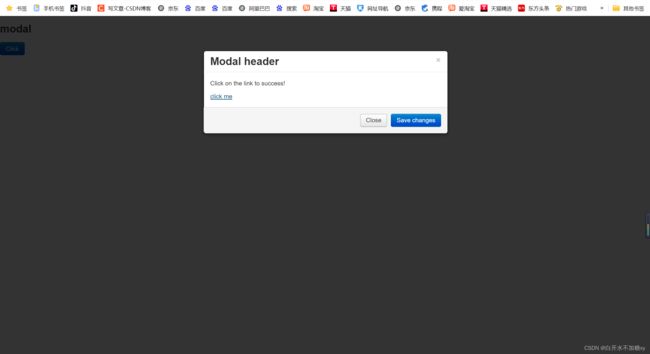
点击对话框中的链接
1.首先定位元素所在的div 模块
2.再定位到div模块基础上,去精确寻找要定位的元素
适用于页面复杂,元素非常多,没有id下,name或tag name重复

定位 close 按钮
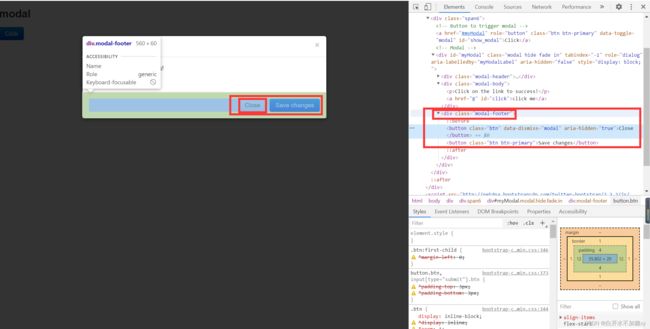
html
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>modaltitle>
<script type="text/javascript" src="http://code.jquery.com/jquery-1.9.1.min.js">script>
<link
href="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/css/bootstrap-combined.min.css"
rel="stylesheet" />
<script type="text/javascript">
$(document).ready(function(){
$('#click').click(function(){
$(this).parent().find('p').text('Click on the link to success!');
});
});
script>
head>
<body>
<h3>modalh3>
<div class="row-fluid">
<div class="span6">
<a href="#myModal" role="button" class="btn btn-primary"
data-toggle="modal" id="show_modal">Clicka>
<div id="myModal" class="modal hide fade" tabindex="-1"
role="dialog" aria-labelledby="myModalLabel" aria-hidden="true">
<div class="modal-header">
<button type="button" class="close" data-dismiss="modal"
aria-hidden="true">×button>
<h3 id="myModalLabel">Modal headerh3>
div>
<div class="modal-body">
<p>Congratulations, you open the window!p>
<a href="#" id="click">click mea>
div>
<div class="modal-footer">
<button class="btn" data-dismiss="modal"
aria-hidden="true">Closebutton>
<button class="btn btn-primary">Save changesbutton>
div>
div>
div>
div>
body>
<script
src="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/js/bootstrap.min.js">script>
html>
代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
import os
import selenium.webdriver.support.ui as ui
dr = webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('D:\\PycharmProjects\\pythonProject1/model.html')
dr.get(file_path)
# 打开对话框
dr.find_element(By.ID, 'show_modal').click()
sleep(5)
# 点击对话框中的链接 先定位DIV,再定位div中的click
link = dr.find_element(By.ID, 'myModal').find_element(By.ID, 'click')
link.click()
sleep(8)
# 关闭对话框
buttons = dr.find_element(By.CLASS_NAME, 'modal-footer').find_elements(By.TAG_NAME, 'button')
buttons[0].click()
sleep(5)
dr.quit()
文件上传操作
html:
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>upload_filetitle>
<script type="text/javascript" src="http://code.jquery.com/jquery-1.9.1.min.js">script>
<link
href="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/css/bootstra
p-combined.min.css" rel="stylesheet" />
<script type="text/javascript">
script>
head>
<body>
<div class="row-fluid">
<div class="span6 well">
<h3>upload_fileh3>
<input type="file" name="file" />
div>
div>
body>
<script
src="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/js/bootstrap.
min.js">script>
html>
代码
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
import os,time
driver = webdriver.Chrome()
# 脚本要与upload_file.html 同一目录
file_path = 'file:///' + os.path.abspath('D:\\PycharmProjects\\pythonProject1/upload.html')
driver.get(file_path)
# 定位上传按钮,添加本地文件
time.sleep(10)
driver.find_element(By.NAME, "file").send_keys('D:\\PycharmProjects\\pythonProject1/a.txt')
time.sleep(2)
driver.quit()
上传过程一般要打开一个本地窗口,从窗口选择本地文件添加。所以,一般会卡在如何操作本地窗口添加上传文件。
其实,在selenium webdriver 没我们想的那么复杂;只要定位上传按钮,通过send_keys 添加本地文件路径就可以了。绝对路径和相对路径都可以,关键是上传的文件存在。