vue和SpringBoot搭建项目(原创)
1.element官网
https://element.eleme.cn/#/zh-CN/component/installation
2.element介绍
Element:网站快速成型工具。是饿了么公司前端开发团队提供的一套基于 Vue 的网站组件库。
使用 Element 前提必须要有 Vue。
组件:组成网页的部件,例如 超链接、按钮、图片、表格等等~
3.element下载
npm 安装
推荐使用 npm 的方式安装,它能更好地和 webpack 打包工具配合使用。
npm i element-ui -S
4.element引入
import Vue from 'vue'
import App from './App.vue'
import router from './router'
import ElementUI from 'element-ui';
import 'element-ui/lib/theme-chalk/index.css';
import './assets/global.css'
Vue.config.productionTip = false
Vue.use(ElementUI,{size:"mini"});
new Vue({
router,
render: h => h(App)
}).$mount('#app')
在main.js中引入
5.vue中使用element中Container 布局容器进行布局
导航一
分组一
选项1
选项2
选项3
选项4
选项4-1
导航二
分组一
选项1
选项2
选项3
选项4
选项4-1
导航三
分组一
选项1
选项2
选项3
选项4
选项4-1
查看
新增
删除
王小虎
在HomeView.vue
5.App.vue的作用
App.vue是项目的主组件,页面入口文件 ,所有页面都在App.vue下进行切换,app.vue负责构建定义及页面组件归集。
在App.vue
6.去除边框
html,body,div{
margin: 0;
padding: 0;
}
html,body{
height: 100%;
}在assets下global.css
import './assets/global.css'引入样式
在main.js
7.增加搜索框
/*常用的样式,根据自己需要去定义*/
/*就表示margin-left=5px*/
.ml-5{
margin-left: 5px;
}
.ml-5{
margin-right: 5px;
}
.ml-5{
margin-left: 5px;
}
.ml-5{
padding: 10px 0;
}
在global.css,常用的样式可以定义一下
搜索
在Home.vue中 (suffix-icon=图标)
8.表格改造
在Home.vue中
border stripe(加上表格和斑马线)
header-cell-class-name="headerBg(定义表格名字,进行style修改样式)
.headerBg{
background-color: cyan !important;
}修改背景颜色
!important
(
解答:CSS 中的 !important 规则用于增加样式的权重。!important 与优先级无关,但它与最终的结果直接相关,使用一个 !important 规则时,此声明将覆盖任何其他声明。
例如:
#myid {
background-color: blue;
}
.myclass {
background-color: gray;
}
p {
background-color: red !important;
}
以上实例中,尽管ID 选择器和类选择器具有更高的优先级,但三个段落背景颜色都显示为红色,因为 !important 规则会覆盖 background-color 属性。
重要说明
使用!important 是一个坏习惯,应该尽量避免,因为这破坏了样式表中的固有的级联规则,使得调试找bug 变得更加困难了。
)
1.创建SpringBoot项目
1.1、什么是SpringBoot?
SpringBoot是一个开发基于Spring框架的应用的快速开发框架,它也是SpringCloud构建微服务分布式系统的基础设施。
1.2、SpringBoot有哪些主要特性?
SpringBoot的主要特色包括构建独立的Spring应用、嵌入式的Web容器、固化的starter依赖、自动装配Spring模块或第三方库、产品就绪特性(日志、指标、健康检查、外部化配置等)、避免或简化XML配置等特性。
可独立运行的Spring应用
相对于普通的Spring应用,使用SpringBoot构建的Spring应用可以直接打包为一个独立可执行的jar或war包,使用java -jar命令即可运行,不需要管理依赖的第三方库,也不需要依赖外部容器来启动应用。之前使用Spring开发的Java Web应用,一般都会在第三方的Web容器中启动,比如Tomcat等,而使用SpringBoot开发的Java Web应用,虽然基于Spring,但它提供了内嵌的Web容器(基于Servlet或Reactive的Web容器,如Tomcat、Jetty、Undertow、NettyWebServer),通过SpringBoot插件,把所有依赖的第三方库、Web容器和应用本身一起重新打包(repackage)为一个Fat Jar或Fat War,然后直接使用java -jar命令运行即可。
嵌入式Web容器
SpringBoot内置了多种嵌入式Web容器,包括Tomcat、Jetty、Undertow、NettyWebServer等,用于运行基于Servlet或Reactive的Web应用,无需再打包部署WAR文件,即不需要依赖外部的Web容器部署。
固化的starter依赖
SpringBoot提供了一系列的starter依赖,用于快速的引入应用依赖的Spring模块及相关的第三方库。不同版本的SpringBoot,与其依赖的Spring模块及其相关的第三方库的版本关系是固定的,一一对应的。开发人员不需要关注依赖的Spring模块和第三方库的版本,只需要关心SpringBoot的版本即可,SpringBoot会正确引入依赖的Spring模块和第三方库的版本。固化依赖,可以降低SpringBoot应用管理依赖的成本。
自动装配Spring模块或第三方库
SpringBoot启动应用时,会推断应用类型,并检测引入的Spring模块或第三方库,当条件满足时自动加载Spring模块或第三方库的组件到容器中,以提供给应用使用。
产品就绪特性
SpringBoot提供了应用部署产品环境运行所必须的日志、指标、健康检查、外部化配置等特性,为部署后的运维提供工具支持,支撑应用尽可能快的部署到产品环境。
避免或简化配置
不会额外生成代码,并且可以简化甚至不需要xml或properties文件配置,即可快速开发Spring应用。
1.3、Spring、SpringBoot、SpringCloud有什么区别?
以前说到Spring,一般指Spring框架(SpringFramework),它是一个开源、轻量级的Java应用开发框架。其核心是控制反转IOC和面向切面编程AOP。Spring提供了很多包括ORM、事务管理、WebMVC等非常有用的模块构建Java应用。
SpringBoot则是在Spring基础之上,用于快速构建Spring应用的一个框架,它并不是要取代Spring,而是基于Spring的。
SpringCloud是一个分布式微服务系统的开发框架,SpringBoot则是SpringCloud的基础设施。三者之间都不是取代的关系,而是一种倒三角的依赖关系,顶层是SpringCloud,中间层是SpringBoot,底层是Spring。
1.4、SpringBoot项目搭建
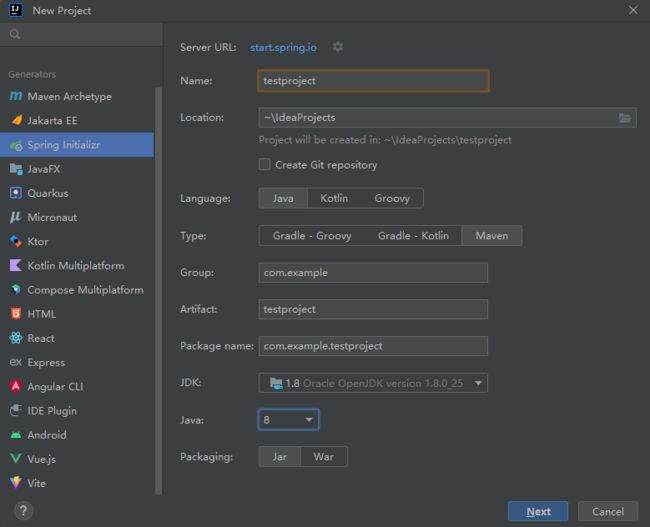
Name:项目名称
Location:项目地址路径
Group:网址域名倒着写,例如com.hjk.www那反过来就是www.hjk.com
Jdk:Jdk版本
Java:
(
解答:一般有两个原因
根据IDEA版本不同来确定的,有的版本支持的是jdk8以及以上的版本,有的支持更好的版本,因此这个是不固定的,可以看到这个是可以选择的(通过8旁边的下拉列表)
这个版本是可以选择的,如果默认选择的是8,是因为你安装的环境变量就是8
)
Packaging:打包方式,一般是用Jar打包
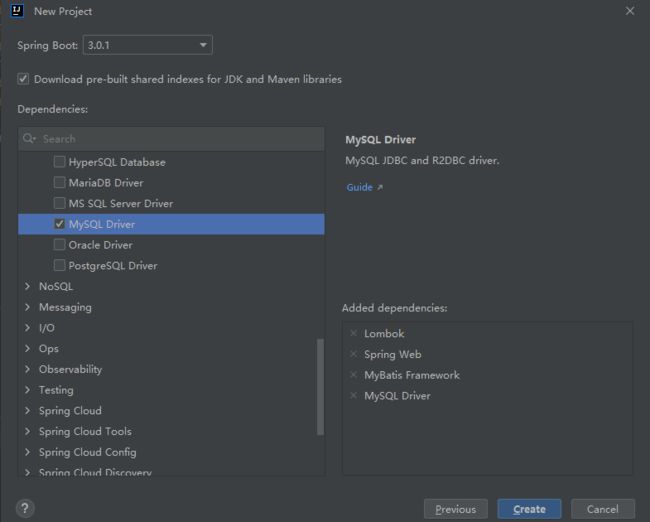
Lombok:我们在实际工作中经常会使用lombok来简化我们的开发,例如我们可以在定义的model类上添加@Data注解,从而免去手写get、set、toString、equals、hashcode等方法。
SpringWeb:(写接口的时候,需要展示数据,后端从数据库把数据查询出来,然后封装成一个json,返回给前端,其实这个web,就是SpringMvc.)
Mybatis Framework:持久层的框架用的mybatis,也可以用JPA(如果使用MybatisPlus框架,可以不需要勾选Mybatis Framework)。
MySQLDriver:(mysql的驱动,如果你的java代码想连接mysql,如果没有驱动是连接不了的,java代码就是通过这个驱动,跟数据库进行连接的)
备注:如果你有忘选的,可以后续添加的,可以在你pom依赖里,进行添加自己想要的其他一些组件。
备注:(太高的版本不是不能使用,可以使用,但是出现的问题可能比较多,不太稳定,需要后期的维护,因此选择相对比较稳定的版本,就像手机的系统,新的系统难免出现各种的问题,当出现问题的时候,只能通过后期版本的更新来维护。)
1.5.进行下载pom依赖

进行下载依赖,我们是通过pom进行定义的,maven是一个远程仓库,通过maven这个坐标,去把项目依赖进行下载,然后存在External Libraries文件夹中。
备注:头一次创建项目下载速度会比较慢,等后续速度就相比较快了。

里面有很多依赖jar包,从远程仓库下载了很多,我们相关需要的依赖jar包,到我们本地来,我们本地的项目就可以跑起来,如果没有这些依赖jar进行支持,我们本地是无法创建一个完整的项目,一个web服务需要很多东西,我们springBoot都帮我做好了,我们只需要定义pom坐标,自然会成远程仓库进行下载的。
1.6.SpringBoot初始项目结构
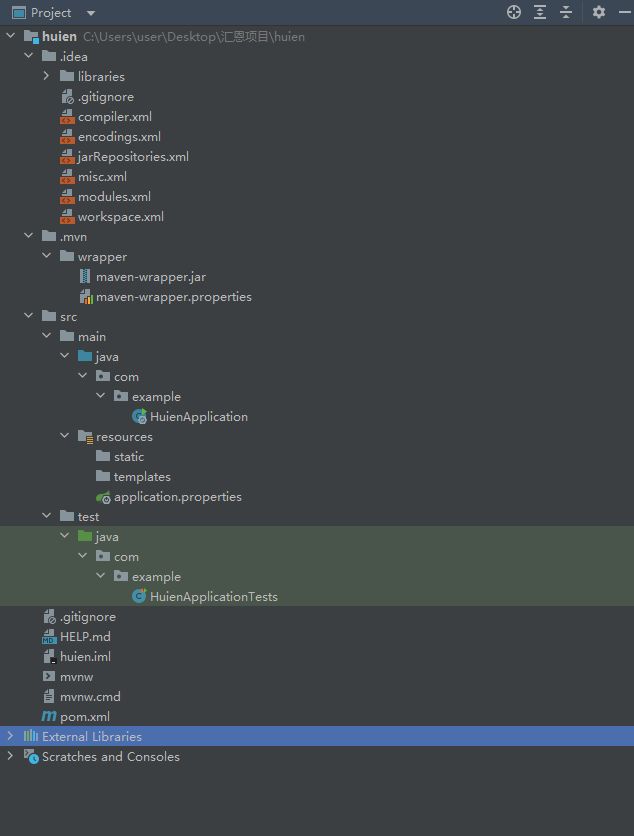
完整的项目结构
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.7.9
com.example
testProject
0.0.1-SNAPSHOT
testProject
testProject
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-configuration-processor
true
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
com.baomidou
mybatis-plus-boot-starter
3.4.1
org.springframework.boot
spring-boot-maven-plugin
org.projectlombok
lombok
pom.xml最初代码
额外加入Mybatis-plus依赖
1.6.将pom.project文件修改成pom.yml
server:
port: 9090
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/qing?serverTimezone=UTC&characterEncoding=utf-8
username: root
password: 1234
mybatis:
mapper-locations: classpath:mapper/*.xml #扫描所有的mybatis.xml文件
# configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
Server port:端口号,当端口号重复的时候,再去设置,一般情况下可以不用设置
Spring datasource:配置数据库资源
Driver-class-name:驱动名
Url:路径
Username:用户名
Password:密码
Mybatis-plus configuration:配置资源
Log-impl:配置日志
备注:
8.0版本是:com.mysql.cj.jdbc.Driver
5.0版本是:com.mysql.jdbc.Driver
2.SpringBoot测试项目启动
1.1.三层架构原理
什么是三层?
UI(表现层): 主要是指与用户交互的界面。用于接收用户输入的数据和显示处理后用户需要的数据。
BLL:(业务逻辑层): UI层和DAL层之间的桥梁。实现业务逻辑。业务逻辑具体包含:验证、计算、业务规则等等。
DAL:(数据访问层): 与数据库打交道。主要实现对数据的增、删、改、查。将存储在数据库中的数据提交给业务层,同时将业务层处理的数据保存到数据库。(当然这些操作都是基于UI层的。用户的需求反映给界面(UI),UI反映给BLL,BLL反映给DAL,DAL进行数据的操作,操作后再一一返回,直到将用户所需数据反馈给用户)
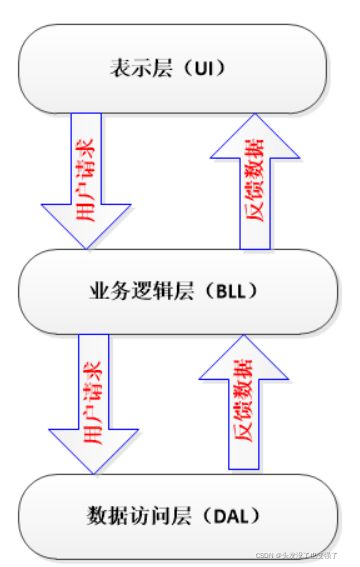
Entity(实体层):它不属于三层中的任何一层,但是它是必不可少的一层。
Entity在三层架构中的作用
对于大量的数据来说,用变量做参数有些复杂,因为参数量太多,容易搞混。比如:我要把员工信息传递到下层,信息包括:员工号、姓名、年龄、性别、工资....用变量做参数的话,那么我们的方法中的参数就会很多,极有可能在使用时,将参数匹配搞混。这时候,如果用实体做参数,就会很方便,不用考虑参数匹配的问题,用到实体中哪个属性拿来直接用就可以,很方便。这样做也提高了效率。
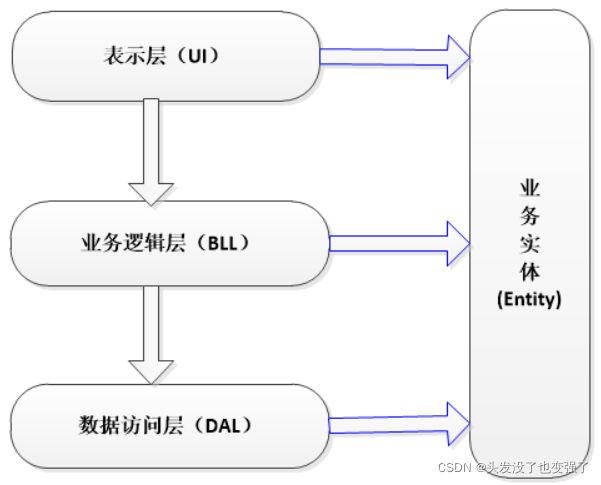
为什么使用三层?
使用三层架构的目的:解耦!!!
同样拿上面饭店的例子来讲:
(1)服务员(UI层)请假——另找服务员;厨师(BLL层)辞职——招聘另一个厨师;采购员(DAL)辞职——招聘另一个采购员; (2)顾客反映:
1、你们店服务态度不好——服务员的问题。开除服务员;
2、你们店菜里有虫子——厨师的问题。换厨师;
任何一层发生变化都不会影响到另外一层!!!
与两层的区别??
两层:(当任何一个地方发生变化时,都需要重新开发整个系统。"多层"放在一层,分工不明确耦合度高——难以适应需求变化,可维护性低、可扩展性低)
三层:(发生在哪一层的变化,只需更改该层,不需要更改整个系统。层次清晰,分工明确,每层之间耦合度低——提高了效率,适应需求变化,可维护性高,可扩展性高)
相较起来三层架构的优势
1,结构清晰、耦合度低
2,可维护性高,可扩展性高
3,利于开发任务同步进行, 容易适应需求变化
劣势
1、降低了系统的性能。这是不言而喻的。如果不采用分层式结构,很多业务可以直接造访数据库,以此获取相应的数据,如今却必须通过中间层来完成。
2、有时会导致级联的修改。这种修改尤其体现在自上而下的方向。如果在表示层中需要增加一个功能,为保证其设计符合分层式结构,可能需要在相应的业务逻辑层和数据访问层中都增加相应的代码
3、增加了代码量,增加了工作量
相比较总结:如果是个小项目或者后期不会再添加新的功能,代码量小的情况下建议还是使用二层架构,不要盲目使用三层架构,只会降低性能,增加工作量。
1.2.创建controller包
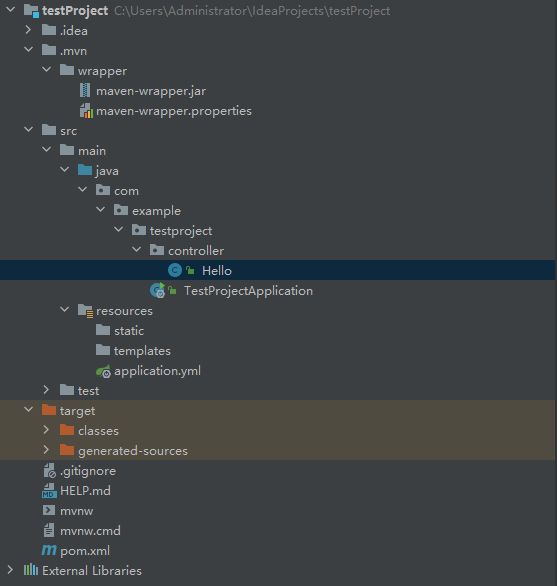
创建controller包
在controller报下创建Hello(测试类)
1.3.使用测试类,进行测试Springboot项目启动
package com.example.testproject.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class Hello {
@GetMapping
public String hello(){
return "hello";
}
}@RestController注解:@RestController=@ResponseBody+@Controller,Spring4之后新加入的注解,原来返回json需要@ResponseBody和@Controller配合,所以想要理解@RestController注解就要先了解@Controller和@ResponseBody注解。
@Controllre注解:在一个类上添加@Controller注解,表明了这个类是一个控制器类(启动类)。
@ResponseBody注解:表示方法的返回值直接以指定的格式写入Http response body中,而不是解析为跳转路径。格式的转换是通过HttpMessageConverter中的方法实现的,因为它是一个接口,因此由其实现类完成转换。如果要求方法返回的是json格式数据,而不是跳转页面,可以直接在类上标注@RestController,而不用在每个方法中标注@ResponseBody,简化了开发过程。
@GetMappint注解:
1.4.启动SpringBoot项目
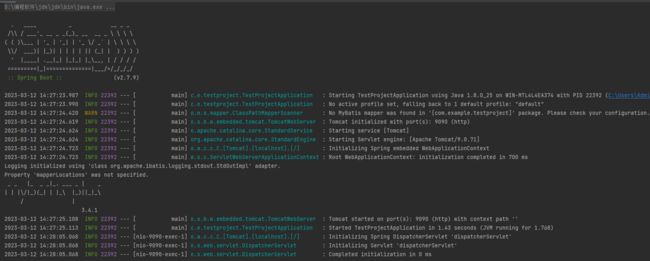
显示后端端口号为9090
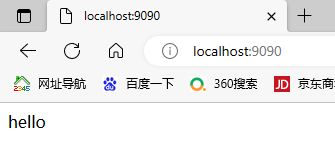
localhost:9090,得到返回hello,证明项目启动成功
(项目代码:1.SpringBoot项目初始启动)
3.使用Mysql创建数据库
1.1.使用Navicat Premium数据库视图化工具
Navicat是一套数据库管理工具,专为简化数据库的管理及降低系统管理成本而设。Navicat 是以直觉化的图形用户界面而建的,可以安全和简单地创建、组织、访问并共用信息。
Navicat Premium 是 Navicat 的产品成员之一,能简单并快速地在各种数据库系统间传输数据,或传输一份指定 SQL 格式及编码的纯文本文件。其他功能包括导入向导、导出向导、查询创建工具、报表创建工具、资料同步、备份、工作计划及更多。
1.2.连接Mysql
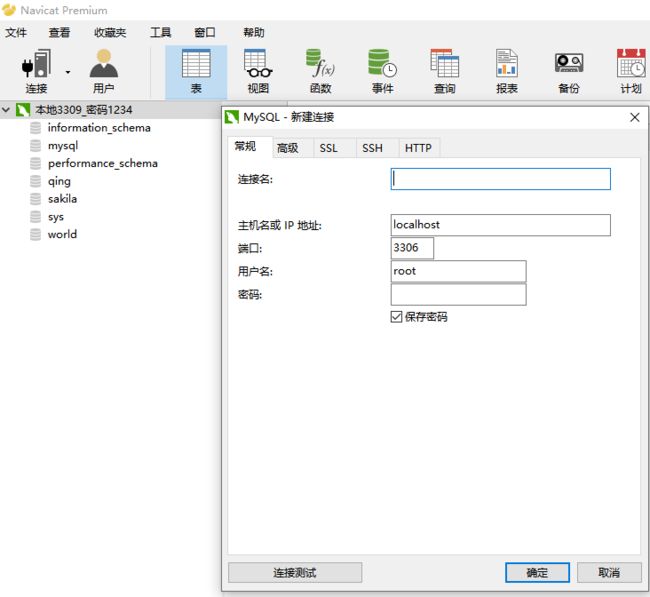
点击连接,选择mysql,连接名可以不写,默认帮你创建

连接成功
1.3.创建数据库

点击新建数据库
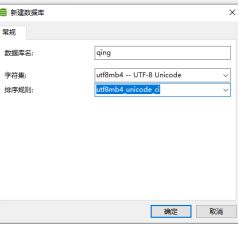
utf-8是我们国家简体中文,数据库等都是外国人发明的,因此我们要进行字符集的转换,不然不利于我们的使用,选择utf-8,是符合我们国家的使用!
新建成功
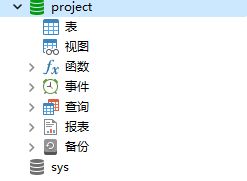
1.4.创建数据库表
点击project
右键选择命令列界面
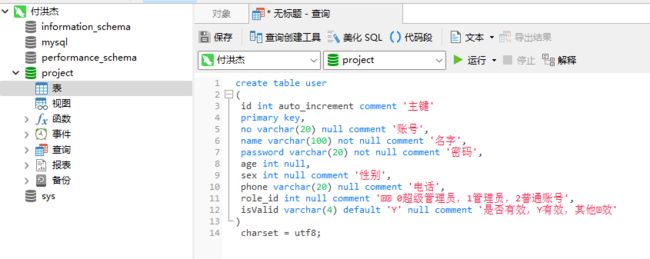
create table user
(
id int auto_increment comment '主键'
primary key,
no varchar(20) null comment '账号',
name varchar(100) not null comment '名字',
password varchar(20) not null comment '密码',
age int null,
sex int null comment '性别',
phone varchar(20) null comment '电话',
role_id int null comment '⻆⾊ 0超级管理员,1管理员,2普通账号',
isValid varchar(4) default 'Y' null comment '是否有效,Y有效,其他⽆效'
)
charset = utf8;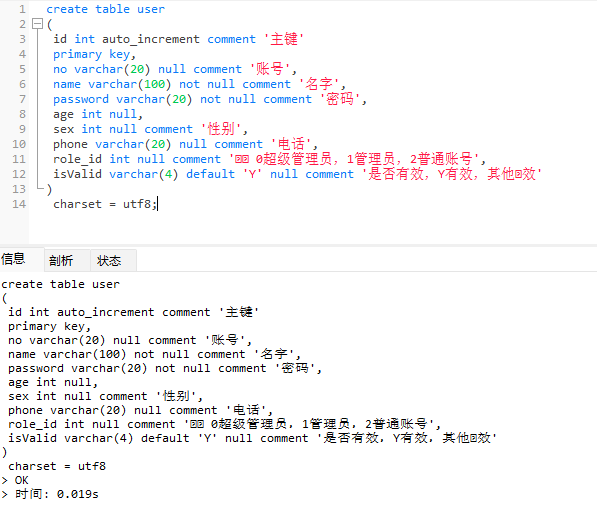

初始表是没有任何数据的
null:定义空的,意思是这个字段可以为空,简而言之,就是可以不插入这个字段的数据
notnull:不为空,意思就是这个字段必须插入数据,否则会报错
auto_increment:是用于主键自动增长的,从1开始增长,当你把第一条记录删除时,再插入第二条数据时,主键值是2,不是1。
primary:主键用于唯一标识表中的每一条数据,不能重复, 不能为空。
comment:注释
1.5.新增数据库数据
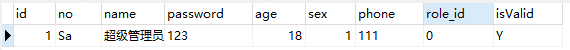
新增一条数据
id是可以不用设置的,因为本身写了自增的。
sex一般用1表示男,用0表示女。
isValid默认是Y
4.SpringBoot框架项目搭建
1.1.加入数据访问层,服务层,请求层,实体类
1、dao(mapper)层:数据访问层
dao层属于一种比较底层,比较基础的操作,具体到对于某个表的增删改查,也就是说某个DAO一定是和数据库的某一张表一 一对应的,其中封装了增删改查基本操作,建议DAO只做原子操作,增删改查。
负责与数据库进行联络的一些任务都封装在此,dao层的设计首先是设计dao层的接口,然后在Spring的配置文件中定义此接口的实现类,然后就可以再模块中调用此接口来进行数据业务的处理,而不用关心此接口的具体实现类是哪个类,显得结构非常清晰,dao层的数据源配置,以及有关数据库连接参数都在Spring配置文件中进行配置。
2、service层:服务层
粗略的理解就是对一个或多个DAO进行的再次封装,封装成一个服务,所以这里也就不会是一个原子操作了,需要事物控制。
service层主要负责业务模块的应用逻辑应用设计。同样是首先设计接口,再设计其实现类,接着再Spring的配置文件中配置其实现的关联。这样我们就可以在应用中调用service接口来进行业务处理。service层的业务实,具体要调用已经定义的dao层接口,封装service层业务逻辑有利于通用的业务逻辑的独立性和重复利用性。程序显得非常简洁。
3、controller层
Controler负责请求转发,接受页面过来的参数,传给Service处理,接到返回值,再传给页面。
controller层负责具体的业务模块流程的控制,在此层要调用service层的接口来控制业务流程,控制的配置也同样是在Spring的配置文件里进行,针对具体的业务流程,会有不同的控制器。我们具体的设计过程可以将流程进行抽象归纳,设计出可以重复利用的子单元流程模块。这样不仅使程序结构变得清晰,也大大减少了代码量。
4、entity实体类层
实体类就是一个拥有Set和Get方法的类。实体类通常总是和数据库之类的(所谓持久层数据)联系在一起。这种联系是借由框架(如Hibernate)来建立的。
其次说定义(比较生涩难懂):
实体类主要是作为数据管理和业务逻辑处理层面上存在的类别; 它们主要在分析阶段区分 实体类的主要职责是存储和管理系统内部的信息,它也可以有行为,甚至很复杂的行为,但这些行为必须与它所代表的实体对象密切相关。
这段话看起来不太好懂,应该结合实体类的作用来看:
实体类的作用(需要面向对象的一点很基本的知识):
实体类就是一个载体。
现在的设计差不多都是一张表就等于业务里面的一个类。一条记录(一般一行数据)是一个对象,一行中的一列就是这个对象的一个属性。
所以我们在操作某个表时(比如更改这个表的信息),我们就可以在前台定义一个这样的对象,然后将其对应的属性赋值,然后传到后台。
这样后台就可以拿到这个对象的所有值了——不用一个一个属性当参数传过来,只要传一个这个类的对象就好了,也就是说只要一个参数就好了。好处不言而喻。
而这种前台对象到后台数据库的联系,我们是借由框架、配置文件来配置实现的,很方便快捷。并不需要自己手动编程实现。
简而言之,(大多数情况下)实体类就是数据库在Java代码中对应的东东。
最后,摘抄一点JavaPeak大大使用实体类的经验:
一、实体类的名字尽量和数据库的表的名字对应相同。
二、实体类应该实现java.io.Serializable接口。
三、实体类应该有个无参的构造方法。
四、实体类应该有个有参(所有的参数)的构造方法。
五、实体类有属性和方法,属性对应数据库中表的字段,方法主要有getter和setter方法。
六、实体类还应该有个属性serialVersionUID。
例如:private static final long serialVersionUID = -6125297654796395674L;
七、属性一般是private类型,方法为public类型,对于数据库自动生成的ID字段对应的
属性的set方法为private。
关系
Service层是建立在DAO层之上的,建立了DAO层后才可以建立Service层,而Service层又是在Controller层之下的,因而Service层应该既调用DAO层的接口,又要提供接口给Controller层的类来进行调用,它刚好处于一个中间层的位置。每个模型都有一个Service接口,每个接口分别封装各自的业务处理方法。
1.2.创建实体类层
package com.example.testproject.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
import java.io.Serializable;
@Data
@EqualsAndHashCode(callSuper = false)
@ApiModel(value = "user对象",description = "")
public class User implements Serializable {
@ApiModelProperty(value = "主键")
@TableId(value = "id",type = IdType.AUTO)
private int id;
@ApiModelProperty(value = "账号")
@TableField(value = "no")
private String no;
@ApiModelProperty(value = "名字")
@TableField(value = "name")
private String name;
@ApiModelProperty(value = "密码")
@TableField(value = "password")
private String password;
@ApiModelProperty(value = "性别")
@TableField(value = "sex")
private int sex;
@ApiModelProperty(value = "电话")
@TableField(value = "phone")
private String phone;
@ApiModelProperty(value = "0超级管理员,1管理员,2普通账号")
@TableField(value = "role_id")
private int roleId;
@ApiModelProperty(value = "默认Y")
@TableField(value = "isValid")
private String isvalid;
}
在entity包下创建User实体类
(实现Serializable接口的作用是使一个类的对象可以被序列化,即可以将对象转换为字节流进行传输或存储。这样,在网络传输或持久化存储时,就可以方便地将对象进行传输或存储,而不需要手动进行对象的转换。同时,实现Serializable接口的类也可以被用于Java RMI(远程方法调用)等分布式系统中,使得远程调用更加方便。)
如果想想使用Swagger,需要在pom.xml加上依赖坐标。
io.springfox
springfox-swagger2
2.9.2
io.springfox
springfox-swagger-ui
2.9.2
Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。
总体目标是使客户端和文件系统作为服务器以同样的速度来更新。文件的方法、参数和模型紧密集成到服务器端的代码,允许API 来始终保持同步。Swagger 让部署管理和使用功能强大的 API 从未如此简单。
注解的作用:
@Data:我们在实际工作中经常会使用lombok来简化我们的开发,例如我们可以在定义的model类上添加@Data注解,从而免去手写get、set、toString、equals、hashcode等方法。
2.@EqualsAndHashCode(callSuper = true),就是用自己的属性和从父类继承的属性来生成hashcode;
@EqualsAndHashCode(callSuper = false),就是只用自己的属性来生成hashcode;
3.@ApiModel注解是用在接口相关的实体类上的注解,它主要是用来对使用该注解的接口相关的实体类添加额外的描述信息,并且常常和@ApiModelProperty注解配合使用。
4.而@ApiModelProperty注解则是作用在接口相关实体类的属性(字段)上的注解,用来对具体的接口相关实体类中的参数添加额外的描述信息,除了可以和 @ApiModel 注解关联使用,也会单独拿出来用。
所以可以理解为ApiModel和 ApiModelProperty两个注解的作用域不同,它们都是作用在接口相关的实体类上用来进行额外信息的描述,只是一个是作用在类上,一个作用在属性上。毕竟Property的中文意思就是属性。
Lombok知识点:
Lombok是一个Java库,能通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,提高了一定的开发效率。
Lombok使用
org.projectlombok
lombok
true
maven依赖引用
安装Lombok插件(IDEA)
File->Settings->plugins 搜索Lombok Install并重启IDEA
Lombok常用注解
@Getter/@Setter
作用类上,生成所有成员变量的getter/setter方法;作用于成员变量上,生成该成员变量的getter/setter方法。可以设定访问权限及是否懒加载等。
@ToString
作用于类,覆盖默认的toString()方法,可以通过of属性限定显示某些字段,通过exclude属性排除某些字段。
@EqualsAndHashCode
作用于类,覆盖默认的equals和hashCode
@NonNull
主要作用于成员变量和参数中,标识不能为空,否则抛出空指针异常。
@NoArgsConstructor, @RequiredArgsConstructor, @AllArgsConstructor
作用于类上,用于生成构造函数。有staticName、access等属性。
staticName属性一旦设定,将采用静态方法的方式生成实例,access属性可以限定访问权限。
@NoArgsConstructor
生成无参构造器;
@RequiredArgsConstructor
生成包含final和@NonNull注解的成员变量的构造器;
@AllArgsConstructor
生成全参构造器
@Data
作用于类上,是以下注解的集合:@ToString @EqualsAndHashCode @Getter @Setter @RequiredArgsConstructor
@Builder
作用于类上,将类转变为建造者模式
Lombok优缺点
能通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,提高了一定的开发效率
让代码变得简洁,不用过多的去关注相应的方法
属性做修改时,也简化了维护为这些属性所生成的getter/setter方法等
常用的几个注解:
@Data : 注在类上,提供类的get、set、equals、hashCode、canEqual、toString方法
@AllArgsConstructor : 注在类上,提供类的全参构造
@NoArgsConstructor : 注在类上,提供类的无参构造
@Setter : 注在属性上,提供 set 方法
@Getter : 注在属性上,提供 get 方法
@EqualsAndHashCode : 注在类上,提供对应的 equals 和 hashCode 方法
@Log4j/@Slf4j : 注在类上,提供对应的 Logger 对象,变量名为 log备注:
比如在我们数据库里role_id,在实体类里roleId
比如在我们实体类里isValid,读的时候会自动变成is_valid
1.3.创建数据访问层
package com.example.testproject.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.testproject.entity.User;
import org.mapstruct.Mapper;
@Mapper
public interface UserMapper extends BaseMapper {
} 在mapper包下创建UserMapper接口
@Mapper注解:写在每个Dao接口层的接口类上,@MapperScan注解写在SpringBoot的启动类上。
当我们的一个项目中存在多个Dao层接口的时候,此时我们需要对每个接口类都写上@Mapper注解,非常的麻烦,此时可以使用@MapperScan注解来解决这个问题。让这个接口进行一次性的注入,不需要在写@Mapper注解
@Mapper注解相当于是@Reponsitory注解和@MapperScan注解的和,会自动的进行配置加载。
@MapperScan注解多个包,@Mapper只能把当前接口类进行动态代理。
在实际开发中,如何使用@Mapper、@MapperSacn、@Repository注解
在SpringBoot的启动类上给定@MapperSacn注解。此时Dao层可以省略@Mapper注解,当让@Repository注解可写可不写,最好还是写上。
当使用@Mapper注解的时候,可以省略@MapperSacn以及@Repository。
建议:
以后在使用的时候,在启动类上给定@MapperScan("Dao层接口所在的包路径")。在Dao层上不写@Mapper注解,写上@Repository即可
备注:
为什么要继承BaseMapper,因为BaseMapper接口中自带插入,删除等方法,继承此接口,就可以直接使用接口中定义好的一些方法,方便。
BaseMapper
1.4.创建服务逻辑层
package com.example.testproject.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.testproject.entity.User;
public interface UserService extends IService {
} 在service包下创建UserService接口
为什么要继承IService接口,同BaseMapper接口类型
package com.example.testproject.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.testproject.entity.User;
import com.example.testproject.mapper.UserMapper;
import com.example.testproject.service.UserService;
import org.springframework.stereotype.Service;
@Service
public class UserServiceImpl extends ServiceImpl implements UserService {
} 在Service包下创建Impl包下创建UserServiceImpl类
为什么要创建Impl包
在Java开发中,通常将后台分成几层,常见的是三层mvc:model、view、controller,模型视图控制层三层,而impl通常处于controller层的service下,用来存放接口的实现类,impl的全称为implement,表示实现的意思。
impl用于实现接口

1.5.下载小鸟
点击settings

点击plugin
输入Mybatis,下载小鸟
作用:
MyBatis-Plus为我们提供了强大的mapper和service模板,能够大大提高开发效率,但是在真正开发过程中,mybatis-plus并不能解决所有问题,例如一些复杂的sql,多表联查,就需要我们自己去编写代码和sql语句,那么如何能够快速的解决这个问题呢?就是MyBatisX插件。
5.Mybatis-plus代码生成器
6.Mybatis-plus增删改查的实现
1.1.新增
package com.example.testproject.controller;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/user")
public class Hello {
@Autowired
private UserService userService;
//新增
@PostMapping("/save")
public boolean save(@RequestBody User user){
return userService.save(user);
}
}
1.2.修改
package com.example.testproject.controller;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/user")
public class Hello {
@Autowired
private UserService userService;
//修改
@PostMapping("/mod")
public boolean mod(@RequestBody User user){
return userService.updateById(user);
}
}
1.3.新增或者修改
package com.example.testproject.controller;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/user")
public class Hello {
@Autowired
private UserService userService;
//新增或修改
/*根据id来进行处理,如果我们传入这个user对象里面有id,
* 他就去更新,如果每有id,他就会去新增。*/
@PostMapping("/saveOrMod")
public boolean mod(@RequestBody User user){
return userService.saveOrUpdate(user);
}
}
1.4.删除
package com.example.testproject.controller;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/user")
public class Hello {
@Autowired
private UserService userService;
//删除
@GetMapping("/saveOrMod")
public boolean delete(@RequestBody Integer id){
return userService.removeById(id);
}
}
1.5.查询
package com.example.testproject.controller;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/user")
public class Hello {
@Autowired
private UserService userService;
@GetMapping
public List list(@RequestBody User user){
return userService.list();
}
}
1.6.模糊查询
package com.example.testproject.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("user")
public class Hello {
@Autowired
private UserService userService;
//查询(模糊.查询)
/*比如我需要带入用户某个名字,或者账号进来,使用Like进行模糊查询,就如同数据库中
* 的like,也可以使用eq完全等于条件一样*/
@PostMapping("/saveOrMod")
public List listp(@RequestBody User user){
LambdaQueryWrapper lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.like(User::getName,user.getName());
return userService.list(lambdaQueryWrapper);
}
}
1.7.增删改查全部代码
package com.example.testproject.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("user")
public class Hello {
@Autowired
private UserService userService;
//查询
@GetMapping("/list")
public List list(){
return userService.list();
}
//新增
@PostMapping("/save")
public boolean save(@RequestBody User user){
return userService.save(user);
}
//修改
@PostMapping("/mod")
public boolean mod(@RequestBody User user){
return userService.updateById(user);
}
//新增或修改
/*根据id来进行处理,如果我们传入这个user对象里面有id,
* 他就去更新,如果每有id,他就会去新增。*/
@PostMapping("/saveOrMod")
public boolean saveOrMod(@RequestBody User user){
return userService.saveOrUpdate(user);
}
//删除
@GetMapping("/delete")
public boolean delete(@RequestBody Integer id){
return userService.removeById(id);
}
//查询(模糊.查询)
/*比如我需要带入用户某个名字,或者账号进来,使用Like进行模糊查询,就如同数据库中
* 的like,也可以使用eq完全等于条件一样*/
@PostMapping("/saveOrMod")
public List listp(@RequestBody User user){
LambdaQueryWrapper lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.like(User::getName,user.getName());
return userService.list(lambdaQueryWrapper);
}
}
1.8.备注
@ResponseBody放在不同地方的作用
@ResponseBody的作用其实是将java对象转为json格式的数据。
@responseBody注解的作用是将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML数据。
注意:在使用此注解之后不会再走视图处理器,而是直接将数据写入到输入流中,效果等同于通过response对象输出指定格式的数据。
1.@ResponseBody作用在方法上的,@ResponseBody 表示该方法的返回结果直接写入 HTTP response body 中,一般在异步获取数据时使用【也就是AJAX】。
2.@ResponseBody作用在方法形参上 。
@RequestBody 作用在形参列表上,用于将前台发送过来固定格式的数据(xml、json)封装为对应的 JavaBean 对象,封装时使用到的一个对象是系统默认配置的 HttpMessageConverter进行解析,然后封装到形参上 。
补充:
1. @ResponseBody 也可以直接作用在类上的 ,最典型的例子就是 @RestController 这个注解,它就包含了 @ResponseBody 这个注解(@RestController=@ResponseBody+@Controller)
2. 在类上用@RestController,其内的所有方法都会默认加上@ResponseBody,也就是默认返回JSON格式。如果某些方法不是返回JSON的,就只能用@Controller了吧,这也是它们俩的区别。
请求方法的区别
(1)@GetMapping: 是一个组合注解,通常用来处理get请求,常用于执行查询操作。
(2)@PostMapping:是一个组合注解, 通常用来处理post请求,常用于执行添加操作。
(3)@PutMapping:是一个组合注解,通常用来处理put请求,常用于执行更新操作。
(4)@DeleteMapping:是一个组合注解。通常用来处理delete请求,常用于执行删除操作。
(5) @RequestMapping注解类型用于映射一个请求或一个方法,其注解形式为@RequestMapping,可以使用该注解标注在一个方法或一个类上。
LambdaQueryWrapper作用
lambdaquerywrapper是一个Java库,用于构建Lambda表达式查询条件。它可以帮助开发人员更方便地构建复杂的查询条件,同时提高代码的可读性和可维护性。该库支持多种数据库,包括MySQL、Oracle、SQL Server等。
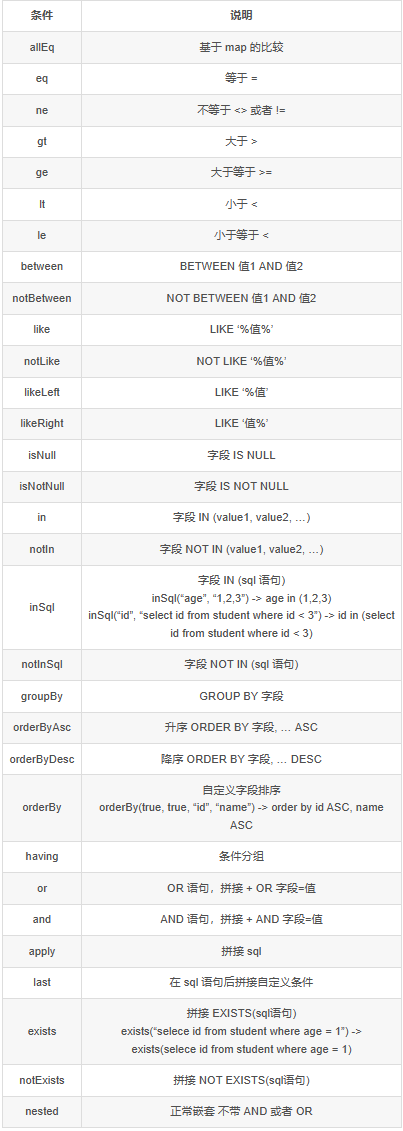
lambdaQueryWrapper.like(User::getName,user.getName());作用
User::getName是一个循环的写法,意思就是循环出所有的姓名
User.getName():是通过get方法获取当前对象的姓名
总体:就是获取到当前对象的姓名(比如:张三),然后在循环出所有的姓名中去找,看是否有匹配的
7.Mybatis-plus分页处理
pageSize:每页多少条记录
pageNum:当前页
1.1.入参的封装
package com.example.testproject.common;
import lombok.Data;
import java.util.HashMap;
@Data
public class QueryPageParam {
//默认值
private static int PAGE_SIZE=20;
private static int PAGE_NUM=1;
//真正传到后端参数,如果前端没有传值,走默认值
private int pageSize=PAGE_SIZE;
private int pageNum=PAGE_NUM;
private HashMap param;
}
在common包下创建QueryPageParam类
common包一般作为公共类和一些通用方法
1.2.分页查询的实现
package com.example.testproject.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.example.testproject.common.QueryPageParam;
import com.example.testproject.entity.User;
import com.example.testproject.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.HashMap;
import java.util.List;
@RestController
@RequestMapping("user")
public class Hello {
@Autowired
private UserService userService;
//分页查询
@PostMapping("listPage")
public List listPage(@RequestBody QueryPageParam query){
HashMap param = query.getParam();
String name = (String)param.get("name");
System.out.println(query);
System.out.println("num==="+query.getPageNum());
System.out.println("num==="+query.getPageSize());
//current:当前页 size:每页多少条
Page page = new Page(query.getPageNum(), query.getPageSize());
//也可以如下写法
// Page page = new Page<>();
// page.setCurrent(1);
// page.setSize(10);
LambdaQueryWrapper lambdaQueryWrapper = new LambdaQueryWrapper();
lambdaQueryWrapper.like(User::getName,name);
IPage result = userService.page(page, lambdaQueryWrapper);
//打印总记录数
System.out.println("total=="+result.getTotal());
return result.getRecords();
}
}
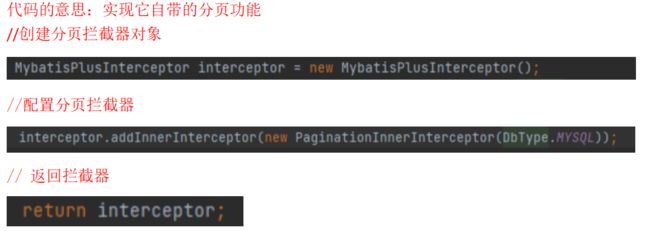
1.3.添加分页拦截器
package com.example.testproject.common;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}在common包下创建MybatisPlusConfig类
分页拦截器的作用:作用就是我们可以拦截某些方法的调用,我们可以选择在这些被拦截的方法执行前后加上某些逻辑,也可以在执行这些被拦截的方法时执行自己的逻辑而不再执行被拦截的方法。Mybatis拦截器设计的一个初衷就是为了供用户在某些时候可以实现自己的逻辑而不必去动Mybatis固有的逻辑。打个比方,对于Executor,Mybatis中有几种实现:BatchExecutor、ReuseExecutor、SimpleExecutor和CachingExecutor。这个时候如果你觉得这几种实现对于Executor接口的query方法都不能满足你的要求,那怎么办呢?是要去改源码吗?当然不。我们可以建立一个Mybatis拦截器用于拦截Executor接口的query方法,在拦截之后实现自己的query方法逻辑,之后可以选择是否继续执行原来的query方法。
1.4.备注
HashMap集合:
HashMap是基于Map接口的实现,在存储键值对时使用HashMap。
特点:
1.使用HashMap定义的Map集合,是无序存放的(顺序无用);
2.元素(key)不能重复,如果发现了重复的key,会进行覆盖,使用新的内容替换旧的内容;
3.使用HashMap子类保存数据时,key或value可以保存为null。
4.HashMap是异步的,线程不安全。
8.后端返回数据的封装
1.1.让前端收到统一的数据方便处理
{
Code:200//400, 状态码
Msg:"成功,失败",
Total:10, 总条数
Data:[]{}, 有可能是数组,有可能是对象
}1.2.数据封装类
package com.example.testproject.common;
import lombok.Data;
@Data
public class Result {
private int code; //状态码 200成功 400失败
private String msg;//成功或者失败
private Long total;//总记录数
private Object data;//数据(有可能是集合[],有可能是对象,所以定义的是Object类型)
//失败
public static Result fail(){
return result(400,"失败",0L,null);
}
//成功(无参数)
public static Result suc(){
return result(200,"成功",0L,null);
}
//成功(有参数(有data数据))
public static Result suc(Object data){
return result(200,"成功",0L,data);
}
//成功(有参数(有data数据,有total数据))
public static Result suc(Object data,Long total){
return result(200,"成功",0L,data);
}
private static Result result(int code,String msg,Long total,Object data){
Result res = new Result();
res.setData(data);
res.setMsg(msg);
res.setCode(code);
res.setTotal(total);
return res;
}
}
在common包下创建Result类
9.创建vue项目
1.1.vue简介
1 概述
Vue.js 可以说是MVVM架构的最佳实践,是一个JavaScript MVVM库,是一套构建用户界面的渐进式框架。专注于 MVVM 中的 ViewModel,不仅做到了数据双向绑定,而且也是一款相对比较轻量级的JS 库,API 简洁。
Vue用于构建用户界面的渐进式框架,渐进式代表的含义是:主张最少。每个框架都不可避免会有自己的一些特点,从而会对使用者有一定的要求,这些要求就是主张,主张有强有弱,它的强势程度会影响在业务开发中的使用方式。
双向数据绑定:vue.js会自动响应数据的变化情况,并且根据用户在代码中预先写好的绑定关系,对所有绑定在一起的数据和视图内容都进行修改。这也是vue.js最大的优点,通过MVVM思想实现数据的双向绑定,让开发者不用再操作dom对象,有更多的时间去思考业务逻辑。
组件化:Vue.js通过组件,把一个单页应用中的各种模块拆分到一个一个单独的组件(component)中,我们只要先在父级应用中写好各种组件标签(占坑),并且在组件标签中写好要传入组件的参数(就像给函数传入参数一样,这个参数叫做组件的属性),然后再分别写好各种组件的实现(填坑),然后整个应用就算做完了。
视图、数据和结构的分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作
虚拟DOM:用JQuery或者原生的JavaScript DOM操作函数对DOM进行频繁操作的时候,浏览器要不停的渲染新的DOM树,导致页面看起来非常卡顿,而Virtual DOM则是虚拟DOM的英文,简单来说,他就是一种可以预先通过JavaScript进行各种计算,把最终的DOM操作计算出来并优化,由于这个DOM操作属于预处理操作,并没有真实的操作DOM,所以叫做虚拟DOM。最后在计算完毕才真正将DOM操作提交,将DOM操作变化反映到DOM树上。
2 Vue热加载
因为vue的双向数据绑定特性以及技术的成形,实现了项目的热加载,改完页面代码能立即在浏览器方面显示效果,提高开发效率。
3 Vue的双向数据绑定的原理
Vue.js 是采用 Object.defineProperty 的 getter 和 setter,并结合观察者模式来实现数据绑定的。当把一个普通 Javascript 对象传给 Vue 实例来作为它的 data 选项时,Vue 将遍历它的属性,用Object.defineProperty 将它们转为 getter/setter。用户看不到 getter/setter,但是在内部它们让 Vue 追踪依赖,在属性被访问和修改时通知变化。
Observer数据监听器:能够对数据对象的所有属性进行监听,如有变动可拿到最新值并通知订阅者,内部采用Object.defineProperty的getter和setter来实现。
Compile指令解析器:它的作用对每个元素节点的指令进行扫描和解析,根据指令模板替换数据,以及绑定相应的更新函数。
Watcher订阅者: 作为连接 Observer 和 Compile 的桥梁,能够订阅并收到每个属性变动的通知,执行指令绑定的相应回调函数。
Dep消息订阅器:内部维护了一个数组,用来收集订阅者(Watcher),数据变动触发notify 函数,再调用订阅者的 update 方法。
1.2.vue创建流程
1.1创建文件
以管理员身份打开命令行界面,进入任意一个想要创建项目的文件夹
(ctrl+shift+enter)
输入:vue create vue01

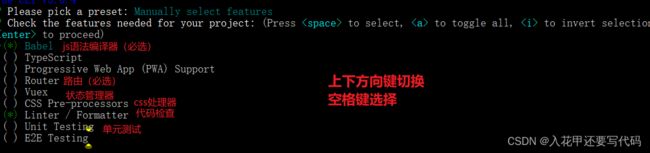
1.2选择配置信息
通过上下方向键选择对应配置,然后回车,选择自定义配置

按空格键选择要安装的配置资源,带 * 号说明被选上了
1.3选择版本
上下方向键选择版本,这里我们选择vue2,然后回车

1.4路径模式选择
这里可以不用管,直接输入 no/n

1.5语法代码格式检查
代码检查,选标准的就行,方向键切换,空格键选择然后回车
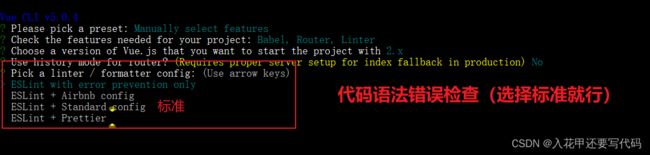
代码检查时间,方向键切换,空格键选择然后回车

1.6第三方文件存在的方式
1.独立的文件 2.综合的

1.7是否保存本次配置信息(保存预设)
这里如果选择保存的话,就要输入名字,默认就是文件夹的名字,下次配置的时候就会显示这个文件配置的选项就像上面的一样,在配置的时候会多出来一个

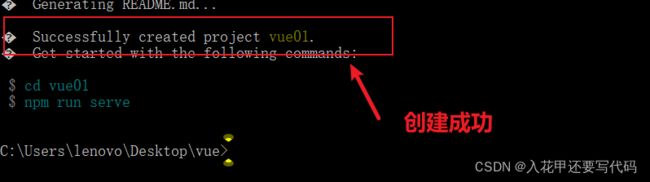
1.8创建成功
Successfully created project vue01出现这个说明创建成功
1.9运行
cd到项目文件夹下面
cd vue01

输入代码运行文件
npm run serve
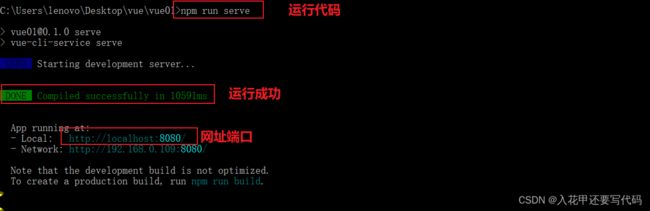
1.10启动
在浏览器输入对应的网址就可以看到界面啦
http://localhost:8080/
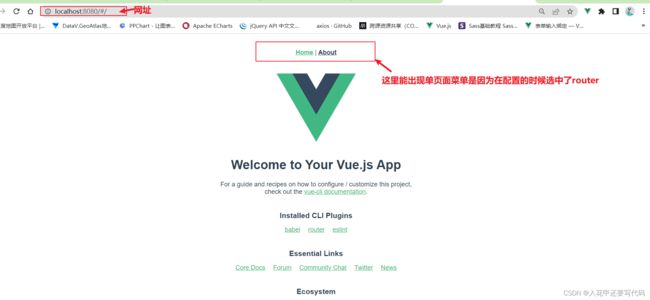
1.11停止服务
两下Ctrl+C 或者Ctrl+C一下然后Y

2、用vue资源管理器创建
2.1进入vue资源管理器界面(vue ui界面)
cmd命令,因为是全局的,所以在哪里打开都行,注意:运行的时候不能关闭cmd窗口,不然就停止服务了,如果电脑太卡,可以直接在浏览器输入:http://localhost:8000/
vue ui

2.2创建文件
这里直接create 创建文件
2.3配置信息
和用cmd命令差不多,填完之后下一步
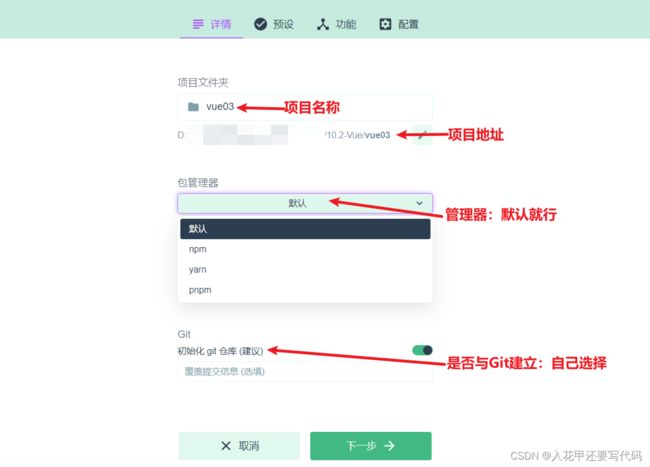
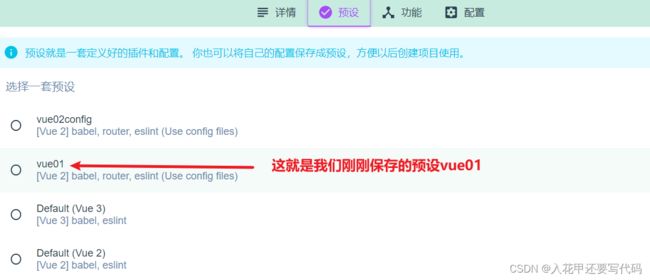
2.4配置预设
选择预设,或者自定义,然后下一步完成创建
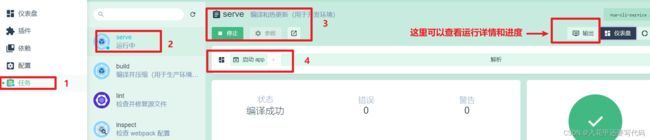
2.5启动运行项目
按步骤来:任务>serve>运行>启动

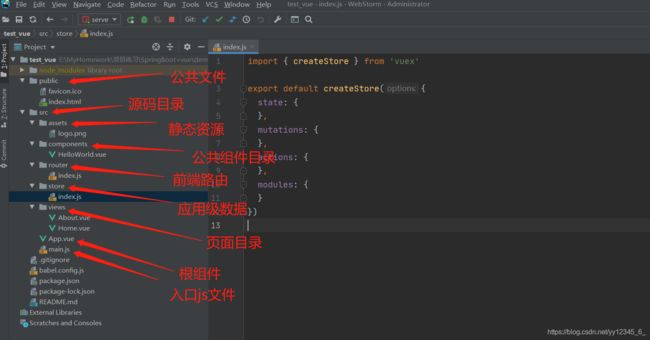
四、Vue-cli工程中每个文件夹和文件的用处
dist 文件夹:默认 npm run build 命令打包生成的静态资源文件,用于生产部署
node_modules:存放npm命令下载的开发环境和生产环境的依赖包
public:有的叫assets:存放项目中需要用到的资源文件,css、js、images以及index
src文件夹:存放项目源码及需要引用的资源文件
src-api文件夹:放ajax相关操作的代码文件:index.js(相关的接口),ajax.js(封装的axios,拦截器)。有的叫service:自己配置的vue请求后台接口方法
src-common文件夹:stylus的混合文件.styl,不要写到public也可以
src-components文件夹:存放vue开发中抽离的一些公共组件
src-mock文件夹:mock数据存放文件及mock模拟接口(没有后台接口或接口不完整情况下可以模拟后台接口)
src-pages文件夹:涉及到路由的组件
src-router文件夹:vue-router,路由器及路由的配置
src-store文件夹:存放 vue中的状态数据,用vuex集中管理
App.vue文件:使用标签渲染整个工程的.vue组件
main.js文件:vue-cli工程的入口文件
package.json文件:用于 node_modules资源部 和 启动、打包项目的 npm 命令管理
build 文件夹:用于存放 webpack 相关配置和脚本。开发中仅 偶尔使用 到此文件夹下 webpack.base.conf.js 用于配置 less、sass等css预编译库,或者配置一下 UI 库
config 文件夹:主要存放配置文件,用于区分开发环境、线上环境的不同,常用到此文件夹下 config.js 配置开发环境的 端口号、是否开启热加载 或者 设置生产环境的静态资源相对路径、是否开启gzip压缩、npm run build 命令打包生成静态资源的名称和路径等

2.5用编程软件启动vue项目
(1)可以使用的编辑器有:
webstorm:?https://www.jetbrains.com/zh-cn/webstorm/
vscode:https://vscode.en.softonic.com/
Hbuilder:https://www.dcloud.io/
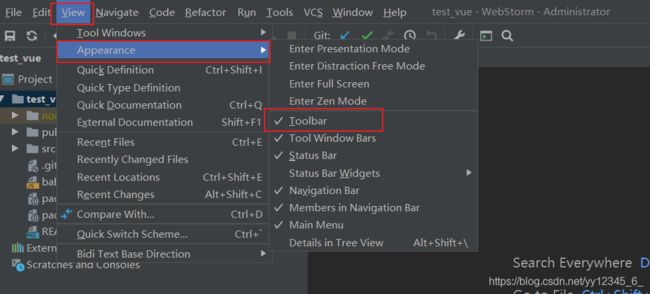
(2)使用webstorm编辑器演示:
修改启动按钮位置:
添加启动器npm:
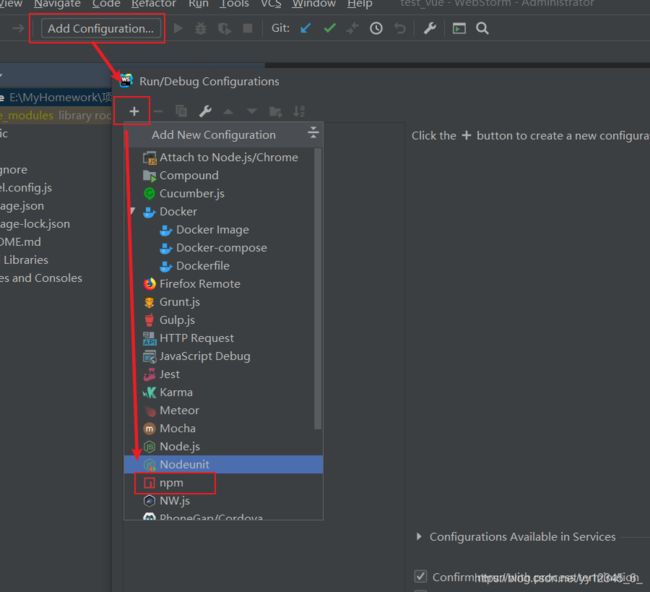
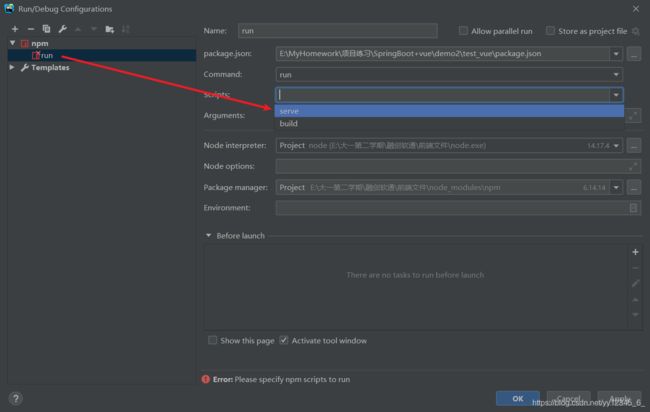
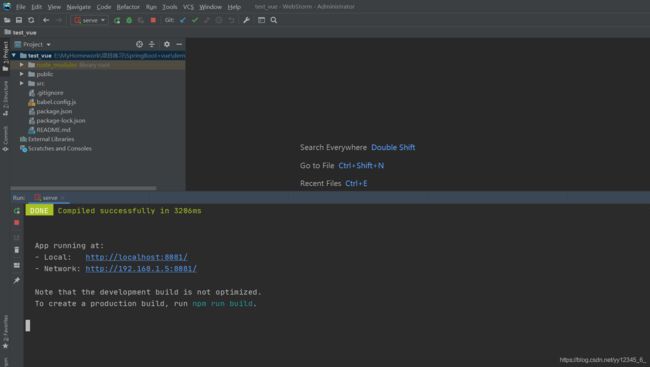
4)项目启动成功
10.前端Vue项目导入到Idea并允许
1.创建新的文件夹(重构前后端项目)
2.将前端和后端项目,放在新的文件夹里
3.用idea进行打开
11.加入element-ui支持
补充:Vue脚⼿架(注意版本冲突) npm install -g @vue/cli
1.1.Element-ui简介
element官网
https://element.eleme.cn/#/zh-CN/component/installation
element介绍
Element:网站快速成型工具。是饿了么公司前端开发团队提供的一套基于 Vue 的网站组件库。
使用 Element 前提必须要有 Vue。
组件:组成网页的部件,例如 超链接、按钮、图片、表格等等~
1.2.安装Element-ui
npm 安装
推荐使用 npm 的方式安装,它能更好地和 webpack 打包工具配合使用。
npm i element-ui -S
cmd中
node_modules文件夹中
package.json中
1.3.main.js全局引入

import Vue from 'vue'
import App from './App.vue'
import ElementUI from 'element-ui';
import 'element-ui/lib/theme-chalk/index.css';
Vue.config.productionTip = false
Vue.use(ElementUI);
new Vue({
render: h => h(App),
}).$mount('#app')
main.js
12.页面布局搭建
1.1.布局容器
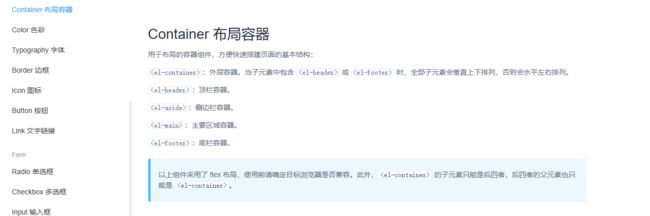
1.2.全局css
*{
margin: 0;
padding: 0;
}在src包下assets包下的global.css
import Vue from 'vue'
import App from './App.vue'
import ElementUI from 'element-ui';
import 'element-ui/lib/theme-chalk/index.css';
import './assets/global.css' //导入全局css(重点)
Vue.config.productionTip = false
Vue.use(ElementUI);
new Vue({
render: h => h(App),
}).$mount('#app')
在main.js中导入全局css
在App.vue中
1.3.设置高度百分之百

初始页面展示效果
在App.vue页面
//(重点)设置高度为百分之百
导航一
分组一
选项1
选项2
选项3
选项4
选项4-1
导航二
分组一
选项1
选项2
选项3
选项4
选项4-1
导航三
分组一
选项1
选项2
选项3
选项4
选项4-1
查看
新增
删除
王小虎
在Index.vue页面
13.页面布局的拆分
1.1.页面组成部分
aside(左边菜单),header(头部菜单),main(主页面)
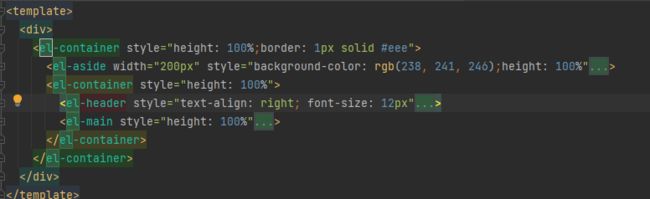
如果页面都在一起,会导致页面的臃肿
1.2.页面的分开
在Index.vue
1.3.页面的整合
导航一
分组一
选项1
选项2
选项3
选项4
选项4-1
导航二
分组一
选项1
选项2
选项3
选项4
选项4-1
导航三
分组一
选项1
选项2
选项3
选项4
选项4-1
在components包下的Aside.vue中
//(重点),有两个节点,vue是不可以的
查看
新增
删除
王小虎
在components包下的Header.vue中
在components包下的Main.vue中
13.编写头部页面
1.1.初始样子
1.2.修改图标
王小虎
个人中心
退出
在components包下的Header.vue中
1.3.菜单伸缩功能
header做一个图标,点击的时候aside进行伸缩
在components包下的Header.vue中
13.菜单导航页面编写
1.1.多层和单层的区别
多层有多层的好处,单层有单层的好处,单层比较明确,有什么就点什么,根据不同的功能分在子菜单。
1.2.修改颜色背景和激活当前菜单
首页
导航1
导航2
在components包下的Aside.vue中
在components包下的Index.vue中

展示效果
15.导航菜单的伸缩
1.1.伸缩的思路

展开
收起
收起和展开是有变量的,可以根据collapse来进行控制
1.2.callapse

1.3.思路
header点击图标以后---提交数据---父组件进行改变---aside子组件(collapse)
enity包下的user类
16.Mysql数据库查询接口
mapper简介:
mapper层(数据持久化层,专门用来跟数据库打交道的)。
mapper层用于和数据库交互,想要访问数据库并且操作,只能通过mapper层向数据库发送sql语句,将这些结果通过接口传给service层,对数据库进行数据持久化操作,他的方法语句是直接针对数据库操作的,
主要实现一些增删改查操作,在mybatis中方法主要与与xxx.xml内相互一一映射。
@Mapper
@Repository
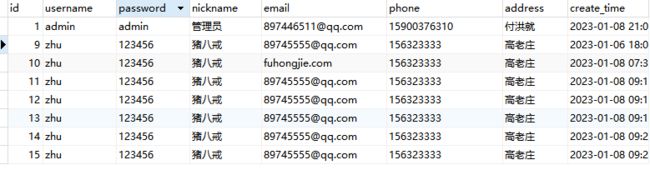
public interface UserMapper extends BaseMapper {//数据库查询接口,专门用来跟数据库交互用的
@Select("SELECT * from sys_user")
public List findAll();
List findAll1();
@Insert("INSERT into sys_user(username,password,nickname,email,phone,address)VALUES(#{username},#{password},#{nickname}," +
"#{email},#{phone},#{address});")
public int insert(User user);
public int updateUser(User user);
@Delete("delete from sys_user where id = #{id}")
public Integer deleteById(@Param("id") Integer id); 例子
对应数据库
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class HuienApplication {
public static void main(String[] args) {
SpringApplication.run(HuienApplication.class, args);
}
}
SpringBootApplication.java(主启动类)
@SpringBootApplication: Spring Boot应用标注在某个类上说明这个类是SpringBoot的主配置类,SpringBoot就应该运行这个类的main方法来启动SpringBoot应用。
package com.example.enity;
import lombok.*;
import java.io.Serializable;
@Data
public class User implements Serializable {
private Integer id;
private String username;
private String password;
private String nickname;
private String email;
private String phone;
private String address;
}
User(实体类)
@Data:作用于类上,是以下注解的集合:@ToString @EqualsAndHashCode @Getter @Setter
package com.example.mapper;
import com.example.enity.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface UserMapper {
@Select("select * from sys_user")
List findAll();
}
UserMapper(数据持久层接口)
@Mapper注解的的作用
1:为了把mapper这个DAO交給Spring管理
2:为了不再写mapper映射文件
3:为了给mapper接口 自动根据一个添加@Mapper注解的接口生成一个实现类
package com.example.controller;
import com.example.enity.User;
import com.example.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class UserController {
@Autowired
private UserMapper mapperUser;
@GetMapping("/")
public List index(){
return mapperUser.findAll();
}
}
UserController(用来接受前台数据和返回页面请求信息的类)
@RestController:
一、在Spring中@RestController的作用等同于@Controller + @ResponseBody。
所以想要理解@RestController注解就要先了解@Controller和@ResponseBody注解。
二、@Controller注解
在一个类上添加@Controller注解,表明了这个类是一个控制器类。这里省略对Controller注解的说明了。
三、@ResponseBody注解
@ResponseBody表示方法的返回值直接以指定的格式写入Http response body中,而不是解析为跳转路径。
格式的转换是通过HttpMessageConverter中的方法实现的,因为它是一个接口,因此由其实现类完成转换。
如果要求方法返回的是json格式数据,而不是跳转页面,可以直接在类上标注@RestController,而不用在每个方法中标注@ResponseBody,简化了开发过程。
@Autowired:Spring对组件自动装配的一种方式,常用于在一个组件中引入其他组件。
@GetMapping("/"):
Spring的复杂性不是来自于它处理的对象,而是来自于自身,不断演进发展的Spring会带来时间维度上复杂性,比如SpringMVC以前版本的*@RequestMapping*,到了新版本被下面新注释替代,相当于增加的选项:
@GetMapping
@PostMapping
@PutMapping
@DeleteMapping
@PatchMapping
从命名约定我们可以看到每个注释都是为了处理各自的传入请求方法类型,即*@GetMapping用于处理请求方法的GET类型,@ PostMapping用于处理请求方法的POST*类型等。
如果我们想使用传统的*@RequestMapping*注释实现URL处理程序,那么它应该是这样的:
@RequestMapping(value = “/get/{id}”, method = RequestMethod.GET)
新方法可以简化为:
@GetMapping("/get/{id}")
17.SpringBoot实现增删改查和分页查询
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class HuienApplication {
public static void main(String[] args) {
SpringApplication.run(HuienApplication.class, args);
}
}
SpringBootApplication.java(主启动类)
package com.example.enity;
import lombok.*;
import java.io.Serializable;
@Data
public class User implements Serializable {
private Integer id;
private String username;
private String password;
private String nickname;
private String email;
private String phone;
private String address;
}
User(实体类)
package com.example.mapper;
import com.example.enity.User;
import org.apache.ibatis.annotations.*;
import java.util.List;
@Mapper
public interface UserMapper {
//新增
@Insert("INSERT into sys_user(username,password,nickname,email,phone,address) values (#{username},#{password},+" +
"#{nickname},#{email},#{phone},#{address})")
Integer insert(User user);
//删除
@Delete("delete from sys_user where id =#{id}}")
Integer deleteById(@Param("id") Integer id);
//修改
@Update("update sys_user set username = #{username},password = #{password}},nickname = #{nickname} where id = #{id}")
List update(User user);
//查询
@Select("select * from sys_user")
List findAll();
//分页查询
@Select("SELECT * FROM sys_user where username like concat('%',#{username},'%') LIMIT #{pageNum},#{pageSize}")
List selectPage(Integer pageNum, Integer pageSize,String username);
//分页查询出user的总条数
@Select("select count(*) from sys_user where username like concat('%',#{username},'%')")
Integer selectTotal(String username);
}
UserMapper(数据持久层接口)
package com.example.controller;
import com.example.enity.User;
import com.example.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper usermapper;
//新增
@PostMapping
public Integer save(@RequestBody User user){
return usermapper.insert(user);
}
//删除
@DeleteMapping("/{id}")
public Integer delete(@PathVariable Integer id){
//根据id区删除,假删除的话就是改一个数据库的字段,把它改成0
return usermapper.deleteById(id);
}
//修改
public List update(User user){
return usermapper.update(user);
}
//查询
@GetMapping//查询所有
public List find(){
return usermapper.findAll();
}
//分页查询
@GetMapping("/page")//查询所有
public Map findpage(@RequestParam Integer pageNum,
@RequestParam Integer pageSize,
@RequestParam String username){
pageNum = (pageNum - 1) * pageSize;
List data = userMapper.selectPage(pageNum, pageSize,username);
//他返回的是List,我么总条数应该是个数字对吧,
Integer total = userMapper.selectTotal(username);
Map res = new HashMap<>();
res.put("data",data);
res.put("total",total);
return res;
}
}
UserController(用来接受前台数据和返回页面请求信息的类)
@RequestMapping:这个注解是统一给接口,加前缀。
18.Mybatis插件
点击settings
点击plugin
输入Mybatis,下载小鸟
19.SpringBoot完整配置文件
server:
port: 9090
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3309/qing?serverTimezone=UTC&characterEncoding=utf-8
username: root
password: 1234
mybatis:
mapper-locations: classpath:mapper/*.xml #扫描所有的mybatis.xml文件
# configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
20.SpringBoot集成Vue产生的问题(终结)
*为什么表格头要加上!Important
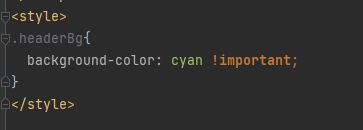
解答:CSS 中的 !important 规则用于增加样式的权重。!important 与优先级无关,但它与最终的结果直接相关,使用一个 !important 规则时,此声明将覆盖任何其他声明。
例如:
#myid {
background-color: blue;
}
.myclass {
background-color: gray;
}
p {
background-color: red !important;
}
以上实例中,尽管ID 选择器和类选择器具有更高的优先级,但三个段落背景颜色都显示为红色,因为 !important 规则会覆盖 background-color 属性。
使用!important 是一个坏习惯,应该尽量避免,因为这破坏了样式表中的固有的级联规则,使得调试找bug 变得更加困难了。
*为什么要用el-table-column标签
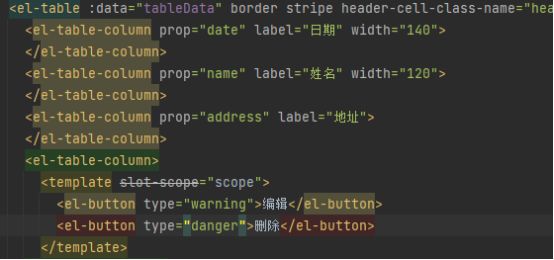
解答:
实现表格的多级表头功能,数据结构比较复杂的时候,可使用多级表头来展现数据的层次关系。只需要在 el-table-column 里面嵌套 el-table-column,就可以实现多级表头。如:
"80"/>
*创建SpringBoot项目,为什么要用8这个版本
解答:一般有两个原因
根据IDEA版本不同来确定的,有的版本支持的是jdk8以及以上的版本,有的支持更好的版本,因此这个是不固定的,可以看到这个是可以选择的(通过8旁边的下拉列表)
这个版本是可以选择的,如果默认选择的是8,是因为你安装的环境变量就是8
*mybatis和JPA有什么区别
解答:主要从这3个方面比较
1. jpa和mybatis的反映对象不同
GPA是java persistence api的缩写,它的中文翻译就是指程序JAVA持久层API,Mybatis相对来说比较实用的持久层框架。首先,两者最大的不同就在于内部的反应对象,JPA的操作是在对象与对象之间的反射,而mybatis的处理对象是在对象和结果集合之间的反射。虽然其最终的持久层框架结果是一样的,但是却在操作过程中有千差万别。
2. jpa和mybatis的功能性质不同
从整体的移植性来看,GPA的一致性相对较好,他在数据库的兼容性基本都是相同的,所以不用担心其他问题。一般来说springdatajpa都知道当一个接口继承了GPA,接口之后便会自动具备数据移植的良好性质。由于mybatis是使用SQL语句,所以在移植时必须将数据库的类型改为sql了。从这一点上来看,GPA更具优势,其次在操作层面修改字段的时候,mybatis也相对操作步骤比较多。
3. jpa和mybatis操作流程不同
如果是学习操作持久层的话,用hibernate会比较麻烦,所以从具体学习操作来看,mybatis具有更强烈的优势,同时也可以使用springdatajpa,但是这一种方式更适合于单表。但在这里可以发现这一篇a的妥协性,为了支持这一特性,但在实际操作起来,并不推荐荐使用,因为这种操作方式并不符合领域驱动设计的目标和理念。
*为什么要把这些删除掉
解答:这些是不需要删掉的,只是个人习惯的问题,可以不用删除的!!!
*字符集和排序规则为什么要这样选
解答:因为utf-8是我们国家简体中文,数据库等都是外国人发明的,因此我们要进行字符集的转换,不然不利于我们的使用,选择utf-8,是符合我们国家的使用!