关于HashMap扩容机制
HashMap的底层有数组 + 链表(红黑树)组成,数组的大小可以在构造方法时设置,默认大小为16,数组中每一个元素就是一个链表,jdk7之前链表中的元素采用头插法插入元素,jdk8之后采用尾插法插入元素,由于插入的元素越来越多,查找效率就变低了,所以满足某种条件时,链表会转换成红黑树。随着元素的增加,HashMap的数组会频繁扩容,如果构造时不赋予加载因子默认值,那么负载因子默认值为0.75,数组扩容的情况如下:
1:当添加某个元素后,数组的总的添加元素数大于了 数组长度 * 0.75(默认,也可自己设定),数组长度扩容为两倍。(如开始创建HashMap集合后,数组长度为16,临界值为16 * 0.75 = 12,当加入元素后元素个数超过12,数组长度扩容为32,临界值变为24)
2:在没有红黑树的条件下,添加元素后数组中某个链表的长度超过了8,数组会扩容为两倍.(如开始创建HashMAp集合后,假设添加的元素都在一个链表中,当链表中元素为8时,再在链表中添加一个元素,此时若数组中不存在红黑树,则数组会扩容为两倍变成32,假设此时链表元素排列不变,再在该链表中添加一个元素,数组长度再扩容两倍,变为64,假设此时链表元素排列还是不变,则此时链表中存在10个元素,这是HashMap链表元素数存在的最大值,此时,再加入元素,满足了链表树化的两个条件(1:数组长度达到64, 2:该链表长度达到了8),该链表会转换为红黑树
HashMap创建的底层原理
1:首先创建HashMap集合时,在不手动赋值的情况下会先设置默认负载因子0.75
![]()
2.向集合值添加元素会调用putVal()方法,前三个参数分别为hash(key),key,value,即hash值,键值对。
![]()

3.hash(key)方法计算hash值
计算方法是键的hashCode()方法与高位16进行异或运算得到hash值
4.进入putVal方法,首先看上半部分
首先判断数组中是否已经创建,此时还创建数组,所以此时调用
resize()方法设置初始容量
若未在构造方法时设置初始容量,则初始容量设置为16.(注意容量只能为2的倍数,即使输入的不是2的倍数也会自动转换)
将元素存储在i = (n - 1) & hash的下标链表中,因为此时为加入元素所以table[i]一定是null,元素一定会存入到数组中。

5.接着会跳过之后的判断语句
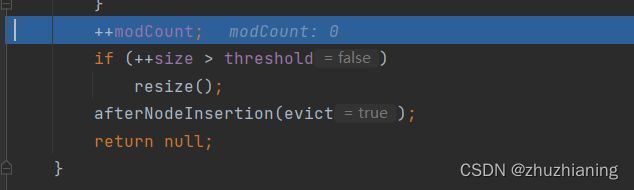
size代表了此时集合中已经加入的元素个数,当其值大于了临界值
threshold(此时为12)时,会调用resize()方法进行二倍扩容
6.添加完第一个元素后继续添加下一个元素,因为重写了hashCode()方法,让两个元素的hash值相同,所以它们会存储在同一个链表中,进入putVal()方法后,上面的第一个if语句为false,因为已经初始化了数组,第二个if也是false,因为当前链表下的头元素已经存在,它会进入if语句的分支else语句
![]()

7.第一个if语句判断链表中头元素与当前插入的元素是否是同一个元素(hash()方法与equals()方法比较)

这里重写了hash()方法所以hash值相同但两种内容不同所以进入else分支,判断当前数组中的结点是链表还是红黑树,如果是红黑树,就按红黑树的添加方式添加。
 此时我们还未形成红黑树,所以不会执行,进入else语句。
此时我们还未形成红黑树,所以不会执行,进入else语句。

8.接下来进入一个死循环,死循环结束有两种方式
1.第一种结束方式:链表中没有找到与当前添加元素相同的元素(euqals()方法比较),就会用尾插法在链表末尾插入这个添加的元素,然后会进行if判断,判断添加元素前当前链表中元素是否达到了8,如果达到了,进入
treeifyBin(tab, hash)语句,在该语句中,我们只关注前半部分,在数组容量小于64时,数组会调用
resize()方法扩容为2倍


2.第二种结束方式
还是在for循环中,如果找到了与添加元素相同的元素(euqals()方法比较),直接跳出循环。然后进入if语句,覆盖掉链表中元素的“值”(value),


9.之后更新集合中元素的个数,判断是否超过了临界值,超过了就会扩容为2倍
