算法刷题总结 (五) 字符串操作
算法总结5 字符串方法
- 一、理解Python中的字符串
-
- 1.1、字符串的特性
- 1.2、字符串的操作
-
- 1.2.1、字符串的截取与加长
- 1.2.2、字符串的数字与字母的操作
- 1.2.3、字符串的字母分割添加
- 1.2.4、字符串的对齐填充
- 1.2.5、字符串的左右剔除
- 1.2.6、ASCII值最大/最小的字符
- 1.2.7、整数与字符的转化
- 1.2.8、字符串的替换
- 1.2.9、字符串中字符的寻找(报错和不报错)
- 1.2.10、字符串按指定字符/字符串切分
- 1.2.11、统计字符/字符串出现次数
- 1.2.12、字符串起始/结尾首字符的检查
- 二、经典题型
-
- 2.1、344. 反转字符串
- 2.2、541. 反转字符串 II
- 2.3、剑指 Offer 05. 替换空格
- 2.4、151.翻转字符串里的单词
- 2.5、剑指Offer58-II.左旋转字符串
- 2.6、28. 实现 strStr()
- 2.7、459. 重复的子字符串
- 三、参考
一、理解Python中的字符串
字符串是 Python 中最常用的数据类型使用频率非常高,并且它非常灵活有非常多的操作,且拥有非常强大的内置库函数。
字符串经常作为考题出现,或者为其他主题考题的某一部分,所以熟练的掌握字符串的相关操作对自己编程解决问题的能力的提升至关重要。
1.1、字符串的特性
(1)、字符串是字符的有序可重复集合
字符串中的字符是有序的,所以可以像list和tuple一样通过索引查找相应位置的元素;它的元素也可以重复,所以它不像set不仅无序,而且元素不可重复。
(2)、字符串不可修改,或者“修改”会开辟新的内存空间。
字符串为不可变类型(字符串、数字和元组为不可变类型;列表、字典和集合为可变类型),所以不可以直接在字符串上进行修改操作,否则会报错。
所以我们只能生成新的字符串变量来保存结果,这算是变相“修改”字符串。但这样做是生成新的变量,去开辟一块新的内存空间而产生新的内存地址,不是对原变量进行操作,而有些题目会要求进行原址操作,那么在新的变量上的任何操作都对原变量没任何影响,结果会出现问题。
但字符串不会进行任何更改,所以原址操作修改是不可能的,这里不用考虑,但是对于list需要其修改是否为原址。
1.2、字符串的操作
1.2.1、字符串的截取与加长
截取:string [ start : end : step ]
字符串索引从左往右从0,1开始,step为1;从右往左从-1,-2开始,step要设置为-1.
类似于range的使用。
注意[:]生成相同值的string,当赋予新的变量时,内存地址还是相同的。
加长:
1.拼接:string1 + string2
直接将两个字符串加起来,结果为新的地址。
无减法操作。
2.重复:string1 * n
将sting1重复n次,n必须为整数,为小数则报错,为0和负数则为’'空字符串。
结果同样为新的地址。
3.百分比输出: ’ …%s’%string
m='abc'
'123%s'%m
4.format输出:‘{}’.format()
m = 'you'
'123{love}'.format(love=m)
1.2.2、字符串的数字与字母的操作
1.判断整个字符串是否为数字:
string.isnumeric() / isdigit(),返回值为True或者False
'12a'.isnumeric()
False
区别: 前者支持所有形式的数字,后者不支持类似汉字数字
'一'.isnumeric()
True
'一'.isdigit()
False
2.字母大小写互换:
string.swapcase()
'a123B'.swapcase()
'A12b'
3.字符串全转大/小写
string.upper() / string.lower(),将字符串中的每个字符转换成大写 / 转换成小写
'abC'.upper()
'ABC'
'abC'.lower()
'abc'
4.是否全是大写或小写
string.isupper()/islower()
5.是否全是字母和数字
string.isalnum()
6.是否全是空白字符
S.isspace()
7.是否是首字母大写的
S.istitle()
8.首字母大写
S.capitalize()
1.2.3、字符串的字母分割添加
splitSym.join(string)
将splitSym添加到string的每个字母之间
'|'.join('abcde')
a|b|c|d|e
1.2.4、字符串的对齐填充
1. 中间对齐,两边对称填充:
string.center(width, fillchar),fillchar默认为空格必须为str类型,width为填充后整个字符串的长度。
当不对称时,比如string为两个字符,width为奇数5,则左边的填充比右侧的多1.
'ab'.center(5, '0')
00ab0
2.左边对齐,右侧填充:
string.ljust(width[ ,fillchar])
'ab'.ljust(5)
'ab '
3.右边对齐,左侧填充:
rjust(width[ ,fillchar])
'ab'.rjust(5)
' ab'
1.2.5、字符串的左右剔除
1. 两边剔除:
string.strip(ch) ,截掉字符串两边的字符/字符串,可指定。当ch为空时,默认剔除空格字符(包括’\n’, ‘\r’, ‘\t’, ’ ')
'a b c d '.strip('a')
' b c d '
2. 左侧剔除:
string.lstrip(ch)
' a b c d '.lstrip()
'a b c d '
3. 右侧剔除:
string.rstrip(ch)
' a b c d '.rstrip('d ')
' a b c '
1.2.6、ASCII值最大/最小的字符
max(string)/min(string)
1.2.7、整数与字符的转化
chr(num)/ord(char) 将一个整数转化成一个字符 / 将一个字符转化成一个整数
整数同样为ASCII数值
A-Z 65-90
a-z 97-122
1.2.8、字符串的替换
string.replace( oldStr, newStr [,times] ),将string字符串中的原有字符/字符串串old替换成new字符/字符串,从而形成新的string字符串序列,默认new替换所有old,除非指定times替换次数。
'aaa'.replace('a', 'b', 2)
'bba'
1.2.9、字符串中字符的寻找(报错和不报错)
不报错的寻找 (提倡使用):
1.左侧开始寻找:
s.find(str,beg=0,length=len) ,返回第一个找到的结果。beg指定从左开始的起始点,可为负数,默认为0;length指定寻找的长度,默认为整个长度,注意从0开始而不是从beg开始。
找不到指定的str时,返回-1
'111222111'.find('1', 3)
6
2.右侧开始寻找:
s.rfind(str,beg=0,length=len),注意这里的beg也是从左侧开始,而不是右侧。
'111222111'.rfind('1', -3,7)
6
3.找不到返回-1
'1'.find('2')
-1
报错的寻找 (不提倡使用):
s.index(str,beg=0,length=len) / rindex(str,beg=0,length=len)
同上,但找不到则报错。
'1'.index('2')
ValueError: substring not found
1.2.10、字符串按指定字符/字符串切分
string.split(splitChar [,times] ),以splitChar(字符或者字符串)为分隔符,将string拆分成不同组字符串,各个字符串整体形成一个列表。
'112211221'.split('1', 3)
['', '', '22', '1221']
1.2.11、统计字符/字符串出现次数
str.count(sub, start= 0,end=len(string)),统计出现次数,可指定起始位置,默认为0,;可指定结尾位置,默认为整个字符串长度。
'112211'.count('11')
2
1.2.12、字符串起始/结尾首字符的检查
1. 以某字符开头:
str.startswith(str, beg=0,end=len(string)),用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
'12345'.startswith('2',1)
True
2. 以某字符结尾:
str.endswith(suffix[, start[, end]])

二、经典题型
2.1、344. 反转字符串
leetcode链接
1.库函数(不推荐):
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
s.reverse()
2.创建新变量反向替换
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# 创建一个反向新变量
for n, i in enumerate(s[::-1]):
s[n]=i
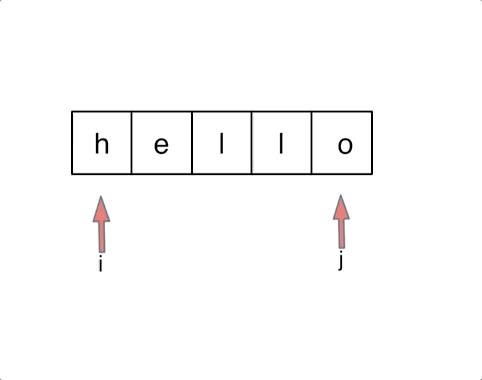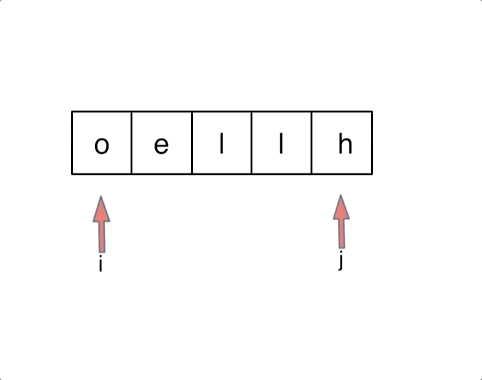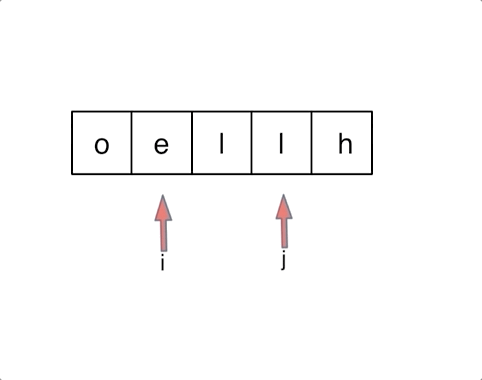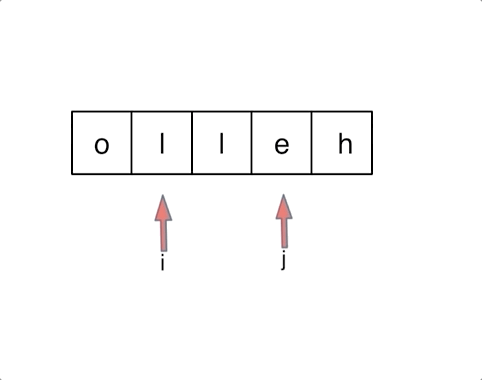
3.双指针原址交换
首尾向中间交换遍历
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
for i in range(len(s)//2):
s[i], s[len(s)-i-1] = s[len(s)-i-1],s[i]
另一种双指针标准写法
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
left, right = 0, len(s) - 1
# 该方法已经不需要判断奇偶数,经测试后时间空间复杂度比用 for i in range(right//2)更低
# 推荐该写法,更加通俗易懂
while left < right:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
2.2、541. 反转字符串 II
leetcode链接
过程模拟题,找到规律,设定起始点,每次2*k跳跃
class Solution:
def reverseStr(self, s: str, k: int) -> str:
#s = list(s)
#if len(s)
# s.reverse()
# return ''.join(s)
#elif len(s)<2*k:
# s = list(reversed(s[:k]))+s[k:]
# return ''.join(s)
#else:
# 前面这些部分可以去掉,被包含在了下面
# 对于[start:end]超过len(s)会被会略而不会报错
start = 0
while start<len(s):
end = start+k
s = s[:start]+s[start:end][::-1]+s[end:]
start+= 2*k
return s
# return ''.join(s)
2.3、剑指 Offer 05. 替换空格
leetcode链接
1.使用函数(不推荐):
class Solution:
def replaceSpace(self, s: str) -> str:
s = s.replace(' ', '%20')
return s
2.遍历过程:
从后往前遍历,不然长度变化,未处理过的空格的索引的位置会改变。
比如:
" "
会输出
"%20%20 "
而不是
"%20%20%20%20%20"
因为第一次len(s)的长度为3,从前往后替换时,替换第一个,遍历到%20
class Solution:
def replaceSpace(self, s: str) -> str:
for i in range(len(s)-1,-1,-1):
if s[i]==' ':
s = s[:i] + '%20'+ s[i+1:]
return s
2.4、151.翻转字符串里的单词
leetcode链接
1.使用函数:
class Solution:
def reverseWords(self, s: str) -> str:
tmp = s.split(' ')
tmp.reverse()
while ''in tmp:
tmp.remove('')
return ' '.join(tmp)
2.双指针:
class Solution:
def reverseWords(self, s: str) -> str:
left, right = 0, 0
res = []
while right < len(s):
if s[left] == ' ':
left+=1
elif right==len(s)-1 or s[right+1] == ' ':
# s = s[:left]+s[left:right+1][::-1]+s[right+1:]
res.insert(0, s[left:right+1])
left = right+1
right+=1
# print((left,right))
return ' '.join(res)
2.5、剑指Offer58-II.左旋转字符串
leetcode链接
1.拆分拼接:
class Solution:
def reverseLeftWords(self, s: str, n: int) -> str:
return s[n:]+s[:n]
2.6、28. 实现 strStr()
leetcode链接
1.使用函数:
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
return haystack.find(needle)
2. KMP算法
这里可以使用更为具体的KMP算法,理解比较复杂,后续再学习补充。
2.7、459. 重复的子字符串
leetcode链接
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
for i in range(len(s)):
# 重复则至少两个以上
if s[:i+1] + s[:i+1] in s:
# 该子串的n次能拼成s,成功
if s[:i+1]*(len(s)//len(s[:i+1])) == s:
return True
return False
三、参考
KMP算法(百度百科)
字符串(blog)