87、Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation
简介
主页:https://ku-cvlab.github.io/3DFuse/
分数蒸馏是一种使用预先训练的文本到2d扩散模型来优化零镜头设置下神经辐射场(NeRF)的方法
二维扩散模型中缺乏三维感知,使得基于分数蒸馏的方法无法重建一个可信的3D场景
例如:文本提示“一只可爱的猫”具有颜色模糊性,因为它可以指黑猫或白猫。这种模糊性导致在这个范围内生成任何图像的自由,这损害了生成的NeRF的质量和一致性

3DFuse 将3D感知整合到预训练的2D扩散模型中,增强了基于分数蒸馏的方法的鲁棒性和3D一致性
实现流程

在该框架中,对语义代码进行采样,通过基于文本提示生成图像,然后优化提示的嵌入以匹配生成的图像来减少文本提示的模糊性。一致性注入模块接收这个语义代码来合成特定于视图的深度图,作为扩散U-net的一个条件。该模块还包括一个稀疏深度注入器,通过利用外部3D先验隐式融合3D感知,以及LoRA层来保持语义一致性。
Semantic code sampling
一种简单而有效的技术来对抗这种文本提示歧义,成为语义代码采样(semantic code sampling)来指定优化的场景的语义标识,从而减少歧义
首先,从文本提示 c 生成一个2D图像 x ^ \hat{x} x^。然后,优化文本提示嵌入 e 以更好地适应生成的图像,类似于文本反转

x ^ t \hat{x}_t x^t 为生成图像 x 的噪点图像,在时间步 t 和 噪声 ϵ \epsilon ϵ
生成的图像 x 和优化后的嵌入函数 e ∗ e^* e∗ 的组合称为语义代码 s : = ( x ^ , e ∗ ) s:=(\hat{x},e^*) s:=(x^,e∗)
Incorporating a coarse 3D prior
构建了给定初始图像的粗略3D表示,并将其投射到目标视点以制作稀疏深度图,将3D感知整合到预训练的2D扩散模型。
以一个现成的模型 D(·) 接收图像作为输入,输出一个粗略的3D表示(稀疏3D点云)
可以从多种模型中选择D(·):它可以是点云生成模型,如 Point-E,也可以是单幅图像重建模型,如 MCC
将它们作为3D先验,构建稀疏点云并对其进行投影,得到相机位姿 π 对应的稀疏深度图 P
![]()
P(·) 为深度投影函数,如 ControlNet
稀疏深度注入器 E ϕ E_\phi Eϕ 接收稀疏深度图 P,将其输出特征添加到 θ ( x ^ t , e ∗ ) θ(\hat{x}_t, e^∗) θ(x^t,e∗) 的扩散 U -net 中的中间特征,表示为: ϵ θ ( x ^ t , e ∗ , E ϕ ( P ) ) \epsilon_\theta(\hat{x}_t,e^*,E_\phi(P)) ϵθ(x^t,e∗,Eϕ(P))
3DFuse在语义代码及其特定于视图的深度图上显式地调整3D优化,这不仅增强了NeRF的3D一致性和保真度,而且还鼓励3D场景忠实于语义代码,确保生成的3D场景的几何和语义鲁棒性
Training the sparse depth injector

3D模型得到的点云不可避免地包含误差和伪影,需要处理稀疏几何和投影深度图的误差
采用两种训练策略训练稀疏深度注入器 E ϕ E_\phi Eϕ
- 使用稀疏深度图来训练注入器,通过将点云从点云数据集投影到已知视点来获得,通过用稀疏深度图-图像对训练模块,模型学会了从稀疏深度中插值和推断密集结构信息。通过对点云数据进行随机子采样,并添加随机生成的噪声点,对点云数据进行增强,增加了模型对预测的稀疏深度图中存在的错误和噪声的鲁棒性,使用图像标题模型获得对应图像的文本
- E ϕ E_\phi Eϕ 使用 MiDaS 获得文本到图像对的预测密集深度图上进行训练,加强了模型的泛化能力,使其能够从未包含在3D点云数据集中的类别中推断结构信息,用于稀疏深度训练
给定深度图 P 以及对应的图像 y 和标题 c,深度注入器 E ϕ E_\phi Eϕ 的训练目标为
![]()
只是调整深度注入器 E ϕ E_\phi Eϕ ,而扩散模型保持冻结状态。能够直接接收稀疏和噪声深度图作为输入,并成功地从中推断出密集和鲁棒的结构信息,而不需要任何辅助深度补全网络
Pivotal tuning for semantic consistency
扩散模型应该根据语义代码,从不同的相机姿势生成尽可能多的相同物体
优化嵌入 e ∗ e^* e∗ 保留了语义,但通过采用[激励的LoRA技术进一步增强了这一点。
LoRA层 ψ 由线性层组成,插入扩散 U-net 中注意层的残差路径
在测试时,给定一个由文本提示符 c 生成的图像 x,修正优化的嵌入 e ∗ e^∗ e∗ 并调优 LoRA层 ψ
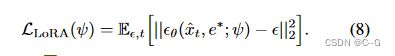
只训练 LoRA 层,而不是整个扩散模型,以避免过度拟合到特定的视点
实验


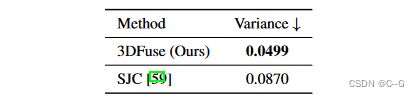
Conclusion
解决了文本到3d生成中的3d不连贯问题,3DFuse,它有效地将3D感知整合到预训练的2D扩散模型中。
利用了来自粗略3D结构的特定于视图的深度图,并辅以稀疏深度注入器和语义代码采样以实现语义一致性。
为解决当前文本到3D生成技术的局限性提供了一种实用的解决方案,并为从文本提示生成更逼真的3D场景提供了可能性。