目录
- 爱因斯坦与Physical Review的公案
- 数据处理初步
- 迈向真正的科研:动力学建模
本文用到的包
import sys
from collections import defaultdict
import numpy as np
import pylab as plt
import matplotlib.cm as cm
import statsmodels.api as sm
from os import listdir
import json
爱因斯坦与Physical Review的公案
APS是美国物理学会的简称,这个历史悠久的组织旗下有一系列著名的期刊,许多颠覆人类世界观的理论与猜想都是在这些期刊上发表的。其中最著名之一的是EPR猜想,由Einstein, Boris Podolsky 和Rosen 于1935年发表。当时爱因斯坦已经来到普林斯顿,所以开始在北美的物理学杂志上发表文章。
关于爱因斯坦与Physical Review(以下简称PR),还有一个著名的公案。
爱因斯坦与助手Rosen在1936年6月1日给PR提交了文章Do Gravitational Waves Exist?,并在这篇文章中主张引力波不存在。期刊主编John T. Tate将这篇发送给匿名评审,7月23日Tate将评审的批评意见发送回给爱因斯坦。爱因斯坦勃然大怒,写了科学史上最著名的Respondence to the editors,说自己寄稿件就是要直接发表的,从未同意让其他人来审自己的稿件。为表达愤怒,爱因斯坦将稿件转寄给Journal of the Franklin Institute,后者原封不动地发表了这个稿件。

以上这个故事许多人都知道。但并非人人都知道的是,Tate给爱因斯坦的回复里坚持表示,PR不能发表没有经过评审的文章。同时爱因斯坦寄给Journal of the Franklin Institute的稿件,其实经过了修改,而修订的部分,正与那位“匿名评审”所指出的意见相关。
这位匿名评审,通过查阅PR的日志可以知道,是物理学家Howard Percy Robertson。这位Robertson于1936年夏天访问了普林斯顿,与接替的Rosen位置的Leopold Infeld曾经一起工作,他再次指出了爱因斯坦与Rosen合作的文章的问题,这些意见,经由Infeld,传递给了爱因斯坦。那么,爱因斯坦是否知道Robertson就是那位令他生气的匿名评审,以及他修改文章是否因为Robertson的意见呢?这些都难以考证,但我们今天确实知道的是,Robertson给出的意见,的确是对的。事实证明,即便是对于爱因斯坦这样的人物,同行评议也是有意义的。更多细节,可以阅读Physics Today的这篇文章。

数据处理初步
令人高兴的是,APS公开了历年的文献数据,从数据里我们不仅可以了解一个个像爱因斯坦这样的小故事,还可以管窥整个物理学发展史,以此来研究人类合作生产知识的规律。我们在这里简单展示处理该数据的Python代码,以激发大家来共同挖掘和使用这个数据,回答自己关心的问题。
本数据的下载地址和数据说明在这里。如简介所言,只要给[email protected]发邮件,解释数据用途,就可以获得两个数据。一个是metadata,其中每个文章是一个json文件,记录了每篇文章的DOI,作者,发表年份,页数等信息。另一个数据是citations,是一个CSV文件,记录了所有的AB(A引用B)关系。我获得的数据库一共有将近53万文章和54万条引用记录。
我们先获得每篇文章引用别人和被引用的次数
#citation count
C=defaultdict(lambda:[0,0]) #paper doi : (cite n papers, been cited by n papers)
citationCounter=0
with open('/Users/csid/Documents/bigdata/aps/aps-dataset-citations-2013/aps-dataset-citations-2013.csv','r') as f:
for line in f:
citationCounter+=1
if citationCounter%10000==0:
flushPrint(citationCounter/10000)
x,y=line.strip().split(',')#x cited y
C[x][0]+=1
C[y][1]+=1
然后将其整合进文章的信息里
P=defaultdict(lambda:[])
paperCounter=0
path='/Users/csid/Documents/bigdata/aps/aps-dataset-metadata-2013/'
for journal in listdir(path):
if journal=='.DS_Store':
continue
ad2=path+journal+'/'
J=defaultdict(lambda:[])
for folder in listdir(ad2): # all subfolders
if folder=='.DS_Store':
continue
ad1=ad2+folder+'/'
flushPrint(journal+'_'+folder)
for paper in listdir(ad1): # all json files in subfolders
if paper=='.DS_Store':
continue
ad0=ad1+paper
try:
with open(ad0,'rb') as e:
paperCounter+=1
j=json.loads(e.read())
nAuthor=len(j['authors'])
date=str(j['date'])
year=int(date[:4])
length=int(j['numPages'])
doi=str(j['id'])
ncite,ncited = C[doi]
J[doi]=[year,nAuthor,length,ncite,ncited]
except:
pass
P[journal]=J
这样,我们就可以做一些简单的统计了。例如年份与发表数目
Y={}
for j in P:
J = defaultdict(lambda:0)
for x,y in P[j].items():
year,nAuthor,length,ncite,ncited = y
J[year]+=1
Y[j]=J
使用下列代码可以绘制图3
journals = sorted([(sorted(Y[j].keys())[0],j) for j in Y])
fig = plt.figure(figsize=(12, 5),facecolor='white')
cmap = cm.get_cmap('Accent_r', len(journals))
for n, val in enumerate(journals):
firstyear,name=val
year,stat = np.array(sorted(Y[name].items())).T
plt.plot(year,stat,marker='',linestyle='-',color=cmap(n),label=name+'_'+str(firstyear))
plt.legend(loc=2,fontsize=10)
plt.xlabel('Year')
plt.ylabel('N of papers')
#
plt.tight_layout()
plt.show()
我们发现,几乎所有的杂志发表文章数量都在逐年上升。

定义如下函数来考察其他变量(因为RMP专门发表文献综述,统计量与其他发表一手研究的杂志很不同,所以暂时不分析)。
def yearlystat(variable):
v = ['year','nAuthor','length','ncite','ncited']
n = v.index(variable)
Y={}
for j in P:
M = {}
J = defaultdict(lambda:[])
for x,y in P[j].items():
if y[n]>0:
J[y[0]].append(y[n])
for year in J:
M[year]=(np.mean(J[year]),np.std(J[year]))
Y[j]=M
return Y
D = yearlystat('ncite')
E = yearlystat('nAuthor')
F = yearlystat('length')
G = yearlystat('ncite')
H = yearlystat('ncited')
def plotV(dic,ylab):
fig = plt.figure(figsize=(12, 5),facecolor='white')
cmap = cm.get_cmap('Accent_r', len(journals))
for n, val in enumerate(journals):
name,firstyear=val
if name == 'RMP':
continue
d = dic[name]
year,mean,std = np.array(sorted([(year, d[year][0], d[year][1]) for year in d])).T
plt.plot(year,mean,marker='',linestyle='-',color=cmap(n),label=name+'_'+str(firstyear))
plt.fill_between(year, mean-std/2.0,mean+std/2.0,color=cmap(n),alpha=0.05)
lg=plt.legend(loc=2,fontsize=10)
lg.draw_frame(False)
plt.xlabel('Year')
plt.ylabel(ylab)
plt.ylim(0,30)
#
plt.tight_layout()
plt.show()
例如
plotV(D,'Average citations')
其中有一些时候横轴与纵轴的取值范围需要微调使数据趋势更清晰。这里不再给出代码。得到如下结果:
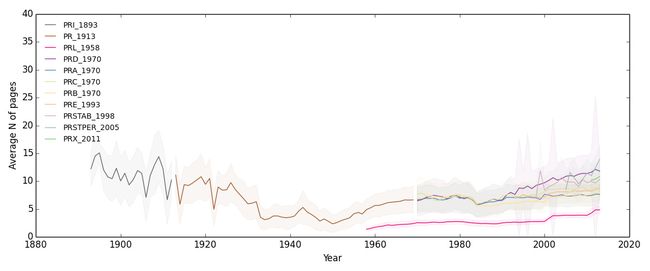
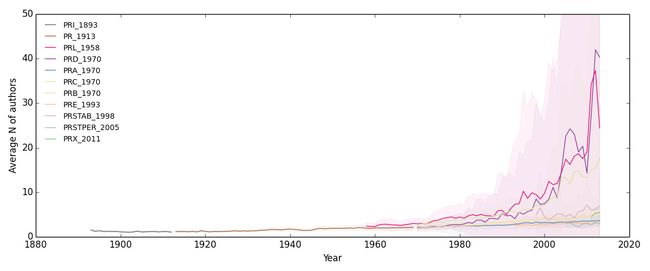
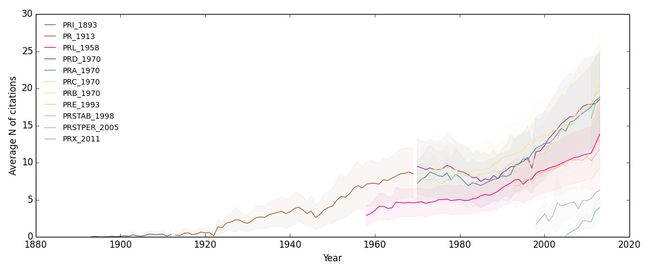

综上各图,结论是APS杂志文章的平均作者数和引用数都在不断增加,说明科研越来越依赖团队作战,而且做出一手科研贡献对专业知识的储备要求也越来越高。
至于论文平均长度,在二战以前的五十年是长度趋于变短,二战后不断增加。我们可以假设,论文长度变短是为了适应专业化,高效的科研交流,二战以后增加的原因是因为作者数量增加。所以如果计算每个作者贡献的文章长度,在过去的一个世纪中,应该是不断下降了。
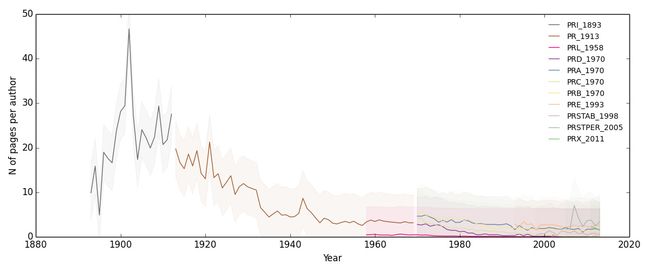
图8证实了我们的猜想(此处不另外给出代码)。
虽然我们看到图7中论文平均被引用次数的下降,但并不能因此就假设说论文的平均影响力在下降,因为可能刚发表的论文是难以获得大量引用的。
另外,从图上可以看出,PRL明显比其他期刊文章更短小,作者数量更多,影响力更大。
迈向真正的科研:动力学建模
在上一节,我们初步分析了数据,并且得到了一些有趣的结论。在实际科研中,这种探索需要不断重复,并构成日常工作的一大部分。需要注意的是,这种工作可以称为data analysis或者data mining,可以用来发一些灌水论文,甚至引起一些媒体的关注,但绝不是科研最核心的部分。
那么科研最核心的部分是什么呢?我个人比较推崇物理学的思路,认为惠勒的“除了物理学的其他科学都是集邮”的判断至今依然有效。要研究一个复杂系统或者社会系统,最要紧的是找到具有极强规律性的,可以写成简洁方程的定律(Laws)。显然,我们之前的探索结果并不具备这种潜质。接下来,我要展示这个数据中的两个定律,一个是超线性增长,一个是指数下降,大家可以感受一下科学之美。
首先我们利用之前的结果,计算文章与引用数的关系。我们先计算每年新增的文章数和引用数,然后在时间上加以累积,得到两个变量,总文章数和总引用数。
W=defaultdict(lambda:[])
for i in G:
for y,val in G[i].items():
mean,std = val
npaper = Y[i][y]
W[i].append([npaper,mean*npaper])
然后将这对关系在双对数坐标系中展示出来并拟合。
fig = plt.figure(figsize=(7, 7),facecolor='white')
cmap = cm.get_cmap('Accent_r', len(journals))
for n, val in enumerate(journals):
firstyear,name=val
if name == 'RMP':
continue
paper,citation = np.array(W[name]).T
alloPlot(np.cumsum(paper),np.cumsum(citation),cmap(n),name+'_'+str(firstyear))
plt.xscale('log')
plt.yscale('log')
plt.xlabel('Total number of papers')
plt.ylabel('Total number of citations')
plt.legend(loc=2,fontsize=10,numpoints=1)
#
plt.tight_layout()
plt.show()
得到下图,发现存在关系
![Eq. 1][1]
[1]: http://latex.codecogs.com/svg.latex?W\sim{N^{\gamma}}
其中W是引用数量,N是文章数量。

考虑一个网络,节点是论文,连边是论文之间彼此引用的关系,这样的网络可以称为科学引文网络。上图中我们发现,链边增长得比节点数量要快,而且总链边数和总节点数之间总是构成如Eq.1所示幂律关系。
如果我们简单地将每篇论文看做知识空间里的一个点,它似乎意味着物理学知识正在成为越来越紧密的一个整体,每一篇论文都要依赖越来越多其他论文的支持来定位自己。张江和我很早就注意到了这个问题,我们称之为异速增长律,感兴趣的可以看集智百科的介绍。我们在这些论文[1,2,3]中给予了讨论。 [3] 给出了一个非常简洁的基于空间的链接模型来解释这种现象。
重要的问题总是同时得到许多人的关注,例如Jure Leskovec, Jon Kleinberg等人也非常关注这个现象,称之为Graph Densification,并在这篇论文中给出了讨论。我们的论文中还引用了其他更多的相关文献。
对于这样的现象,你是否能有自己的解释,是否能得到比 [3]更简单的模型?如果是,请在这篇文章下面留言,介绍你高明的思路。
现在,让我们看一下另一对关关系。我们现在想知道随着时间过去论文的引用是如何下降的。这个事情有很多不同的角度,最简单的是追踪每一篇文章,看对它的引用变化情况。但这样会得到一大堆时间序列,为了得到稳定的规律,必然又使用要取均值等手段去掉噪声,所以未必是最高效的思路。
我们在这里考虑到每一个引用相当于在时间长河里的回头一步,所以每一个引用都有一个对应的时间跨度,我们只需要考察“引用跨越的时间”这个变量的分布,即可得到一个统计图来简洁地回答我们关心的问题。通过早期探索,我们发现这个变量呈现指数分布的简洁规律。因此我们加一个条件概率,将不同年份的引用分开,来观察这个分布是否随年代不同,使分析更有意思。
我们首先要把所有文章以DOI为key放在一个Python字典里,也就是取消掉原来的期刊子字典结构
B={}
for j in P:
for i in P[j]:
B[i]=P[j][i]
然后可以直接在数据里做统计
T=defaultdict(lambda:defaultdict(lambda:0))
n=0
with open('/Users/csid/Documents/bigdata/aps/aps-dataset-citations-2013/aps-dataset-citations-2013.csv','r') as f:
for line in f:
n+=1
if n%10000==0:
flushPrint(n/10000)
x,y=line.strip().split(',')#x cited y
if x in B and y in B:
year2=B[x][0]
year1=B[y][0]
deltaYear=year2-year1
if deltaYear>=0:
T[year2/20][deltaYear]+=1
并且将结果展示出来
fig = plt.figure(figsize=(7, 7),facecolor='white')
cmap = cm.get_cmap('Accent', len(T))
years=sorted(T.keys())
for n,i in enumerate(years):
x,y=np.array(T[i].items()).T
semilogPlot(x,y,cmap(n),str(i*20))
plt.legend(loc=1,fontsize=10)
plt.ylim(1,10**6)
plt.yscale('log')
plt.xlabel('Acrossing years')
plt.ylabel('N of citations')
plt.show()
如前所述,发现存在关系:
![Eq. 2][2]
[2]: http://latex.codecogs.com/svg.latex?M\sim{e^{-\delta{t}}}
其中M是被引用数量,t是时间。

如上图所示,我们发现虽然文章引用的频次随时间跨度加大总是以指数方式迅速衰减,但这个衰减速度在变慢。物理学家不断引用更早的研究发现,这说明随着人类社会发展,科学家对已有知识检验和重构的宽度在不断增加。
信息资源获得注意力随时间的下降速度是很有意思的问题,例如Fang Wu 和 Bernardo A. Huberman在这篇文章中指出,Digg社区中新闻获得注意力的衰减比指数衰减要慢。但我们这里的研究结论是,就论文而言,以年为单位分析的话,注意力的衰减是指数式的。接下来的任务,就是给出一个简洁的模型来解释这种指数衰减。
上述两个图,只是一个科研探索的开始,而不是结束。还有许多有意思的问题,可以用这个数据回答。例如文章的引用是否贫富分化在拉大,更多人合作的文章是否能被引用更多次,是否存在最佳合作规模,等等。希望对使用物理学方法研究社会系统感兴趣的你,通过评论等方式参与到对这些现象的讨论中来。