Faster-RCNN的demo文件详解
目录
pytorch编写Faster-RCNN的下载地址
我们分部讲解demo程序
导入库:
创建生成器用于for:
设置程序输入参数:
使用EasyDict为一些网络属性赋值:
_get_image_blob函数:
主函数初始化:
创建网络:
关于.create_architecture()方法
加载模型数据:
模型,数据放入GPU:
数据送入模型:
画图和显示:
加载图片数据,有两种形式,一种是文件夹下的数据,一种是视频:
demo的总程序如下:
pytorch编写Faster-RCNN的下载地址
我们分部讲解demo程序
导入库:
#python2统一到python3的行为库
from __future__ import absolute_import
#将lib文件夹加入系统路径
import _init_paths
#调试库
import pdb导入库部分重点讲这三个库__future__ , _init_paths,pdb官方参考。
创建生成器用于for:
try:
xrange # Python 2
except NameError:
xrange = range # Python 3在python2中xrange是产生一个生成器,每次返回一个值。range是生成一个遍历列表。
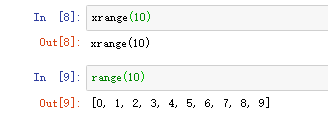
python3中用xrange的功能合并到range中。
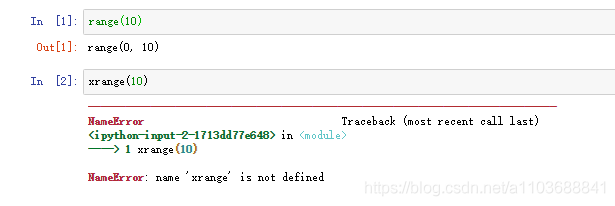
这两者对比详情参考,在python2和python3对比详情参考
设置程序输入参数:
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument('--dataset', dest='dataset',
help='training dataset',
default='pascal_voc', type=str)
args = parser.parse_args()
return args参考下半部分python接口。
使用EasyDict为一些网络属性赋值:
lr = cfg.TRAIN.LEARNING_RATE
momentum = cfg.TRAIN.MOMENTUM
weight_decay = cfg.TRAIN.WEIGHT_DECAYlr = cfg.TRAIN.LEARNING_RATE = __C.TRAIN.LEARNING_RATE = 0.001
momentum = cfg.TRAIN.MOMENTUM = __C.TRAIN.MOMENTUM = 0.9
weight_decay = cfg.TRAIN.WEIGHT_DECAY = __C.TRAIN.WEIGHT_DECAY = 0.0005
参考上半部分。
_get_image_blob函数:
def _get_image_blob(im):
im_orig = im.astype(np.float32, copy=True)
im_orig -= cfg.PIXEL_MEANS
im_shape = im_orig.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2]).astype是转numpy数据的命令。
cfg.PIXEL_MEANS = __C.PIXEL_MEANS = np.array([[[102.9801, 115.9465, 122.7717]]])这里是RGB三个通道的均值。
接下来3条命令就是得到图像的长边和短边
processed_ims = []
im_scale_factors = []
for target_size in cfg.TEST.SCALES:
im_scale = float(target_size) / float(im_size_min)
# Prevent the biggest axis from being more than MAX_SIZE
if np.round(im_scale * im_size_max) > cfg.TEST.MAX_SIZE:
im_scale = float(cfg.TEST.MAX_SIZE) / float(im_size_max)
im = cv2.resize(im_orig, None, None, fx=im_scale, fy=im_scale,
interpolation=cv2.INTER_LINEAR)
im_scale_factors.append(im_scale)
processed_ims.append(im)
# Create a blob to hold the input images
blob = im_list_to_blob(processed_ims)
return blob, np.array(im_scale_factors)变量:
这个是短边固定尺寸 cfg.TEST.SCALES = __C.TEST.SCALES = (600,)
im_scale * im_size_max是长边尺寸,长边最大尺寸是cfg.TEST.MAX_SIZE = __C.TEST.MAX_SIZE = 1000
im_scale 是缩放比例
cv2.resize改变图片大小
逻辑:
先用短边固定尺寸计算缩放比例,如果长边超最大比例,用长边最大除以长边作为缩放比例。
接下来缩放图片大小,缩放比例存入im_scale_factors数组,缩放图片存入processed_ims数组。
最后把图片转为blob格式。im_list_to_blob函数和blob格式,参考。
返回两个数值,一个是blob格式的图片数据列表,一个是对应的缩放列表。
补充:
blob格式就是 [ 图片数量 ,所有图片的最大长,所有图片的最大宽,RGB3通道 ] ,这里如果图片长比所有最大图片的长小,多出来的值用0补充,宽也一样。
主函数初始化:
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
if args.cfg_file is not None:
cfg_from_file(args.cfg_file)
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)
cfg.USE_GPU_NMS = args.cuda
print('Using config:')
pprint.pprint(cfg)
np.random.seed(cfg.RNG_SEED)pprint是格式化打印,用于输出格式化字典,让字典打印的时候不会乱糟糟的。
创建网络:
fasterRCNN是一个类,.create_architecture()是一个方法,该方法在lib/model/faster_rcnn/faster_rcnn.py中。
faster_rcnn是一个父类,vgg16这些是继承这个父类。
if args.net == 'vgg16':
fasterRCNN = vgg16(pascal_classes, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res101':
fasterRCNN = resnet(pascal_classes, 101, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res50':
fasterRCNN = resnet(pascal_classes, 50, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res152':
fasterRCNN = resnet(pascal_classes, 152, pretrained=False, class_agnostic=args.class_agnostic)
else:
print("network is not defined")
pdb.set_trace()
fasterRCNN.create_architecture()关于.create_architecture()方法
#在_fasterRCNN类中
def create_architecture(self):
self._init_modules()
self._init_weights()其中_init_modules()在VGG16类中重写
#在vgg16类中
def _init_modules(self):
vgg = models.vgg16()
if self.pretrained:
print("Loading pretrained weights from %s" %(self.model_path))
state_dict = torch.load(self.model_path)
vgg.load_state_dict({k:v for k,v in state_dict.items() if k in vgg.state_dict()})
vgg.classifier = nn.Sequential(*list(vgg.classifier._modules.values())[:-1])
# not using the last maxpool layer
self.RCNN_base = nn.Sequential(*list(vgg.features._modules.values())[:-1])
# Fix the layers before conv3:
for layer in range(10):
for p in self.RCNN_base[layer].parameters(): p.requires_grad = False
# self.RCNN_base = _RCNN_base(vgg.features, self.classes, self.dout_base_model)
self.RCNN_top = vgg.classifier
# not using the last maxpool layer
self.RCNN_cls_score = nn.Linear(4096, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred = nn.Linear(4096, 4)
else:
self.RCNN_bbox_pred = nn.Linear(4096, 4 * self.n_classes)
其中_init_weights()在faster_rcnn类中定义:
def _init_weights(self):
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
normal_init(self.RCNN_rpn.RPN_Conv, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_rpn.RPN_cls_score, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_rpn.RPN_bbox_pred, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_cls_score, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_bbox_pred, 0, 0.001, cfg.TRAIN.TRUNCATED)加载模型数据:
print("load checkpoint %s" % (load_name))
if args.cuda > 0:
checkpoint = torch.load(load_name)
else:
checkpoint = torch.load(load_name, map_location=(lambda storage, loc: storage))
fasterRCNN.load_state_dict(checkpoint['model'])
if 'pooling_mode' in checkpoint.keys():
cfg.POOLING_MODE = checkpoint['pooling_mode']
print('load model successfully!')
print("load checkpoint %s" % (load_name))这里有几种torch.load的用法:
>>> torch.load('tensors.pt')
# Load all tensors onto the CPU
>>> torch.load('tensors.pt', map_location=lambda storage, loc: storage)
# Map tensors from GPU 1 to GPU 0
>>> torch.load('tensors.pt', map_location={'cuda:1':'cuda:0'})模型,数据放入GPU:
# initilize the tensor holder here.
im_data = torch.FloatTensor(1)
im_info = torch.FloatTensor(1)
num_boxes = torch.LongTensor(1)
gt_boxes = torch.FloatTensor(1)
# ship to cuda
if args.cuda > 0:
im_data = im_data.cuda()
im_info = im_info.cuda()
num_boxes = num_boxes.cuda()
gt_boxes = gt_boxes.cuda()
# make variable
with torch.no_grad():
im_data = Variable(im_data)
im_info = Variable(im_info)
num_boxes = Variable(num_boxes)
gt_boxes = Variable(gt_boxes)
if args.cuda > 0:
cfg.CUDA = True
if args.cuda > 0:
fasterRCNN.cuda()
fasterRCNN.eval()
加载图片数据,有两种形式,一种是文件夹下的数据,一种是视频:
start = time.time()
max_per_image = 100
thresh = 0.05
vis = True
webcam_num = args.webcam_num
# Set up webcam or get image directories
if webcam_num >= 0 :
cap = cv2.VideoCapture(webcam_num)
num_images = 0
else:
imglist = os.listdir(args.image_dir)
num_images = len(imglist)
print('Loaded Photo: {} images.'.format(num_images))
数据送入模型:
rois, cls_prob, bbox_pred, \
rpn_loss_cls, rpn_loss_box, \
RCNN_loss_cls, RCNN_loss_bbox, \
rois_label = fasterRCNN(im_data, im_info, gt_boxes, num_boxes)
scores = cls_prob.data
boxes = rois.data[:, :, 1:5]
#当shape==2的时候,说明图片是单色的,下面把他拼接,硬是变成3通道
if len(im_in.shape) == 2:
im_in = im_in[:,:,np.newaxis]
im_in = np.concatenate((im_in,im_in,im_in), axis=2)
图片格式是这样的im_in[batch,形状,深度]
im_blob是变化尺寸后的图像im_in,im_scales是对应变化的比例储存。
while (num_images >= 0):
total_tic = time.time()
if webcam_num == -1:
num_images -= 1
# Get image from the webcam
if webcam_num >= 0:
if not cap.isOpened():
raise RuntimeError("Webcam could not open. Please check connection.")
ret, frame = cap.read()
im_in = np.array(frame)
# Load the demo image
else:
im_file = os.path.join(args.image_dir, imglist[num_images])
# im = cv2.imread(im_file)
im_in = np.array(imread(im_file))
#当shape==2的时候,说明图片是单色的,下面把他拼接,硬是变成3通道
if len(im_in.shape) == 2:
im_in = im_in[:,:,np.newaxis]
im_in = np.concatenate((im_in,im_in,im_in), axis=2)
# rgb -> bgr
im_in = im_in[:,:,::-1]
im = im_in
blobs, im_scales = _get_image_blob(im)
assert len(im_scales) == 1, "Only single-image batch implemented"
im_blob = blobs
im_info_np = np.array([[im_blob.shape[1], im_blob.shape[2], im_scales[0]]], dtype=np.float32)
im_data_pt = torch.from_numpy(im_blob)
im_data_pt = im_data_pt.permute(0, 3, 1, 2)
im_info_pt = torch.from_numpy(im_info_np)
im_data.data.resize_(im_data_pt.size()).copy_(im_data_pt)
im_info.data.resize_(im_info_pt.size()).copy_(im_info_pt)
gt_boxes.data.resize_(1, 1, 5).zero_()
num_boxes.data.resize_(1).zero_()
# pdb.set_trace()
det_tic = time.time()画图和显示:
sys.stdout.write('im_detect: {:d}/{:d} {:.3f}s {:.3f}s \r' \
.format(num_images + 1, len(imglist), detect_time, nms_time))
sys.stdout.flush()
这里sys.stdout.write和print一样,sys.stdout.flush()是及时刷新输出,参考。
if cfg.TEST.BBOX_REG:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED:
# Optionally normalize targets by a precomputed mean and stdev
if args.class_agnostic:
if args.cuda > 0:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda()
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS) \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS)
box_deltas = box_deltas.view(1, -1, 4)
else:
if args.cuda > 0:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda()
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS) \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS)
box_deltas = box_deltas.view(1, -1, 4 * len(pascal_classes))
pred_boxes = bbox_transform_inv(boxes, box_deltas, 1)
pred_boxes = clip_boxes(pred_boxes, im_info.data, 1)
else:
# Simply repeat the boxes, once for each class
_ = torch.from_numpy(np.tile(boxes, (1, scores.shape[1])))
pred_boxes = _.cuda() if args.cuda > 0 else _
pred_boxes /= im_scales[0]
scores = scores.squeeze()
pred_boxes = pred_boxes.squeeze()
det_toc = time.time()
detect_time = det_toc - det_tic
misc_tic = time.time()
1)留下高于阈值的置性度
2)对置性度进行排列
3)NMS去除重叠框
4)画图
if vis:
im2show = np.copy(im)
for j in xrange(1, len(pascal_classes)):
inds = torch.nonzero(scores[:,j]>thresh).view(-1)
# if there is det
if inds.numel() > 0:
cls_scores = scores[:,j][inds]
_, order = torch.sort(cls_scores, 0, True)
if args.class_agnostic:
cls_boxes = pred_boxes[inds, :]
else:
cls_boxes = pred_boxes[inds][:, j * 4:(j + 1) * 4]
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1)
# cls_dets = torch.cat((cls_boxes, cls_scores), 1)
cls_dets = cls_dets[order]
keep = nms(cls_dets, cfg.TEST.NMS, force_cpu=not cfg.USE_GPU_NMS)
cls_dets = cls_dets[keep.view(-1).long()]
if vis:
im2show = vis_detections(im2show, pascal_classes[j], cls_dets.cpu().numpy(), 0.5)
misc_toc = time.time()
nms_time = misc_toc - misc_tic
if webcam_num == -1:
sys.stdout.write('im_detect: {:d}/{:d} {:.3f}s {:.3f}s \r' \
.format(num_images + 1, len(imglist), detect_time, nms_time))
sys.stdout.flush()
if vis and webcam_num == -1:
# cv2.imshow('test', im2show)
# cv2.waitKey(0)
result_path = os.path.join(args.image_save_dir, imglist[num_images][:-4] + "_det.jpg")
cv2.imwrite(result_path, im2show)
else:
cv2.imshow("frame", im2show)
total_toc = time.time()
total_time = total_toc - total_tic
frame_rate = 1 / total_time
print('Frame rate:', frame_rate)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if webcam_num >= 0:
cap.release()
cv2.destroyAllWindows()摄像头部分单独提出:
cap = cv2.VideoCapture(webcam_num)
num_images = 0
if not cap.isOpened():
raise RuntimeError("Webcam could not open. Please check connection.")
ret, frame = cap.read()
im_in = np.array(frame)
im = im_in
blobs, im_scales = _get_image_blob(im)
assert len(im_scales) == 1, "Only single-image batch implemented"
OpenCV读取视频的操作参考
demo的总程序如下:
# --------------------------------------------------------
# Tensorflow Faster R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Jiasen Lu, Jianwei Yang, based on code from Ross Girshick
# --------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import _init_paths
import os
import sys
import numpy as np
import argparse
import pprint
import pdb
import time
import cv2
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as dset
from scipy.misc import imread
from roi_data_layer.roidb import combined_roidb
from roi_data_layer.roibatchLoader import roibatchLoader
from model.utils.config import cfg, cfg_from_file, cfg_from_list, get_output_dir
from model.rpn.bbox_transform import clip_boxes
from model.nms.nms_wrapper import nms
from model.rpn.bbox_transform import bbox_transform_inv
from model.utils.net_utils import save_net, load_net, vis_detections
from model.utils.blob import im_list_to_blob
from model.faster_rcnn.vgg16 import vgg16
from model.faster_rcnn.resnet import resnet
import pdb
try:
xrange # Python 2
except NameError:
xrange = range # Python 3
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument('--dataset', dest='dataset',
help='training dataset',
default='pascal_voc', type=str)
parser.add_argument('--cfg', dest='cfg_file',
help='optional config file',
default='cfgs/vgg16.yml', type=str)
parser.add_argument('--net', dest='net',
help='vgg16, res50, res101, res152',
default='res101', type=str)
parser.add_argument('--set', dest='set_cfgs',
help='set config keys', default=None,
nargs=argparse.REMAINDER)
parser.add_argument('--load_dir', dest='load_dir',
help='directory to load models',
default="/srv/share/jyang375/models")
parser.add_argument('--image_dir', dest='image_dir',
help='directory to load images for demo',
default="images")
parser.add_argument('--cuda', dest='cuda',
help='whether use CUDA',
action='store_true')
parser.add_argument('--mGPUs', dest='mGPUs',
help='whether use multiple GPUs',
action='store_true')
parser.add_argument('--cag', dest='class_agnostic',
help='whether perform class_agnostic bbox regression',
action='store_true')
parser.add_argument('--parallel_type', dest='parallel_type',
help='which part of model to parallel, 0: all, 1: model before roi pooling',
default=0, type=int)
parser.add_argument('--checksession', dest='checksession',
help='checksession to load model',
default=1, type=int)
parser.add_argument('--checkepoch', dest='checkepoch',
help='checkepoch to load network',
default=1, type=int)
parser.add_argument('--checkpoint', dest='checkpoint',
help='checkpoint to load network',
default=10021, type=int)
parser.add_argument('--bs', dest='batch_size',
help='batch_size',
default=1, type=int)
parser.add_argument('--vis', dest='vis',
help='visualization mode',
action='store_true')
parser.add_argument('--webcam_num', dest='webcam_num',
help='webcam ID number',
default=-1, type=int)
args = parser.parse_args()
return args
lr = cfg.TRAIN.LEARNING_RATE
momentum = cfg.TRAIN.MOMENTUM
weight_decay = cfg.TRAIN.WEIGHT_DECAY
def _get_image_blob(im):
"""Converts an image into a network input.
Arguments:
im (ndarray): a color image in BGR order
Returns:
blob (ndarray): a data blob holding an image pyramid
im_scale_factors (list): list of image scales (relative to im) used
in the image pyramid
"""
im_orig = im.astype(np.float32, copy=True)
im_orig -= cfg.PIXEL_MEANS
im_shape = im_orig.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
processed_ims = []
im_scale_factors = []
for target_size in cfg.TEST.SCALES:
im_scale = float(target_size) / float(im_size_min)
# Prevent the biggest axis from being more than MAX_SIZE
if np.round(im_scale * im_size_max) > cfg.TEST.MAX_SIZE:
im_scale = float(cfg.TEST.MAX_SIZE) / float(im_size_max)
im = cv2.resize(im_orig, None, None, fx=im_scale, fy=im_scale,
interpolation=cv2.INTER_LINEAR)
im_scale_factors.append(im_scale)
processed_ims.append(im)
# Create a blob to hold the input images
blob = im_list_to_blob(processed_ims)
return blob, np.array(im_scale_factors)
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
if args.cfg_file is not None:
cfg_from_file(args.cfg_file)
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)
cfg.USE_GPU_NMS = args.cuda
print('Using config:')
pprint.pprint(cfg)
np.random.seed(cfg.RNG_SEED)
# train set
# -- Note: Use validation set and disable the flipped to enable faster loading.
input_dir = args.load_dir + "/" + args.net + "/" + args.dataset
if not os.path.exists(input_dir):
raise Exception('There is no input directory for loading network from ' + input_dir)
load_name = os.path.join(input_dir,
'faster_rcnn_{}_{}_{}.pth'.format(args.checksession, args.checkepoch, args.checkpoint))
pascal_classes = np.asarray(['__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor'])
# initilize the network here.
if args.net == 'vgg16':
fasterRCNN = vgg16(pascal_classes, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res101':
fasterRCNN = resnet(pascal_classes, 101, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res50':
fasterRCNN = resnet(pascal_classes, 50, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res152':
fasterRCNN = resnet(pascal_classes, 152, pretrained=False, class_agnostic=args.class_agnostic)
else:
print("network is not defined")
pdb.set_trace()
fasterRCNN.create_architecture()
print("load checkpoint %s" % (load_name))
if args.cuda > 0:
checkpoint = torch.load(load_name)
else:
checkpoint = torch.load(load_name, map_location=(lambda storage, loc: storage))
fasterRCNN.load_state_dict(checkpoint['model'])
if 'pooling_mode' in checkpoint.keys():
cfg.POOLING_MODE = checkpoint['pooling_mode']
print('load model successfully!')
# pdb.set_trace()
print("load checkpoint %s" % (load_name))
# initilize the tensor holder here.
im_data = torch.FloatTensor(1)
im_info = torch.FloatTensor(1)
num_boxes = torch.LongTensor(1)
gt_boxes = torch.FloatTensor(1)
# ship to cuda
if args.cuda > 0:
im_data = im_data.cuda()
im_info = im_info.cuda()
num_boxes = num_boxes.cuda()
gt_boxes = gt_boxes.cuda()
# make variable
with torch.no_grad():
im_data = Variable(im_data)
im_info = Variable(im_info)
num_boxes = Variable(num_boxes)
gt_boxes = Variable(gt_boxes)
if args.cuda > 0:
cfg.CUDA = True
if args.cuda > 0:
fasterRCNN.cuda()
fasterRCNN.eval()
start = time.time()
max_per_image = 100
thresh = 0.05
vis = True
webcam_num = args.webcam_num
# Set up webcam or get image directories
if webcam_num >= 0 :
cap = cv2.VideoCapture(webcam_num)
num_images = 0
else:
imglist = os.listdir(args.image_dir)
num_images = len(imglist)
print('Loaded Photo: {} images.'.format(num_images))
while (num_images >= 0):
total_tic = time.time()
if webcam_num == -1:
num_images -= 1
# Get image from the webcam
if webcam_num >= 0:
if not cap.isOpened():
raise RuntimeError("Webcam could not open. Please check connection.")
ret, frame = cap.read()
im_in = np.array(frame)
# Load the demo image
else:
im_file = os.path.join(args.image_dir, imglist[num_images])
# im = cv2.imread(im_file)
im_in = np.array(imread(im_file))
if len(im_in.shape) == 2:
im_in = im_in[:,:,np.newaxis]
im_in = np.concatenate((im_in,im_in,im_in), axis=2)
# rgb -> bgr
im_in = im_in[:,:,::-1]
im = im_in
blobs, im_scales = _get_image_blob(im)
assert len(im_scales) == 1, "Only single-image batch implemented"
im_blob = blobs
im_info_np = np.array([[im_blob.shape[1], im_blob.shape[2], im_scales[0]]], dtype=np.float32)
im_data_pt = torch.from_numpy(im_blob)
im_data_pt = im_data_pt.permute(0, 3, 1, 2)
im_info_pt = torch.from_numpy(im_info_np)
im_data.data.resize_(im_data_pt.size()).copy_(im_data_pt)
im_info.data.resize_(im_info_pt.size()).copy_(im_info_pt)
gt_boxes.data.resize_(1, 1, 5).zero_()
num_boxes.data.resize_(1).zero_()
# pdb.set_trace()
det_tic = time.time()
rois, cls_prob, bbox_pred, \
rpn_loss_cls, rpn_loss_box, \
RCNN_loss_cls, RCNN_loss_bbox, \
rois_label = fasterRCNN(im_data, im_info, gt_boxes, num_boxes)
scores = cls_prob.data
boxes = rois.data[:, :, 1:5]
if cfg.TEST.BBOX_REG:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED:
# Optionally normalize targets by a precomputed mean and stdev
if args.class_agnostic:
if args.cuda > 0:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda()
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS) \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS)
box_deltas = box_deltas.view(1, -1, 4)
else:
if args.cuda > 0:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda()
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS) \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS)
box_deltas = box_deltas.view(1, -1, 4 * len(pascal_classes))
pred_boxes = bbox_transform_inv(boxes, box_deltas, 1)
pred_boxes = clip_boxes(pred_boxes, im_info.data, 1)
else:
# Simply repeat the boxes, once for each class
_ = torch.from_numpy(np.tile(boxes, (1, scores.shape[1])))
pred_boxes = _.cuda() if args.cuda > 0 else _
pred_boxes /= im_scales[0]
scores = scores.squeeze()
pred_boxes = pred_boxes.squeeze()
det_toc = time.time()
detect_time = det_toc - det_tic
misc_tic = time.time()
if vis:
im2show = np.copy(im)
for j in xrange(1, len(pascal_classes)):
inds = torch.nonzero(scores[:,j]>thresh).view(-1)
# if there is det
if inds.numel() > 0:
cls_scores = scores[:,j][inds]
_, order = torch.sort(cls_scores, 0, True)
if args.class_agnostic:
cls_boxes = pred_boxes[inds, :]
else:
cls_boxes = pred_boxes[inds][:, j * 4:(j + 1) * 4]
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1)
# cls_dets = torch.cat((cls_boxes, cls_scores), 1)
cls_dets = cls_dets[order]
keep = nms(cls_dets, cfg.TEST.NMS, force_cpu=not cfg.USE_GPU_NMS)
cls_dets = cls_dets[keep.view(-1).long()]
if vis:
im2show = vis_detections(im2show, pascal_classes[j], cls_dets.cpu().numpy(), 0.5)
misc_toc = time.time()
nms_time = misc_toc - misc_tic
if webcam_num == -1:
sys.stdout.write('im_detect: {:d}/{:d} {:.3f}s {:.3f}s \r' \
.format(num_images + 1, len(imglist), detect_time, nms_time))
sys.stdout.flush()
if vis and webcam_num == -1:
# cv2.imshow('test', im2show)
# cv2.waitKey(0)
result_path = os.path.join(args.image_dir, imglist[num_images][:-4] + "_det.jpg")
cv2.imwrite(result_path, im2show)
else:
cv2.imshow("frame", im2show)
total_toc = time.time()
total_time = total_toc - total_tic
frame_rate = 1 / total_time
print('Frame rate:', frame_rate)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if webcam_num >= 0:
cap.release()
cv2.destroyAllWindows()