机器学习案例1:KNN实现鸢尾花分类
案例1:KNN实现鸢尾花分类
为什么写本博客
前人种树,后人乘凉。希望自己的学习笔记可以帮助到需要的人。
需要的基础
懂不懂原理不重要,本系列的目标是使用python实现机器学习。
必须会的东西:python基础、numpy、matplotlib和库的使用技巧。
说明
完整的代码在最后
目录结构
文章目录
-
- 案例1:KNN实现鸢尾花分类
-
- 1. 数据集介绍和划分:
- 2. 训练集显示:
- 3. 模型创建、训练和评估:
- 4. 探究不同K值对于准确率的影响:
- 5. 完整代码:
1. 数据集介绍和划分:
鸢尾花数据集,一个小型数据集,可以在网上下载到数据集,也可以使用sklearn自带的(建议)。这个数据集共150条,每条共四个特征(花萼长、花萼宽、花瓣长、花瓣宽),一个标签,标签共三类(反正是三种鸢尾花,具体的我也不清楚)。
下面,我们通过sklearn加载数据集:
from sklearn.datasets import load_iris
# 加载数据
data = load_iris()
print(data)
打印的结果部分为:
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
......
可以看出,返回的结果是一个字典,因此可以通过字典的方法把值取出来。
下一步,我们需要划分训练集和测试集,比例为8:2。这里,涉及到sklearn中的一个方法:
from sklearn import model_selection
x_train,x_test,y_train,y_test = model_selection.train_test_split(x,y,test_size=0.2,random_state=22)
# 方法名: train_test_split
# 主要参数:x(数据)、y(数据)、test_size(测试集大小0-1)、random_state(随机数种子,填写整数即可)
我们使用该方法来划分数据集:
# 划分数据集
x_train,x_test,y_train,y_test = model_selection.train_test_split(data['data'],data['target'],test_size=0.2,random_state=22)
print(x_train.shape) # 120,4
print(y_train.shape) # 120,
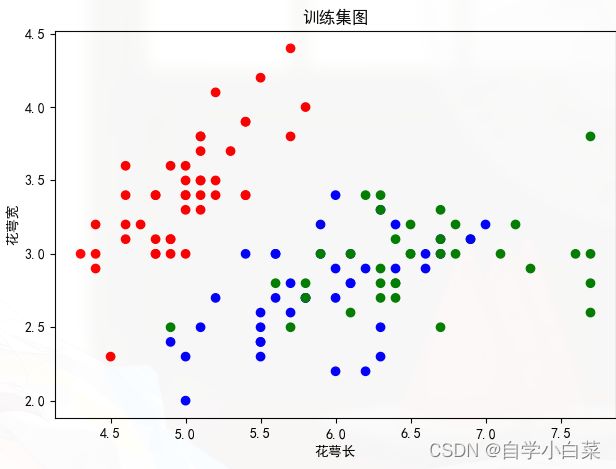
2. 训练集显示:
我打算把训练集画成散点图来给大家看看,有一个直观印象,这里我们采取四个特征中的前两个作为x、y轴,为三个类别设置不同的颜色:
from matplotlib import pyplot as plt
# 画出训练集
# 处理中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure()
c = ['r','b','g'] # 设置三个颜色
color = [c[y] for y in y_train] # 为不同的标签设置颜色,比如0--r--红色
plt.scatter(x_train[:,0],x_train[:,1],c=color)
plt.title('训练集图')
plt.xlabel('花萼长')
plt.ylabel('花萼宽')
plt.show()
结果为:
3. 模型创建、训练和评估:
在创建模型之前,介绍一下相关的API:
# 所处的包
from sklearn.neighbors import KNeighborsClassifier
# 创建模型函数
model = KNeighborsClassifier(n_neighbors)
'''
方法: KNeighborsClassifier
参数: n_neighbors指定KNN中的K值
'''
# 模型训练方法
model.fit(x,y)
'''
方法: 隶属于对象model,名字为fit
参数: x和y数据,一般为训练集数据
'''
# 准确率计算方法
score = model.score(x_test,y_test)
'''
方法: 隶属于对象model,名为score
参数: x和y数据,一般为测试集数据
'''
基于上述的方法,来写代码。
首先,构建模型,这里的K值暂时随机选择为5:
# 创建模型
model = KNeighborsClassifier(n_neighbors=5)
接着,训练模型:
model.fit(x_train,y_train)
最后,进行评估:
# 评估
score = model.score(x_test,y_test)
print('测试集准确率:',score)
运行,结果如下:
测试集准确率: 0.9666666666666667
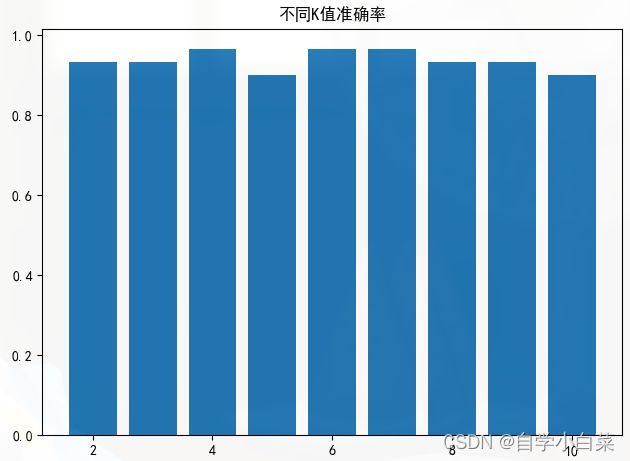
4. 探究不同K值对于准确率的影响:
**KNN中的一个重要问题就是K值如何选取?**这个问题是仁者见仁,智者见智。毕竟,这种问题逃不过多次尝试。但是,我们必须明确不同的K值对结果有不同的影响,不能简单的认为K值越大越好或越小越好。
这里,我创建多个模型,其中唯一变换的就是K值,分别从2-10:
# 探究k值影响
model_new = {
KNeighborsClassifier(n_neighbors=2),
KNeighborsClassifier(n_neighbors=3),
KNeighborsClassifier(n_neighbors=4),
KNeighborsClassifier(n_neighbors=5),
KNeighborsClassifier(n_neighbors=6),
KNeighborsClassifier(n_neighbors=7),
KNeighborsClassifier(n_neighbors=8),
KNeighborsClassifier(n_neighbors=9),
KNeighborsClassifier(n_neighbors=10),
}
然后,一一进行训练,并将准确率保存下来:
score_list = [] # 定义一个列表
for model in model_new: # 一一迭代
model.fit(x_train,y_train) # 训练
score = model.score(x_test,y_test) # 准确率
score_list.append(score) # 保存准确率
将上面的使用柱状图画出来:
# 画出图形
# 处理中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure()
plt.bar(range(len(score_list)),score_list)
plt.title('不同K值准确率')
plt.show()
结果如下:
5. 完整代码:
# author: baiCai
# 导包
import sklearn
from sklearn.neighbors import KNeighborsClassifier
from sklearn import model_selection
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
# 加载数据
data = load_iris()
# print(data) # 返回的字典
# 划分数据集 8:2
x_train,x_test,y_train,y_test = model_selection.train_test_split(data['data'],data['target'],test_size=0.2,random_state=22)
# print(x_train.shape) # 120,4
# print(y_train.shape) # 120,
# # 创建模型
# model = KNeighborsClassifier(n_neighbors=5)
# model.fit(x_train,y_train)
# # 评估
# score = model.score(x_test,y_test)
# print('测试集准确率:',score)
# # 评估2
# y_predict = model.predict(x_test)
# print('测试集对比真实值和预测值:',y_predict == y_test)
# 探究k值影响
model_new = {
KNeighborsClassifier(n_neighbors=2),
KNeighborsClassifier(n_neighbors=3),
KNeighborsClassifier(n_neighbors=4),
KNeighborsClassifier(n_neighbors=5),
KNeighborsClassifier(n_neighbors=6),
KNeighborsClassifier(n_neighbors=7),
KNeighborsClassifier(n_neighbors=8),
KNeighborsClassifier(n_neighbors=9),
KNeighborsClassifier(n_neighbors=10),
}
score_list = []
for model in model_new:
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
score_list.append(score)
# 画出图形
# 处理中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure()
plt.bar(range(2,11),score_list)
plt.title('不同K值准确率')
plt.show()
# print(score_list)
# 画出训练集
# 处理中文显示问题
# plt.rcParams['font.sans-serif'] = ['SimHei']
# plt.figure()
# c = ['r','b','g'] # 设置三个颜色
# color = [c[y] for y in y_train] # 为不同的标签设置颜色,比如0--r--红色
# plt.scatter(x_train[:,0],x_train[:,1],c=color)
# plt.title('训练集图')
# plt.xlabel('花萼长')
# plt.ylabel('花萼宽')
# plt.show()
运行的时候,把一些注释去掉即可。