【Pytorch】利用PyTorch实现图像识别

本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
这是目录
- 使用torchvision库的datasets类加载常用的数据集或自定义数据集
- 使用torchvision库进行数据增强和变换,自定义自己的图像分类数据集并使用torchvision库加载它们
- 使用torchvision库的models类加载预训练模型或自定义模型
- forward方法
- 进行模型训练和测试,使用matplotlib.pyplot库可视化结果
使用torchvision库的datasets类加载常用的数据集或自定义数据集
图像识别是计算机视觉中的一个基础任务,它的目标是让计算机能够识别图像中的物体、场景或者概念,并将它们分配到预定义的类别中。例如,给定一张猫的图片,图像识别系统应该能够输出“猫”这个类别。
为了训练和评估图像识别系统,我们需要有大量的带有标注的图像数据集。常用的图像分类数据集有:
- ImageNet:一个包含超过1400万张图片和2万多个类别的大型数据库,是目前最流行和最具挑战性的图像分类基准之一。
- CIFAR-10/CIFAR-100:一个包含6万张32×32大小的彩色图片和10或100个类别的小型数据库,适合入门级和快速实验。
- MNIST:一个包含7万张28×28大小的灰度手写数字图片和10个类别的经典数据库,是深度学习中最常用的测试集之一。
- Fashion-MNIST:一个包含7万张28×28大小的灰度服装图片和10个类别的数据库,是MNIST数据库在时尚领域上更加复杂和现代化版本。
使用torchvision库可以方便地加载这些常用数据集或者自定义数据集。torchvision.datasets提供了一些加载数据集或者下载数据集到本地缓存文件夹(默认为./data)并返回Dataset对象(torch.utils.data.Dataset) 的函数。Dataset对象可以存储样本及其对应标签,并提供索引方式(dataset[i])来获取第i个样本。例如,要加载CIFAR-10训练集并进行随机打乱,可以使用以下代码:
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([transforms.ToTensor()]) # 定义转换函数,将PIL.Image转换为torch.Tensor
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # 加载CIFAR-10训练集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True) # 定义DataLoader对象,用于批量加载数据
使用torchvision库进行数据增强和变换,自定义自己的图像分类数据集并使用torchvision库加载它们
- 数据增强和变换:为了提高模型的泛化能力和数据利用率,我们通常会对图像数据进行一些随机的变换,例如裁剪、旋转、翻转、缩放、亮度调整等。这些变换可以在一定程度上模拟真实场景中的图像变化,增加模型对不同视角和光照条件下的物体识别能力。torchvision.transforms提供了一些常用的图像变换函数,可以组合成一个transform对象,并传入datasets类中作为参数。例如,要对CIFAR-10训练集进行随机水平翻转和随机裁剪,并将图像归一化到[-1, 1]范围内,可以使用以下代码:
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomCrop(32, padding=4), # 随机裁剪到32×32大小,并在边缘填充4个像素
transforms.ToTensor(), # 将PIL.Image转换为torch.Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 将RGB三个通道的值归一化到[-1, 1]范围内
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # 加载CIFAR-10训练集,并应用上述变换
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True) # 定义DataLoader对象,用于批量加载数据
- 自定义图像分类数据集:如果我们有自己的图像分类数据集,我们可以通过继承torch.utils.data.Dataset类来自定义一个Dataset对象,并实现__len__和__getitem__两个方法。__len__方法返回数据集中样本的数量,__getitem__方法根据给定的索引返回一个样本及其标签。例如,假设我们有一个文件夹结构如下:
my_dataset/
├── class_0/
│ ├── image_000.jpg
│ ├── image_001.jpg
│ └── ...
├── class_1/
│ ├── image_000.jpg
│ ├── image_001.jpg
│ └── ...
└── ...
其中每个子文件夹代表一个类别,每个子文件夹中包含该类别对应的图像文件。我们可以使用以下代码来自定义一个Dataset对象,并加载这个数据集:
import torch.utils.data as data
from PIL import Image
import os
class MyDataset(data.Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir # 根目录路径
self.transform = transform # 变换函数
self.classes = sorted(os.listdir(root_dir)) # 类别列表(按字母顺序排序)
self.class_to_idx = {c: i for i,c in enumerate(self.classes)} # 类别名到索引的映射
self.images = [] # 图片路径列表(相对于根目录)
self.labels = [] # 标签列表(整数)
for c in self.classes:
c_dir = os.path.join(root_dir, c) # 类别子目录路径
for img_name in sorted(os.listdir(c_dir)): # 遍历每个图片文件名(按字母顺序排序)
img_path = os.path.join(c,img_name) # 图片相对路径(相对于根目录)
label = self.class_to_idx[c] # 图
使用torchvision库的models类加载预训练模型或自定义模型
- 加载预训练模型或自定义模型:torchvision.models提供了一些常用的图像分类模型,例如AlexNet、VGG、ResNet等,并且可以选择是否加载在ImageNet数据集上预训练好的权重。这些模型可以直接用于图像分类任务,也可以作为特征提取器或者微调(fine-tune)的基础。例如,要加载一个预训练好的ResNet-18模型,并冻结除最后一层外的所有参数,可以使用以下代码:
import torchvision.models as models
model = models.resnet18(pretrained=True) # 加载预训练好的ResNet-18模型
for param in model.parameters(): # 遍历所有参数
param.requires_grad = False # 将参数的梯度设置为False,表示不需要更新
num_features = model.fc.in_features # 获取全连接层(fc)的输入特征数
model.fc = torch.nn.Linear(num_features, 10) # 替换全连接层为一个新的线性层,输出特征数为10(假设有10个类别)
如果我们想要自定义自己的图像分类模型,我们可以通过继承torch.nn.Module类来实现一个Module对象,并实现__init__和forward两个方法。__init__方法用于定义模型中需要的各种层和参数,forward方法用于定义前向传播过程。例如,要自定义一个简单的卷积神经网络(CNN)模型,可以使用以下代码:
import torch.nn as nn
class MyCNN(nn.Module):
def __init__(self):
super(MyCNN, self).__init__() # 调用父类构造函数
self.conv1 = nn.Conv2d(3, 6, 5) # 定义第一个卷积层,输入通道数为3(RGB),输出通道数为6,卷积核大小为5×5
self.pool = nn.MaxPool2d(2, 2) # 定义最大池化层,池化核大小为2×2,步长为2
self.conv2 = nn.Conv2d(6, 16, 5) # 定义第二个卷积层,输入通道数为6,输出通道数为16,卷积核大小为5×5
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 定义第一个全连接层,输入特征数为16×5×5(根据卷积和池化后的图像大小计算得到),输出特征数为120
self.fc2 = nn.Linear(120, 84) # 定义第二个全连接层,输入特征数为120,输出特征数为84
self.fc3 = nn.Linear(84, 10) # 定义第三个全连接层,输入特征数为84,
forward方法
forward方法用于定义前向传播过程,即如何根据输入的图像张量(Tensor)计算出输出的类别概率分布。我们可以使用定义好的各种层和参数,并结合一些激活函数(如ReLU)和归一化函数(如softmax)来实现forward方法。例如,要实现上面自定义的CNN模型的forward方法,可以使用以下代码:
import torch.nn.functional as F
class MyCNN(nn.Module):
def __init__(self):
# 省略__init__方法的内容
...
def forward(self, x): # 定义前向传播过程,x是输入的图像张量
x = self.pool(F.relu(self.conv1(x))) # 将x通过第一个卷积层和ReLU激活函数,然后通过最大池化层
x = self.pool(F.relu(self.conv2(x))) # 将x通过第二个卷积层和ReLU激活函数,然后通过最大池化层
x = x.view(-1, 16 * 5 * 5) # 将x展平为一维向量,-1表示自动推断批量大小
x = F.relu(self.fc1(x)) # 将x通过第一个全连接层和ReLU激活函数
x = F.relu(self.fc2(x)) # 将x通过第二个全连接层和ReLU激活函数
x = self.fc3(x) # 将x通过第三个全连接层
x = F.softmax(x, dim=1) # 将x通过softmax函数,沿着第一个维度(类别维度)进行归一化,得到类别概率分布
return x # 返回输出的类别概率分布
进行模型训练和测试,使用matplotlib.pyplot库可视化结果
模型训练和测试是机器学习中的重要步骤,它们可以帮助我们评估模型的性能和泛化能力。matplotlib.pyplot是一个Python库,它可以用来绘制各种类型的图形,包括曲线图、散点图、直方图等。使用matplotlib.pyplot库可视化结果的一般步骤如下:
- 导入matplotlib.pyplot模块,并设置一些参数,如字体、分辨率等。
- 创建一个或多个图形对象(figure),并指定大小、标题等属性。
- 在每个图形对象中创建一个或多个子图(subplot),并指定位置、坐标轴等属性。
- 在每个子图中绘制数据,使用不同的函数和参数,如plot、scatter、bar等。
- 添加一些修饰元素,如图例(legend)、标签(label)、标题(title)等。
- 保存或显示图形。
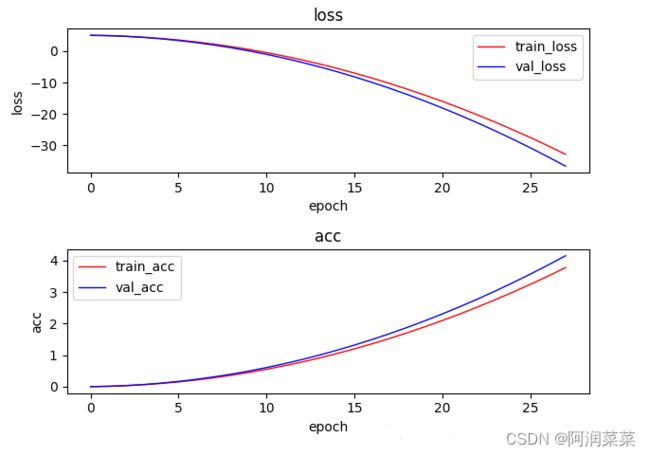
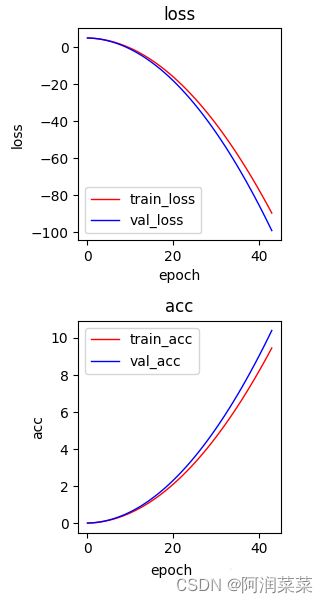
例如:使用matplotlib.pyplot库绘制了一个线性回归模型的训练误差和测试误差曲线:
# 导入模块
import matplotlib.pyplot as plt
import numpy as np
# 设置字体和分辨率
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
%config InlineBackend.figure_format = "retina"
# 生成数据
x = np.linspace(0, 10, 100)
y = 3 * x + 5 + np.random.randn(100) * 2 # 真实值
w = np.random.randn() # 随机初始化权重
b = np.random.randn() # 随机初始化偏置
# 定义损失函数
def loss(y_true, y_pred):
return ((y_true - y_pred) ** 2).mean()
# 定义梯度下降函数
def gradient_descent(x, y_true, w, b, lr):
y_pred = w * x + b # 预测值
dw = -2 * (x * (y_true - y_pred)).mean() # 权重梯度
db = -2 * (y_true - y_pred).mean() # 偏置梯度
w = w - lr * dw # 更新权重
b = b - lr * db # 更新偏置
return w, b
# 训练模型,并记录每轮的训练误差和测试误差
epochs = 20 # 训练轮数
lr = 0.01 # 学习率
train_loss_list = [] # 训练误差列表
test_loss_list = [] # 测试误差列表
for epoch in range(epochs):
# 划分训练集和测试集(8:2)
train_index = np.random.choice(100, size=80, replace=False)
test_index = np.setdiff1d(np.arange(100), train_index)
x_train, y_train = x[train_index], y[train_index]
x_test, y_test = x[test_index], y[test_index]
# 梯度下降更新参数,并计算训练误差和测试误差
w, b = gradient_descent(x_train, y_train, w, b, lr)
train_loss = loss(y_train, w * x_train + b)
test_loss = loss(y_test, w * x_test + b)
# 打印结果,并将误差添加到列表中
print(f"Epoch {epoch+1}, Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}")
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
# 创建一个图形对象,并设置大小为8*6英寸
plt.figure(figsize=(8,6))
# 在图形对象中创建一个子图,并设置位置为1行1列的第1个
plt.subplot(1, 1, 1)
# 在子图中绘制训练误差和测试误差曲线,使用不同的颜色和标签
plt.plot(np.arange(epochs), train_loss_list, "r", label="Train Loss")
plt.plot(np.arange(epochs), test_loss_list, "b", label="Test Loss")
# 添加图例、坐标轴标签和标题
plt.legend()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Linear Regression Loss Curve")
# 保存或显示图形
#plt.savefig("loss_curve.png")
plt.show()
运行后,可以看到如下的图形:
参考:: PyTorch官方网站