时效准确率提升之承运商路由网络挖掘 | 得物技术
1引子
履约时长是电商的生命线,直接关系到用户的消费体验。新华网[5]2022年双十一的报告显示,37.4%的受访者希望次日达,29.91%希望当日达。相较于其他物品,受访者对手机、电脑、数码产品的物流时效要求更高,更希望当日或1-2天内能收到货。
得物履约场景中,主要的阶段包括仓库内生产和第三方承运商配送。在用户支付时,得物会根据仓库的生产情况和运配资源,给用户一个承诺时效。
1.1 为什么要预测承运商的线路时效
在履约过程中,得物需要监控订单的流转,及时的发现可能超时的订单(与和用户承诺时效相比),这里包含仓库生产的监控和三方配送的监控。在实际过程中我们发现:配送节点发生变更时,承运商给的预测偏保守的。下面例子中,到了营业部承运商才给到比较精准的预计送达时间,故在分拣中心使用承运商的预计送达时间容易出现误报。
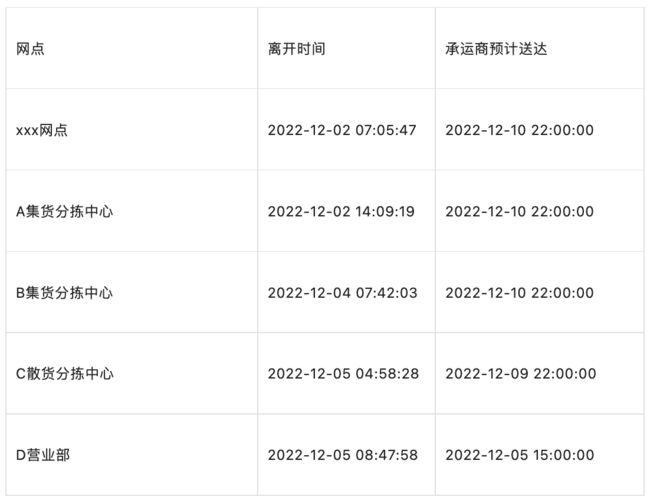
下图是承运商接口返回的预计送达时效的宽松指数,可以看到在接近目的地时,承诺时效才比较准确。
2承运商网络是如何运作的
在构建承运商网络之前,需要先了解承运商网络是如何工作的。下面是从A网点到E网点的配送示意图,分为以下内容:
(1)节点,包含的揽收和派送网点以及分拣中心。
(2)线路,包括干线和支线。例如从网点到分拣中心属于支线,从分拣中心到分拣中心属于干线。
(3)班次:承运商为了平衡成本和时效,会设置生产班次。到分拣中心之后,需要根据目的地进行分拣,当到达一定量的货物之后,会从分拣中心出发,前往下一个节点。承运商在设置班次的时候,会考虑单量,兼顾运输的成本以及时效。
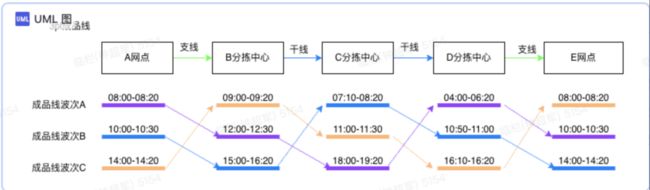
上图中:以紫色为例,在A网点,早上8点截单,即8点之前交接给承运商的货物,会在8点20左右完成封车,然后从网点出发,前往B分拣中心,到达B分拣中心的时间是11点40,这个时候赶上了B分拣中心截单时间为12点的班次,B分拣中心会在12:30完成分拣并前往下一个分拣中心,以此类推完成整个配送过程。
在构建承运商的网络时,需要进行建模。除了节点、线路和班次之外,核心还包括以下两个模型:
(5)成品线,即从A网点到E网点经过所有节点。上图中:A网点-B分拣中心-C分拣中心-D分拣中心-E网点构成了一条成品线。
(6)成品线波次:因为节点存在波次,所以成品线也存在波次,实际上成品线波次和第一个节点的波次数一样。
3如何构建承运商网络
在了解承运商网络如何工作后,需要着手构建承运商的网络。承运商回将轨迹信息推送到得物,内容类似以下的文本。
[
{
"code":"180",
"desc":"快件到达【xxx营业部】",
"location":{
"city":"xxx市",
"district":"xxx县",
"point":{
"latitude":xxx,
"longitude":xxx
},
"province":"xxx"
},
"node":"已揽收",
"opeTitle":"站点装箱",
"time":"2022-09-04 17:29:27"
},
{
"code":"xxx",
"desc":"收取快件",
"location":{
"city":"xxx",
"district":"xxx",
"point":{
"latitude":28.65,
"longitude":120.07
},
"province":"xx"
},
"node":"已揽收",
"opeTitle":"配送员完成揽收",
"time":"2022-09-04 17:29:27"
}
]
3.1 结构化清洗
轨迹的文本,需要经过结构化的清洗之后,才能获取轨迹的含义。对于每一个运单,它的轨迹会经过很多个节点,而每个节点的数据类型如下:
1. waybill_no 表示运单号,同一个运单号会有多条节点记录
2. station_index 表示当前这个节点的下标
3. station_enum 表示这个节点的类型,是分拣中心还是揽派网点
4. station_name 表示节点的名称,例如上面例子里的xxx营业部
5. station_status 表示这个节点的状态,例如是进入还是离开
6. operate_time 表示当前节点的操作时间
3.2 轨迹里面是否真的有班次信息
承运商网络工作原理提到了承运商会按班次进行生产,从轨迹的结果里面是否能找到班次生产的证据呢。通过分析,我们猜想:相同流向(例如从A分拣中心开往B分拣中心)离开某个分拣中心(例如离开A分拣中心)的时间应该是相对集中的。
实时上通过一些简单的聚类方法,证实了我们的猜想。下面图中,横轴表示的是出分拣中心的小时,每一个点表示历史上的某一个运单,纵轴没有业务含义,只是为了方便显示。

绘制上述图时使用的是kmeans聚类算法,kmeans聚类算法需要指定聚类的个数。故需要使用Knee/Elbow 这类的算法进行聚类数检测,同时它对异常值敏感,故在实现时最终使用的DBSCAN。

3.3 聚类参数该如何选取
DBSCAN虽然不需要指定聚类的个数,但是需要指定点之间的距离以及点的密度,通过反复调整,最终确定这两个核心的参数如下:
clustering = DBSCAN(eps=0.25, min_samples=max(5, int(x.size * 0.02)), metric=metric).fit(x_after_reshape)
其中eps为0.25,即15分钟。点密度为5和总数的2%的最大值。
3.4 如何解决跨天的问题
从上面聚类图看,同一个波次的点可能出现跨天的情况,即有些点出分拨中心的时间可能是23:50,有些分拨中心的点可能是00:10。这两个点的欧式距离比较大,故需要重写距离的metrics函数。
ret = abs(x[0] - y[0])
if ret > 12:
ret = abs(24 - ret)
return ret
3.5 线路是如何串联的
分析节点的生产班次和线路的班次是不够的,还需要将它们进行串联,得到成品线班次,这样才能在售前或者售中进行应用。这里在处理的时候进行了一些简化,一方面是分拣中心的分拣波次是没有办法识别到的,另外一方面其实可以不用关注分拣中心的分拣波次。
实际上,串联成品线班次的过程是这样的:
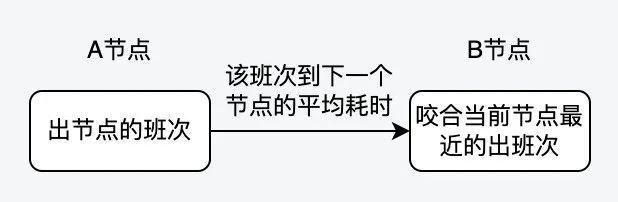
核心的代码如下:
List
next = tmp.getResourceList().get(i)
.getWaveList();
next.sort(Comparator.comparing(NetworkResourceWaveDTO::getOffTime));
boolean match = false;
for (NetworkResourceWaveDTO nextWave : next) {
if (nextWave.getOffTime() > p.getEndTime()) {
match = true;
duration += nextWave.getDurationDay();
p = nextWave;
break;
}
}
if (!match) {
duration += next.get(0).getDurationDay() + 1;
p = next.get(0);
}
productLineWave.add(p);
}
3.6 四级地址与揽派网点的关系是如何建立的
从应用的角度,输入条件是买家的四级地址,但承运商网络的终点是派送站点,故需要建立承运商派送站点和四级地址的映射关系。映射关系的建立比较简单,取过去一段时间负责派送该四级地址的站点中,派送该地址单量最多的那个。
4工程落地的挑战
Part 3更像是一个理论家的滔滔不绝,那如何在工程上进行落地呢?这里面包含了ODPS SQL的开发、UDF的开发以及DDD,总之需要十八般武艺。
4.1 如何在ODPS进行简单的机器学习
在班次分析的过程中,使用到DBSCAN的聚类算法。如果在odps上使用这些算法呢?实际上python里面已经实现了DBSCAN算法,而odps支持使用python编写UDF。只是目前odps的运行环境并没有安装DBSCAN相关的包,故需要手动进行安装,安装的教程可以参考阿里云的官方文档
4.2 在线服务化的问题
上述清洗过程需要每天或者至少一周运行一次,选取过去一个时间窗口的数据进行训练,得到承运商的网络,这样才能及时的感知承运商网络的变化。这意味着会定时的更新成品线、成品线波次以及节点波次的信息,在在线服务化的过程中,我们是直接将数据这些数据存放在redis里面。为了不占用太多的内存,通过使用hash数据结构对内存进行了一些优化,当然hash的一个缺点是无法为field设置超时时间,这意味着某个key的某个field数据实际已经是过期数据了,但是它不会被删除,进而造成泄漏,但这种泄漏可以通过其他技术手段解决。
5进展与规划
目前我们已经构建了第三方承运商网络,首网点预测的准确率在65%左右,末分拣预测的准确率在85%左右。未来持续优化点包括:班次聚合(对于一些数据比较稀疏线路,需要做班次的聚合)、时间衰减(清洗数据需要选取过去一段时间的数据,对于太久远的数据,应该进行衰减,使得它在结果中的贡献小一些)等,相信准确率能有进一步提升。
6参考文献
[1]. Knee/Elbow Point Detection
[2]. arvkevi/kneed
[3].https://datascience.stackexchange.com/questions/46106/kmeans-vs-dbscan
[4]. https://redis.io/docs/management/optimization/memory-optimization/
[5]. 用户调研:今年11.11消费者最关注“确定性” 京东是八成用户首选-新华每日电讯