hadoop--伪分布式部署
文章目录
-
- 1.资料下载
- 2.大数据介绍
-
- 2.1什么是大数据?
- 2.2为什么要学习大数据?
- 2.3大数据相关技术
- 2.4海量数据存储
- 2.5海量数据清洗
- 2.6海量数据处理
- 3.集群环境准备
-
- 3.1准备虚拟机
- 3.2修改为静态IP
- 3.3配置文件
- 3.4配置文件内容
- 3.5重启网络
- 3.6查看IP
- 3.7mobaxTerm的使用
- 3.8关闭防火墙
- 3.9修改主机名
- 3.10修改hosts文件
- 3.11三台机器重启
- 3.12设置免密登录
-
- 3.12.1三台机器生成公钥与私钥
- 3.12.2拷贝公钥到同一台机器
- 3.12.3复制第一台机器的认证到其他机器
- 3.12.4测试
- 3.13三台机器时钟同步
- 3.14三台机器安装jdk
- 3.14修改windows中的hosts文件
- 4.Hadoop介绍
-
- 4.1hadoop的核心组件
- 4.2hadoop的介绍及发展历史
- 4.3 hadoop的历史版本介绍
- 4.4 hadoop2.x架构模型
- 4.5Hadoop 的安装有三种方式
- 4.6 伪分布式部署
-
- 4.6.1进入目录
- 4.6.2上传安装包并解压
- 4.6.3修改配置文件
- 4.6.4.修改hadoop-env.sh
- 4.6.5.修改 core-site.xml
- 4.6.6.修改 hdfs-site.xml
- 4.6.7.修改 mapred-site.xml
- 4.6.8.修改 yarn-site.xml
- 4.6.9.修改slaves
- 4.6.10.配置hadoop的环境变量
- 4.7启动
-
- 4.7.1.初始化
- 4.7.2.启动
- 4.7.3.停止
- 4.7.4.测试
- 4.7.5.停止服务
- 4.7.6.访问浏览器
- 4.8.如果没有安装成功
1.资料下载
https://pan.baidu.com/s/1N2MZEvKxnsBjz6rh0Xkpmw
提取码:44u3
2.大数据介绍

2.1什么是大数据?
简单来说大数据就是海量数据及其处理。
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产(资源)。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》 [2] 中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。——摘自百度百科
2.2为什么要学习大数据?
拓宽发展面
大数据已经成为基础技术,现在最火的人工智能,物联网等就建立在大数据的基础上。
面向面试,提高认知深度,拓宽知识广度,增加面试筹码,提高薪资。
2.3大数据相关技术
海量数据获取
爬虫(分析别人家的事):Python,java…
日志(分析自己的事):log4j、flume(数据的收集聚集加载)
历史数据(分析以前的事):mysql、oracle、ETL(数据的提取转化加载)hdfs、
实时数据(分析现在的事):hbase、spark、flink
2.4海量数据存储
HDFS(Hive、Hbase、Spark依赖存储都是HDFS)Hadoop distributed file system
S3(亚马逊)
NFS(sun公司)
2.5海量数据清洗
数据清洗没有我们想的那么复杂,方式有很多:
过程中可以用代码直接清洗,flume可以清洗,Hive可以清洗,flink可以清洗。整个流程中几乎每个步骤都可以做到数据的清洗。
2.6海量数据处理
离线数据处理:MapReduce(hadoop的一部分)、Hive(底层是MR,业界主流)、SparkSQL、FlinkDataSet
流式数据处理:Flink(全面高效)、Storm(速度快,亚秒级)、SparkStreaming(速度没有Storm快,但是吞吐量高)
3.集群环境准备
3.1准备虚拟机
克隆三个虚拟机hadoop01、hadoop02、hadoop03均为NAT模式,其中hadoop01内存设置为1G(16G内存以上建议设置为2G),hadoop02和hadoop03为512M。
注:虚拟机登录的用户名和密码都是root

3.2修改为静态IP
修改IP地址,将:
第一台hadoop01的虚拟机ip地址改为:192.168.65.101
第二台hadoop02的虚拟机ip地址改为:192.168.65.102
第三台hadoop03的虚拟机ip地址改为:192.168.65.103
3.3配置文件
cd /etc/sysconfig/network-scripts #进入网络配置目录
dir ifcfg* #找到网卡配置文件
ifcfg-ens33 #找到版本最新的文件并修改
vim ifcfg-ens33
或者
vim /etc/sysconfig/network-scripts/ifcfg-ens33
3.4配置文件内容
注意不要写注释部分
TYPE=Ethernet
BOOTPROTO=static #改成static,针对NAT
NAME=eno16777736
UUID=4cc9c89b-cf9e-4847-b9ea-ac713baf4cc8
DEVICE=eno16777736
DNS1=114.114.114.114 #和网关相同
ONBOOT=yes #开机启动此网卡
IPADDR=192.168.65.101 #固定IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.65.2 #网关和NAT自动配置的相同,不同则无法登录
3.5重启网络
以下两种方式任选其一
service network restart #重启网络
systemctl restart network.service #重启网络centos7
3.6查看IP
ip addr #查看IP地址 ip add
3.7mobaxTerm的使用
登录成功后,弹出对话框点yes 保存密码。
补充:mobaxTerm远程连接慢的问题
在使用shell连接虚拟机时连接等待时间太长,ssh的服务端在连接时会自动检测dns环境是否一致导致的,修改为不检测即可。
1、打开sshd服务的配置文件
vim /etc/ssh/sshd_config
把UseDNS yes改为UseDNS no(如果没有,自行编写在文件末尾加入)
2、重启sshd服务
systemctl restart sshd.service 或者 /etc/init.d/sshd restart
3.8关闭防火墙
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开启启动
systemctl restart firewalld.service #重启防火墙使配置生效
systemctl enable firewalld.service #设置防火墙开机启动
检查防火墙状态
[root@hadoop01 ~]# firewall-cmd --state #检查防火墙状态
false #返回值,未运行
3.9修改主机名
vi /etc/hostname
3.10修改hosts文件
vi /etc/hosts
在配置文件中增加ip地址映射
192.168.65.101 hadoop01
192.168.65.102 hadoop02
192.168.65.103 hadoop03
3.11三台机器重启
reboot
3.12设置免密登录
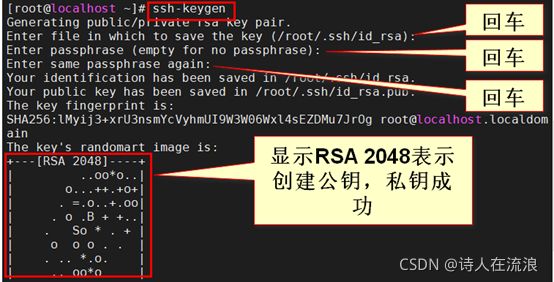
3.12.1三台机器生成公钥与私钥
ssh-keygen
执行该命令之后,按下三个回车即可
3.12.2拷贝公钥到同一台机器
三台机器执行命令:
ssh-copy-id hadoop01
3.12.3复制第一台机器的认证到其他机器
将第一台机器的公钥拷贝到其他机器上
在第一台机器上面执行以下命令
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh
3.12.4测试
在hadoop01上进行远程登录测试
ssh hadoop02
不需要输入密码直接进入说明成功,exit退出
3.13三台机器时钟同步
通过网络进行时钟同步
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
ntpdate us.pool.ntp.org;
阿里云时钟同步服务器
ntpdate ntp4.aliyun.com
三台机器定时任务
crontab -e
*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org;
或者直接与阿里云服务器进行时钟同步
crontab -e
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
3.14三台机器安装jdk
查看自带的openjdk
rpm -qa | grep java
如果有,请卸载系统自带的openjdk,方式如下(注:目前系统已经卸载)
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodeps
三台机器创建目录
所有软件的安装路径
mkdir -p /opt/servers
所有软件压缩包的存放路径
mkdir -p /opt/softwares
上传jdk到/export/softwares路径下去,并解压
tar -xvzf jdk-8u65-linux-x64.tar.gz -C ../servers/
配置环境变量
vim /etc/profile
export JAVA_HOME=/opt/servers/jdk1.8.0_65
export PATH=:$JAVA_HOME/bin:$PATH
修改完成之后记得 source /etc/profile生效
source /etc/profile
发送文件到hadoop02和hadoop03
scp -r /opt/servers/jdk1.8.0_65/ hadoop02:/opt/servers/
scp -r /opt/servers/jdk1.8.0_65/ hadoop03:/opt/servers/
注意:发送完成后要配置环境变量并生效。
测试
java -version
出现JDK版本号即为成功。
3.14修改windows中的hosts文件
在windows中的hosts文件里添加如下映射
192.168.65.101 hadoop01
4.Hadoop介绍
hadoop的定义:hadoop是一个分布式存储和分布式计算的框架。
4.1hadoop的核心组件
HDFS:分布式存储框架
MapReduce:分布式计算框架
Yarn:资源调度管理器
4.2hadoop的介绍及发展历史
- Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。 - Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
狭义上来说,hadoop就是单独指代hadoop这个软件,
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件。
4.3 hadoop的历史版本介绍
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
3.x版本系列:基于2.x的版本进行多层优化(新特性),主要的是改变MapReduce的数据计算方式。

4.4 hadoop2.x架构模型
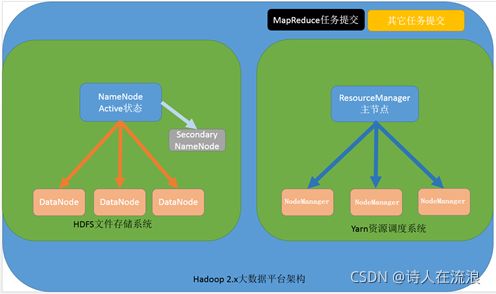
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种元数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务
4.5Hadoop 的安装有三种方式
单机模式:直接解压,只支持MapReduce的测试,不支持HDFS,一般不用。
伪分布式模式:单机通过多进程模拟集群方式安装,支持Hadoop所有功能。
优点:功能完整。
缺点:性能低下。学习测试用。
完全分布式模式:集群方式安装,生产级别。
HA:高可用。
4.6 伪分布式部署
需要环境:
JDK,JAVA_HOME,配置hosts,关闭防火墙,配置免密登录等。
注意:我们只将其安装在hadoop01节点上。
4.6.1进入目录
cd /opt/servers
4.6.2上传安装包并解压
tar -xvzf hadoop-2.7.7.tar.gz -C ../servers/
4.6.3修改配置文件
位置:/opt/servers/hadoop-2.7.7/etc/hadoop
4.6.4.修改hadoop-env.sh
vim /opt/servers/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
修改
export JAVA_HOME=/opt/servers/jdk1.8.0_65
export HADOOP_CONF_DIR=/opt/servers/hadoop-2.7.7/etc/hadoop
4.6.5.修改 core-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/core-site.xml
增加namenode配置、文件存储位置配置:粘贴代码部分到标签内
<property>
<name>fs.default.namename>
<value>hdfs://hadoop01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/servers/hadoop-2.7.7/tmpvalue>
property>
4.6.6.修改 hdfs-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
- 配置包括自身在内的备份副本数量到标签内
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
4.6.7.修改 mapred-site.xml
说明:在/opt/servers/hadoop-2.7.7/etc/hadoop的目录下,只有一个mapred-site.xml.template文件,复制一个。
cp mapred-site.xml.template mapred-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/mapred-site.xml
配置mapreduce运行在yarn上:粘贴高亮部分到标签内
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
4.6.8.修改 yarn-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/yarn-site.xml
- 配置:粘贴高亮部分到标签内
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
4.6.9.修改slaves
vim /opt/servers/hadoop-2.7.7/etc/hadoop/slaves
修改
hadoop01
4.6.10.配置hadoop的环境变量
vim /etc/profile
export HADOOP_HOME=/opt/servers/hadoop-2.7.7
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
环境变量配置完成,测试环境变量是否生效
echo $HADOOP_HOME
4.7启动
4.7.1.初始化
hdfs namenode -format
4.7.2.启动
start-all.sh
4.7.3.停止
stop-all.sh
4.7.4.测试
jps
4.7.5.停止服务
stop-all.sh
4.7.6.访问浏览器
windows的浏览器中访问hadoop01:50070

安装成功!
4.8.如果没有安装成功
如果没有成功(进程数不够)
1.stop-all.sh 停掉hadoop所有进程
2.删掉hadoop2.7.7下的tmp文件
3.hdfs namenode -format 重新初始化(出现successfully证明成功),如果配置文件报错,安装报错信息修改相应位置后重新执行第二步。
4.start-all.sh 启动hadoop