数据结构与算法 学习笔记(陈越)
数据机构c语言版本-陈越笔记
- 第一章(数据结构和算法)
-
- 数据结构
- 算法
- 第二章
-
- 线性表
- 堆栈
- 队列
- 多项式问题
- 第三章
-
- 树与树的表示
- 二叉树及存储结构
- 二叉树的遍历
- 小白专场
- 第四章
-
- 二叉搜索树
- 平衡二叉树
- 小白专场
- 习题选讲
- 第五章
-
- 堆
- 哈弗曼树
- 集合及运算
- 小白专场1
- 小白专场2
- 第六章
-
- 图的定义
- 图的遍历
- 例
- 邻接矩阵表示的图
- 用邻接表表示的图
- 第七章
-
- Tree Traversals Again
- Complete Binary Search Tree
- Huffman Codes
- 最短路径问题
- 小白专场
- 第八章
-
- 最小生成树问题
- 拓扑排序
- 图习题
- 第九章
-
- 简单排序
- 希尔排序
- 堆排序和选择排序
- 归并排序
- 第十章
-
- 快排
- 表排
- 基数排
- 排序的比较
- 第十一章
-
- 散列表
- 散列函数构建
- 冲突处理方法
- 散列表性能分析
- 文件中单词词频统计
- 小白专场
- 第十二章
-
- 习题选讲
- 串的模式选讲
第一章(数据结构和算法)
数据结构
- 官方定义-没有统一
解决问题的方法效率,跟数据的组织方式有关
- 空间的使用
解决问题的方法效率,跟空间的利用率有关 - 算法的效率
解决问题的方法效率,跟算法的巧妙程度有关 - 抽象数据类型

算法
- 定义
1.一个有限指令集
2.接收一些输入
3.产生输出
4.在一定有限步骤后结束
5.每一条指令必须有充分明确的目标,不可以有歧义,在计算机处理范围内,描述不依赖于任何一种计算机语言以及具体的实现手段 - 算法的好坏
时间复杂度S(n)和空间复杂度T(n)
最坏情况复杂度T worst (n)
平均复杂度T avg (n)
Tworst(n)>=Tavg(n - 复杂度分析
复杂度分析的一些小窍门

第二章
线性表
- 多项式表示
- 顺序储存结构直接表示

- 顺序储存结构表示非零项
每个多项式可以看成系数和指数二元组的集合 - 链式结构储存非零项
链表中每个节点储存一个非零项,每个节点包括两个数据域和一个指针域
| coef | expon | link |
typedef struct PolyNode *Polynomial;
struct PolyNode
{
int cofe;
int expon;
Polynomial link;
};
链表的储存形式为:

- 线性表顺序储存
线性表是由同类型数据元素构成有序序列的线性集合
- 表中元素个数成为线性表的长度
- 表中若无元素,称之为空表
- 表中的起始位置称为表头,结束位置称为表尾
线性表的抽象数据类型描述
线性表利用数组连续存储空间的顺序存放线性表的各元素
typedef struct LNode*List;
struct LNode
{
ElementType Data[Maxsize];
int Last;
};
struct LNode L;
List Ptrl;
访问下表为i的元素方法为:L.Data[i]或者PtrL->Data[i]
线性表的长度为L.last+1或者PtrL->Last+1
- 初始化
List MakeEmpty()
{
List PtrL;
PtrL=(List)malloc(sizeof(struct LNode));
PtrL->Last = -1;
return PtrL;
}
- 查找
int Find(ElementType X, List PtrL)
{
int i = 0;
while (i <= PtrL->Last && PtrL.Data[i] != X)
i++;
if(i>PtrL->Last)return -1;
else return i;
}
//时间复杂度为O(n)
- 顺序储存的插入和删除
- 插入(在i的位置上插入一个值为X的元素(1<=i<=n+1)
先移动再插入
void Insert(ElementType X, int i, List PtrL)
{
int j;
if(PtrL->Last==MAXSIZE-1)
{
printf("该表已满");
return;
}
if(i>=PtrL->Last+2||i<1)
{
printf("位置不合法");
return;
}
for(j = PtrL->Last; j >= i-1; j --)
PtrL->Data[j+1] = PtrL->Data[j];
//将第i个元素插入
//因为下标从0开始所以为i-1
PtrL->Data[i-1] = X;
//因为整体向后移动,要使Last+1继续指向最后一个元素
PtrL->Last++;
}
- 删除操作(删除第i个元素)
后面元素依次向前移动
void Delete(int i ,List PtrL)
{
int j;
//检查i位置是否合法
if(i>=PtrL+2||i<1)
{
printf("不存在第%d个元素",i);
return;
}
for( j = i; j <= PtrL->Last; j ++)
PtrL->Data[j-1]=PtrL->Data[j];
//更新Last
PtrL->Last--;
return;
}
- 链式储存和查找
链式储存解决了线性整体移动的问题,不要求逻辑上相邻的两个元素物理上也相邻,通过链建立数据元素之间的逻辑关系
- 插入删除不需要移动数据元素,只需要修改“链”
typedef struct LNode *List;
struct LNode
{
ElementType Data;
List Next;
};
struct LNode L;
List PtrL;
//在这里注意与顺序存储的区别
- 求表长
int Length(List PtrL)
{
//令p指向表的第一个节点
List p = PtrL;
int j;
while(j)
{
p = p->Next;
j++;
}
return j;
//返回的j即为表的长度
}
- 查找
- 按序号查找
List Findkth( int k, List PtrL)
{
List p = PtrL;
int i = 1;
while(p!=NULL&&i<k)
{
p=p->Next;
i++;
}
if(i==k)return i;
else return NULL;
}
- 按值查找
List Find( ElementType X, List PtrL)
{
List p = PtrL;
while(p!=NULL&&p->Next!=X)
p = p->Next;
return p;
}
- 链式储存的插入和删除
- 插入操作(在第i个结点位置上插入一个值为X的新结点,换句话说就是在第i-1个结点后插入一个值为X的新节点)
- 构造一个新结点用s指
- 找到链表的第i-1个结点,用p指
- 修改指针

List Insert(ElementType X, int i, List PtrL)
{
list p,s;
if(i==1)
{
s=(List)malloc(sizeof(struct LNode));
s->Data = X;
s->Next = PtrL;
return s;
}
//此处查找的节点为i-1
p = Findkth(i-1,PtrL);
//该结点不存在
if(p==NULL)
{
printf("参数出错");
return NULL;
}
//申请新的结点
else
{
s=(List)malloc(sizeof(struct LNode));
s->Data = X;
s->Next = p->Next;
p->Next = s;
return PtrL;
}
//将第i个结点插在i-1个结点的后面
- 删除操作(删除第i个结点)(1<=i<=n)
- 先找到第i-1个结点,用p指向
- 然后用s指针指向第i个结点,即为p结点的下一个结点
- 修改指针,删除s所指向的结点
- 最后释放s所指向结点的空间free

List Delete(int i,List PtrL)
{
List p,s;
//删除结点分为删除头结点和第i个结点
if(i==1)
{
s = PtrL;
if(PtrL!=NULL)
PtrL = PtrL->Next;
else return NULL;
free(s);
return PtrL;
}
p = Findkth(i-1,PtrL);
//查找i-1个结点和i个结点
if(p==NULL)
{
printf("第%d个结点不存在",i-1);
return NULL:
}
else if (p->Next==NULL)
{
printf("第%d个结点不存在",i);
return NULL;
}
else
{
s=p->Next;//s指向i
p->Next=s->Next;//删除操作
free(s);
return PtrL;
}
-
广义表和多重链表
一元多项式可以用上述式子表示,二元多项式又该如何表示?可以用“复杂”链表表示
- 广义表是线性表的推广
- 对于线性表来说,n个元素都是基本的单元素
- 广义表中,这些元素不仅是单元素也可以是另一个广义表
typedef struct GNode*GList;
struct GNode
{
int Tag;//标志域,0表示结点是单元素,1表示结点是广义表
union
{
ElementType Data;
GList Sublist;
}URegion;
//这里数据域Data(单元素)和指针域Sublist复用,共用存储空间
GList Next;//指向后继结点
};
-
多重链表
多重链表中的结点属于多个链多重链表中的结点指针域有很多, 但是包含两个指针域的链表并不一定是多重链表, 比如双向链表不是多重链表 多重链表可以用在树和图中实现存储
堆栈
- 什么是堆栈
中缀表达式:运算符位于两个数字之间
后缀表达式:运算符位于两个数字之后
堆栈是具有一定操作约束的线性表,只在一端做插入,删除
Last In First Out(LIFO)后入先出
抽象数据类型

原理图

- 堆栈的顺序存储
栈的顺序存储结构通常是由一个一维数组和一个记录栈顶元素位置的变量组成#define Maxsize<存储数据元素的最大值> typedef struct SNode *Stack struct SNode { ElementType Data[Maxsize]; int Top; };
- 入栈
void Push(Stack PtrL,ElementType item)
{
if(PtrL->Top==Maxsize-1)
{
printf("堆栈满");
return;
}
else
{
PtrL->Data[++(PtrL->Top)] = item;
return;
}
}
- 出栈
ElementType Pop(Stack PtrL)
{
if(PtrL->Top==-1)
{
printf("堆栈空");
return ERROR;
}
else
return (PtrL->Data[(PtrL->Top)--]);
}
-
用数组实现两个堆栈,最大利用数组空间,若有空间则可以实现入栈
两个栈分别从数组的两头开始向中间生长,当两个栈的栈顶指针相遇时,表示两个栈都已经满
#define MaxSize <存储数据元素的最大个数>
struct DoubleStack{
ElementType Data[MaxSize];
int Top1;
int Top2;
//其中top1和top2两个指针
}S;
S.Top1=-1;
S.Top2=MaxSize;
}
void Push(struct DoubleStack *PtrS,ElementType item,int Tag)
{
if(PtrS->Top2-PtrS->Top1 == 1)
{
printf("堆栈满");
return;
}
if(Tag==1)
PtrS->Data[++(PtrS->Top1)] = item;
else
PtrS->Data[--(PtrS->Top2)] =item;
}
ElementType Pop(struct DoubleStack *PtrS, int Tag)
{
if(Tag==1)
{
if(PtrS->Top1 == -1)
{
printf("堆栈1空");
return NULL;
}
else return PtrS->Data[(PtrS->Top1)--];
}
else
{
if(PtrS->Top2 == Maxsize)
{
printf("堆栈空");
return NULL;
}
else return PtrS->Data[(PtrS->Top2)++];
}
}
- 堆栈的链式存储
- 链式存储结构实际上就是一个单链表,叫做链栈,插入和删除操作只能在链栈的栈顶进行
typedef struct SNode *Stack;
struct SNode
{
ElementType Data;
struct SNode *Next;
};
- 初始化
Stack CreatStack()
{
Stack s;
s = (Stack)malloc (sizeof(struct SNode));
s->Next = NULL;
return s;
}
- 判断堆栈s是否为空
int Empty(Stack s)
{
return (s->Next == NULL);
}
- 入栈
void Push(ElementType item,Stack s)
{
struct SNode *Temcell;
Tmpcell = (struct *SNode)malloc(sizeof (struct SNode));
Tmpcell->Element = item;//赋值
Tmpcell->Next = s->Next;
s->Next = Tmpcell;
}
- 出栈
ElementType Pop(Stack s)
{
struct SNode *Firstcell;
ElementType TopElement;
if(Empty(s))
{
printf("堆栈空");
return NULL;
}
else
{
//Firstcell是删除的元素,TopElement是栈顶元素
Firstcell = s-Next;
s->Next = Firstcell->Next;
TopElement = Firstcell->Element;
free(Firstcell);
return TopElement;
}
}
- 堆栈的应用
中缀表达式转换为后缀表达式
- 运算数:直接输出
- 左括号:入栈
- 右括号:栈顶元素出栈并输出,直到遇到左括号
- 运算符:优先级大于栈顶运算符,入栈;优先级小于等于栈顶运算符出栈输出,继续比较新的栈顶运算符
- 处理完毕后,将堆栈剩余元素一并输出
队列
- 队列及顺序存储
具有一定操作约束的线性表
-
插入和删除操作:只能在一端插入,而在另一端删除
数据插入:入队列
数据删除:出队列
先进先出(FIFO)First In First Out -
抽象数据描述

-
队列存储的实现
队列的顺序存储结构通常由一个一维数组和一个记录队列头元素位置的变量ront以及一个记录队列尾元素位置的变量rear组成
#define Maxsize<数据元素的最大个数>
struct QNode{
ElementType Data[Maxsize];
int rear;
int front;
};
typedef struct QNode *Queue;
//front 指的是第一个元素之前的位置
在顺环队列判断是否满的问题上使用额外标记Tag域或者Size
- 入队
void AddQ(Queue PtrL,ElementType item)
{
if(PtrQ->rear+1)%Maxsize ==PtrQ->front)
{
printf("队列满");
return;
}
PtrQ->rear = (PtrQ->rear+1)%Maxsize;
PtrQ->Data[PtrQ->rear]=item;
}
- 出队
ElementType DQ(Queue PtrQ)
{
if(PtrQ->rear==PtrQ->front)
{
printf("队列空");
return ERROR;
}
else
{
PtrQ->front = (PtrQ->front+1)%Maxsize;
return PtrQ->Data[PtrQ->front];
}
}
- 队列的链式存储
struct Node{
ElementType Data;
struct Node *Next;
};
struct QNode{
struct Node *rear;
struct Node *front;
};
typedef struct QNode *Queue;
Queue PtrQ;
- 出队
ElementType DQ(Queue PtrQ)
{
struct Node *Frontcell;
ElementType Frontelement;
if(PtrQ->front==NULL)
{
printf("空");
return ERROR;
}
Frontcell = PtrQ->front;
//分情况讨论,队列只有一个元素和多个元素
if(PtrQ->front == PtrQ->rear)
PtrQ->front=PtrQ->rear=NULL;
else
PtrQ->front = PtrQ->front->Next;
Frontelement = Frontcell->Data;
free(Frontcell);
return Frontelement;
}
多项式问题
- 加法运算的实现
采用不带头结点的单项链表。按照指数递减的顺序排列各项
struct PolyNode{
int coef;//系数
int expon;//指数
struct PolyNode *link;
};
typedef struct PolyNode *Polynomial;
Polynomial P1,P2;
- 算法思路
- P1->expon==P2->expon:系数相加,若结果不为0,则作为结果多项式对应系数。同时,P1和P2 都指向下一项
- P1->expon>P2->expon将P1存入当前多项式,并使P1指向下一项
- P1->expon < P2->expon将P2存入当前多项式,并使P2指向下一项
Polynomial Polyadd(Polynomial P1,Polynomial P2)
{
Polynomial front ,rear,temp;
int sum;
rear = (Polynomial) malloc (sizeof (struct PolyNode);
front = rear;
//front这里指的是多项式链表头结点
while(P1&&P2)
{
switch (Compare(P1->expon,P2->expon))
{
case 1:
Attach(P1->coef,P1->expon,&rear);
P1 = P1->link;
break;
case-1:
Attach(P2->coef,P2->expon,&rear);
P2 = P2->link;
break;
case 0:
sum = P1->coef+P2->coef;
if(sum)Attach(sum,P1->expon,&rear);
P1 = P1->link;
P2 = P2->link;
break;
}
//还有未处理完的另一个多项式的所有结点依此复制
for(;P1;P1=P1->link)Attach(P1,P1->link,&rear);
for(;P2;P2=P2->link)Attach(P2,P2->link,&rear);
rear->link = NULL;
temp = front;
front = front->link;
free(temp);
return front;
}
}
void Attach( int c, int e, int Polynomial *pRear)
{
Polynomial P;
P = (Polynomial)malloc (sizeof (struct PolyNode));
P->coef = c;
P->expon = e;
p->link = NULL:
(*pRear)->link = P;
*pRear = P;
//修改pRear值
}
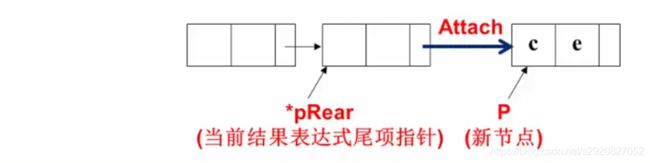

- 题意理解与多项式表示
数据结构设计typedef struct PolyNode *Polynomial; struct PolyNode { int coef; int expon; Polynomial link; }; - 程序框架及读入多项式

//ReadPoly()读入一个多项式
//Mult()两个多项式相乘
//Add()两个多项式相加
//PrintPoly()打印一个多项式
int main()
{
Polynomial P1,P2,PP,PS;
P1 = ReadPoly();
P2 = ReadPoly();
PP = Mult(P1,P2);
PrintPoly(PP);
PS = Add(P1,P2);
PrintPoly(PS);
return;
}
读取多项式
Polynomial ReadPoly()
{
Polynomial P,Rear,t;
int c,e,N;
scanf("%d",&N);
//链表头空结点
P = (Polynomial)malloc(sizeof(struct PolyNode));
P->link = NULL:
Rear = P;
while(N--)
{
scanf("%d %d",&c,&e);
Attach(c,e,&Rear);
//将当前项插入多项式尾部
}
//将删除临时生成的头结点
t = P;
P = P->link;
free(t);
return P;
}
void Attach(int c,int e,Polynomial *pRear)
{
Polynomial P;
P = (Polynomial)malloc (sizeof(struct PolyNode));
P->coef = c;
P->expon = e;
P->link = NULL;
(*pRear)->link = P;
*pRear = P;
}
- 加法乘法及多项式的输出

上面已经写过此代码
- 两个多项式相乘
Polynomial Mult(Polynomial P1, Polynomial P2)
{
Polynomial P,Rear,t1,t2,t;
int c,e;
if(!P1||!P2)return NULL;
t1 = P1;
t2 = P2;
P = (Polynomial)malloc(sizeof(struct PolyNode));
P->link = NULL:
Rear = P;
while(t2)
{ //先用P1的第一项乘以P2,得到P
Attach(t1->coef*t2->coef,t1->expon+t2->expon,&Rear);
t2=t2->link;
}
t1 = t1->link;
//两重循环,P1第一项和P2第一项相乘插入
while(t1)
{
t2= P2;Rear = P;
while(t2)
{
e = t1->expon+t2->expon;
c = t1->coef*t2->coef;
while(Rear->link&&Rear->link->expon>e)
Rear = Rear->link;
if(Rear->link&&Rear->link->expon==e)
{
if(Rear->link->coef==c)
Rear->link->coef+=c;
//else做删除操作
else
{
t = Rear->link;
Rear->link = t->link;
free(t);
}
}
//不相等就申请新的结点然后插入
else
{
t = (Polynomial)malloc(sizeof(struct PolyNode));
t->coef = c;
t->expon = e;
//插入过程
t->link = Rear->link;
Rear->link = t;
Rear = Rear->link;
}
t2 = t2->link;
}
t1 = t1->link;
}
//删除空结点
t2 = P;
P = P->link;
free(t2);
return P;
}
- 多项式输出
void PrintPoly(Polynomial P)
{
int flag = 0;
//flag用于调整输出格式
if(!P){printf("0 0\n");return;}
while(P)
{
if(!flag)flag = 1;
else
printf(" ");
printf("%d %d",P->coef,P->expon);
P = P->link;
}
}
第三章
树与树的表示
- 顺序查找
- 查找:根据给定某个关键字K,从集合R中找出关键字与K相同的记录
- 静态查找:集合中记录是固定的,没有删除和插入操作只有查找操作
- 动态查找:集合中记录是动态的,除了查找操作,还可能有删除和插入操作`
typedef struct LNode* List;
LNode struct
{
ElementType Element[Maxsize];
int length;
};
有哨兵
int SequentialSearch(List Tb1,ElementType K)
{
int i;
//建立哨兵
Tb1->Element[0] = K;
for(i = Tb1->length; Tb1->Element[i] != K; i-- )
return i;
}
无哨兵
int SequentialSearch(List Tb1,ElementType K);
{
int i;
for(i = Tb1->length; i>0 && Tb1->Element[i] != K; i--)
return i;
}
- 二分查找(Binary Search)
要求:数组连续,有序
思路:利用mid,right,left三者的比较缩小范围,查找值
left>right?查找失败:结束;
复杂度:log(n)
int BinarySearch(List Tb1, ElementType K)
{
int mid,right,left,notFound = -1;
left = 1;
right = Tb1->length;
mid = (left + right) / 2;
while(left<=right)
{
if(Tb1->ElementType[mid]>K)
return right = mid-1;
else if(Tb1->ElementType[mid]<K)
return left = mid + 1;
//查找成功返回数组下标
else return mid;
}
return notFound;
}
- 树的定义和表示
- 定义:树是由n(n>=0)个结点构成的有限集合
-
每一个树都有一个根结点(root),用r表示
-
其余结点可以分为数个互不相交的有限集合,每个集合又是一个树,称为原来树的子树
每颗树的子树互不相交,除了根结点外,每个结点只有一个父结点,每个有N个结点的树有N-1条边
树的一些基本术语:
树的度是所有结点中最大的度数,即子孩子的个数
其他自行了解
|Element|
|Firstchild|Nextsibling|
|Left|Right|
二叉树及存储结构
- 二叉树的定义和性质
定义:有穷的集合
- 集合可以为空
- 若不为空,则有左子树和右子树两个互不交叉的二叉树
性质:
- 一个二叉树第i层最大的结点数为2i-1,i>=1
- 深为k的二叉树最大的结点数为2k-1,k>=1
- 对于任意非空二叉树,n0代表叶结点个数,n2代表度数为2的非叶结点个数,那么满足n0=n2+1
- 二叉树的存储结构
- 顺序存储结构
完全二叉树:按照从上到下,从左到右的顺序存储n个节点完全二叉树的父子结点关系
- 非根结点序号为i/2
- 序号结点为i的左孩子结点的序号为2i
- 序号结点为i的右孩子结点的序号为2i+1
一般二叉树采用此种存储方法会造成空间的浪费
- 链表存储
typedef struct TreeNode* BinTree;
typedef BinTree Position;
struct TreeNode
{
ElementType Data;
BinTree Left;
BinTree Right;
};
二叉树的遍历
- 先序中序后序
- 先序
访问根结点
遍历左子树
遍历右子树
void PreorderTraversal(BinTree BT)
{
if(BT)
{
printf("%d",BT->Data);
PreorderTraversal(BT->Left);
PreorderTraversal(BT->Right);
}
}
- 中序
遍历左子树
访问根结点
遍历右子树
void InorderTraversal(BinTree BT)
{
if(BT)
{
InorderTraversal(BT->Left);
printf("%d",BT->Data);
InorderTraversal(BT->Right);
}
}
- 后序
遍历左子树
遍历右子树
访问根结点
void PostorderTraversal(BinTree BT)
{
if(BT)
{
PostorderTraversal(Left);
PostorderTraversal(Right);
printf("%d",BT->Data);
}
}
- 中序非递归
思路:利用堆栈
- 遇到一个结点就把它堆栈,然后遍历其左子树
- 遍历完左子树后将该结点弹出并访问
- 利用有指针中序遍历该结点右子树
void InorderTraversal(Bintree BT)
{
BinTree T = BT;
Stack S = CreatStack(MaxSize);
while(T||!isEmpty(S))
{
while(T)
{
Push(S,T);
T = T->Left;
}
if(!isEmpty(S))
{
Pop(S);
printf("%5d",T->Data);
T = T->Right;
}
}
}
- 层序
二叉树遍历的核心问题:二维结构遍历的线性化
从结点访问其结点左右儿子
层序基本过程:
先根结点入队
- 先从队列中取一个元素
- 访问该元素结点
- 若该元素结点为非空,则按左右指针顺序入队
void LevelOrderTraversal(BinTree BT)
{
BinTree T;
Queue Q;
//若是空树直接返回
if(!BT)return;
//初始化队列
Q = CreatQueue(MaxSize);
AddQ(Q,BT);//入队
while(!Q)
{
//访问取出队列的结点
T = DeletQ(Q);
printf("%5d",T->Data);
if(T->Left)AddQ(Q,T->left);
if(T->Right)AddQ(Q,T->Right);
}
}
- 例
求二叉树高度
递归
void InOrderTraversal(BinTree BT)
{
int Hr,Hl,Maxh;
if(BT)
{
Hl = InOrderTraversal(BT->Left);
Hr = InOrderTraversal(BT->Right);
return (Maxh+1);
}
//代表该树为空树
else return 0;
}
- 确定一颗二叉树
- 根据先序遍历第一个结点确定根结点
- 利用根结点在中序遍历序列中分出左右两个子序列
- 对左右子树分别使用递归的方法继续分解直到形成一颗二叉树
小白专场
第四章
二叉搜索树
二叉搜索树又称为二叉排序树或二叉选择树
满足以下性质:
- 二叉树可以为空
- 非空左子树所有键值小于根结点键值
- 非空右子树所有键值大于根结点键值
- 左子树和右子树都是二叉搜索树
- 查找
-
从查找跟结点开始,若根结点为空,直接返回NULL
-
若根结点不为空,根结点关键字和X进行比较
若根节点键值大于X则从左子树继续搜索 若根节点键值小于X则从右子树继续搜索 若两者相等,搜索查找完成,结束
Position Find(ElementType X,BinTree BT)
{
if(!BT)return NULL:
if (BT->Data>X)return Find(X,BT->Left);
else if (BT->Data<X)return Find(X,BT->Right);
else return BT;
//都是尾递归
}
非递归函数执行效率高,可将递归函数改为迭代函数
Position InterFind(ElementType X,BinTree BT)
{
while(BT)
{
if(BT->Data>X)BT=BT->Left;
else if (BT->Data<X)BT=BT->Right;
else return BT;
}
//树为空
return NULL;
}
- 最大元素一定在最右分支端结点上
- 最小元素一定在最左分支端结点上
//查找最小元素递归
Position FindMin(BinTree BT)
{
if(!BT)return NULL;
//找到最左结点并返回
else if(!BT->Left)return BT;
else return FindMin(BT->Left);
}
//查找最大元素迭代
Position FindMax(BinTree BT)
{
if(BT)
{
//沿右结点查找,直到最右叶结点
while(BT->Right)
BT = BT->Right;
}
return BT;
}
- 插入
方法类似find
BinTree Insert(ElementType X,BinTree BST)
{
//若该树为空,生成并返回一个结点为一的二叉树
if(!BST)
{
BST = malloc (sizeof (struct TreeNode));
BST->Data = X;
BST->Right = BST->Left =NULL;
}
else
{
if(BST->Data>X)
BST->Left = Insert(X,BST->Left);
else if(BST->Data<X)
BST->Right = Insert(X,BST->Right);
}
return BST;
}
- 删除
分三种情况
- 若删除的为叶结点,则直接删除,并将父结点指针置为NULL
- 若删除的结点只有一个孩子结点,则将父结点指向要删除结点的孩子结点
- 若要删除的结点有左右两颗子树,则用其他结点替代要删除的结点,左子树的最大元素或者右子树的最小元素
BinTree Delet(ElementType X,BinTree BST)
{
Position Tmp;
if(!BST)printf("未查找到");
else if(BST->Data>X)
BST->Left = Delete(X,BST->Left);
else if(BST->Data<X)
BST->Right = Delete(X,BST-Right);
//找到要删除的结点
else
{
//被删除的结点由左右两个子结点
if(BST->Left&&BST->Right)
{
Tmp = FindMin(BST->Right);
//用右子树最小值替代被删除结点
BST->Data = Tmp->Data;
BST->Right = Delete(BST->Data,BST->Right);
}
//被删除的结点有一个或无子结点
else
{
Tmp = BST;
//左边是空的,则把右边指针指向父亲结点
if(!BST->Left)
BST = BST->Right;
else if (!BST->Right)
BST = BST->Left;
free(Tmp);
}
}
return BST;
}
平衡二叉树
平衡因子BF(T)= hL-hR,其中hL和hR分别为左右子树高度
平衡二叉树:空树
或者任一结点左右子树高度差的绝对值不超过1
|BF(T)|<=1
给定结点树为n的avl树的最大高度为O(log2n)
平衡二叉树的调整:
RR旋转
LL旋转
LR旋转
RL旋转
判断被破坏点的位置确定旋转方向
小白专场


typedef struct TreeNode *Tree;
struct TreeNode
{
int v;
Tree Left,Right;
//作为是否被访问过的标记
int flag;
};
int main()
{
//读入N和L
//根据第一行序列建树T
//根据树T分别判别后面L个序列是否能与T形成同一搜索树并输出结果
int N,L,i;
Tree T;
scanf("%d",&N);
while(N)
{
scanf("%d",&L);
T = MakeTree(N);
for(int i = 0; i < L; i ++)
{
if(Judge(T,N))printf("Yes\n");
else printf("No\n");
//清除T中的标记flag
ResetT(T);
}
FreeTree(T);
scanf("%d",&N);
}
return 0;
}
//建立搜素树
Tree MakeTree(int N)
{
Tree T;
int i,V;
scanf("%d",&V);
T = NewNode(V);
for(int i = 1; i < N; i ++)
{
scanf("%d",&V);
T = insert(T,V);
}
return T;
}
Tree NewNode(int V)
{
Tree T = (Tree)malloc(sizeof(struct TreeNode));
T->v = V;
T->Left = T->Right = NULL;
T->flag = 0;
return T;
}
Tree Insert(Tree T,int V)
{
if(!T)T = NewNode(V);
else
{
if(V>T->v)
T->Right = Insert(T->Right,V);
else
T->Left = Insert(T->Left,V);
}
return T;
}

int check(Tree T,int V)
{
if(T->flag)
{
if(V<T->v)
return check(T->Left,V);
else if (V>T->v)
return check(T->Right,V);
else return 0;
}
else
{
if(V==T->v)
{
T->flag = 1;
return 1;
}
else return 0;
}
}
Judge 用于判别每一个整数是否一致
有bug版本
当发现一个序列的某个数与T不一致时,必须把序列后面的数字都读完,不能直接退出,否则会被认为是下一个序列
int Judge(Tree T,int N)
{
int i,V;
scanf("%d",&V);
if(V!=T->v)return 0;
else return T->flag = 1;
for(int i = 1; i < N; i ++)
{
scanf("%d",&V);
if(!check(T,V))return 0;
}
return 1;
}
修改后
int Judge(Tree T, int N)
{
//flag 0 代表目前还一致,flag 1代表已经不一致
int V,i,flag = 0;
scanf("%d",&V);
if(V!=T->v)flag = 1;
else T->flag = 1;
for(int i = 1; i < N; i ++)
{
scanf("%d",&V);
//flag不一致时没必要进行check,一致时进行check,当flag为0即一致时,check也为0设置flag为1表示刚发现矛盾,不一致
if((!flag)&&(!check(T,V)))
flag = 1;
}
if(flag)return 0;
else return 1;
}
void ResetT(Tree T)
{
if(T->Left)ResetT(T->Left);
if(T->Right)ResetT(T->Right);
T->flag = 0;
}
void FreeTree(Tree T)
{
if(T->Left)FreeTree(T->Left);
if(T->Right)FreeTree(T->Right);
free(T);
}
习题选讲
Reversing Linked List
逆转链表
在单链表前添加头结点
第五章
堆
- 优先队列:特殊的队列,取出元素的顺序时依照元素的优先权大小,而不是元素进入队列的先后顺序
优先队列的完全二叉树
- 结构性:用数组表示的完全二叉树
- 有序性:任一结点的关键字是其子树所有结点的最大值或者最小值
- 抽象数据描述

最大堆创建
typedef struct HeapStruct *MaxHeap;
struct HeapStruct {
//存储堆元素的数组
ElementType *Elements;
//堆当前元素个数
int Size;
//堆的最容量
int Capacity;
}
MaxHeap Creat(int Maxsize)
{
Maxheap H = malloc(sizeof (struct HeapStruct));
H->Elements = malloc((NaxSize+1)*sizeof (ElementType));
H->Size = 0;
H->Capacity = MaxSize;
H->Elements[0]=MaxData;
return H;
}
最大堆的插入
将新增结点插入到从父结点到跟结点的有序序列中
void insert(MaxHeap H,ElementType item)
{
int i;
if(isFull(i))
{
printf("最大堆已经满");
return;
}
i = ++ H->Size;
//i插入后处于堆最后一个位置
for(;H->Elements[i/2]<item;i/=2)
//向下过滤结点
H->Elements[i]=H->Elements[i/2];
//将item插入
H->[Elements] = item;
}
最大堆的删除
取出根结点最大值元素,同时删除堆的一个结点
ElementType DeletMax(MaxHeap H)
{
int Parent,Child;
ElementType MaxItem,temp;
if(IsEmpty(H))
{
printf("最大堆已空");
return;
}
//取出根结点最大值,用最大堆中最后一个元素从根结点开始向上过滤下层结点
MaxItem = H->Elements[1];
temp = H->Elements[H->Size--];
for(Parent = 1; Parent*2<=H->Size; Parent = child)
//for第二个条件用于判断是否由左儿子
{
//前两句用于将child指向左右儿子中大的一个
Child = Parent * 2;
//child!=H->Size用于判断是否有右儿子
//child==H->Size意味着左儿子是最后一个元素,无右儿子
if((Child!=H->Size)&&(H->Elements[Child]<H->Elements[Child+1]))
Child++;
if(temp >= H->Elements[Child])break;
else
H->Elements[Parent] = H->Elements[Child];
}
H->Elements[Parent] = temp;
return MaxItem;
}
最大堆的建立:
将已经存在的N个元素按照最大堆的要求存放在一个一维数组中
线性复杂度下建立最大堆
N个元素按线性存入,完全满足二叉树结构特性
调整各个结点的位置,以满足最大堆的有序性
哈弗曼树
例:将百分制成绩转换为五分制成绩
结点不同的查找频率可构造更加有效的生成树
- 哈夫曼树的定义
带权路径长度(WPL):设二叉树有n个叶子结点,每个叶子结点带有权值wk,从根节点到每个叶子结点的长度为lk,则每个叶子结点的带权路径长度之和为

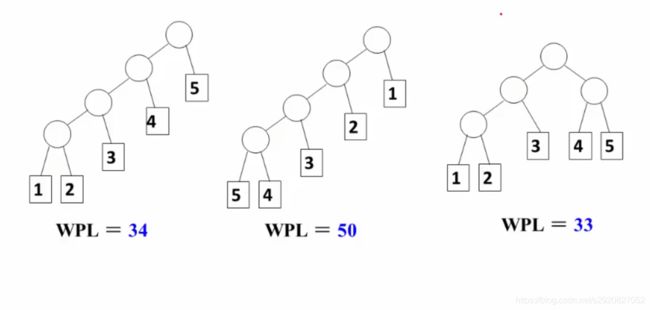
哈弗曼树在做一个问题,如何排序结点使得WPL值最小 - 哈夫曼树的构造
- 每次把权值最小的两棵树合并
typedef struct TreeNode *HuffmanTree;
struct TreeNode{
int Weight;
HuffmanTree Left,Right;
};
HuffmanTree Huffman(MinHeap H)
{
//假设H->Size个权值已经存在H->Elements[]->Weight中
int i;HuffmanTree T;
BuildMinHeap(H);
for(int i; i < H->Size; i ++)
{
//建立新结点
T= malloc(sizeof(struct TreeNode));
T->Left = DeleteMin(H);
T->Right = DeleteMin(H);
T->Weight = T->Left->Weight+T->Right->weight;
Insert(H,T);
}
T = DeleteMin(H);
return T;
//时间复杂性NlogN
}
哈夫曼树的特点:
- 没有度为一的结点
- n个叶子结点的哈夫曼树共有2n-1个结点
- 哈夫曼树任意非叶节点的左右子树交换后仍是哈夫曼树
- 哈夫曼树和哈夫曼编码
不等长编码:出现频率高的字符用的编码短些,出现频率低的字符用的编码高些
如何进行不等长编码?

编码可能出现二义性,根据二义性引出前缀码的概念:
任何字符的编码都不是另一字符编码的前缀
- 可以无义地解码
二叉树用于编码:
左右分支0,1
字符只在叶结点上


用哈夫曼树可以实现二叉树编码代价最小

集合及运算
集合可以用数组存储
typedef struct {
ElementType Data;
int Parent;
}SetType;
- 查找某个元素的集合
int Find(SetType S[],ElementType X)
{
//在数组中查找值为X的元素所属集合
//MaxSize是全局变量,为数组S的最大长度
int i;
for(int i = 0; i < MaxSize && S[i].Data != X; i ++)
if(i>=MaxSize)return -1;
for(;S[i]->Parent>=0;i = S[i].Parent);
return i;
}
- 集合的并运算
- 分别找到X1和X2两个元素所在集合的根结点
- 如果他们不同根,则将一个根结点的父结点指针设置为另一个根结点的数组下标
void Union(SetType S[],ElementType X1,ElementType X2)
{
int Root1,Root2;
Root1 = Find(S,X1);
Root2 = Find(S,X2);
if(Root1!=Root2)
S[Root2].Parent=Root1;
}
为了改善合并以后的查找性能,可以采取小的集合合并到大的集合中,可以修改union函数,即将第一个结点的Parent修改为负的元素个数,对应其绝对值即为元素个数,方便比较
小白专场1
堆中的路径


#define MAXH 1001
#define MINH -10001
int H[MAXH],size;
void Creat()
{
size = 0;
H[0] = MINH;
//因为堆下标从1开始,0下标设置为岗哨,方便后面操作
}
//岗哨使得元素在0的位置停止插入
void Insert(int X)
{
int i;
for(i = ++size; H[i/2] > X; i /= 2)
H[i] = H[i/2];
H[i] = X;
}

int main()
{
int n,m,i,j,x;
scanf("%d%d",&n,&m);
//堆初始化
Creat();
for( i = 0; i < n; i ++)
{
scanf("%d",&x);
insert(x);
}
//m个需求输出
for(int i = 0; i < m; i ++)
{
scanf("%d",&j);
printf("%d",H[j]);
while(j>1)
{
//沿着根的方向输出各个结点
j/=2;
printf("%d",H[j]);
}
printf("\n");
}
return 0;
}
小白专场2
- 集合的简化
File Transfer
int Find(SetType S[],ElementType X)
{
//在数组中查找值为X的元素所属集合
//MaxSize是全局变量,为数组S的最大长度
int i;
for(int i = 0; i < MaxSize && S[i].Data != X; i ++)
if(i>=MaxSize)return -1;
for(;S[i]->Parent>=0;i = S[i].Parent);
return i;
}
这个程序中S[i].Data != X需要线性扫描,消耗许多时间
最坏的情况是每次都扫描到数组最后一个元素,反复如此O(N2)
任意有限集合N都可以被一一映射为整数0~N-1,将计算机编码-1
将集合里的每一个元素用直接用数组中的下标表示,即可取消数据域ElementType Data ,定义一个整型数组

typedef int ElementType;
//根结点下标作元素名称
typedef int SetName;
typedef ElementType SetType [MaxSize];
SetName Find(SetType S,ElementType X)
{
for(; S[X]>=0; X = S[X])
return X;
}
void Union(SetType S, SetName Root1, SetName Root2)
{
S[Root2]= Root1;
}
- 程序框架搭建
int main()
{
SetType S;
int n;
char in;
scanf("%d\n",&n);
Initialization(S,n);
do{
scanf("%d",&in);
switch(in)
{
case 'I':Input_Connection(S);break;
case 'C':Check_Connection(S);break;
case 'S':Check_NetWork(S,n);break;
}
}while(in != 'S');
return 0;
}
void Input_Connection(SetType S)
{
ElementType u,v;
SetName Root1,Root2;
scanf("%d %d\n",&u,&v);
Root1 = Find(S,u-1);
Root2 = Find(S,v-1);
if(Root1!=Root2)
Union(S,Root1,Root2);
}
void Check_Connection(SetType S)
{
ElementType u,v;
SetName Root1,Root2;
scanf("%d %d\n",&u,&v);
Root1 = Find(S,u-1);
Root2 = Find(S,v-1);
if(Root1==Root2)
printf("Yes\n");
else printf("No\n");
}
void Check_NetWork(SetType S,int n)
{
int i,counter=0;
for(int i = 0; i < n; i ++)
{
if(S[i]<0)counter++;
}
if(counter==1)printf("The network is connected.\n");
else printf("There are %d components.\n",counter);
}
前面Union和Find算法会超时

将树低的贴到高树上可减少树的增高
S[Root]= - 树高

if(S[Root2]<S[Root1])
S[Root1]=Root2;
else
{
if(S[Root1]==S[Root2])S[Root1]--;
S[Root2] = Root1;
}
比规模
S[Root] = - 元素个数
void Union(SetType S, SetName Root1, SetName Root2)
{
if(S[Root2]<S[Root1])
{
S[Root2]+=S[Root1];
S[Root1] = Root2;
}
else
{
S[Root1] +=S[Root2];
S[Root2] = Root1;
}
}
最坏情况下logN
此两种方法称为按秩归并
- 路径压缩
使得程序更快
SetName Find(SetType S, ElementType X)
{
if(S[X]<0)return X;
//先找到根,再把根变成X的父结点再返回根
else return Find(S,S[X]);
}
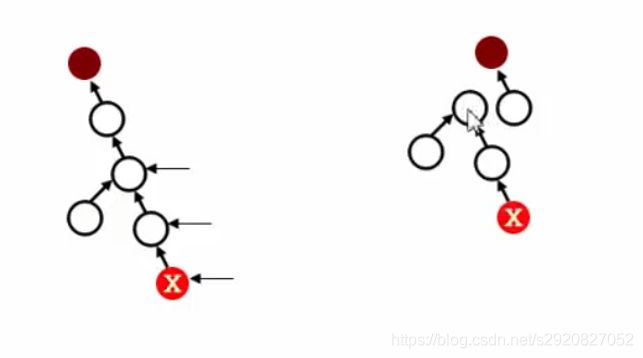


路径压缩的优点在于,反复调用find函数时,造成时间超时,而进行一次路径压缩,下次调用find函数很合算

第六章
图的定义
- 图的定义
六度空间理论(Six Degrees of Separation)
任何两个人之间不超六个人之间认识
图可以解决的问题

花费最少可以转换为最小生成树的问题
线性表和树可以描述为图的一个特殊情况
- 表示多对多的关系
- 包含
一组顶点:通常用V(Vertex)表示顶点集合
一组边:通常用E(Edge)表示边的集合
- 边是顶点对:(v,w)属于E,其中v,w属于V
- 有向边
- 不考虑重边和自回路


抽象数据类型定义:

常见术语:

红色数字称为权重
- 邻接矩阵表示法
邻接矩阵G[N][N]表示N个顶点从0到N-1编号
G[N][N]
= 1 vi和vj是G中的边
= 0
邻接矩阵是对称的,只需要存一半的元素即可,省去一半的存储空间

浪费空间:存稀疏图(点很多而边很少)有大量无效元素
对于稠密图,特别是稀疏图比较合算
3. 邻接表表示法
邻接表:G[N]是指针数组,对应矩阵每一行一个链表,只存非零元素
方便找任一顶点的所有”邻接点“
节约稀疏图空间
需要N个头指针和2E个结点(每个结点至少需要连个域)
图的遍历
- DFS
深度优先搜索
N条边E个结点
邻接表存图O(N+E)
邻接矩阵存图O(N2) - BFS
- 为什么两种遍历
- 图连不通怎么办
- 连通:如果v到w存在一条(无向)路径,则称v到w是连通的
- 路径:v到w的路径是一系列顶点(v,v1,v2,v3,vn,w),其中任意相邻顶点间都有图中的边。路径的长度是路径中的边数(如果带权,是所有边数权重之和)。如果v到w是所有顶点都不同,则称之为简单路径。
- 回路:起点等于终点的路径
- 连通图;图中任意两点均连通
- 连通分量:无向图的极大连通子图
极大顶点数:再加一个顶点就不连通的
极大边数:包含子图中所有顶点相连的所有边 - 强连通:有向图中顶点v和w之间存在双向路径,则称v和w强连通
- 强连通图:有向图中任意两顶点均强连
- 强连通分量:有向图的极大强连通子图
每调用一次DFS(V),就把V所在连通分量遍历一遍,BFS(V)也是一样
例
- 拯救007
void save007(Graph G)
{
for(each V in G)
{
if(!visited[G]&&FirstJump(G))
{
answer = DFS(V);
if(answer==YES)break;
}
}
if(answer==YES)output("Yes");
else output("No");
}
void DFS(Vertex V)
{
visited[V]=true;
if(IsSafe(V))answer = YES;
else
{
//for(V的每个邻接点W)
for(each W in G)
if(!visited[W]&&Jump(V,W))
{
answer = DFS(W);
if(answer==YES)break;
}
}
return answer;
}
- 六度空间

算法思路:
- 对每个节点进行广度优先搜索
- 搜索过程累计访问的节点
- 需要记录“层数”,仅计算6层以内结点数

int BFS(Vertex V)
{
visited[V] = true; count = 1;
level = 0; last = V;
Enqueue(V,Q);
while(!IsEmpty(Q))
{
V = Dequeue(Q);
for(V每个邻接点W)
if(!visited[W])
{
visited[W] = true;
Enqueue(W,Q);
count++;
tail = W;
}
if(V==last)
{
level++;
last = tail;
}
if(level == 6)break;
}
return count;
}
邻接矩阵表示的图

typedef struct GNode *PtrToGNode;
struct GNode{
int Nv;//顶点数
int Ne;//边数
WeightType G[MaxVertexNum][MaxVertexNum];
DataType Data[MaxVertexNum];
};
typedef PtrToGNode MGraph;//以邻接矩阵存储图的类型
- MGraph 初始化
初始化一个有VertexNum个顶点但是没有边的图
MGraph CreatGraph(int VertexNum)
{
MGraph Graph;
Graph = (MGraph)malloc(sizeof(struct GNode));
Graph->Nv = VertexNum;
Graph->Ne = 0;
for(V = 0; V < Graph->Nv; V ++)
for(W = 0; W < Graph->Ne; W ++)
Graph->G[V][W] = 0;
//如果有权值可以使Graph->G[V][W]=INFINITY;
return Graph;
}
- 向MGraph插入一条边
typedef struct ENode *PtrToENode;
struct ENode{
Vertex V1,V2;//有向边V1,V2
WeightType Weight;//权重
};
typedef PtrToENode Edge;
//把相应的权重赋值给相应的邻接矩阵
void InsertEdge(MGraph Graph,Edge E)
{
//有向图
Graph->G[E->V1][E->V2] = E->Weight;
//若为无向图还需要插入一条V2V1边
Graph->G[E->V2][E->V1] = E->Weight;
}
- 完整建立一个MGraph


int G[MAXN][MAXN],Nv,Ne;
void BuildGraph()
{
int i,j,v1,v2,w;
scanf("%d",&Nv);
for( i = 0; i < Nv; i ++)
for( j = 0; j < Nv; j ++)
G[i][j] = 0;
scanf("%d",&Ne);
for( i = 0; i < Ne; i ++)
{
scanf("%d %d %d",&v1,&v2,&w);
G[v1][v2]=w;
G[v2][v1]=w;
}
}
用邻接表表示的图
- 邻接表:G[N]是指针数组,对应矩阵每行一个链表,只存非零元素

typedef struct GNode *PtrToGNode;
struct GNode{
int Nv;
int Ne;
AdjList G;
//邻接表
};
typedef PtrToGNode LGraph;
typedef struct Vnode{
PtrToAdjVNode FirstEdge;
DataType Data;
}AdjList[MaxVertexNum];
//AdjList 邻接表类型
typedef struct AdjVNode PtrToAdjVNode;
struct AdjVNode{
Vertex AdjV;//邻接表下标
WeightType Weight;
PtrToAdjVNode Next;
}
- 初始化
LGraph CreatGraph(int VertexNum)
{
Vertex V,W;
LGraph Graph;
Graph = (LGraph)malloc(sizeof(struct GNode));
Graph->Nv = VertexNum;
Graph->Ne = 0;
for( V = 0; V < Graph->Nv; V ++)
Graph->G[V].FirstEdeg = NULL;
return Graph;
}
- 插入边

void InsertEdge(LGraph Graph,Edge E)
{
PtrToAdjVNode NewNode;
//给V2建立新结点
NewNode = (PtrToAdjVNode)malloc(sizeof(struct AdjVNode));
NewNode->AdjV = E->V2;
NewNode->Weight = E->Weight;
//将V2插入V1表头
NewNode->Next = Graph->G[E->V1].FirstEdge;
Graph->G[E->V1].FirstEdge = NewNode;
//若是无向图,则需要插入V2V1边
//给V1建立新结点
NewNode = (PtrToAdjVNode)malloc(sizeof(struct AdjVNode));
NewNode->AdjV = E->V1;
NewNode->Weight = E->Weight;
//将V1插入V2表头
NewNode->Next = Graph->G[E->V2].FirstEdge;
Graph->G[E->V2].FirstEdge = NewNode;
}
第七章
Tree Traversals Again
- 非递归中序遍历过程
push为先序遍历
pop为中序遍历
 post为后序遍历
post为后序遍历
先确定根结点,然后分而治之,分别解决左右子树
void solve( int preL, int inL, int postL, int n)
{
if(n==0)return;
if(n==1)
{
post[postL]=pre[preL];return;
}
root = pre[preL];
post[postL+n-1] = root;
for(i = 0; i < n; i ++)
//找到根结点
if(in[inL+i]==root)break;
L = i;R = n-L-1;
solve(preL+1,inL,postL,L);
solve(preL+L+1,inL+L+1,postL+L,R);
}
Complete Binary Search Tree
完全二叉搜索树
两个概念:完全二叉树和二叉搜索树
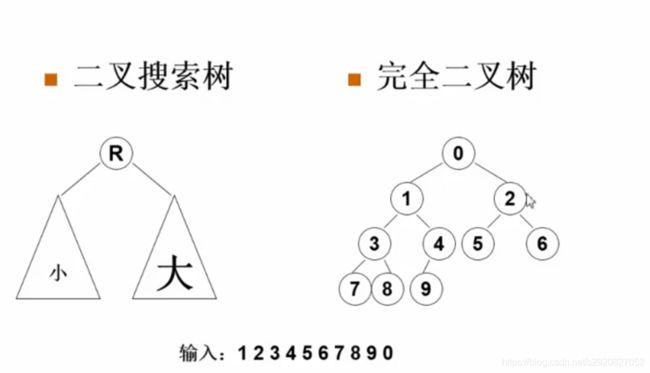

树的表示方法:链表vs数组
需要操作:
填写数字(遍历)
层序遍历
完全二叉树,不浪费空间
层序遍历直接输出
void solve(int ALeft,int ARight,int TRoot)
{
n = ARight - ALeft + 1;
if(n==0)return;
//L计算出n个结点的树的左子树有多少个结点
L = GetLeftLength(n);
T[TRoot] = A[ALeft+L];
LeftTRoot = TRoot*2+1;
RightTRoot = LeftTRoot+1;
solve(ALeft,ALeft+L-1,LeftTRoot);
solve(ALeft+L+1,ARight,RightTRoot);
}
计算左子树的规模
 X取X和2H-1的最小值
X取X和2H-1的最小值
Huffman Codes
Huffman编码不唯一
注意:最优编码不一定通过Huffman算法得到
- 编码总长度最小WPL
- 无歧义的解码,前缀码,每一个数都放在叶子结点上
- 没有度为1的结点
核心算法
- 计算最优编码长度
MinHeap H = CreatHeap(N);
H = ReadHeap(N);
HuffmanTree T = Huffman(H);
int CodeLen = WPL(T,0);
int WPL(HuffmanTree T,int Depth)
{
if(!T->Left&&!T->Right)
return (Depth*T->Weight);
else
return (WPL(T->Right,Depth+1)+WPL(T->Left,Depth+1));
}
- 对提交检查是否正确
长度是否正确

Code[i]最大的长度为N-1

建树是否满足前缀码要求
Code[i]=“1011”

Code[i]=“100”

Code[i]=“1001”
Code[i]=“101”
这两种代码会发现出错
最短路径问题
- 概述
- 网络中求两个不同顶点中所有路径中,边的权值之和最小的那一条路径
- 这条路径就是两点间的最短路径
- 第一个顶点为源点
- 最后一个顶点为终点
单源最短路问题:
从固定源点出发,求其到所有其他顶点的最短路径
多源最短路问题:
求任意两顶点间最短路径
- 无权图的单源最短路
按照递增的顺序找各个顶点的最短路

修改BFS进行搜索
void Unweighted(Vertex S)
{
Enqueue(S,Q);
while(!IsEmpty(Q))
{
V = Dequeue(Q);
for(V的每个邻接点W)
{
if(dist[W]==-1)
{
dist[W]=dist[V]+1;
path[W]=V;
Enqueue(W,Q);
}
}
}
dist[W]=S到W最短的距离
dist[S]=0
path[W]=S到W路上所经过的某个顶点
- 有权图的单源最短路

V1源点V6终点,最短路是哪一条呢?

权值出现负,会出现有意思的事情
按照递增的顺序找到各个顶点间最短路
negetive cost cycle
最短路为负无穷,不考虑这种情况
- Dijkstra算法
- 令s={源点s+已经确定了最短路径的顶点vi}
- 对于任意未录的顶点v,定义dist[v]为s到v的最短路径长度,但该路径仅经过s中的顶点,即路径{s->vi(vi属于S)->v}的最小长度
- 路径是按递增顺序生成
- 真正最短路仅经过s中的顶点
- 每次从未收录的顶点选一个dist最小的收录(贪心)
- 增加一个v进入s,可能影响令外一个w的dist的值
dist[w]=min{dist[w],dist[v]+(v,w)权重}

方法一:直接扫描所有的未收录的顶点O(|V|)
稠密图
T = O(|V2|+|E|)
方法二:将dist存在最小堆-O(log|V|)
稀疏图
更新dist[W]值-O(log|V|)
T = O(|V|log|V|+|E|log|V|) = O(|E|log|V|)
- 多源最短路
方法一:直接调用|V|遍
T = O(|V2|+|E|)稠密图再乘以V变成三次方
方法二:Floyd算法
T = O(|V3|)无立方,不含|E|*V这样的尾巴

void Floyd()
{
for( i = 0; i < N; i ++)
for( j = 0; j < N; j ++)
{
D[i][j] = G[i][j];
path[i][j] = -1;
}
for( k = 0; k < N; k ++)
for( i = 0; i < N; i ++)
for( j = 0; j < N; j ++)
if(D[i][k]+D[k][j]<D[i][j])
{
D[i][j] = D[i]{k}+D[k][j];
path[i][j] = k;
}
}
小白专场
哈瑞波特的考试
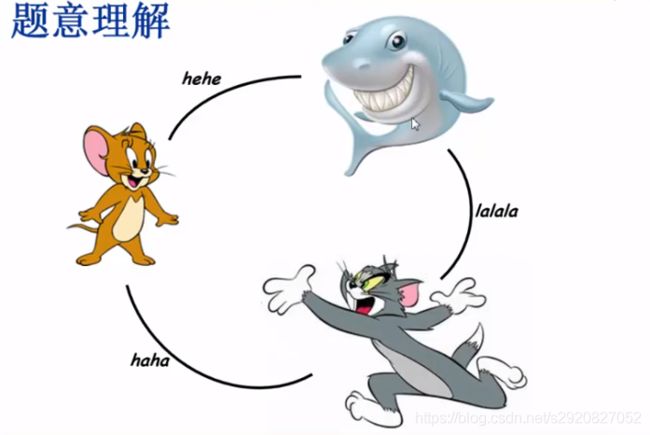
猫变老鼠haha
老鼠变鱼hehe
猫变鱼lalala
问:哈瑞波特带谁去念的字母最少
更复杂的算法

- 程序框架搭建

int main()
{
MGraph G = BuildGraph();
FindAnimal(G);
return 0;
}

此模块现成,修改即可用

- 选择动物

void FindAnimal(MGraph Graph)
{
WeightType MinDist,MaxDist,D[MaxVertexNum][MaxVertexNum];
Vertex Animal,i;
Floyd(Graph,D);
MinDist = INFINITY;
for(i = 0; i < Graph->Nv; i ++)
{
MaxDist = FindMaxDist(D,i,Graph->Nv);
if(MaxDist==INFINITY)
{
printf("0\n");
return;
}
if(MinDist>MaxDist)
{
MinDist=MaxDist;
Animal = i + 1;
}
}
printf("%d %d\n",Animal,MinDist);
}
WeightType FindAnimal(WeightType FindAnimal,Vertex i,int N)
{
WeightType MaxDist;
Vertex j;
MaxDist = 0;
for(int j = 0; j < N; j ++)
if(i!=j&&D[i][j]>MaxDist)
MaxDist=D[i][j];
return MaxDist;
}
- 模块的引用和剪裁

根据前面所学计算
第八章
最小生成树问题
(Minimum Spanning Tree)
-
一棵树
无回路
v个顶点有v-1条边 -
是生成树
包含全部顶点
v-1条边全部在图里
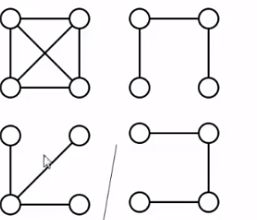
三个生成树任意加一条边都可构成回路 -
边的权重和最小
贪心算法(Prim和Kruskal):
贪:每一步都要最好的
好:权重最小的边
需要约束:
只用图中的边
用完V-1条边
不能有回路
- Prim算法(稠密图)
让小树长大

和Dijkstra算法相似


T=O(|V2|)
- Kruskal算法(稀疏图)

拓扑排序

- 拓扑序:如果图中从v到w有一条有向路径,则v一定在w前,满足此条件的顶点序成为拓扑序
- 获取一个拓扑序的过程就是拓扑序列
- AOV如果有合理的拓扑序,则必定是有向无环图

每次输出没有前驱顶点的顶点,即入度为0的顶点
void TopSort()
{
for(cnt = 0; cnt < |V|; cnt ++)
{
V = 未输出入度为0的结点
if(这样的V不存在)
{
Error("图中有回路");
break;
}
输出V,或者记录V的输出序列
for(V每个邻接点W)
Indegree[W]--;
}
}
T = O(|V2|)
- 更聪明的算法
随时入度为0 的顶点放为一个容器W
void TopSort()
{
for(图中每个顶点V)
if(Indegree[V]==0)
EnQueue(V,Q);
while(!IsEmpty(Q))
{
V = DeQueue(Q);
//输出V或者记录V
cnt++;
for(V每个邻接点W)
if(--Indegree[W]==0)
Enqueue(W,Q);
}
if(cnt!=|V|)
Error("图中有回路");
}
T=O(V+E)
也可以用此算法检验是否是有向无环图
- 关键路径问题
- AOE(Activity On Edge)网络
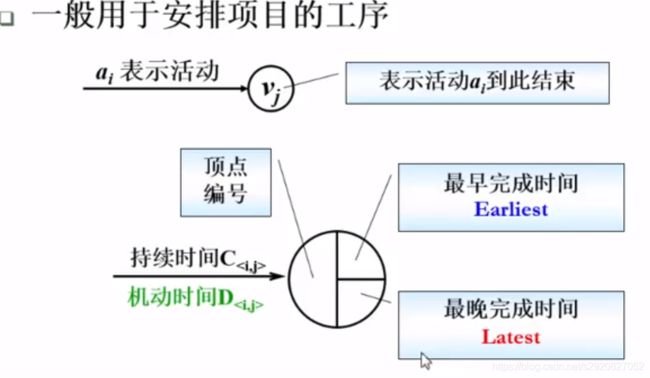


由绝对不允许延误的活动组成的路径
图习题
- 旅游规划
- 城市为结点
- 公路为权重
权重1:距离
权重2:收费 - 单源最短路:
Dijkstra算法
等距离时按收费更新

void Dijkstra(Vertex s)
{
while(1)
{
V = 未收录顶点中dist最小值;
if(这样的V不存在)
break;
collected[V]=true;
for(V每个邻接点W)
if(collected[V]==false)
if(dist[V]+E<v,w><dist[W])
{
dist[W]=dist[V]+E<v,w>;
path[W]=V;
cost[W]=cost[V]+C<v,w>;
}
else if ((dist(V)+E<v,w>==dist[W])&&(cost[V]+E<v,w> < cost[W]))
{
cost[W]=cost[V]+C<v,w>;
path[W]=V;
}
}
}
- 其他类似问题:
- 要求最短路径多少条
count[s] = 1;
如果找到更短路:count[W]=count[V]
如果找到等长的最短路:count[W]+=count[V]; - 要求边数最少的最短路
count[s]=0;
如果找到更短路:count[W]=count[V]+1;
如果找到等长的最短路:count[W]=count[V]+1;
第九章
简单排序
- 概述
void X_Sort(ElementType A[],N)
- 大多数情况为简单,从小到大排序
- N是正整数
- 只基于比较的排序(<=>有定义)
- 只讨论内部排序
- 任意两个相等的数据,排序前后相对位置不变
- 没有一种排序在任何情况下都是最好的
- 冒泡排序
void Bubble_Sort(ElementType A[],int N)
{
for(P = N-1; P >= 0; P--)
{
flag = 0;
for(i = 0; i < P; i ++)
{
if(A[i]>A[i+1])
{
swap(A[i],A[i+1]);
flag = 1;
}
}
if(flag == 1)break;
}
}
最好情况T=O(N)
最坏情况T=O(N2)
- 插入排序
打扑克牌就是一个插入排序的过程

void Insertion_Sort(ElementType A[],int N)
{
for( P = 1; P < N; P ++)
{
Tmp = A[P];//摸下一张牌
for( i = P; i > 0 && A[i-1]>Tmp; i --)
A[i] = A[i-1];//移除空位
A[i] = Tmp;//新牌
}
}
最好情况 T = O(N)
最坏情况 T = O(N2)
- 时间复杂度下界
对于下标i
交换两个相邻元素正好消去一个逆序对
插入排序T(N,I)= O(N+I)
如果一个序列基本有序,那么插入排序比较高效
- 定理:任意N个不同元素组成的序列平均具有N(N-1)/4个逆序对
- 定理:任何仅以交换相邻两元素来排序的算法,其平均时间复杂度(N2)
想要提高算法效率
- 每次消去不止一个逆序对
- 交换相隔较远的两个元素
希尔排序
利用了插入排序的简单,克服了插入排序每次交换两个元素较近的缺点


![]()
同颜色的数字先被选出


void Shell_Sort(ElementType A[], int N)
{
for( D = N/2; D >= 0; D/=2)//希尔增量序列
for( P = D; P < N; P ++)
{
Tmp = A[P];
for( i = P; i >= D && A[i-D]>Tmp; i --)
A[i] = A[i-D];
A[i] = Tmp;
}
}
T = O(N2)
最坏的情况


前面三次排序未起到作用,最后一次排序起作用
增量元素不互质,则小增量可能根本不起作用
互质:元素没有公因子

堆排序和选择排序
- 选择排序
void Seletion_Sort(ElementType A[], int N)
{
for( i = 0; i < N ; i ++)
{
MinPosition = ScanForMin(A,i,N-1);
//从A[i]到A[N-1]中找到最小元,赋值给MinPosition
Swap(A[i],A[MinPosition]);
//将未排序的最小元换到有序部分最后的位置
}
}
T=O(N2)
问题转换成如何快速找到最小元
利用最小堆
推到堆排序
- 算法一
void Heap_Sort(ElementType A[], int N)
{
BuildHeap(A);
for( i = 0; i < N; i ++)
TmpA[i] = DeleteMin(A);
for( i = 0; i < N; i ++)
A[i] = TmpA[i];
}

对空间的利用存在问题,开一个tmpa空间不合理
- 算法二
算法思路:调整一个最大堆
void Heap_Sort(ElementType A[], int N)
{
for(i = N/2; i >=0; i --)
PercDown(A,i,N);//BuildHeap
for(i = N - 1; i > 0; i --)
{
Swap(&A[0],&A[i]);//delete MAX
PercDown(A,0,i);
}
}


归并排序
- 归并
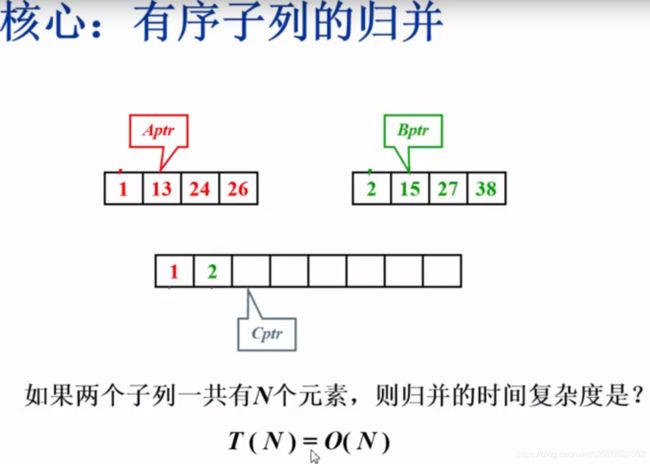
void Merge(ElementType A[],ElementType TmpA[],int L,int R,int RightEnd)
{
LeftEnd = R - 1;//左边终点位置
Tmp = L;//存放数组的初始位置
NumElements = RightEnd - L + 1;
while(L<=LeftEnd&&R<=RightEnd)
{
if(A[L]<=A[R])TmpA[Tmp++] = A[L++];
else TmpA[Tmp++] = A[R++];
}
//直接复制左右位置剩下的
while(L<=LeftEnd)TmpA[Tmp++] = A[L++];
while(L<=RightEnd)TmpA[Tmp++] = A[R++];
//将tmpa中数据返回A中
for(i = 0; i < NumElements; i ++, RightEnd --)
A[RightEnd] = TmpA[RightEnd];
}
- 递归算法

void MSort(ElementType A[],ElementType TmpA[],int L,int RightEnd)
{
int Center;
if(L<RightEnd)
{
Center =(L + RightEnd)/2;
MSort(A,TmpA,L,Center);
MSort(A,TmpA,Center+1,RightEnd);
Merge(A,TmpA,L,Center+1,RightEnd);
//原始数组,新数组,左边起点,右边起点,右边终点
}
}
时间复杂度:左边T(N/2)右边T(N/2)
T(N) = T(N/2)+T(N/2)+O(N)
T(N) = O(NlogN)
- 统一函数接口
void Merge_sort( ElementType A[], int N)
{
ElementType *TmpA;
TmpA = malloc (N*sizeof (ElementType));
if(TmpA != NULL)
{
MSort(A,TmpA,0,N-1);
free(TmpA);
}
else Error("空间不足");
}

- 非递归算法

O(N)
//length是当前有序子列的长度
void Merge_Sort(ElementType A[],ElementType TmpA[], int N, int length)
{
Merge1将A中元素归并到TmpA,最后不进行for循环
for(i = 0; i <= N - 2*length; i += 2*length)
Merge1(A,TmpA,i,i+length,i+length*2-1);
//归并最后两个子列
if(i+length<N)
Mergr1(A,TmpA,i,i+length,N-1);
//子列就剩一个
else
for(j = i; j < N; j ++)
TmpA[j] = A[j];
}
void Merge_Sort(ElementType A[],int N)
{
int length = 1;
ElementType *TmpA;
TmpA = malloc(N*sizeof(ElementType));
if(TmpA!=NULL)
{
while(length<N)
{
Merge_pass(A,TmpA,N,Length);
length*=2;
Merge_pass(TmpA,A,N,Length);
length*=2;
}
free(TmpA);
}
else Error("空间不足");
}
缺点得重新申请一个空间
第十章
快排
- 概述:分而治之

- 选主元

ElementType Median3(ElementType A[], int Right, int Left)
{
int Center = (Left+Right)/2;
if(A[Left]>A[Center])
Swap(&A[Left],&A[Center]);
if(A[Left]>A[Right])
Swap(&A[Left],&A[Right]);
if(A[Center]>A[Right])
Swap(&A[Center],&A[Right]);
//A[Left]<=A[Center]<=A[Right]
Swap(&A[Center],&A[Right-1]);
return A[Right-1];返回主元
}
- 子集划分


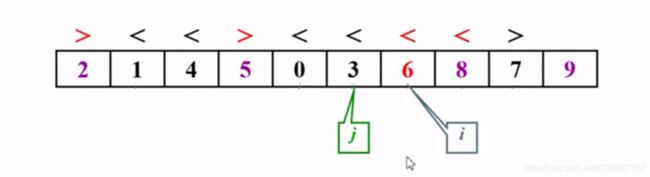
如果有元素正好等于主元(pivot)怎么办?
停下来交换
- 算法实现
void QuickSort(ElementType A[],int Left,int Right)
{
if(Cutoff<=Right - Left)
{
Pivot = Median3(A,Left,Right);
i = Left;
j = Right - 1;
for(;;)
{
while(A[i++]<Pivot)
while(A[j++]>Pivot)
if(i<j)Swap(&A[i],&A[j]);
else break;
}
Swap(&A[i],&A[Right - 1]);
QuickSort(A,Left,i - 1);
QuickSort(A,i+1,Right);
}
else
Insertion_Sort(A+Left,Right - Left + 1);
}
void Quick_Sort(ElementType A[],int N)
{
QuickSort(A,0,N-1);
}
表排
- 概述
- 间接排序
定义一个指针数组作为表(table)
通过比较key的值移动table值



2. 物理排序
N个数字的排列由若干的独立的环组成

如何判断一个环的结束
if(table[i]=i)
复杂度分析
最好的情况:初始即有序
最坏的情况:
有[N/2]个环,每个环包含两个元素
需要3N/2次元素移动

基数排
- 桶排序

- 基数排序
次位优先

- 多关键字的排序
扑克牌就是按照两个关键字排排序的


排序的比较

第十一章
散列表

c语言规则,变量先定义后使用

-
查找的本质:已知对象找位置
有序安排对象:全序,半序
直接算出对象的位置:散列 -
散列查找法两项基本工作:
计算位置冲突:构造散列函数确定关键词的存储位置
解决冲突:应用某种策略,解决多个关键字位置相同的问题
时间复杂度几乎是常量:O(1),即查找时间与问题的规模无关
散列函数构建
- 抽象函数描述

散列基本思想:
- 以关键字key为自变量,通过一个确定得函数h,计算出对应的函数值h(key),作为数据对象的存储地址
- 可能不同的关键字会映射到同一个散列地址上,即h(keyi)=h(keyj)(当keyi!=keyj),称为冲突(Collision),需要某种冲突解决策略
- 散列函数的构造方法
一个好的散列函数一般考虑下列两个因素:
- 计算简单,以便提高转换速度
- 关键字对应的地址空间分布均匀,以便减少冲突
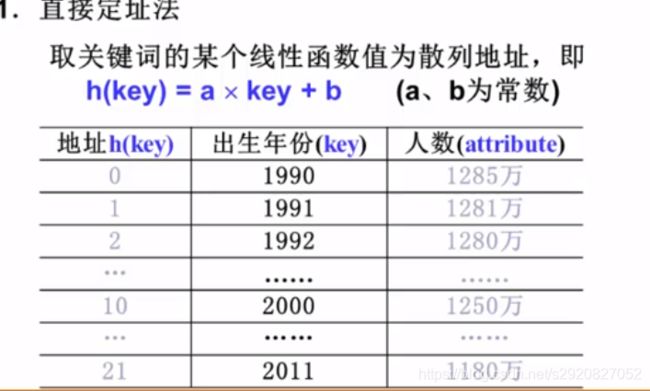
- 数字关键字的散构造



- 字符关键词的散列函数构造
- ASCII码加和法

快速计算:
Index Hash(const char *Key,int TableSize)
{
unsigned int h = 0;
while(* Key != '\0')
h = (h<<5)+*Key++;
return h % TableSize;
}
冲突处理方法
- 开放地址
当发生冲突时,利用某种规则,去寻找另一空间地址

- 线性探测
以增量序列1,2,3,(TableSize-1)循环下一个存储地址



会出现聚集现象
散列表性能分析:
成功平均查找长度(ASLs)
不成功平均查找长度(ASLu)

散列函数:h(key)= key mod 11

- 平方探测
以增量序列12,-12,22,-22,q2,-q2,q<=[TableSize/2]循环试探下一个存储地址


找不到一些空位

定理:如果散列表长度TableSize是某个4k+3(k是正整数)形式的素数时,平方探测法就可以探测到整个散列表空间
程序实现
typedef struct HashTbl*HashTable;
struct HashTbl{
int TableSize;
Cell*TheCells;
}H;
HashTable InitializeTable(int TableSize)
{
HashTable H;
int i;
if(TableSize<MinTableSize)
{
Error("散列表太小");
return NULL;
}
H = (HashTable)malloc(sizeof (struct HashTbl));
if(H==NULL)
FatalError("空间溢出");
H->TableSize = NextPrime(TableSize);
H->TheCells = (Cell*)malloc(sizeof(Cell)*H->TableSize);
if(H->TheCells==NULL)
FatalError("空间溢出");
for(i = 0; i < H->TableSize; i ++)
{
H = TheCell[i].Info = Empty;
}
return H;
}



在开放地址散列表中,删除操作要很小心,通常只能“懒惰操作”,即需要增加一个“删除标记”,而不是真正的删除它,以便查找时不会“断链”,其他空间可以在下次插入时重用
3.双散列探测法

- 再散列
散列表元素过多,查找效率会下降(装填因子a过大)
实用填装因子一般取(0.5<=a<=0.85)
当装填因子过大,解决方法是加倍扩大散列表,这个过程叫做再散列
- 分离链接
将一个位置上冲突的所有关键字存储在同一个链表中

typedef struct ListNode *Position,*List;
struct ListNode{
ElementType Element;
Position Next;
};
typedef struct HashTbl *HashTable;
struct HashTbl{
int TableSize;
List TheLists;
};
Position Find(ElementType Key,HashTable H)
{
Position P;
int Pos;
Pos = Hash(Key,H->TableSize);//初始散列位置
P = H->TheList[Pos].Next;//获得链表头
while(P!=NULL&&strcmp(P->Element,Key));
P=P->Next;
return P;
}
散列表性能分析
- 线性探测法的查找性能
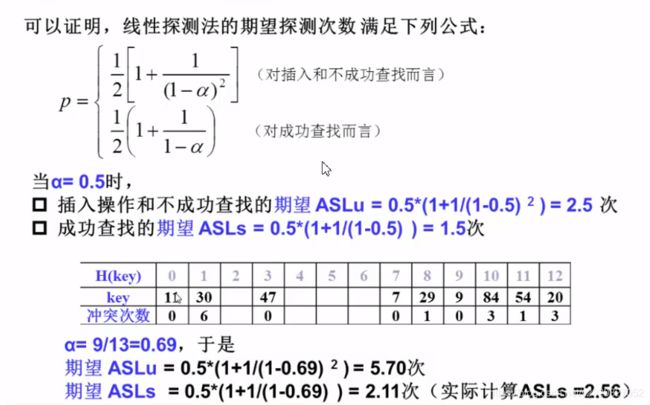
- 平方探测法和双散列探测法的性能分析


- 分离链接法的查找性能

选择合适的h(key),散列法的查找效率期望是常数O(1),它几乎与关键字的空间的大小n无关,也适合于关键字直接比较计算量大的问题
以较小的a为前提,因此,散列是一个以空间换时间
散列方法的存储对关键字是随机的,不便于顺序查找的关键字,也不适于范围的查找,或最大值最小值的查找 - 开放地址法:
散列表是个 数组,存储效率高,随机查找
散列表有聚集现象 - 分离链法:
散列表是顺序存储和链式存储的结合,链表部分的存储效率和查找效率比较低
关键字的删除不需要懒惰删除法,从而没有存储垃圾
太小的a可能导致空间的浪费,太大的a又将付出更多的时间代价,不均匀的链表长度将导致时间效率的严重下降。
文件中单词词频统计

int main()
{
int TableSize;//散列表大小估计
int wordcount = 0,length = 0;
HashTable H;
ElementType word;
FILE *fp;
char document[30] = "HarryPotter.txt";
H = Initialize Table(TableSize);//建立散列表
if((fp=fopen(document,"r"))==NULL)FatalError("无法打开文件!\n");
while(!feof(fp))
{
length = GetAWord(fp,word);
//从文件中读取一个单词
if(length>3)
{
wordcount++;
InsertAndCount(word,H);
}
}
fclose(fp);
printf("该文档中出现了%d个有效单词",wordcount);
Show(H,10.0/100);//显示前百分之10
DestroyTable(H);//销毁散列表
return 0;
}

小白专场
- 电话聊天狂人

解决方法一:排序

解法二:直接映射

下标超过unsigned long

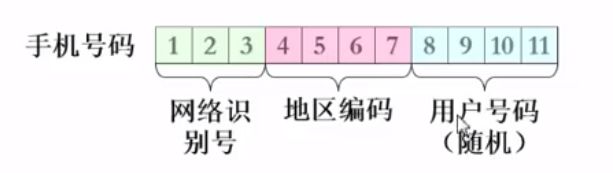
解法三:带智商的散列

- 程序框图搭建
int main()
{
创建散列表
读入号码插入表中
扫描表输出狂人
return 0;
}
int main()
{
int N,i;
ElementType Key;
HashTable H;
scanf("%d",&N);
H = CreatTable(N*2);//创建散列表
for(int i = 0; i < N; i ++)
{
scanf("%s",Key);Insert(H,Key);
scanf("%s",Key);Insert(H,Key);
}
ScanAndOutput(H);
DestoryTable(H);
return 0;
}

扫描整个散列表
更新最大通话次数
更新最小号码+统计人数
void ScanAndOutput(HashTable H)
{
int i,MaxCnt = PCnt = 0;
ElementType MinPhone;
List Ptr;
MinPhone[0] = '\0';
//扫描链接
for( i = 0; i < H->TableSize; i ++)
{
Ptr = H->Head[i].Next;
while(Ptr)
{
if(Ptr->Count>MaxCnt)//更新最大通话次数
{
MaxCnt = Ptr->Count;
strcpy(MinPhone,Ptr->Data);
PCnt = 1;
}
else if (Ptr->Count==Maxcnt)
{
PCnt++;//狂人计数
if(strcmp(MinPhone,p->Count)>0)
strcpy(MinPhone,Ptr->Data);
//更新狂人最小号码
}
Ptr = Ptr->Next;
}
}
printf("%s %d",MinPhone,MaxCnt);
if(PCnt>1)printf("%d",PCnt);
printf("\n");
}
- 模块的引用和裁剪





第十二章
习题选讲
- Insert Or Merge
如何区别简单的插入和非递归的归并排序?

- 捏软柿子算法:
- 判断是否插入排序
从左向右扫描,直到发现顺序不对,跳出循环
从跳出点继续向右扫描,与原始序列比对,发现不同则判断非
循环自然结束,则判断为是,返回跳出地点
- 如果是插入排序,则从跳出地点开始一趟插入
判断归并段长度

判断连接点的前后顺序
2. Sort with Swap(0,*)
给定0到N-1数字,利用0来排序


- 环的分类
分三种:
只有一个元素:不需要交换
环里有n0个元素,包括0:需要n0-1次元素
第i个环里有ni个元素,不包括0:先把0换到环里,再进行(ni+1)-1次交换,一共是ni+1次交换
若N个元素的序列中包含S个单元环,K个多元环,则交换次数为:
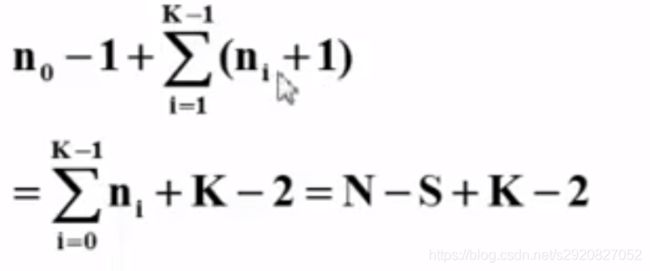

3. Hashing Hard Version

给出散列映射结果,反求输出顺序
若x映射到H(x)若该位置已经有y了,则y一定是x之前被输入的

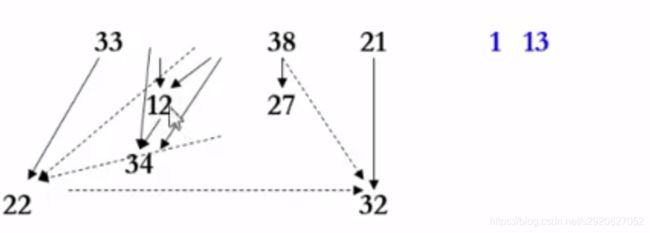
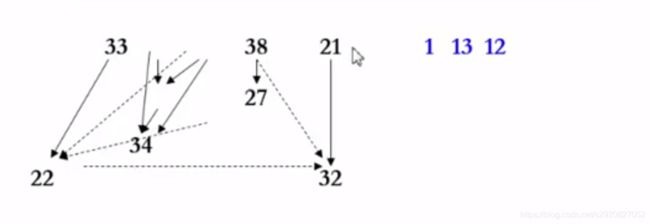


散列映射和拓扑排序结合
串的模式选讲
- 问题及问题的解决方案
线性存储一组数据(默认是字符)
特殊操作
- 求串长度
- 比较两串是否相等
- 两串相接
- 求子串
- 插入子串
- 匹配子串
- 删除子串
模式匹配:
- 方法一:

简单实现:
#include输出结果:

#include输出结果:


- 方法二:从末尾比

最坏时间复杂度没有得到本质提高 - 方法三:KMP(Knuth,Morris,Pratt三个人名)算法
T =O(n+m)


- 算法思路


match又称failure,next

3. 算法实现
#include
Position KMP(char *string,char *pattern)
{
int n = strlen(string);//O(n)
int m = strlen(pattern);//O(m)
int s,p*match;
match = (int*)malloc(sizeof(int)* m);
BuildMatch(pattern,match);
s = p = 0;
while(s<n && p<m)
{
if(string[s] = pattern[p])
{
s++;
p++;
}
else if(p>0)
p=match(p-1)+1;
else s++;
}
return(p==m)?(s-m):NotFound;
}
- BuildMatch实现




void BuildMatch(char*pattern,int *match)
{
int i,j;
int m = strlen(pattern);
match[0]=-1;
for( j = 0; j < m; j ++)
{
i = match[j-1];
while((i>=0)&&(pattern[i+1]!=patern[j]))
i = match[i];
if(pattern[i+1] = pattern[j])
match[j] = i+1;
else match[j] = -1;
}
}

Tm=O(m)