【Redis入门笔记 08】主从复制 & 集群

目录
-
- 主从复制
-
- 单机模拟主从复制(一主两从)
- 三种常用主从复制模式
- 哨兵模式
- 复制延迟
- Redis 集群
-
- 集群是如何工作的?
- Redis Cluster 集群搭建
- Redis Cluster 集群验证
- Redis 集群的利与弊
主从复制
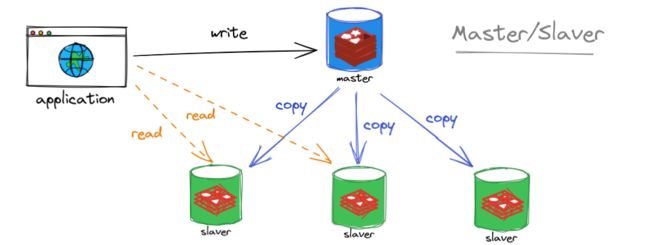
什么是主从复制?
主机数据更新后根据配置和策略, 自动同步到备机的 master/slaver 机制,Master 以写为主,Slave 以读为主。
主从复制的作用:
- 读写分离,保证高性能,易于扩展。
- 实现容灾的快速恢复。
单机模拟主从复制(一主两从)
主从复制需要多台主机来完成,由于没有那么多主机,我们可以在一台主机上开启三个 redis 进程来模拟多个主机的主从复制。这里在单机环境中模拟一个一主二从的 redis 模式,需要为 每个 redis 进程创建单独的配置文件。
创建三个配置文件:
三个配置文件的重复部分可以使用 inclued 导入~
- 新建
redis6379.conf,填写下面的内容:include /www/server/redis/redis.conf pidfile /var/run/redis_6379.pidfile port 6379 dbfilename dump6379.rdb - 新建
redis6380.conf,填写下面的内容:include /www/server/redis/redis.conf pidfile /var/run/redis_6380.pid port 6380 dbfilename dump.6380.rdb - 新建
redis6381.conf,填写下面的内容:include /www/server/redis/redis.conf pidfile /var/run/redis_6381.pid port 6381 dbfilename dump6381.rdb
启动三个 redis 服务进程:
依次启动三个 redis 服务,分别绑定上面的三个配置文件。
[ecs-user@ECS ~]$ sudo /www/server/redis/src/redis-server /myredis/redis6379.conf
[ecs-user@ECS ~]$ sudo /www/server/redis/src/redis-server /myredis/redis6380.conf
[ecs-user@ECS ~]$ sudo /www/server/redis/src/redis-server /myredis/redis6381.conf
查看系统进程中可以看到三个 redis 服务均已启动~

客户端配置主从复制:
我们只需要配置从库即可,主库不需要进行配置。
将刚刚启动的 6379 端口的 redis 作为主库,6380、6381 端口上的 redis 作为从库。分别启动 redis 客户端 redis-cli 连接上 6380 与 6381 端口,使用 slaveof 命令时期成为指定实例的从服务器。
[root@myfirstECS-linux ecs-user]# cd /www/server/redis/src/
[root@myfirstECS-linux src]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
[root@myfirstECS-linux ecs-user]# cd /www/server/redis/src/
[root@myfirstECS-linux src]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
使用 info replication 命令可以查看主从复制的相关信息:
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:0
slave_repl_offset:0
master_link_down_since_seconds:-1
......
测试主从复制:
尝试在从机上写数据,会发现报错,从机不可写。
127.0.0.1:6380> set k1 v1
(error) READONLY You can't write against a read only replica.
切换到主机,在主机中写入数据。
[ecs-user@ECS ~]$ sudo /www/server/redis/src/redis-cli -p 6379
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 hello
OK
将主机 shutdown,模拟主机挂掉的场景,再次重启,会发现数据会自动恢复,一切如初!
127.0.0.1:6379> shutdown
not connected>
[ecs-user@ECS~]$ sudo /www/server/redis/src/redis-server /myredis/redis6379.conf
[ecs-user@ECS ~]$ sudo /www/server/redis/src/redis-cli -p 6379
127.0.0.1:6379> auth redis@7066
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k2
"hello"
如果从机挂掉,重启后还需要重新设置 slaveof 127.0.0.1 6379。
三种常用主从复制模式
☕一主二从:
- 如果从服务器挂掉,使用
slaveof命令重新添加到从机当中来,会将主机中的数据从头复制过来,而不是从切入点开始复制。 - 如果主服务器挂掉,从服务器不会变成主服务器,当主服务器重启以后,依然是主服务器,数据会自动恢复。(重生之我是大哥!)
- 主从复制原理:
- 当从服务器连接上主服务器之后,从服务器向主服务器发送进行数据同步的消息。
- 主服务器链接到从服务器,发送同步消息同时将主服务器的数据持久化,生成
.rdb文件,将.rdb文件发送到从服务器,从服务器拿到.rdb进行读取。(全量复制 ) - 每次主服务器进行写操作之后,会和从服务器进行数据同步。(增量复制 )
- 只要主服务器重新链接,一次完全同步会将被自动执行。(全量复制 )

一主二从只是主从复制的其中一种,此外还有两种常用的主从复制模式:薪火相传、反客为主,以适应不同的需求。
☕薪火相传:
上一个 Slave 可以是下一个 slave 的 Master,从机同样可以接收其他从机的连接和同步请求,那么该从机作为了链条中下一个的主机,可以有效减轻 master 的写压力,去中心化降低风险。

同样的,slaveof 命令可以指定整个主从复制系统中的其他从机,成为该结点的 “主机”。
这种模式也存在一些问题:如果某个从机挂掉,后面以它为主机的从机都没办法备份,同时如果主机挂掉,也不能写数据了。
☕反客为主:
当主机宕机以后,可以使用 slaveof no one 命令手动将从机升级为主机,其余的从机不用修改,自动连上刚刚升级的主机。
哨兵模式
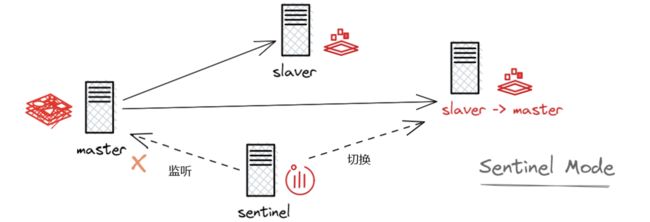
在哨兵模式下,由一个 redis 服务器充当哨兵,后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库,是上面介绍的反客为主的自动版。
☕哨兵模式的配置:
-
先开启一个一主二从的主从复制 redis。
-
创建哨兵 redis 的配置文件
sentinel.conf,内容只需要下面一行。sentinel monitor mymaster 127.0.0.1 6379 1mymaster是监控对象的别称,结尾的数字1表示哨兵同意迁移的数量。哨兵其实也可以配置多个,当服务器出现问题以后,哨兵会对服务器是否故障进行投票,只有投票数超过设置值才进行主机迁移。 -
启动哨兵,进入到 redis 的启动目录,执行如下命令。
[ecs-user@myfirstECS-linux ~]$ redis-sentinel /myredis/sentinel.conf
哨兵模式启动成功,默认端口号26379。
☕故障恢复:
当主机挂掉,会在从机中选举出新主机,选举的条件依次为:
- 选择优先级靠前的。(从机的优先级在配置文件中可以设置,
slave-priority为优先级设置) - 选择偏移量大的。(获得原主机数据最全的)
- 选择
runid最小的。(redis 启动后会生成一个 40 位的runid)
挑选出新的主机 Master 以后,哨兵会向原主机的从机发送 slaveof 命令,复制新主机的数据。当已下线的服务重新上线时,哨兵同样会向其发送 slaveof 命令,让其成为新主机的从机。
总结一下就是:主机重启以后会变为从机。(重生之我是小弟!)
复制延迟
主从复制虽然提高了系统的可靠性,但也会产生弊端,由于所有的写操作都是先在 Master上操作,然后同步更新到 Slave上,所以从 Master 同步到 Slave 有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave 机器数量的增加也会使这个问题更加严重。
Redis 集群
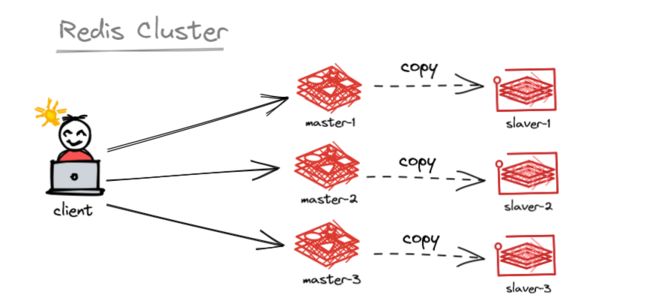
Redis 在 3.0 版本支持了无中心化集群配置,便于 redis 扩容,提高并发访问时的性能。
redis 集群实现了对 redis 的水平扩容,即启动 n n n 个 redis 节点,将整个数据库分布存储在这 n n n 个节点中,每个节点存储总数据的 1 / n 1/n 1/n。
redis 集群通过分区(partition)来提供一定程度的可用性: 即便集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
集群是如何工作的?
redis 集群都是有多台 redis 服务器组成的,考虑到以后可能还会加入新的机器,类似于 TCP 的三次握手协议,redis 也搞了一套握手协议:
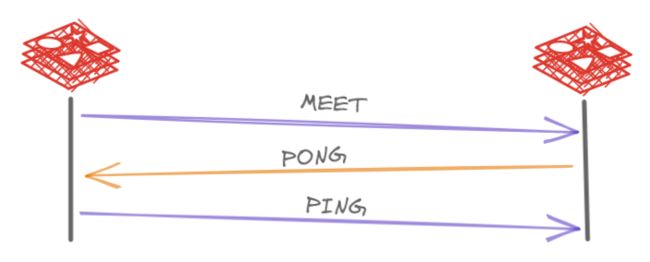
给新加入的主机指定集群中随便一个 redis 服务的 IP 地址和端口号,新主机首先发送 MEET 信息发起握手,对方回应 PONG 信息表示同意入伙,新主机再回应一个 PING 信息完成三次握手。
然后收到信息的主机再去通知集群中的其他主机,新主机就正式加入集群当中了。
在集群中,数据是分布存储在不同的 redis 中的,为了避免某个 redis 机器存储的数据过多或过少,redis 采用了类似哈希表的方法,划分了 16,384 个哈希槽(Slot),我们可以根据每台 redis 服务器的性能来从中分配不同大小的槽位。
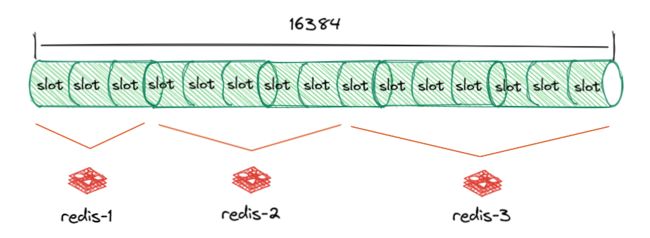
数据读写的时候,会对键值做哈希计算(公式:CRC16(key) % 16384),映射到哪个槽位就由谁来负责存储该数据。
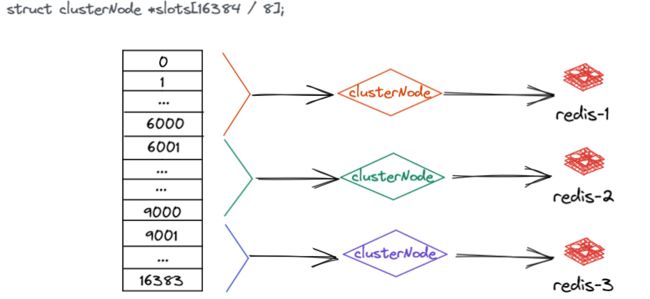
启动的时候,redis 会通知其他服务器自己负责的槽位信息,为了压缩存储空间,每个槽位用一个 bit 来表示,自己负责这一位就是 1,否则就是 0,表示 16384 个槽位的存储信息只需要 2048 个字节,传输信息也很快速。
同时为了更加快速的确定每个槽位有哪个节点来负责,redis 会维护一个数组来存储槽位与节点的对应关系,通过上面的方式获取槽位与节点的信息后就更新到数组中,这样在数据访问的时候,就可以快速地找到这个数据存储在哪一个 redis 节点上了。
Redis Cluster 集群搭建
redis 集群至少需要 3 个 Master 节点,这里在单机环境下搭建三个 Master 节点,并给每个 Master 再搭建一个 Slaver 节点,总计 6 个 redis 节点的集群。
单机模拟集群搭建可以创建 6 个不同端口号的 redis 实例,三主三从。
(多台机器部署只需要修改 ip 地址就可以,步骤都是一样的)
1.创建节点安装目录:
mkdir -p /usr/local/redis_cluster
2.在 redis_cluster 目录下分别创建 7001-7005 文件夹:
mkdir 7000 7001 7002 7003 7004 7005
3.将 redis.conf 分别拷贝到这六个文件夹下:
cp /www/server/redis/redis.conf ./7000
cp /www/server/redis/redis.conf ./7001
cp /www/server/redis/redis.conf ./7002
cp /www/server/redis/redis.conf ./7003
cp /www/server/redis/redis.conf ./7004
cp /www/server/redis/redis.conf ./7005
4.依次修改这六个配置文件:
# 关闭保护模式,用于公网访问
protected-mode no
# 指定端口号 7000~7005
port 7000
# 开启集群模式
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 15000
# 开启守护模式,允许后台允许
daemonize yes
pidfile /var/run/redis_7000.pid
logfile "7000.log"
# 链接主节点的密码
masterauth xxxxxx
# 设置redis密码,各个节点密码保持一致
requirepass redis@7066
5.将安装的 redis 目录下的 src 文件夹复制到 cluster 下:
cp -r /www/server/redis/src/ /usr/local/redis_cluster/
6.依次启动 6 个节点:
cd /usr/local/redis_cluster/
./src/redis-server ./7000/redis.conf
./src/redis-server ./7001/redis.conf
./src/redis-server ./7002/redis.conf
./src/redis-server ./7003/redis.conf
./src/redis-server ./7004/redis.conf
./src/redis-server ./7005/redis.conf
用 ps 命令查看进程:
7.创建集群:
redis 5 版本以后,通过 redis-cli 客户端命令来创建集群。
./src/redis-cli --cluster create -a xxxxxx 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
-a 为可选项,后面跟着 redis 密码,没有密码可以忽略。
--replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组。
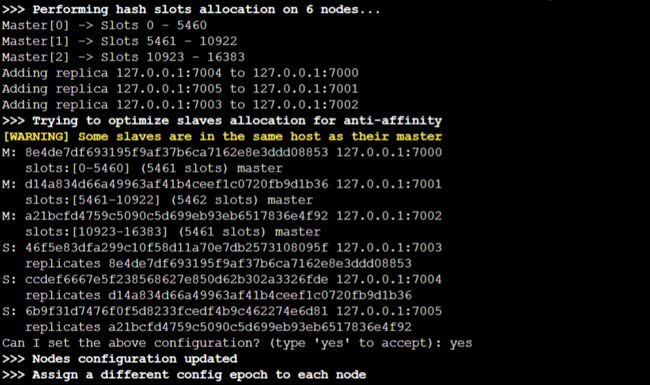
可以看到 7000 - 7002 为主机,7003 - 7005 为从机。
♂️这 6 个节点是如何分配的?
一个集群至少要有三个主节点。可选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。分配原则尽量保证每个主数据库运行在不同的 IP 地址,每个从库和主库不在一个 IP 地址上。
Redis Cluster 集群验证
在 redis-cli 查询、录入键值时,redis 都会计算出该 key 应该送往的插槽,如果不是该客户端对应服务器的插槽,redis 会报错,并告知应前往的 redis 实例地址和端口。(在实际的编程中,很多中间件都为我们屏蔽了重定向的操作,因此我们在编写程序时可以不用考虑重定向的问题)
当然,由于插槽 slot 的设计,不在一个 slot 下的键值,是不能使用 mget、mset 等多键操作的。
redis 客户端提供了 -c 参数实现自动重定向:
src/redis-cli -h 127.0.0.1 -c -p 7000 -a xxxxxx
redis 在设计的时候就考虑到了去中心化,集群中的每个节点都是平等关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点链接,而且这些链接保持活跃,这样就保证了我们只需要链接集群中的任意一个节点,就可以获取到其他节点的信息。
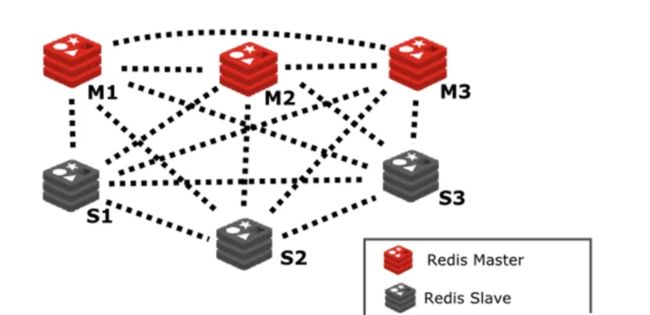
登录集群中的任意一个节点(包括从节点),都可以存取数据:
src/redis-cli -c -p 7001 -a xxxxxx
127.0.0.1:7001> set k2 v1
-> Redirected to slot [449] located at 127.0.0.1:7000
OK
同时客户端会根据分配到的插槽自动重定向至对应的 redis 端口:
src/redis-cli -c -p 7005 -a xxxxxx
127.0.0.1:7005> set k3 v3
-> Redirected to slot [4576] located at 127.0.0.1:7000
OK
127.0.0.1:7000> get k2
"v2"
故障恢复:
-
如果主节点宕机,从节点会自动升级为主节点(相当于主从复制中的哨兵机制),原来的主节点如果重新上线,会作为从机。
-
如果某一段插槽的主从节点全部挂掉,redis 能否继续提供服务取决于配置文件中
cluster-require-full-coverage的设置:- 设置为 yes,那么整个集群都会挂掉。
- 设置为 no,只是该插槽的数据全都不能使用,也无法存储。
Redis 集群的利与弊
♂️Redis 集群提供了以下好处:
- 实现扩容。
- 分摊压力。
- 无中心配置相对简单。
♂️Redis 集群也有以下不足:
- 多键操作是不被支持的 。
- 多键的 redis 事务是不被支持的,lua 脚本不被支持。
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至 redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
redis 系列专栏:Redis 快速入门
❤整理不易❤ 还请各位读者老爷们三连支持一下╰( ̄ω ̄o)
