正则表达式和sed命令
正则表达式
位置锚定
^n 以n为开头
n$ 以n为结尾
^root$ 匹配有且只有root的文件的其中行
^$ 空行
1*$ 空行
<或\b 词首锚定,用于单词模式的左侧
>或\b 词尾锚定,用于单词模式右侧
[root@localhost~]#echo hello-123 | grep “\b123”
[root@localhost~]#echo hello-123 | grep “\bhello-1”
[root@localhost~]#echo hello-123 | grep “123\b”
(匹配整个单词)
分组或其他
分组:( )将多个字符捆绑在一起,当做一个整体处理
或者:|
[root@localhost~]#echo abcabcabc | grep “(abc){3}”
abcabcabc
连续出现:
[root@localhost~]#echo abcabcabc | grep “(ab){3}”
[root@localhost~]#
[root@localhost~]#echo abcabcabc | grep “(ab){1}”
[root@localhost~]#ab c ab c ab c
[root@localhost~]#echo 1abc | grep “1|2abc”
[root@localhost~]#1 abc
[root@localhost~]#echo 1abc | grep “(1|2)abc”
[root@localhost~]#1abc
扩展正则表达式
grep -E 必须用 sed -r
或者
egrep
表示次数
- 匹配前面的字符任意次,包括0次
.* 匹配所有,任意长度的任意字符,不包括0次
? 匹配前面的字符,出现0次或1
- 匹配其前面的字符出现最少1次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m次,最多n次
{,n} 匹配前面的字符至多n次,最少0次
{n,} 匹配前面的字符至少n次
sed编辑器介绍Stream Editor
以行的方式对文件的内容进行增删改查
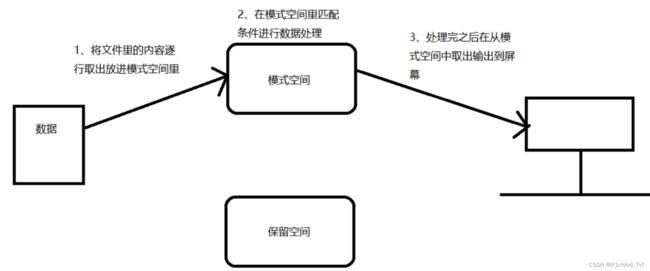
是一种流编辑器,它一次处理一行内容,从输入流(文件、管道、标准输入),称为“模式空间”pattern space,接着用sed命令处理缓冲区的内容。
sed工作流程:读取 、执行、 显示
执行:默认情况下,所有的sed命令都在模式空间中顺序的执行,除非指定了行的地址,否则sed命令将会在所有的行上依次执行。
显示:发送修改后的内容到输出流。在发送数据后,模式空间将被清空。在所有的文件内容都被处理完之前,上述过程将重复执行,直至所有内容都被处理完。
默认情况下所有的sed命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非使用“sed -i”修改源文件或使用重定向输出到新文件中。
sed -e ‘操作’ 文件1 文件2
sed -f 脚本文件 文件1 文件2
sed -i -e ‘操作’ 文件1 文件2
执行多条命令的格式:
方式一:
sed -e ‘操作1’ -e ‘操作2’ 文件
sed -n -e ‘/^r/p’ -e’/^b/p’ /etc/passwd p表示打印
方式二:
sed -e ‘操作1;操作2’ 文件
sed命令常用选项
e 或 --expression=:表示用指定命令来处理输入的文本文件,只有一个操作命令时可省略,一般在执行多个操作命令使用。
-f 或–file=:表示用指定的脚本文件来处理输入的文本文件
-h 或 --help:显示帮助
-i 直接修改目标文本文件
-n 仅显示script处理后的结果,取消默认输入
-r 用正则
sed命令操作符:
s: 替换 ,替换指定字符
d: 删除,删除选定的行
a: 增加, 在当前行下面增加一行指定内容
i:插入,在选定行上面插入一行指定内容
c: 替换 ,将选定行替换为指定内容。
y :字符转换,转换前后的字符长度必须相同
p: 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;
l: 打印数据流中的文本和不可打印的ASCII字符(比如结束符$、制表符\t)
sed最为核心的功能就是增删改查
sed命令的打印功能
sed ’ ’
sed -e ‘p’
只打印第二行: sed -n 2p
只显示行号: sed -n ‘=’
打印行号和内容: sed -n ‘=;p’
打印底行: sed -n ‘$p’
sed的寻址打印
行号范围内区间打印:set -n ‘1,3p’ 第一行到第三行
选定行:sed -n -e ‘2p’ -e ‘$p’ 打印第二行和最后一行
条件判断用单引号
偶数行: sed -n ‘n;p’
奇数行:sed -n ‘p;n’
文本模式过滤内容(对指定行的字符串进行操作)
sed -n ‘/o/p’ xxx.txt 包含o的所有行
正则表达式打印
sed -n ‘/^root/p’ 打印以root开头的行
sed -n ‘/root / p ′ 打印以 r o o t 结尾的行 s e d − n ′ 5 , / r o o t /p' 打印以root结尾的行 sed -n '5,/root /p′打印以root结尾的行sed−n′5,/root/p’ 从第五行开始打印到第一个以root结尾的行
sed -r -n ‘/(99:){2,}/p’ 打印包含有两个99:内容的行
sed删除操作
sed ‘d’ 文件名 全删
不删除文件的情况下删除文件内容
sed -i ‘d’ 文件名
cat /dev/null > 文件名
touch 文件名 > 文件名
true > 文件名
指定删除
sed -n ‘3d;p’ 文件名 只删除第三行
sed -n ‘5,8d;p’ 文件名 删除五到八行
sed ‘4,6!d’ 文件名 除了四到六行
匹配字符串内容进行删除
sed ‘/one/d’ 文件名 删除包含one的行(整行)
sed ‘/one/,/six/d’ 删除包含one到six的全部删掉
sed '/six/!d ’ 文件名 删除除了six的行
sed '/^KaTeX parse error: Expected group after '^' at position 34: …三种方法: grep -v "^̲" 文件名
cat 文件名 | tr -s 压缩空行
sed ‘/^$/d’ 文件名
sed的替换功能
s 替换字符串(不校验长度)
c 替换整行
y 字符替换,前后长度一致
sed -n ‘s/root/test/2p’ /etc/passwd 指定第二个root替换成test
sed -n ‘/^root/ s/^/#/p’ /etc/passwd 将以root开头的前面空格替换成井号
sed ‘s/[A-Z]/\l&/g’ 文件名 将大写转换为小写
sed ‘s/[a-z]/\u&/’ 文件名 首字母转换为大写
\l& \u&要加转义符,转换成小写、大写的意思
整行替换: sed ‘/one/c two’ 文件名 有one的行就写成two(区分大小写)
sed ‘y/on/te/’ 文件名 (要长度一致,匹配一个算一个,所有o和n都会替换)
sed增加内容对行
a 在行后添加内容
i 在行前插入内容
r 在行后读入文件内容
sed ‘/three/a 123’ 文件名 在three行后换行添加123
sed ‘/three/i 123’ 文件名 在three行前添加一行123
sed '$r 文件名1 ’ 文件名2 先读取文件1,再把内容插入文件2行后
sed ‘$a 内容’ 文件名2 将指定内容插入到文件2下一行
sed ‘$i 内容’ 文件名2 将指定内容插入到文件2的倒数第二行
sed命令中字符串和字符的位置交换
echo xxxy | sed -r ‘s/(xxx)(y)/\2\1/’ 交换xxx和y位置
echo xxxyyyzzz | sed -r ‘s/(xxx)(yyy)(zzz)/\3\2\1/’
zzzyyyxxx
echo xxxyyyzzz | sed -r ‘s/(xxx)(yyy)(zzz)/\3\1/’
zzzxxx
echo xxyyzz | sed -r ‘s/(.)(.)(.)/\1\2\3/’
sed -n ‘3p;5p’ test1.txt —输出第三行和第五行
[root@localhost weektest]# sed -n '3p;5p' 111.txt
333
5555
sed -f 后跟保存了sed指令的文件
[root@localhost weektest]# cat 111.txt
/IPADDR=192.168.179.20/c IPADDR=10.10.10.10
[root@localhost weektest]# cat 222.txt
IPADDR=192.168.179.20
[root@localhost weektest]# sed -n -f 111.txt 222.txt
IPADDR=10.10.10.10
读取message 17:30-17:50
sed -n ‘/Mar 24 17:30:01/,/Mar 24 17:50:02/p’ /var/log/message
修改网卡IP
ed -i ‘/^IPADDR/c IPADDR=192.168.179.20’ /etc/sysconfig/network-scripts/ifcfg-ens33
怎么解决sed命令处理容量过大,或者内容过多而导致执行效率慢的问题?
解决方法一:
使用split命令进行文件分割
split -l -30 test1.txt se—按行分割
split -b 400M test1.txt se ----按大小分割
解决方案二:
使用cat 文件名 | sed 处理
(但是该方案只能针对中大型的文件文本,文本量过大,处理效果不好)
执行多条命令的格式:
方式一:
sed -e ‘操作1’ -e ‘操作2’ 文件
sed -n -e ‘/^r/p’ -e’/^b/p’ /etc/passwd p表示打印
方式二:
sed -e ‘操作1;操作2’ 文件
不删除文件的情况下删除文件内容
sed -i ‘d’ 文件名
cat /dev/null > 文件名
touch 文件名 > 文件名
true > 文件名
[:space:] ↩︎