使用HashSet存储自定义类对象时为什么要重写equals和hashCode方法?
作者:GaoYan__Ze
来源:CSDN
原文:https://blog.csdn.net/GaoYan__Ze/article/details/81674079
版权声明:本文为转载文章,原地址如上,尊重原创。
在Java集合的运用中,HashSet抽象类实现了Set接口,我们可以通过HashSet存储Java中定义过的类创建的对象,当然也可以存储我们自定义的类创建的对象。
但是在存储自定义类创建的对象时,就会遇到实际问题导致的漏洞;首先,我们分析一下HashSet类中add()、remove()、contains()方法对同一个对象的判断机制: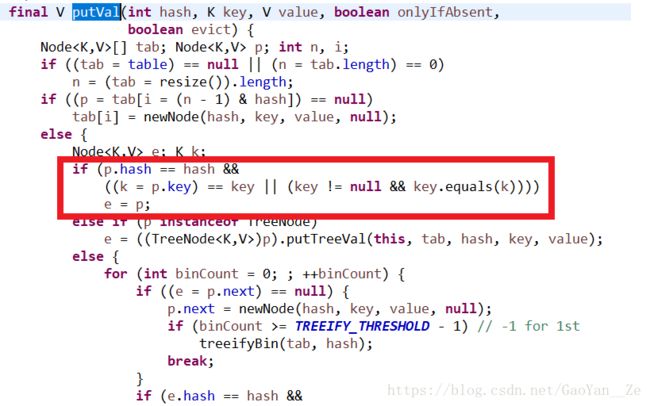
HashSet集合对象如何判断数据元素是否重复:
检查待存对象hashCode值是否与集合中已有元素对象hashCode值相同,如
果hashCode不同则表示不重复, 如果hashCode相同再调用equals方法进一步检查
,equals返回真表示重复,否则表示不重复。
如图中所示,在调用以上方法时,在HashSet类中都会执行红框中的代码去判断传入的对象是否和集合中已存在的对象们重复,首先判断对象所对应的hashCode值是否相同,而Java中的hashCode值是由对象的地址所确定的,每一个地址对应一个值,这是就出现了问题,例如下图的情况:

我们所预想的是由于第一个已经添加了学号为20172430407的Student对象,第二次再次存入的Student对象学号也是20172430407,这在实际中应该是不能存进的,但是由于两次传入的对象并不是同一个,所以它们的地址就不同了,hashCode值也就不同了,这时上面的判断机制就会返回false将它们判断为两个不同的对象,这样就存进了两个实际上代表同一个Student对象的对象。
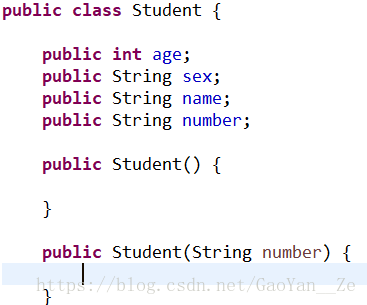
通过上一个例子我们就会明白,我们需要在我们自定义的Student类中重写一个hashCode方法,让学号(number)相同的Student对象的hashCode值相同,这样才能让number相同的对象通过上面判断条件的第一关。
也就是下图的方法,只要让这个方法使调用它的对象获取的是它的number所对应的hashCode即可:
这样一来,第二个学号为20172430407的Student对象就会在第一个判断条件就会为true而进入下一个判断条件,而由于k = p.key) == key比较的是两个对象的地址,所以自然是false,接着就进入key != null && key.equals(k)的判断,而由于Student类中没有equals方法,所以这里调用的是Object类中的equals方法,而通过查找我们发现,Object类中的equals方法比对的仍然是对象的地址,这样返回的结果还是false,那么我们之前所做的努力就白费了,所以我们这里就需要对Student类做一些处理;
这个处理就是在Student类中重写equals方法,来达到我们需要将这两个Student对象判断为实际上是一个对象的目的,下图就是我在Student类中重写的equals方法:
需要注意的是:在重写这个方法的时候,需要考虑到调用这个方法的并不一定是Student类所创建的对象,这时就需要添加一个if语句去判断调用这个方法的对象是否为Student类的实例,如果是,那么我们就将它的number与集合中已有对象的number做对比。
这样一来就解决了所有的问题:使用HashSet存储自定义类对象时,可以在自定义类中重写equals和hashCode方法避免“真实”对象被多次存入,主要原因是集合内不允许有重复的数据元素,在集合校验元素的有效性时(数据元素不可重复),需要调用equals和hashCode验证。