Mybatis源码解析:SQL解析流程

SQL解析
上一节我们提到在解析的过程中一个比较重要的点是,对每个sql进行解析并封装为SqlSource对象

sql定义的方式有很多种,比如用xml,@Select,@SelectProvider等来描述要执行的sql,针对不同的定义方式,mybatis定义了不同的SqlSource实现类


SqlSource接口只有一个方法,传入sql执行的参数,获取BoundSql

这个BoundSql我们在参数处理器这一节再分享,你目前只需要知道BoundSql经过参数处理器处理后就能获取到可以执行的sql
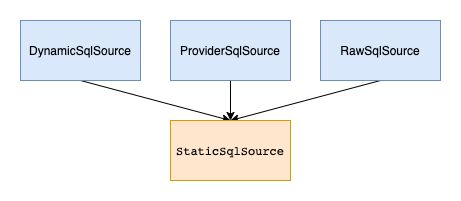
常见的SqlSource实现类的作用如下
| SqlSource | 作用 |
|---|---|
| DynamicSqlSource | 动态sql |
| ProviderSqlSource | @*Provider 注解 提供的 SQL ,这种注解在通用mapper中用的最多 |
| RawSqlSource | 静态sql |
| StaticSqlSource | 仅会含有?的sql |
在执行的过程中会把对应的SqlSource都转为StaticSqlSource,StaticSqlSource就是对BoundSql的一个简单封装
当然如果你想增加另外一种sql定义的方式,只需要实现SqlSource接口即可。
那么问题来了,既然新写了一种sql定义的方式,那么相应的解析程序也要重新实现,不然mybatis根本不知道如何把你定义的sql翻译为可以执行的sql,此时你只需要重写LanguageDriver接口即可,增加你自己的解析实现
网上就有其他大神,重写了LanguageDriver和SqlSource,利用velocity定义了一套sql的解析流程,但是用的人比较少哈。
<dependency>
<groupId>org.mybatis.scriptinggroupId>
<artifactId>mybatis-velocityartifactId>
<version>2.1.0version>
dependency>
加入依赖后,写出来的sql如下所示,有兴趣的小伙伴可以玩玩。
<select id="findPerson" lang="velocity">
#set( $pattern = $_parameter.name + '%' )
SELECT * FROM person WHERE name LIKE @{pattern, jdbcType=VARCHAR}
</select>

LanguageDriver在mybatis中有两个默认实现
XMLLanguageDriver:默认的LanguageDriver,可以处理动态sql和静态sql
RawLanguageDriver:只可以处理静态sql
那么静态sql和动态sql如何区分呢?
举个例子,下面这段sql会被解析为如下的语法树
select id, name, age
from ${tableName}
<where>
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null">
and age = #{age}
</if>
</where>
order by id


在mybatis中是用SqlNode来解析标签中的内容的,每个不同的标签交给不同的SqlNode来进行解析
SqlNode的定义如下,当执行SqlNode#apply方法时,会把标签解析完的sql放到DynamicContext(当所有标签解析完后,就可以从DynamicContext或获取到只会含有#{}占位符的sql)

常见的SqlNode如下,基本上就是一种标签一个SqlNode,MixedSqlNode是一个比较特殊的标签,它是多个标签的一个组合,因为一个标签下可能有很多子标签,这些子标签会被合并为一个MixedSqlNode,典型的组合模式

一段sql描述会被解析为一个MixedSqlNode,然后基于MixedSqlNode来构建SqlSource
XMLScriptBuilder#parseScriptNode

如下为将sql描述转为sql标签的过程
XMLScriptBuilder#parseDynamicTags

对应的内容和解析成的SqlNode的对应关系如下
| 内容 | 解析成的SqlNode |
|---|---|
| if标签中的内容 | IfSqlNode |
| where标签中的内容 | WhereSqlNode |
| 含有${}占位符的静态文本 | TextSqlNode |
| 纯静态文本或含有#{}占位符 | StaticTextSqlNode |
从这个解析过程可以看出来,静态sql为纯静态文本或含有#{}占位符的sql,除此之外都是动态sql(如含有${}占位符号,含有动态sql标签)
静态sql会被封装为RawSqlSource,动态sql会被封装为DynamicSqlSource
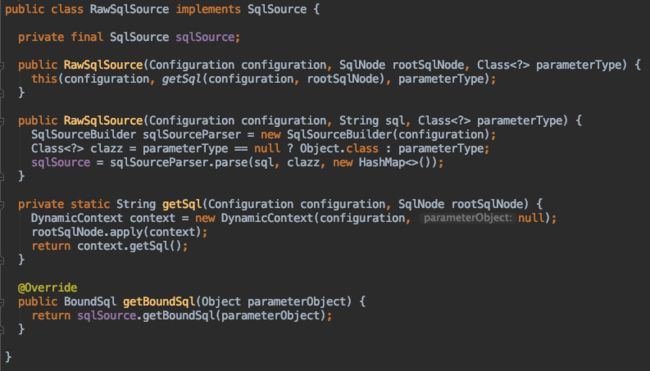
可以看到静态sql在初始化的时候已经解析完成了,SqlSourceBuilder会将#{}替换为?,并将#{}中的内容转为ParameterMapping对象
org.apache.ibatis.builder.SqlSourceBuilder#parse

ParameterMappingTokenHandler#handleToken

我们一般只在#{}中写属性值,但是它其实可以设置很多属性,因此需要转为ParameterMapping对象
<if test="name != null and name != ''">
name = #{name,jdbcType=VARCHAR,typeHandler=org.apache.ibatis.type.StringTypeHandler}
</if>
#{}占位符中可以写的属性如下

将#{}中的内容封装为ParameterMapping对象
StaticSqlSource其实就是对BoundSql的一个简单封装

动态sql在执行的时候,才会执行解析,解析的过程和静态sql类似

分析完静态sql和动态sql,我们可以发现静态sql的执行效率比动态sql的执行效率高,因为静态sql在初始化的时候已经解析完成了,动态sql在执行的时候才会解析
SqlNode解析流程
最后我们挑几个典型的SqlNode来分析一下解过程

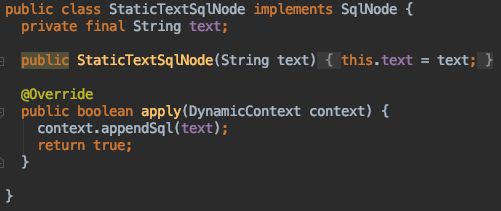
StaticTextSqlNode为纯静态文本或含有#{}占位符的节点,所以直接把内容加到容器中就行
if标签中的表达式为true时,才会将子节点的内容加到DynamicContext中

foreach标签的解析过程比较麻烦,直接看解析后的结果
<select id="selectByIds" resultType="org.apache.ibatis.mytest.UserInfo">
SELECT
<include refid="Base_Column_List"/>
FROM user_info WHERE id in
<foreach collection="list" open="(" close=")" separator="," item="item">
#{item}
</foreach>
</select>
可以看到将foreach标签被替换为#{}占位符,后续会把sql中名字和值的映射关系放到BoundSql的additionalParameters
![]()

foreach标签的解析流程和设置参数的流程比较耗时间,因此当你的foreach标签中的属性过多时,性能会极速下降,这个需要特别注意,此时你可以选择BatchExecutor来执行sql
参考博客
动态sql
[1]https://blog.csdn.net/pan_junbiao/article/details/106763772
[2]https://blog.csdn.net/isea533/article/details/78493852