【OpenCV】车牌自动识别算法的设计与实现
写目录
- 一. 设计任务说明
-
- 1.1 主要设计内容
-
- 1.1.1 设计并实现车牌自动识别算法,基本功能要求
- 1.1.2 参考资料
- 1.1.3 参考界面布局
- 1.2 开发该系统软件环境及使用的技术说明
- 1.3 开发计划
- 二. 系统设计
-
- 2.1 功能分析
-
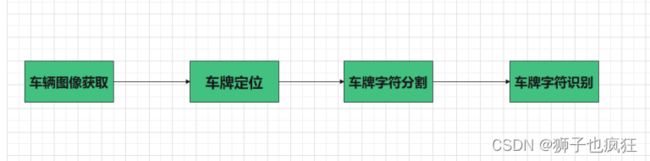
- 2.1.1 车辆图像获取
- 2.1.2 车牌定位
- 2.1.3 车牌字符分割
- 2.1.4 车牌字符识别
- 2.2 部分功能代码实现
- 2.3 概要设计
- 2.4 详细设计
-
- 2.4.1 读取图像
- 2.4.2 降噪
- 2.4.3 二值化
- 2.4.4 将图像边缘连接为一个整体
- 2.4.5 查找车牌(矩形区域)
- 2.4.6 图形修正
- 2.4.7 颜色识别
- 2.4.8 车牌部分二值化
- 2.4.9 字符分割(投影法)
- 2.4.10 匹配模板
- 三. 程序运行结果
- 四. 算法性能
- 五. 总结

一. 设计任务说明
1.1 主要设计内容
1.1.1 设计并实现车牌自动识别算法,基本功能要求
Ⅰ. 对给定的包含有汽车车牌的照片进行处理,利用图像分割算法将目标从背景中分离出来。
Ⅱ. 对目标图像进行合适的处理,然后利用Tesseract库实现车牌号码的识别,将结果输出。
Ⅲ. 要求提供比较友好的用户接口,可以对新的图片导入到系统中进行处理,并将结果返回给用户。
Ⅳ. 要求处理过程的自动化,即输入图像,自动输出车牌信息,无需人去干预。
1.1.2 参考资料
Ⅰ. OpenCV官方参考文档
Ⅱ. Github网站
Ⅲ. 文字识别可以用Tesseract库实现,也可以用其他方式实现
1.1.3 参考界面布局

1.2 开发该系统软件环境及使用的技术说明
PyQt5:5.11.3
opencv-python:4.2
1.3 开发计划

二. 系统设计
2.1 功能分析
2.1.1 车辆图像获取
车辆图像获取是车牌识别的第一步,也是很重要的一步,车辆图像的好坏对后面的工作有很大的影响。如果车辆图像的质量太差,连人眼都没法分辨,那么肯定不会被机器所识别出来。车辆图像都是在实际现场拍摄出来的,实际环境情况比较复杂,图像受天气和光线等环境影响较大,在恶劣的工作条件下系统性能将显著下降。
现有的车辆图像获取方式主要有两种:
一种是由彩色摄像机和图像采集卡组成,其工作过程是:当车辆检测器(如地感线圈、红外线等)检测到车辆进入拍摄范围时,向主机发送启动信号,主机通过采集卡采集一幅车辆图像,为了提高系统对天气、环境、光线等的适应性,摄像机一般采用自动对焦和自动光圈的一体化机,同时光照不足时还可以自动补光照明,保证拍摄图片的质量;另一种是由数码照相机构成,其工作过程是:当车辆检测器检测到车辆进入拍摄范围时,直接给数码照相机发送一个信号,数码相机自动拍摄一幅车辆图像,再传到主机上,数码相机的一些技术参数可以通过与数码相机相连的主机进行设置,光照不足时也需要自动开启补光照明,保证拍摄图片的质量。
2.1.2 车牌定位
车牌定位的主要工作是从摄入的汽车图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来,供字符分割使用。因此,牌照区域的确定是影响系统性能的重要因素之一,牌照的定位与否直接影响到字符分割和字符识别的准确率。目前车牌定位的方法很多,但总的来说可以分为以下4类:
- (1)基于颜色的分割方法,这种方法主要利用颜色空间的信息,实现车牌分割,包括彩色边缘算法、颜色距离和相似度算法等;
- (2)基于纹理的分割方法,这种方法主要利用车牌区域水平方向的纹理特征进行分割,包括小波纹理、水平梯度差分纹理等;
- (3)基于边缘检测的分割方法;
- (4)基于数学形态法的分割方法。
2.1.3 车牌字符分割
要识别车牌字符,前提是先进行车牌字符的正确分割与提取。字符分割的任务是把多列或多行字符图像中的每个字符从整个图像中切割出来成为单个字符。车牌字符的正确分割对字符的识别是很关键的。传统的字符分割算法可以归纳为以下三类:直接分割法、基于识别基础上的分割法、自适应分割线类聚法。
- 直接分割法简单,但它的局限是分割点的确定需要较高的准确性;
- 基于识别基础上的分割法是把识别和分割结合起来,但是需要识别的高准确性,它根据分类和识别的耦合程度又有不同的划分;
- 自适应分割线聚类法是要建立一个分类器,用它来判断图像的每一列是否是分割线,它是根据训练样本来进行自适应学习的神经网络分类器,但对于粘连字符训练困难。也有直接把字符组成的单词当作一个整体来识别的,诸如运用马尔科夫数学模型等方法进行处理,这些算法主要应用于印刷体文本识别。
2.1.4 车牌字符识别
与一般印刷体字符识别相比,车牌字符识别尤其自身的特点,它是文字识别技术与车牌图像自身因素协调兼顾的综合技术,目前,车牌字符识别算法主要是基于模板匹配、特征匹配或神经网络的方法。我国的车牌字符包括50多个汉字,25个大写英文字母,10个数字,总共也就80多个字符,鉴于车牌识别系统的特殊性,如果照搬普通汉字识别的方法,对文字细化后再提取其结构或统计特征,非但得不到意想的结果,反而会降低识别率。
2.2 部分功能代码实现
def __imreadex(self, filename):
return cv2.imdecode(np.fromfile(filename, dtype=np.uint8), cv2.IMREAD_COLOR)
def __point_limit(self, point):
if point[0] < 0:
point[0] = 0
if point[1] < 0:
point[1] = 0
def __find_waves(self, threshold, histogram):
up_point = -1 # 上升点
is_peak = False
if histogram[0] > threshold:
up_point = 0
is_peak = True
wave_peaks = []
for i, x in enumerate(histogram):
if is_peak and x < threshold:
if i - up_point > 2:
is_peak = False
wave_peaks.append((up_point, i))
elif not is_peak and x >= threshold:
is_peak = True
up_point = i
if is_peak and up_point != -1 and i - up_point > 4:
wave_peaks.append((up_point, i))
return wave_peaks
def __seperate_card(self, img, waves):
part_cards = []
for wave in waves:
part_cards.append(img[:, wave[0]:wave[1]])
return part_cards
def __accurate_place(self, card_img_hsv, limit1, limit2, color):
row_num, col_num = card_img_hsv.shape[:2]
xl = col_num
xr = 0
yh = 0
yl = row_num
# col_num_limit = self.cfg["col_num_limit"]
row_num_limit = self.cfg["row_num_limit"]
col_num_limit = col_num * 0.8 if color != "green" else col_num * 0.5 # 绿色有渐变
for i in range(row_num):
count = 0
for j in range(col_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if limit1 < H <= limit2 and 34 < S and 46 < V:
count += 1
if count > col_num_limit:
if yl > i:
yl = i
if yh < i:
yh = i
for j in range(col_num):
count = 0
for i in range(row_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if limit1 < H <= limit2 and 34 < S and 46 < V:
count += 1
if count > row_num - row_num_limit:
if xl > j:
xl = j
if xr < j:
xr = j
return xl, xr, yh, yl
def __preTreatment(self, car_pic):
if type(car_pic) == type(""):
img = self.__imreadex(car_pic)
else:
img = car_pic
pic_hight, pic_width = img.shape[:2]
if pic_width > self.MAX_WIDTH:
resize_rate = self.MAX_WIDTH / pic_width
img = cv2.resize(img, (self.MAX_WIDTH, int(pic_hight * resize_rate)),
interpolation=cv2.INTER_AREA)
#确定车牌颜色
colors = []
for card_index, card_img in enumerate(card_imgs):
green = yellow = blue = black = white = 0
try:
card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)
except:
card_img_hsv = None
if card_img_hsv is None:
continue
row_num, col_num = card_img_hsv.shape[:2]
card_img_count = row_num * col_num
for i in range(row_num):
for j in range(col_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if 11 < H <= 34 and S > 34:
yellow += 1
elif 35 < H <= 99 and S > 34:
green += 1
elif 99 < H <= 124 and S > 34:
blue += 1
if 0 < H < 180 and 0 < S < 255 and 0 < V < 46:
black += 1
elif 0 < H < 180 and 0 < S < 43 and 221 < V < 225:
white += 1
color = "no"
limit1 = limit2 = 0
if yellow * 2 >= card_img_count:
color = "yellow"
limit1 = 11
limit2 = 34
elif green * 2 >= card_img_count:
color = "green"
limit1 = 35
limit2 = 99
elif blue * 2 >= card_img_count:
color = "blue"
limit1 = 100
limit2 = 124
elif black + white >= card_img_count * 0.7:
color = "bw"
# print(color)
colors.append(color)
if limit1 == 0:
continue
xl, xr, yh, yl = self.__accurate_place(card_img_hsv, limit1, limit2, color)
if yl == yh and xl == xr:
continue
need_accurate = False
if yl >= yh:
yl = 0
yh = row_num
need_accurate = True
if xl >= xr:
xl = 0
xr = col_num
need_accurate = True
card_imgs[card_index] = card_img[yl:yh, xl:xr] \
if color != "green" or yl < (yh - yl) // 4 else card_img[yl - (yh - yl) // 4:yh, xl:xr]
if need_accurate:
card_img = card_imgs[card_index]
card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)
xl, xr, yh, yl = self.__accurate_place(card_img_hsv, limit1, limit2, color)
if yl == yh and xl == xr:
continue
if yl >= yh:
yl = 0
yh = row_num
if xl >= xr:
xl = 0
xr = col_num
card_imgs[card_index] = card_img[yl:yh, xl:xr] \
if color != "green" or yl < (yh - yl) // 4 else card_img[yl - (yh - yl) // 4:yh, xl:xr]
return card_imgs, colors
2.3 概要设计
2.4 详细设计
2.4.1 读取图像
使用cv2.imdecode()函数将图片文件转换成流数据,赋值到内存缓存中,便于后续图像操作。使用cv2.resize()函数对读取的图像进行缩放,以免图像过大导致识别耗时过长。
2.4.2 降噪
使用cv2.GaussianBlur()进行高斯去噪。使用cv2.morphologyEx()函数进行开运算,再使用cv2.addWeighted()函数将运算结果与原图像做一次融合,从而去掉孤立的小点,毛刺等噪声。
高斯去噪 :
if blur > 0:
img = cv2.GaussianBlur(img, (blur, blur), 0)
oldimg = img
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('GaussianBlur', img)
kernel = np.ones((20, 20), np.uint8)
img_opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算
img_opening = cv2.addWeighted(img, 1, img_opening, -1, 0); # 与上一次开运算结果融合
# cv2.imshow('img_opening', img_opening)


2.4.3 二值化
使用cv2.threshold()函数进行二值化处理,再使用cv2.Canny()函数找到各区域边缘。
ret, img_thresh = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) # 二值化
img_edge = cv2.Canny(img_thresh, 100, 200)
# cv2.imshow('img_edge', img_edge)

2.4.4 将图像边缘连接为一个整体
使用**cv2.morphologyEx()和cv2.morphologyEx()**两个函数分别进行一次开运算(先腐蚀运算,再膨胀运算)和一个闭运算(先膨胀运算,再腐蚀运算),去掉较小区域,同时填平小孔,弥合小裂缝。将车牌位置凸显出来。
kernel = np.ones((self.cfg["morphologyr"], self.cfg["morphologyc"]), np.uint8)
img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel) # 闭运算
img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel) # 开运算
# cv2.imshow('img_edge2', img_edge2)

2.4.5 查找车牌(矩形区域)
查找图像边缘整体形成的矩形区域,可能有很多,车牌就在其中一个矩形区域中,逐个排除不是车牌的矩形区域。车牌形成的矩形区域长宽比在2到5.5之间,因此使用cv2.minAreaRect()函数框选矩形区域计算长宽比,长宽比在2到5.5之间的可能是车牌,其余的矩形排除。最后使用cv2.drawContours()函数将可能是车牌的区域在原图中框选出来。

2.4.6 图形修正
矩形区域可能是倾斜的矩形,需要矫正,以便使用颜色定位,从而进一步确认是否是车牌。类似下两图(仅列举出两个,可能有很多)。
在这里插入图片描述 在这里插入图片描述

2.4.7 颜色识别
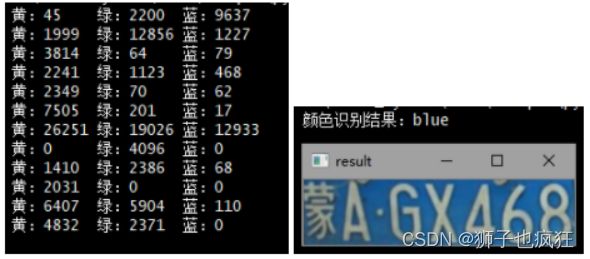
使用颜色定位,排除不是车牌的矩形,目前只识别车牌的颜色主要为蓝、绿、黄三种颜色车牌。根据矩形的颜色不同从而选出最可能是车牌的矩形。同时匹配出车牌的类型(颜色类型)。使用参数为cv2.COLOR_BGR2HSV的cv2.cvtColor()函数将原始的RGB图像转换成HSV图像,以便定位颜色。
基于HSV颜色模型可知色调H的取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;查阅相关资料确定出下表:
| 黄色 | 绿色 | 蓝色 | |
|---|---|---|---|
| H | 14-34 | 34-99 | 99-124 |
根据上表计算出每个矩形中各颜色的占有量,比较每个矩形三个颜色的占有量,即可确定最可能是车牌的矩形以及车牌颜色。
2.4.8 车牌部分二值化
利用参数为cv2.COLOR_BGR2GRAY的cv2.cvtColor()函数将定位到的车牌部分RGB图像转化为灰度图像,再利用cv2. threshold() 函数将灰度图像二值化。需要注意的是,黄、绿色车牌字符比背景暗、与蓝的车牌刚好相反,所以黄、绿车牌在二值化前需要利用cv2.bitwise_not( )函数取反向。
# 做一次锐化处理
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32) # 锐化
card_img = cv2.filter2D(card_img, -1, kernel=kernel)
# cv2.imshow("custom_blur", card_img)
# RGB转GARY
gray_img = cv2.cvtColor(card_img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('gray_img', gray_img)
# 黄、绿车牌字符比背景暗、与蓝车牌刚好相反,所以黄、绿车牌需要反向
if color == "green" or color == "yellow":
gray_img = cv2.bitwise_not(gray_img)
# 二值化
ret, gray_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# cv2.imshow('gray_img', gray_img)
2.4.9 字符分割(投影法)
根据设定的阈值和图片直方图,找出波峰,利用找出的波峰,分隔图片。因为车牌中“ • ”也会产生一组波峰,因此将八组波峰中的第三组去除掉,即可得到每个字符的波峰,再根据每组波峰的宽度分割牌照图像得到每个字符的图像。

2.4.10 匹配模板
将分割后的每个图像逐个与已训练好的模板进行匹配,得到识别结果。
from _collections import OrderedDict
from flask import Flask, request, jsonify
from json_utils import jsonify
import numpy as np
import cv2
import time
from collections import OrderedDict
from Recognition import PlateRecognition
# 实例化
app = Flask(__name__)
PR = PlateRecognition()
# 设置编码-否则返回数据中文时候-乱码
app.config['JSON_AS_ASCII'] = False
# route()方法用于设定路由;类似spring路由配置
@app.route('/', methods=['POST']) # 在线识别
def forecast():
# 获取输入数据
stat = time.time()
file = request.files['image']
img_bytes = file.read()
image = np.asarray(bytearray(img_bytes), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
RES = PR.VLPR(image)
if RES is not None:
result = OrderedDict(
Error=0,
Errmsg='success',
InputTime=RES['InputTime'],
UseTime='{:.2f}'.format(time.time() - stat), # RES['UseTime'],
Number=RES['Number'],
From=RES['From'],
Type=RES['Type'],
List=RES['List'])
else:
result = OrderedDict(
Error=1,
Errmsg='unsuccess')
return jsonify(result)
if __name__ == '__main__':
app.run()
三. 程序运行结果
系统测试结果
点击打开文件,在本地中选择要识别的车辆的照片
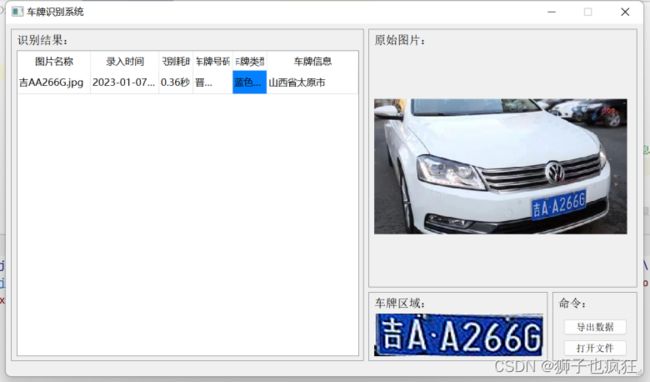

点击导出数据,得到所识别的车牌数据

四. 算法性能
每次处理时间小于1s
算法准确度为97%
五. 总结
设计过程中对于车牌部分的矩形的识别,出现识别错误区域的问题,通过查找网上的相关案例设定好判断条件以及和周围相同题目的同学请教其如何识别出车牌区域得以解决。通过此次综合项目练习,让我对以往的知识点的运用有了更进一步的实践和运用。
tips:
一个数字图像分析期末考核实验,如果您喜欢,可以一键三连哟!!!
【源码获取】pull