1.CentOS7 搭建 Hadoop 单节点模式
目录
- 1.前期准备
-
- 1.1.硬件要求
- 1.2.jdk8 环境
- 1.3.ssh 命令
- 1.4.关闭防火墙
- 1.5.下载 Hadoop
- 2.安装 Hadoop
-
- 2.1.上传安装包并解压
- 2.2.配置 JAVA_HOME
- 2.3.伪分布模式启动 Hadoop
-
- 2.3.1.配置
- 2.3.2.配置 root 用户运行
- 2.3.3运行 Hadoop
- 3.安装 Yarn
-
- 3.1.配置
- 3.2.配置 root 用户运行
- 3.3.运行 Yarn
本文旨在搭建一个简单的 Hadoop 环境用于编程,依据官方文档而成,补充了几个搭建过程中可能会遇到的问题。官方文档地址:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
1.前期准备
1.1.硬件要求
CentOS7 服务器一台,虚拟机也可以,保证网络畅通
[root@localhost ~]# ping www.baidu.com
PING www.wshifen.com (103.235.46.39) 56(84) bytes of data.
64 bytes from 103.235.46.39 (103.235.46.39): icmp_seq=2 ttl=128 time=249 ms
1.2.jdk8 环境
jdk8 环境搭建参见笔者的另一篇文章:
CentOS7 安装 jdk8
1.3.ssh 命令
直接执行安装命令
[root@localhost ~]# yum install ssh
检查是否能够免密登录本机
[root@localhost ~]# ssh localhost
开启本机的免密访问权限
[root@localhost ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@localhost ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@localhost ~]# chmod 0600 ~/.ssh/authorized_keys
1.4.关闭防火墙
[root@localhost hadoop]# systemctl stop firewalld.service
[root@localhost hadoop]# systemctl disable firewalld.service
1.5.下载 Hadoop
选择合适的版本下载,笔者的版本是3.3.2
下载地址
2.安装 Hadoop
2.1.上传安装包并解压
[root@localhost usr]# pwd
/usr
[root@localhost usr]# tar -xvf hadoop-3.3.2.tar.gz
// 给文件夹改名
[root@localhost usr]# mv hadoop-3.3.2/ hadoop/
// 删除安装包
[root@localhost usr]# rm -rf hadoop-3.3.2.tar.gz
2.2.配置 JAVA_HOME
[root@localhost usr]# cd hadoop/
[root@localhost hadoop]# pwd
/usr/hadoop
[root@localhost hadoop]# vi etc/hadoop/hadoop-env.sh
修改如下内容:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/java/jdk1.8.0_333
2.3.伪分布模式启动 Hadoop
2.3.1.配置
etc/hadoop/core-site.xml:
fs.defaultFS
hdfs://localhost:9000
etc/hadoop/hdfs-site.xml:
dfs.replication
1
2.3.2.配置 root 用户运行
hadoop中没有默认root的用户,需要手动添加。
sbin/start-dfs.sh 和 sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
关闭CentOS中SELinux
/etc/selinux/config
SELINUX=disabled
2.3.3运行 Hadoop
- 格式化文件系统
[root@localhost hadoop]# bin/hdfs namenode -format
- 运行NameNode和DataNode
[root@localhost hadoop]# sbin/start-dfs.sh
- 打开浏览器访问:
http://ip:9870/ - 创建执行 MepReduce 任务所需的文件夹
[root@localhost hadoop]# bin/hdfs dfs -mkdir /user
[root@localhost hadoop]# bin/hdfs dfs -mkdir /user/root
- 将输入文件拷贝至 Hdfs
[root@localhost hadoop]# bin/hdfs dfs -mkdir input
[root@localhost hadoop]# bin/hdfs dfs -put etc/hadoop/*.xml input
- 运行示例
[root@localhost hadoop]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar grep input output 'dfs[a-z.]+'
- 查看运算结果
[root@localhost hadoop]# bin/hdfs dfs -cat output/*
- 关闭 Hadoop
[root@localhost hadoop]# sbin/stop-dfs.sh
3.安装 Yarn
3.1.配置
etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
3.2.配置 root 用户运行
sbin/start-yarn.sh 和 sbin/stop-yarn.sh 添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.3.运行 Yarn
运行 Yarn 之前,确保 sbin/start-dfs.sh 已经执行。
- 启动 ResourceManager 和 NodeManager
[root@localhost hadoop]# sbin/start-yarn.sh
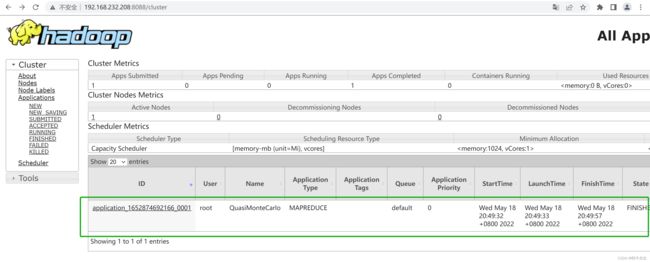
- 打开浏览器访问:
http://ip:8088/ - 运行任务
[root@localhost hadoop]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 2 3
可以通过浏览器查看任务的运行情况
4. 关闭 Yarn
[root@localhost hadoop]# sbin/stop-yarn.sh