鲲鹏服务器+openEuler 搭建Hadoop完全分布式集群
【基本流程】
- 下载并解压Hadoop、JDK安装包并配置好环境变量、节点域名解析、防火墙、端口
- 进入Hadoop的解压目录,编辑hadoop-env.sh文件
- 编辑Hadoop中配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml四个核心配置文件
- 配置ssh,生成密钥,用ssh免密在各节点间切换
- 格式化HDFS 并使用./start-all.sh启动Hadoop集群
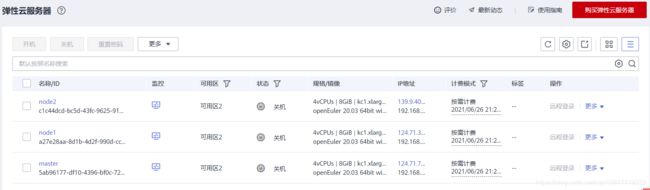
【1】购买云服务器
首先准备三台华为ECS云服务器,配置如下:
- CPU架构:鲲鹏计算
- 规格:4vCPUs | 8GiB | kc1.xlarge.2 (可自行选择更高规格)
- 镜像:openEuler 20.03 64bit with ARM
- 购买公网IP,并设置带宽 100Mbit/s (为后面的下载提速)
- 分别设置服务器名为:master、node1、node2
【2】准备工作
(在这里推荐一款超级棒的终端神器 MobaXterm,可自行百度,在其官网下载)
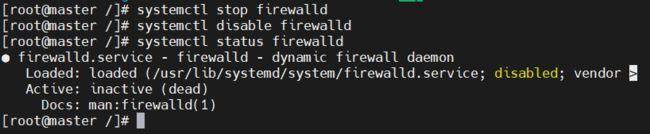
1. 在所有节点中均关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2. 查看防火墙状态(按q退出查看)
systemctl status firewalld
从这里开始只操作你的master(主节点)服务器,除非特地说明操作所有节点
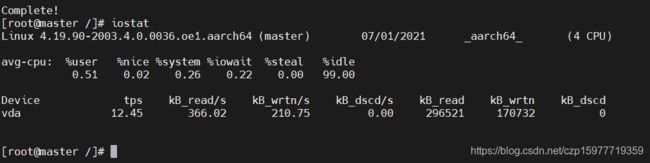
3. 安装资源检测工具(可自行安装其他其他工具)
yum install sysstat
运行iostat查看云服务器状态
iostat
配置域名解析:
vi /etc/hosts

把里面的127.0.0.1 master master改行删除
然后添加自己服务器的内网IP地址和服务器名

然后保存退出
按ESC,然后输入冒号+wq(:wq)
【3】安装JDK并配置环境变量
这里安装在home下(可选其他位置)
cd home
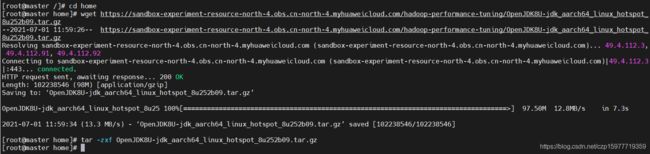
然后下载openJDK-1.8.0并安装(华为云的源会相对更快):
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/hadoop-performance-tuning/OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gz
解压
tar -zxf OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gz
配置环境变量
vi /etc/profile
在最末尾添加
export JAVA_HOME=/home/jdk8u252-b09
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
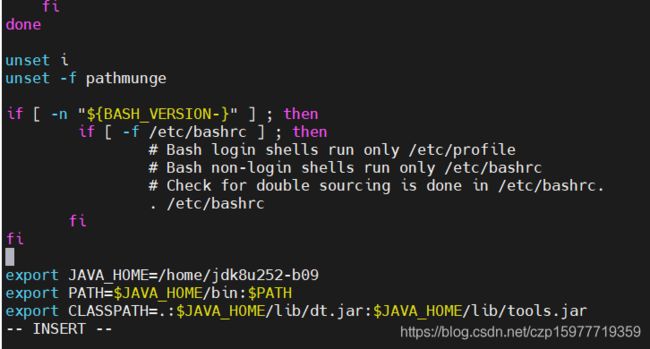
然后保存退出
使环境变量生效:
source /etc/profile
然后可以验证环境变量时候配置成功:
java -version

【4】部署hadoop
下载安装包到home下
cd /home
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/hadoop-performance-tuning/hadoop-3.1.1.tar.gz
#解压hadoop-3.1.1
tar -zxvf hadoop-3.1.1.tar.gz
建立软连接
ln -s hadoop-3.1.1 hadoop
配置hadoop环境变量,打开/etc/profile文件
vi /etc/profile
点击键盘"Shift+g"移动光标至文件末尾,单击键盘“i”键进入编辑模式,在代码末尾回车下一行,添加如下内容
export HADOOP_HOME=/home/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
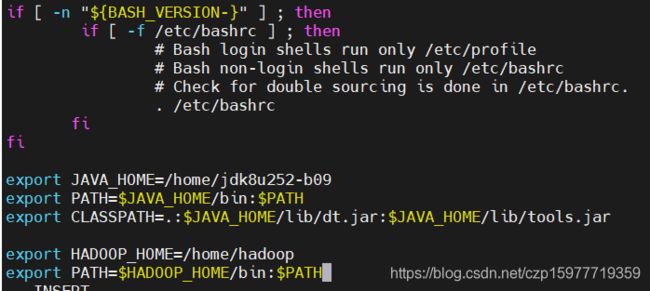
然后保存退出
使环境变量生效
source /etc/profile
验证hadoop安装是否成功
hadoop version
安装成功:

【5】修改hadoop配置文件
共需要修改五个文件的配置:hdfs-env.xml,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml
以上五个文件都在 $HADOOP_HOME/etc/hadoop/目录下,先进入
cd $HADOOP_HOME/etc/hadoop/
5.1 配置hdfs-env.xml
vi hadoop-env.sh
找到hadoop-env.sh的第54行中的java目录(在命令模式下输入“:set nu”,查看行数),输入java的安装目录(),然后删除行左端“#”取消注释,并保存退出
export JAVA_HOME=/home/jdk8u252-b09
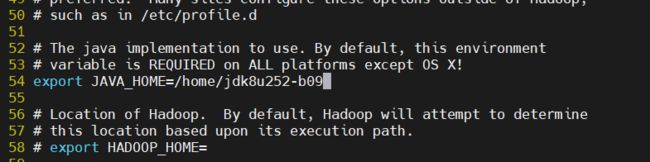
5.2 配置core-site.xml
vi core-site.xml
在configuration标签之间添加如下代码并保存退出
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
<description> 设定NameNode的主机名及端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp/hadoop-${user.name}</value>
<description>指定hadoop 存储临时文件的目录 </description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
<description>配置该superUser允许通过代理的用户 </description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
<description>配置该superUser允许通过代理用户所属组 </description>
</property>
<!-- 设置以下两步用于web上可手动上传和下载文件 -->
<!-- 设置用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 不开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
5.3 配置hdfs-site.xml
vi hdfs-site.xml
在configuration标签之间添加如下代码并保存退出
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
<description> NameNode 地址和端口 </description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
<description> Secondary NameNode地址和端口 </description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description> 设定 HDFS 存储文件的副本个数,默认为3 </description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hadoop3.1.1/hdfs/name</value>
<description> NameNode用来持续存储命名空间和交换日志的本地文件系统路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hadoop3.1.1/hdfs/data</value>
<description> DataNode在本地存储块文件的目录列表</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/hadoop/hadoop3.1.1/hdfs/namesecondary</value>
<description> 设置 Secondary NameNode存储临时镜像的本地文件系统路径。如果这是一个用逗号分隔的文件列表,则镜像将会冗余复制到所有目录
</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>是否允许网页浏览HDFS文件</description>
</property>
<property>
<name>dfs.stream-buffer-size</name>
<value>1048576</value>
<description> 默认是4 KB,作为Hadoop缓冲区,用于Hadoop读HDFS的文件和写HDFS的文件,
还有map的输出都用到了这个缓冲区容量(如果太大了map和reduce任务可能会内存溢出)
</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
5.4 配置mapred-site.xml
vi mapred-site.xml
在configuration标签之间添加如下代码并保存退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description> 指定MapReduce程序运行在Yarn上 </description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description> 指定历史服务器端地址和端口 </description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description> 历史服务器web端地址和端口</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/hadoop/etc/hadoop,
/home/hadoop/share/hadoop/common/*,
/home/hadoop/share/hadoop/common/lib/*,
/home/hadoop/share/hadoop/hdfs/*,
/home/hadoop/share/hadoop/hdfs/lib/*,
/home/hadoop/share/hadoop/mapreduce/*,
/home/hadoop/share/hadoop/mapreduce/lib/*,
/home/hadoop/share/hadoop/yarn/*,
/home/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>6144</value>
<description> map container配置的内存的大小(调整到合适大小防止物理内存溢出)这里我的服务器是8G内存,6144M不会超过8G</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>6144</value>
<description> reduce container配置的内存的大小(调整到合适大小防止物理内存溢出)</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop</value>
</property>
5.5 配置yarn-site.xml
vi yarn-site.xml
在configuration标签之间添加如下代码并保存退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description> 指定ResourceManager的主机名</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
<description> NodeManager总的可用物理内存。
注意:该参数是不可修改的,一旦设置,整个运行过程中不可动态修改。
该参数的默认值是8192MB,即使你的机器内存不够8192MB,YARN也会按照这些内存来使用,因此,这个值通过一定要配置。
</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description> 指定MapReduce走shuffle</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
<description> 指定ResourceManager对客户端暴露的地址和端口,客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
<description> 指定ResourceManager对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
<description> 指定ResourceManager对NodeManager暴露的地址。NodeManager通过该地址向RM汇报心跳,领取任务等</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
<description> 指定ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
<description> 指定ResourceManager对外web UI地址。用户可通过该地址在浏览器中查看集群各类信息</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description> 开启日志聚集功能</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
<description> 设置日志聚集服务器地址</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<description> 设置日志保留时间为7天</description>
</property>
5.6 将各节点信息加入到workers
workers文件在$HADOOP_HOME/etc/hadoop/目录下
echo master > workers
echo node1 > workers
echo node2 > workers
5.7 修改dfs和yarn的启动脚本,添加root用户权限
5.7.1 编辑start-dfs.sh和stop-dfs.sh文件
vi /home/hadoop/sbin/start-dfs.sh
vi /home/hadoop/sbin/stop-dfs.sh
分别在以上两个文件的第一行添加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
5.7.2 编辑start-yarn.sh 和 stop-yarn.sh文件
vi /home/hadoop/sbin/start-yarn.sh
vi /home/hadoop/sbin/stop-yarn.sh
分别在以上两个文件的第一行添加如下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
【6】 同步主节点master的配置到node1,node2从节点
6.1 连通性测试
ping -c 3 master
ping -c 3 node1
ping -c 3 node2
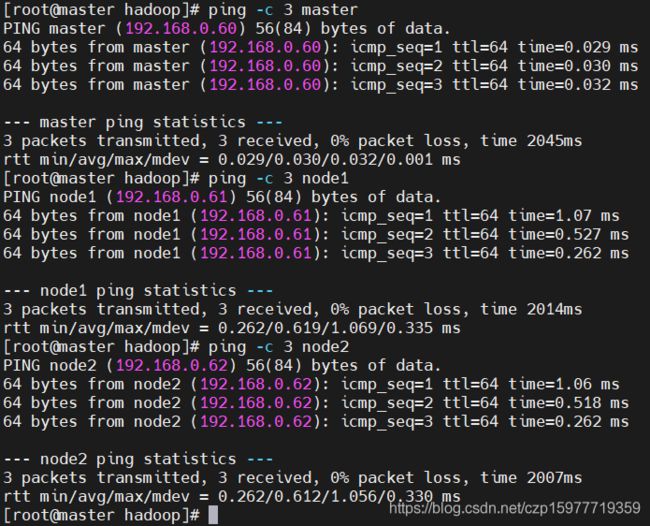
6.2 将主节点master的hosts文件同步至node1和node2从节点
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
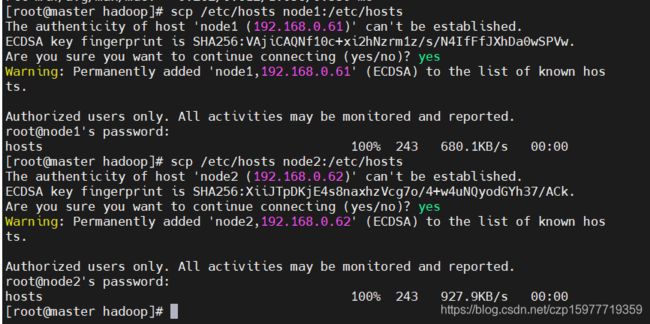
6.3 配置各节点间SSH免密登录
同时对三台云服务器输入以下命令(遇到提示就按回车即可):
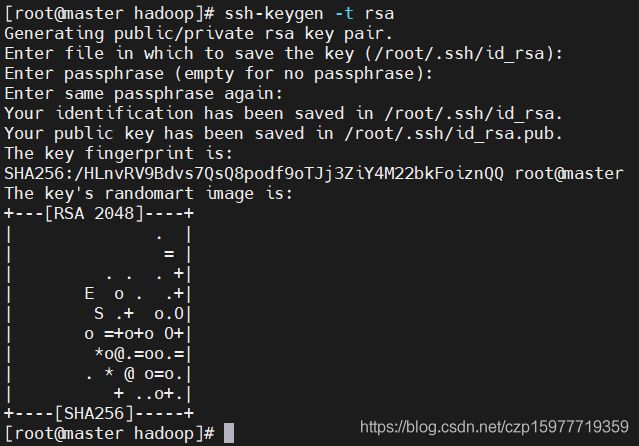
ssh-keygen -t rsa
master:
node1:略
node2:略
然后分别在三台服务器上输入命令以复制公钥到服务器中
ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
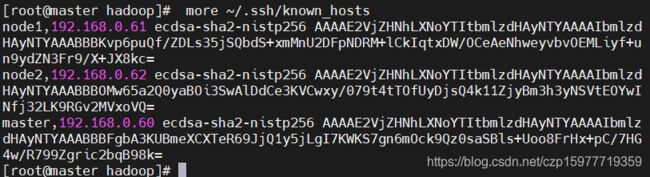
然后查看所有协商的秘钥
more ~/.ssh/known_hosts
master:
node1:
node2:
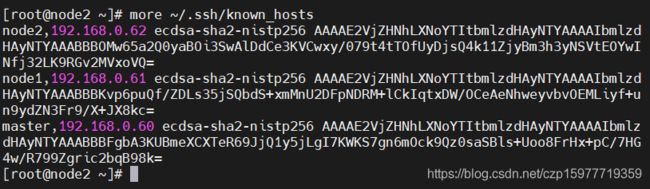
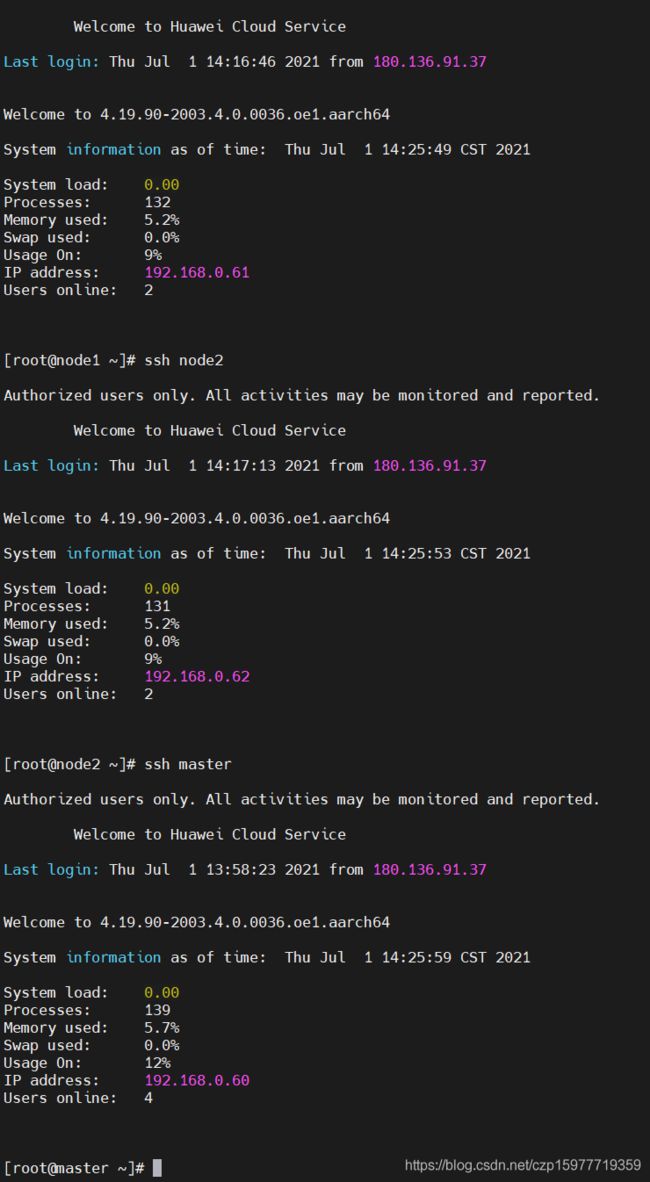
然后用以下命令可在各个节点间切换
ssh master
ssh node1
ssh node2
6.4 复制hadoop到各datanode并修改
把master的hadoop目录、jdk目录复制到node1,node2节点
cd $HADOOP_HOME/..
#hadoop目录
scp -r hadoop node1:/home
scp -r hadoop node2:/home
#java目录
scp -r jdk8u252-b09 node1:/home
scp -r jdk8u252-b09 node2:/home
登录node1和node2节点修改java和haoop环境变量
vi /etc/profile
在文件最后插入以下内容
export JAVA_HOME=/home/jdk8u252-b09
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
使环境变量生效
source /etc/profile
【7】启动hadoop
第一次启动前一定要格式化HDFS
hdfs namenode -format
注意:提示信息的倒数第2行出现“>= 0”表示格式化成功,如图。在Linux中,0表示成功,1表示失败。因此,如果返回“1”,就应该好好分析前面的错误提示信息,一 般来说是前面配置文件和hosts文件的问题,修改后同步到其他节点上以保持相同环境,再接着执行格式化操作
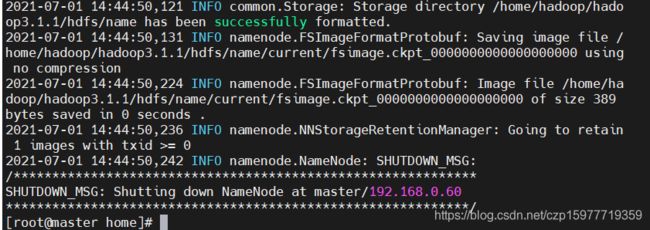
执行以下命令,启动所有节点
cd /home/hadoop/sbin
#群起节点
./start-all.sh
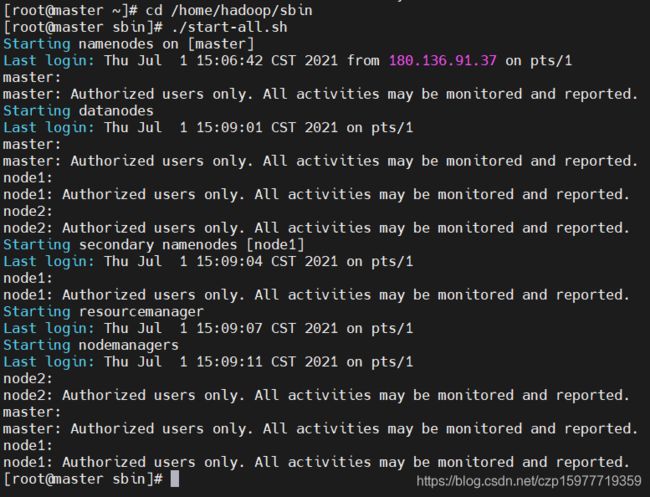
可用 jps在各个节点查看是否开启成功
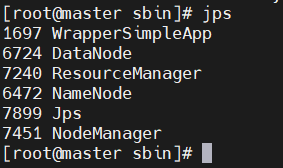
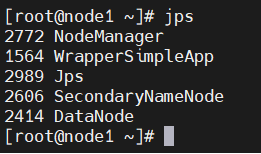
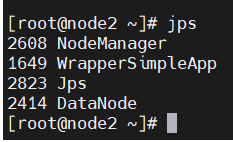
如上图则启动成功,如少了哪个服务未启动,可以用相关命令在对应节点单独启动
hdfs --daemon start namenode
hdfs --daemon start datanode
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
【8】web访问测试
在网页输入(ip地址:50070)可访问NameNode的webUI界面
在网页输入(ip地址:8088)可访问RMwebUI界面
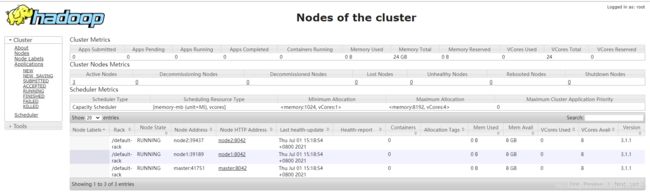
【9】集群测试
使用Hadoop自带的WordCount例子/share/Hadoop/mapredu icehadoop-mapreduce-examples-3.1.1.jar验证集群
#创建目录,目录/data/wordcount用来存储Hadoop自带的WordCount例子的数据文件,运行这个MapReduce任务的结果输出到目录中的/output/wordcount文件中
hdfs dfs -mkdir -p /data/wordcount
hdfs dfs -mkdir -p /output/
#将本地文件上传到HDFS中(这里上传一个配置文件),执行如下命令
hdfs dfs -put /home/hadoop/etc/hadoop/core-site.xml /data/wordcount
可以查看,上传后的文件情况,执行如下命令
hdfs dfs -ls /data/wordcount

下面运行WordCount案例,执行如下命令
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /data/wordcount /output/wordcount
DFSIO测试:使用hadoop的DFSIO写入50个文件,每个文件10M(可自行选择文件个数和大小)
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.1-tests.jar TestDFSIO -write -nrFiles 50 -filesize 10
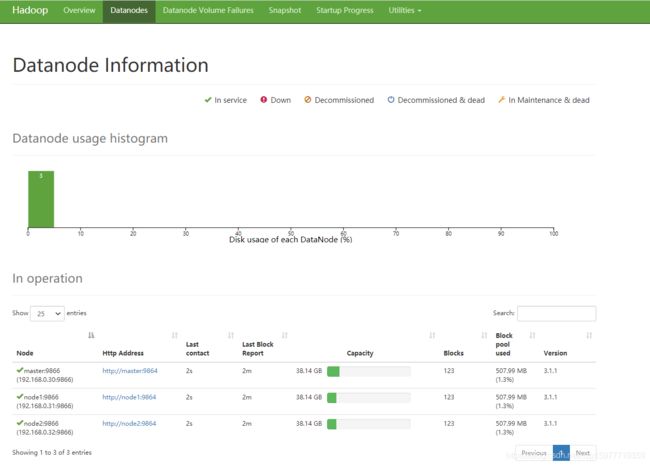
可以在web上的datanode查看各个节点HDFS占用情况
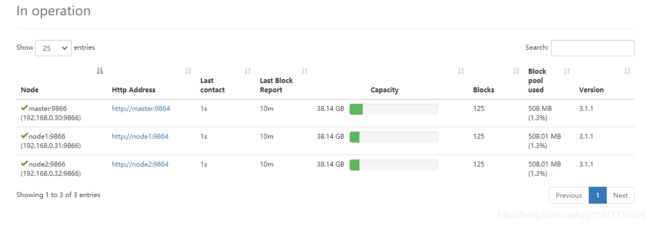
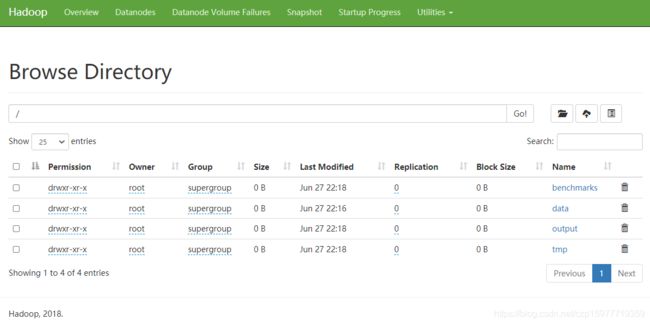
【10】可能遇到的问题及解决方案
10.1 关机重启后不能通过web访问
使用如下命令,可查看HDFS的状态
hdfs dfsadmin -report
发现主节点的IP地址和名称可能与之前设置的不同,会导致不能与其他节点互相组成集群
原因是重启后,/etc/profile又重新自动加载了系统自带映射,需要删除掉该行:127.0.0.1 master master
然后保存退出,用命令更新一下: source /etc/profile
然后执行下面命令同步hosts的配置到其他节点
scp -r /etc/hosts node1:/etc/hosts
scp -r /etc/hosts node2:/etc/hosts
重启hadoop,尝试访问web
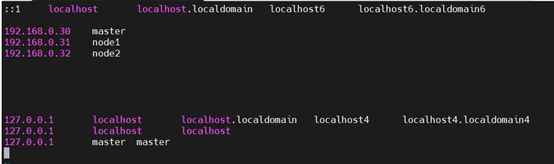
10.2 不能在web手动上传文件
在系统环境变量中的系统变量Path添加
%HADOOP_HOME%\bin
可能需要重启电脑才能生效
本人在参考博客的基础上做了修改,特别是hadoop配置文件的内容不尽相同,还增加了部分可能会遇到的问题及其解决方案,谢谢大家的阅读~
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/devcloud/article/details/115346499