在vmbox里面安装Ubuntu16.04并且配置jdk以及Hadoop配置的教程【附带操作步骤】
系列文章目录
Hadoop升级命令 sudo apt-get update报错问题,_张小鱼༒的博客-CSDN博客
Hadoop与主机连接以及20版本的Hadoop配置网络的问题_hadoop未指定主机host网卡_张小鱼༒的博客-CSDN博客
Hadoop升级update命令被锁定的解决方法_hadoop锁定符号怎么去掉_张小鱼༒的博客-CSDN博客
文章目录
目录
系列文章目录
文章目录
前言
一、安装Ubuntu16.04步骤
二、对虚拟机的网络以及相关主机映射的配置
2.1、查看WLAN的对应网络IP
2.2、进入etc的network目录下,修改interfaces文件
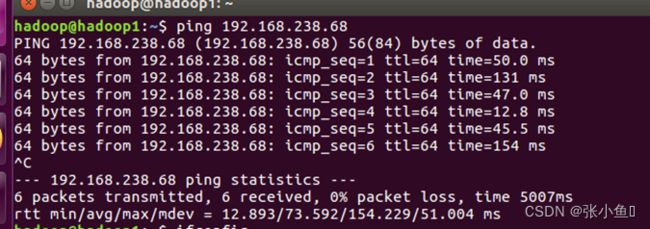
2.3三台主机能够实现互通的截图:
2.4、修改主机名称和添加相关的映射关系
三、建立ssh本地连接以及上传密钥
3.1、下载ssh到虚拟机里面
3.2、生成密钥【仅以一台展示】
3.3、加入授权
3.4、进行免密登录
四、配置jdk环境到虚拟机
4.1、上传配置的jdk文件到对应的虚拟机
4.2、解压缩文件
4.3、移动jdk到op t目录
4.4、进入opt目录下对jdk重新命名
4.5、配置环境变量
4.6、进入系统目录下面的bashrc文件里面配置环境变量
4.7、查看Java是否配置成功
五、配置Hadoop环境
5.1、上传Hadoop
5.2、解压Hadoop文件
5.3、将解压后的文件上传到opt目录
5.4、进入opt目录下将Hadoop的文件名进行修改并验证
六、Hadoop伪分布式搭建
6.1、进入Hadoop目录下,配置相关的文件
6.2、配置core-site.xml文件
6.3、配置hdfs-site.xml文件
6.4、成功配置的提示
6.5、配置Hadoop环境变量
6.6、进入 /opt/Hadoop/下启动之前的hdfs
6.7、关闭hdfs服务
总结
前言
学习Linux操作时,常常需要安装虚拟机进行相关的操作,但是操作是基于环境的,以下以其中的一种虚拟机做参考进行介绍,环境是Ubuntu16.04,在vmbox里面,以及jdk与Hadoop压缩包
提示:以下是本篇文章正文内容,下面步骤仅供参考
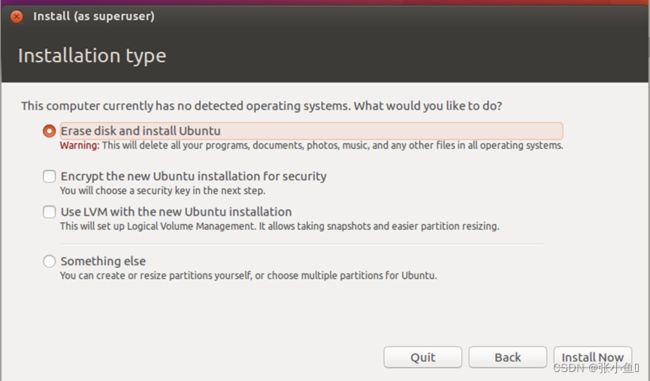
一、安装Ubuntu16.04步骤
安装Ubuntu16.04
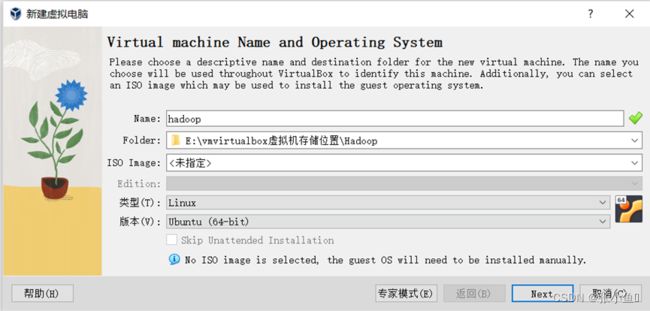
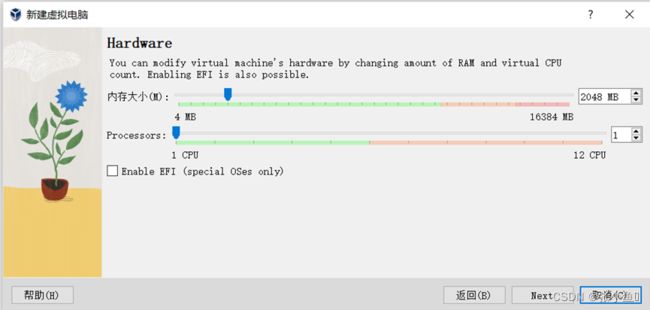



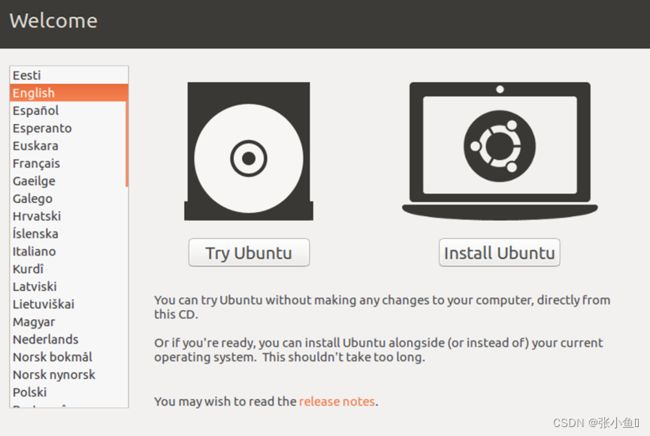
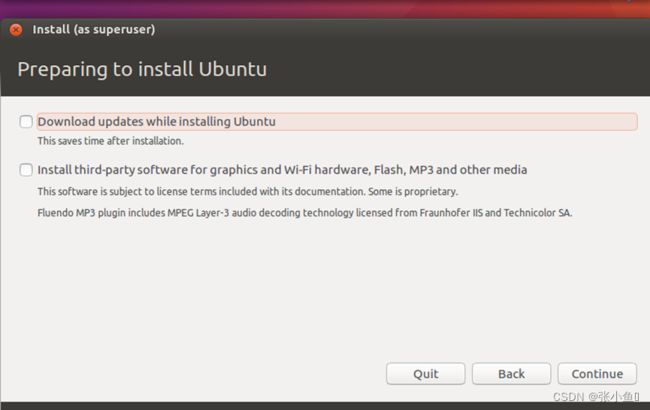

此处选择你所在的地区
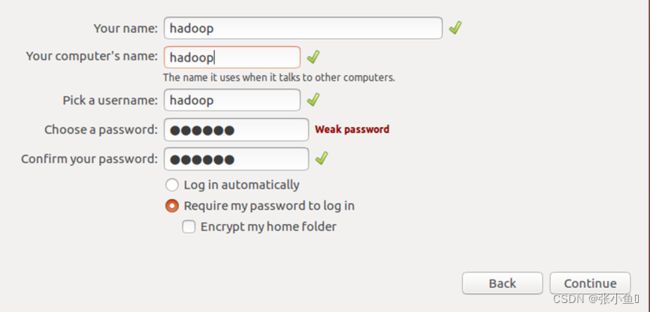
添加用户名与主机名称以及相关的密码,设置完成之后安装,安装完成之后重启计算机就可以了
附加相关软件与压缩包:
来自于百度网盘资源
jdk资源:
链接:https://pan.baidu.com/s/1TS9Yh9F4l6KC-mNHUWrv9w
提取码:l4w6
链接:https://pan.baidu.com/s/19p-v5RRQun19HZL3oPtmEA
提取码:r0a4
两个链接都有效
Hadoop资源:
链接:https://pan.baidu.com/s/1Q3WxEQrU3t-mVV572ZWN3A
提取码:4b4s
Ubuntu资源:
链接:https://pan.baidu.com/s/1of4W84NfL_F2mX3xXefvoQ
提取码:o9g4
二、对虚拟机的网络以及相关主机映射的配置
2.1、查看WLAN的对应网络IP

2.2、进入etc的network目录下,修改interfaces文件

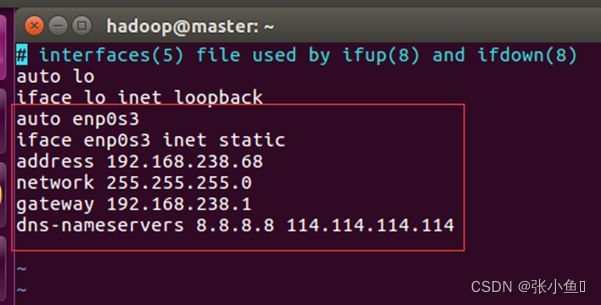


2.3三台主机能够实现互通的截图:
Master

Slave1

Slave2


2.4、修改主机名称和添加相关的映射关系
Sudo vim /etc/hosts
Sudo vim /etc/hostname

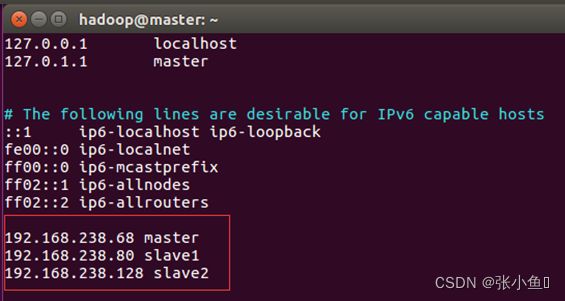
映射关系
192.168.238.68 master
192.168.238.86 slave1
192.168.238.128 slave2
三台的修改的截图
Master:

Slave1:


Slave2:

三、建立ssh本地连接以及上传密钥
3.1、下载ssh到虚拟机里面
Sudo apt-get install openssh-service
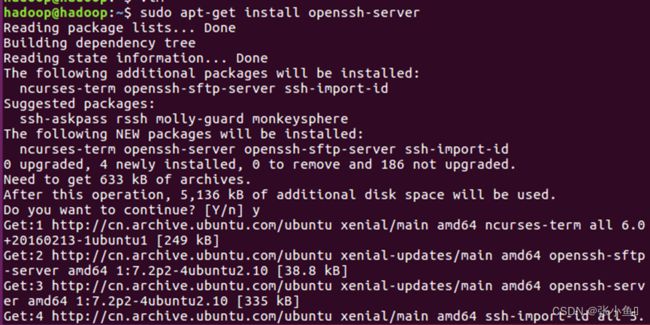
Ssh localhost

3.2、生成密钥【仅以一台展示】
cd ~/.ssh/
ssh -keygen -t rsa

3.3、加入授权
cat ./id_rsa.pub >> ./authorized_keys
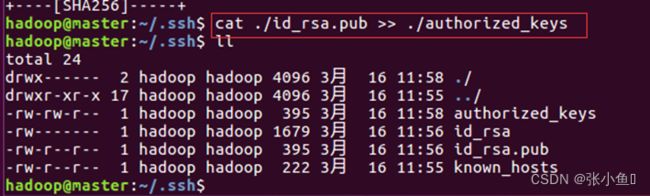
3.4、进行免密登录

四、配置jdk环境到虚拟机
4.1、上传配置的jdk文件到对应的虚拟机
scp jdk-8u321-linux-x64.tar.gz [email protected]:/home/hadoop/
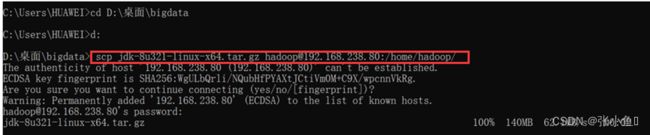
注意此处先进入存放压缩包的目录里面,再进行上传
4.2、解压缩文件
tar -zxvf jdk-8u321-linux-x64.tar.gz

4.3、移动jdk到op t目录
sudo mv jdk1.8.0_321/ /opt/

4.4、进入opt目录下对jdk重新命名
sudo mv jdk1.8.0_321/ jdk1.8
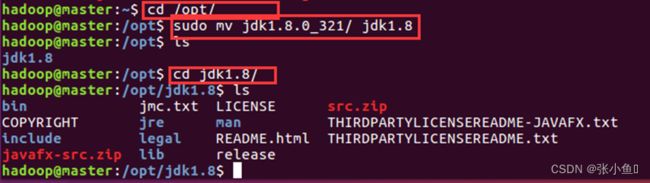
4.5、配置环境变量
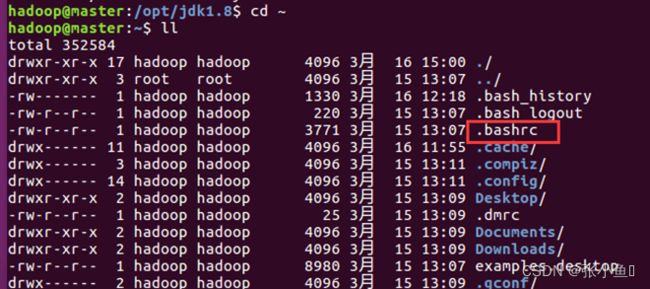
4.6、进入系统目录下面的bashrc文件里面配置环境变量
![]()
#配置Java环境变量
export JAVA_HOME=/opt/jdk1.8
export JRE_HOME=/$JAVA_HOME/jre
export CLASSPATH=.:${JAVA_HOME}/lib:$JRE_HOME/lib
export PATH=$PATH:${JAVA_HOME}/bin

4.7、查看Java是否配置成功

五、配置Hadoop环境
5.1、上传Hadoop
scp hadoop-2.7.1.tar.gz [email protected]:/home/hadoop/
![]()
与上传jdk一样,需要先进入压缩包的目录
5.2、解压Hadoop文件
Tar -zxvf Hadoop-2.7.1.tar.gz

5.3、将解压后的文件上传到opt目录
Sudo mv hadoop-2.7.3/ /opt

5.4、进入opt目录下将Hadoop的文件名进行修改并验证
cd /opt/
sudo mv hadoop-2.7.3/hadoop
cd hadoop
bin/hadoop

Bin/hadoop version
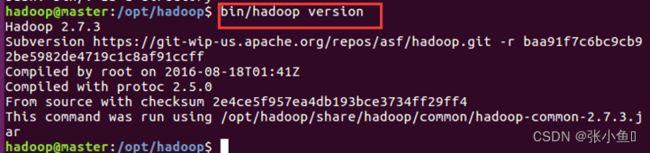
六、Hadoop伪分布式搭建
6.1、进入Hadoop目录下,配置相关的文件
cd etc/hadoop/
cp core-site.xml core-site.bak
Cp hdfs-site.xml hdfs-site.bak

配置之前要先复制一份再配置,分别进入
vim core-site.xml
vim hdfs-site.xml

6.2、配置core-site.xml文件
hadoop.tmp.dir
file:/opt/hadoop/tmp
fs.defaultFS
hdfs://localhost:9000
dfs.permission
false
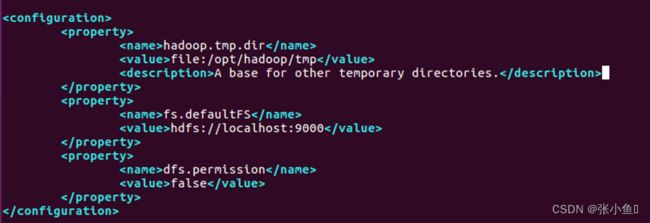
配置之前先复制一份
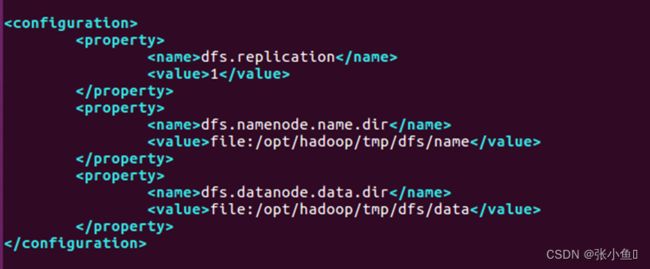
6.3、配置hdfs-site.xml文件
dfs.replication
1
dfs.namenode.name.dir
file:/opt/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/opt/hadoop/tmp/dfs/data
6.4、成功配置的提示
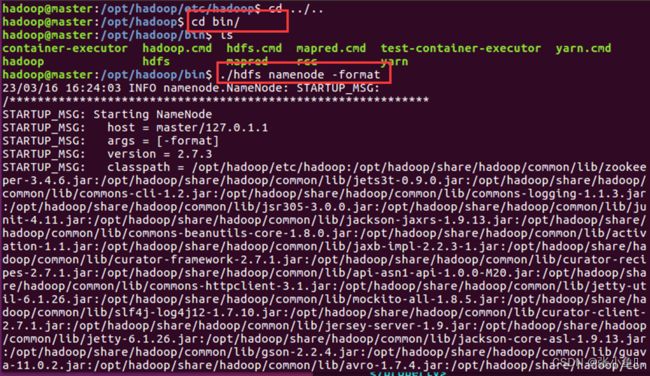
cd bin/
./hdfs namenode -format

6.5、配置Hadoop环境变量
vim .bashrc
#配置Hadoop环境变量
export HADOOP_HOME=/opt/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

配置完成之后重启source .bashrc
6.6、进入 /opt/Hadoop/下启动之前的hdfs
进入cd /opt/Hadoop/


6.7、关闭hdfs服务
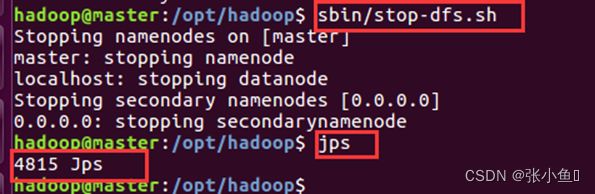
至此,配置过程全部完成。
总结
以上就是今天要讲的内容,本文主要介绍了虚拟机Ubuntu16.04配置jdk以及hadoop的具体步骤,希望对你有所帮助。
结语
最后欢迎大家点赞,收藏⭐,转发,
如有问题、建议,请您在评论区留言哦。