虚拟机下基于CentOS 7 Hadoop 分布式搭建
目录
- 一、准备工作
-
- 1.虚拟机准备
- 2.对四台机器分别配置网络
- 3.xftp上传压缩包(给master机上传即可)
- 二、搭建JDK环境
-
- 1.免密登录
- 2.检查是否有内置JDK
- 3.解压JDK压缩包到 /root下
- 4.配置环境变量
- 5.刷新环境变量
- 6.验证搭建
- 7.分发到 slave1~3机器
- 三、配置Hadoop环境变量
-
- 1.解压,改名
- 2.配置Hadoop环境变量
- 3.刷新环境变量
- 4.验证搭建
- 四、部署Hadoop
-
- 1.切换目录
- 2.配置 core-site.xml 文件
- 3.配置 hdfs-site.xml 文件
- 4.配置 hadoop-env.sh 文件
- 5.配置 slaves 文件
- 6.指定 SecondaryNameNode 节点
- 7.分发到 slave1~3机器
- 8.启动Hadoop
- 五、效果图
- 六、其他
-
- 1.参考链接
- 2.解决小问题
一、准备工作
1.虚拟机准备
- 镜像为CentOS 7
- master,slave1~3,共四台
- 直接使用root用户进行操作
2.对四台机器分别配置网络
2.1.IP分配
192.168.255.140 —>> master
192.168.255.141 —>> slave1
192.168.255.142 —>> slave2
192.168.255.143 —>> slave3
[root@localhost ~]# vi /etc/hosts
# 在文末添加
192.168.255.140 master
192.168.255.141 slave1
192.168.255.142 slave2
192.168.255.143 slave3
2.2.设置主机ip
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
将最后一行的 ONBOOT=no #将no改为yes
然后文末添加
IPADDR=192.168.255.140
NETMASK=255.255.255.0
GATEWAY=192.168.255.2
2.3.更改主机名
[root@localhost ~]# hostnamectl set-hostname master
# 需要 reboot 重启主机名才会改变
# hostname 查看主机名,可以观察当前主机名
2.4.关闭防火墙,改变SeLinux策略,重启网络服务
关闭防火墙
[root@localhost ~]# systemctl stop firewalld.service
[root@localhost ~]# systemctl disable firewalld.service
改变SeLinux策略
[root@localhost ~]# vi /etc/selinux/config
# 将里面的 SELINUX=enforcing 进行更改
SELINUX=disabled
重启网络服务
[root@localhost ~]# service network restart
3.xftp上传压缩包(给master机上传即可)
注:本人直接上传到目录 /root 下
- hadoop-2.7.6.tar.gz
- jdk-16.0.2_linux-x64_bin.tar.gz
链接:https://www.aliyundrive.com/s/LayCMwvbuLM
二、搭建JDK环境
1.免密登录
注:本人四台机器设置全部免密登录,不过好像只要master机配置
[root@master ~]# ssh-keygen -t rsa # 一路回车即可
[root@master ~]# ssh-copy-id root@master
[root@master ~]# ssh-copy-id root@slave1
[root@master ~]# ssh-copy-id root@slave2
[root@master ~]# ssh-copy-id root@slave3
2.检查是否有内置JDK
[root@master ~]# rpm -qa | grep jdk
[root@master ~]# yum -y remove *jdk*
3.解压JDK压缩包到 /root下
[root@master ~]# tar -zxf jdk-16.0.2_linux-x64_bin.tar.gz
[root@master ~]# mv jdk-16.0.2 jdk
4.配置环境变量
[root@master ~]# vi /etc/profile
#Java Environment 添加在文末即可
JAVA_HOME=/root/jdk #该路径是你解压jdk的路径,可以用命令 pwd 查看
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
5.刷新环境变量
[root@master ~]# source /etc/profile
6.验证搭建
[root@master ~]# java -version
java version "16.0.2" 2021-07-20
Java(TM) SE Runtime Environment (build 16.0.2+7-67)
Java HotSpot(TM) 64-Bit Server VM (build 16.0.2+7-67, mixed mode, sharing)
7.分发到 slave1~3机器
[root@master ~]# scp -r jdk/ root@slave1:/root
[root@master ~]# scp -r jdk/ root@slave2:/root
[root@master ~]# scp -r jdk/ root@slave3:/root
再对 slave1~3机器 进行步骤4、5操作
三、配置Hadoop环境变量
1.解压,改名
[root@master ~]# tar -xf hadoop-2.7.6.tar.gz
[root@master ~]# mv hadoop-2.7.6 hadoop
2.配置Hadoop环境变量
[root@master ~]# vi /etc/profile
# Hadoop Environment
export HADOOP_HOME=/root/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.刷新环境变量
[root@master ~]# source /etc/profile
4.验证搭建
[root@master ~]# hadoop version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /root/hadoop/share/hadoop/common/hadoop-common-2.7.6.jar
四、部署Hadoop
1.切换目录
[root@master ~]# cd hadoop/etc/hadoop/
2.配置 core-site.xml 文件
[root@master hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.255.140:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
</property>
</configuration>
注:
1.hadoop.tmp.dir是hadoop 文件系统依赖的配置文件。 默认是在 /tmp 目录下的,而这个目录下的文件,在Linux系统中,重启之后,很多都会被清空。所以我们要手动指定这写文件的保存目录。
2.修改点为 value 包裹的内容 第一个是master机的ip地址,第二个是Hadoop解压后路径
3.配置 hdfs-site.xml 文件
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.255.141:50090</value>
</property>
</configuration>
注:
1.dfs.replication 是配置文件保存的副本数;dfs.namenode.secondary.http-address 是指定 secondary 的节点。
2.修改点为 包裹的内容 第一个可以不改,第二个为slave1机的IP地址(应该不强制使用,四台机器随便一个都可以,不过没有实验过)
4.配置 hadoop-env.sh 文件
[root@master hadoop]# vi hadoop-env.sh
将里面的export JAVA_HOME=${JAVA_HOME}注释,添加你的JDK路径
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/root/jdk
5.配置 slaves 文件
[root@master hadoop]# vi slaves
删除默认的localhost,增加3个从节点
192.169.255.141 slave1
192.169.255.142 slave2
192.169.255.143 slave3
6.指定 SecondaryNameNode 节点
在 $HADOOP_HOME/etc/hadoop 目录下手动创建一个 masters 文件
[root@master hadoop]# cd $HADOOP_HOME/etc/hadoop
[root@master hadoop]# pwd
/root/hadoop/etc/hadoop
[root@master hadoop]# vi masters
192.168.255.141 slave1
注: masters文件里面的指定IP地址必须和 hdfs-site.xml文件中的IP地址一致
7.分发到 slave1~3机器
[root@master hadoop]# cd
[root@master ~]# scp -r hadoop/ root@slave1:/root
[root@master ~]# scp -r hadoop/ root@slave2:/root
[root@master ~]# scp -r hadoop/ root@slave3:/root
8.启动Hadoop
1.初始化
[root@master ~]# hdfs namenode -format
2.启动HDFS命令
[root@master ~]# start-dfs.sh
注:备用方案(切换到Hadoop下)
- 初始化,输入命令,bin/hdfs namenode -format
- 启动hdfs 命令:sbin/start-dfs.sh
3. 查看进程
[root@master ~]# jps
五、效果图
master机器 jps进程
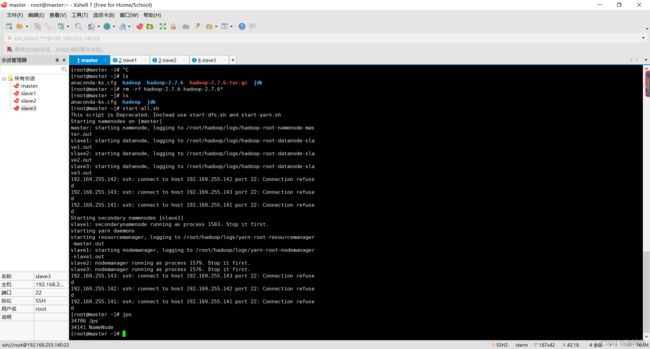
slave1机器 jps进程

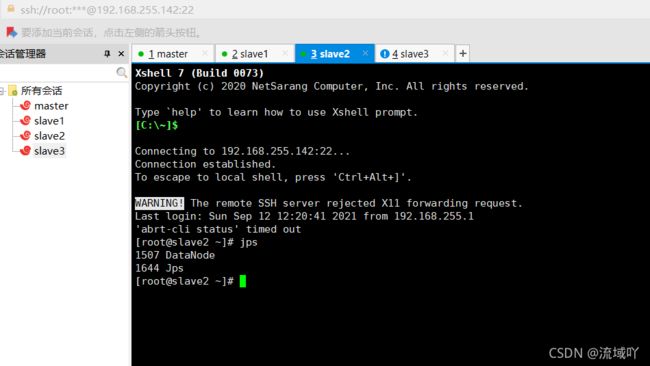
slave2机器 jps进程
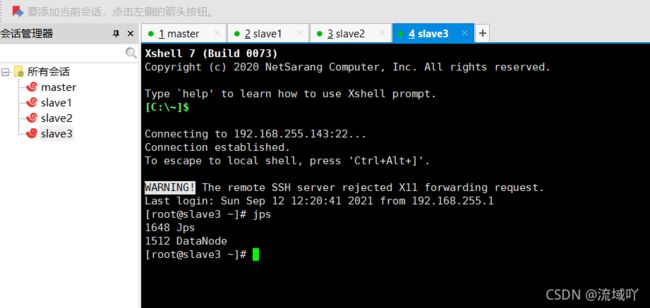
slave3机器 jps进程
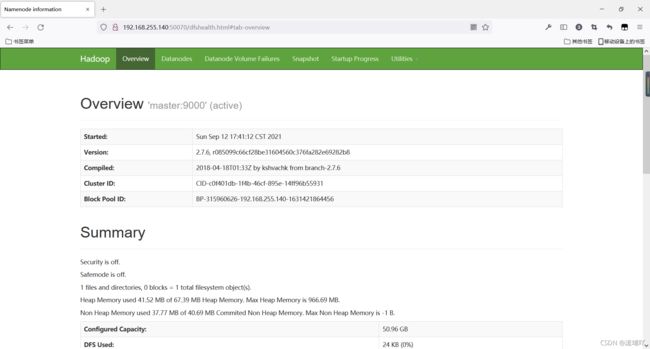
Hadoop web页面 NameNode
Hadoop web页面 DataNode
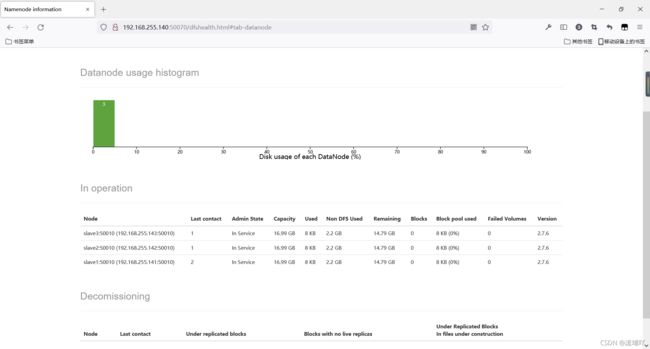
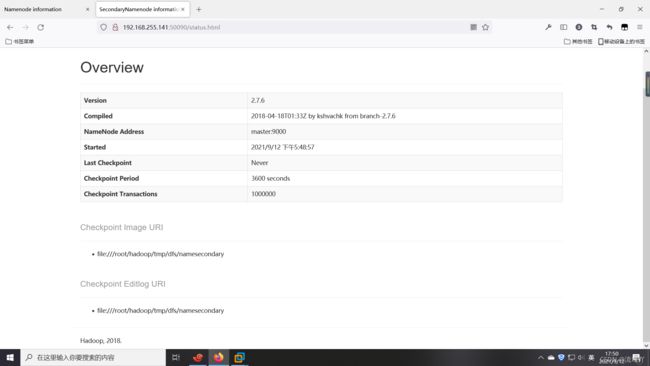
Hadoop web页面SecondaryNameNode
六、其他
1.参考链接
Hadoop hdfs完全分布式搭建教程
注:此文章Hadoop搭建思路来自此链接大佬,如有侵权,联系删除
2.解决小问题
对于本人虚拟机能够ping通网关,不能连接百度,真机可以ping通虚拟机网关
1.转到 ifcfg-ens33 文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
2.修改参数
BOOTPROTO=dhcp #需要注释DNS配置
猜测: 如果使用dhcp则会动态获取,static需要自己添加DNS
#或者
BOOTPROTO=static
DNS="网关IP" # 例如 192.168.255.2 -> GATEWAY
3.重启网络
service network restart
4.如果上述操作不行,查看一下你的Windows服务
打开任务管理器 -> 服务选项 查看VMnetDHCP和VMware NAT Service
