Kafka 基础整理、 Springboot 简单整合
定义:
- Kafka 是一个分布式的基于发布/订阅默认的消息队列
- 是一个开源的分布式事件流平台,被常用用于数据管道、流分析、数据集成、关键任务应用
消费模式:
- 点对点模式 (少用)
消费者主动拉取数据,消息收到后清除消息

- 发布/订阅模式
生产者推送消息到队列,都消费者订阅各自所需的消息

基本概念:
- Producer: 消息生产者
- Consumer: 消费者
- Consumer: Group 消费者组,消费者组id相同得消费者为一个消费者组;一个消费者也为一个消费者组去消费
- Broker: kafka服务器
- Topic :消息主题, 数据分类
- Partition :分区,一个Tpoic 有多个分区组成
- Replica : 副本,每个分区对应多个副本
- Leader:副本里包含leader、follower ;生产以及消费只针对 leader
生产者发送流程:
- producer -> send(producerRecord) -> interceprots 拦截器 -> Serializer 序列化器 -> Partitioner 分区器
- 当数据累积到
batch.size之后,sender才会发送数据;默认16k- 如果数据迟迟未达到batch.size , sender等待
linger.ms设置的时间,到了之后就会发送数据。单位ms.默认值0ms,标识没有延迟compression.type数据压缩方式RecordAccumulator缓冲区大小,默认32m- 应答模式
ack
- 0: 生产者发送数据后,不需要等待数据应答
- 1:生产者发送过来的数据,Leader收到数据后应答
- 1:all leader与其它所有节点收齐数据后应答

消费大概逻辑:

消费者组(Consumer Group (CG)):
groupid相同的消费者形成一个消费者组- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内的一个消费者消费
- 消费者组之间互不影响
- 当消费者组的数量,大于分区数,则会有
闲置coordinator:辅助实现消费者组的初始化和分区的分配
- 每个节点有个
coordinator, 通过groupid % 50,选择出coordinator节点 50为 _consumer_offset 的分区数- 1%50 = 1 ,
_consumer_offset的 号分区上的coordinator则为 leadercoordinator再消费者组中随机选择一个 consumer 成为leader,由leader 制定消费计划,让后返回给coordinator,再由coordinator来把消费技化 分配给其它消费者coordinator与消费者的心跳保持时间3秒,45秒 超时- 会移除消费者,触发再平衡- 消费者消费时间过长,默认
5分钟- 会移除消费者触发再平衡
消费流程:
- 创建消费者网络连接客户端
ConsumerNetworkClient,与kafka交互- 消费请求初始化:每批次
最小抓取大小、数据未达到超时 时间 500ms 、抓取数据大小上限- 发送消费请求 -》onSuccess() 回调, 拉取数据 -》 按批次放入消息队列
- 消费者从 消息队列每批次消费数据 (500条) -》反序列化 -》拦截器 -》 处理数据

消费计划(分区分配策略)默认 Range + CooperativeSticky:
- Range:针对
每一个topic,对topic分区排序、消息者排序,通过分区数 / 消费者数,决定每个消息者消费几个分区,除不尽的前面的消费者多消费。容易产生数据倾斜
- RoundRobin:轮询分区策略,
针对所有topic,把所有topic的分区和消费者列出来,按照hashcode进行排序,通过轮询算法把分区分配给消费者- Sticky :黏性 (执行新的分配的时,尽量靠近上次的分配结果),首先回尽量的均匀,且随机分配分区到消费者
- CooperativeSticky:协作者黏性,Sticky 的策略相同,但支持合作式再平衡,消费者可以继续从没有被重新分配的分区消费

offset 位移: 是标记消费消费位置
- <0.9 : 是维护在 zookeeper中
- 0.9 之后:offset 维护在一个内置的 topic :_consumer_offsets 中
- 采用 key - value 方式存储数据,key:groupid +topic + 分区号
- offset
自动提交:默认每5秒自动提交offset ,默认就是 true- offset
手动提交:消费的时候,手动提交offset
- 同步:等待提交offset成功,再消费下一条
- 异步:不等待,直接消费,失败后没有重试机制
- 指定offset 消费:
earliest: 自动将偏移量重置为最早的偏移量 --from-beginninglatest(默认): 自动将偏离量充值为最新偏移量nono: 如果未找到消费者组的先前偏移量,则向消费者抛出异常。
//设置自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
//自动提交时间 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"5000");
//offset 手动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer kafkaConsumer = new KafkaConsumer<String,String>(properties);
//定义主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
//订阅
kafkaConsumer.subscribe(topics);
while (true){
ConsumerRecords<String,String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
if (CollectionUtil.isNotEmpty(consumerRecords)){
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println(record);
}
}
//手动提交offset
kafkaConsumer.commitAsync();
}
指定时间消费:
//查询对应分区
Set<TopicPartition> partitions = kafkaConsumer.assignment();
//保证分区分配方案定制完毕
while (partitions.size()==0){
kafkaConsumer.poll(Duration.ofSeconds(1));
partitions=kafkaConsumer.assignment();
}
//把时间转换成对应的 offset
Map<TopicPartition,Long> map = new HashMap<>(6);
Map<TopicPartition,Long> offsetmap = kafkaConsumer.offsetsForTimes(map);
for (TopicPartition topicPartition : partitions) {
//一天前
offsetmap.put(topicPartition,System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
}
Map<TopicPartition, OffsetAndTimestamp> offsetsForTimeMap = kafkaConsumer.offsetsForTimes(offsetmap);
for (TopicPartition partition : partitions) {
OffsetAndTimestamp timestamp = offsetsForTimeMap.get(partition);
kafkaConsumer.seek(partition,timestamp.offset());
}
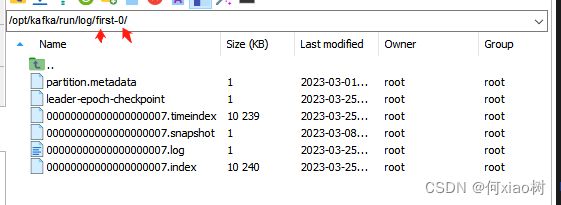
kafka 文件存储机制 :
Topic是逻辑上的概念,partition是物理上的概念, 每个partition对应一个log文件。该log文件中存储的就是 producer生产的数据- Producer生产的数据,会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低,kafka采取了分片和索引机制
- 每个partition分为多个
segment,每个segment包含, .index .log .timeindex .snapshot 文件- 这些文件位于一个文件夹下,该文件夹命名规则为:topic名称+分区序号 first-0
- 稀疏索引:大约每往log文件写入 4kb数据,会往index文件写入一条索引。
- index文件中保存的 odffset是
相对offset,这样能确保 offset得值所占空间不会过大,因此能将offset得值控制在固定大小

文件清除、压缩策略:
- kafka 默认日志保存时间为 7 天
- 压缩策略:compact,对应相同key的value,只保留最新的一个版本。
kafka 高效读写:
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用
稀疏索引,可以快速定位要消费得数据- 顺序写磁盘,kafka得producer生产数据,要写入
log文件中,写得过程是一直追加到文件末端,为顺序写零拷贝: Kaka的数据加工处理操作交由Kaka生产者和Kaka消费者处理。Kaka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。- 页缓存: Kaka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。
常用脚本命名:
- topic 相关命令 :
- 查询topic列表 :
sh kafka-topics.sh --bootstrap-server localhost:9092 --list- 创建topic (名称:first 分区:1个 副本 3个)副本数量不能超过集群数量
sh kafka-topics.sh --bootstrap-server localhost:9092 --topic first --create --partitions 1 --replication-factor 3- topic 信息
sh kafka-topics.sh --bootstrap-server localhost:9092 --topic first --describe- 修改topic 分区数(只能增加)
sh kafka-topics.sh --bootstrap-server localhost:9092 --topic first --describe --partitions 3- 生产消息:
sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first- 消费消费:
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic firstsh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first --from-beginning
Spring boot 简单整合:
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
spring:
mvc:
pathmatch:
matching-strategy: ant_path_matcher
application:
name: @artifactId@
kafka:
bootstrap-servers: 192.168.2.207:9092,192.168.2.208:9092
# 生产配置
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
#消费配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
group-id: xiaoshu
enable-auto-commit: false
listener:
# 手动调用Acknowledgment.acknowledge()后立即提交
ack-mode: manual
生产:
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
@ApiOperation(value = "推送消息到kafak")
@GetMapping("/sendMsg")
public String sendMsg(String msg){
String topic="first";
kafkaTemplate.send(topic,msg);
return "ok";
}
消费:
@Configuration
public class KafkaConsumer {
@KafkaListener(topics = {"first"})
public void consumerTopic(ConsumerRecord<?, ?> record, Acknowledgment ack){
String topic = record.topic();
long offset = record.offset();
int partition = record.partition();
Object value = record.value();
try {
System.out.println("收到消息:"+value);
ack.acknowledge();
}catch (Exception e){
e.printStackTrace();
}
}
}