非常好的单体到分布式的演变之路!
- 读到的一篇公众号,写的单体服务到分布式演变之路,写的非常好,分享给大家!
由于疫情的原因,我被分配的任务不是很多,所以就会空出一点时间,一般这个时候我都会做自己的事情,比如看看源码、翻翻博客、然后就是写写博客。
正当我沉迷在源码中不能自拔的时候,总监突然来到我旁边轻声的对我说道:最近这段时间大家的任务也不是特别多,空闲时间比较足,你这边能不能做点技术分享什么的,一来可以联络一下同事之间的感情,二来也可以增加同事之间的学习氛围。

宝宝心里难受,一直在想我要讲一个什么样的话题才能让大部分的人都能听得懂并且感兴趣呢?
这里面肯定不时出现太多的代码,既然这样,那我就讲一讲分布式的架构演进吧,这个话题既高端,也能让大部分的人听懂,我就是个天才。

好了,不废话了,开始这次的主题,分布式架构的演变。
单体服务
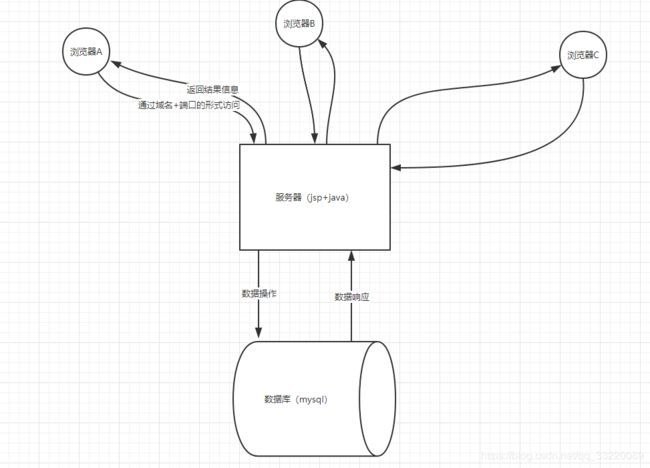
我记得在我实习的时候用的就是单体的服务,那个时候的架构很简单,前后端分离都还没有,直接 JSP+Java 实现一套项目,整个流程相当简单,就连 Nginx 都没有用到。
我们一起来看看当时的架构是什么样的:
①引入 Nginx
没错,就是这么简单,浏览器通过接口访问服务器,服务器通过用户的请求操作数据库,然后再相应给浏览器,这就是一个最简单的单体服务的流程。
后来领导觉得直接将端口暴露出去相当危险,我们需要做一层代理,让用户直接通过域名访问。
然后流程就被设计成了这样:

这是引入 Nginx 之后的架构图,在这样运行了一段时间之后,突然有一天,领导找到我并说到:你写的代码是不是有问题,为什么一个普通的查询需要很长的时间?基本操作都卡的要死,给你一周时间,赶紧给我解决!
②引入 Redis 单体
经过我的排查之后发现导致程序变卡的原因是数据库受到了瓶颈,压力太大,承受不住那么大的请求,既然问题找到了,那解决就很简单了。
我在程序和数据库之间增加一个中间件:Redis,使用它来降低数据库的访问,这样性能自然会得到提升。
![]()
舒服,引入 Redis,并且对代码做了一些优化之后,发现速度上来了,我有可以快乐的写 Bug 了。
就这样过去了大概一个月左右,这天我正在和同事讨论一些八卦,突然感觉背后一阵阴风 ,我知道,出事了。
没想到是领导又来找我麻烦了,他说由于我们的产品太火了,下载注册人数都几十万了,日活跃人数也是上万,我们现在的这套架构撑不住了,你有没有什么好的建议?我惊讶了一下,我们的产品这么受欢迎吗?
于是我和领导说,我们可以将数据做一下读写分离,这样也可以提升一下程序的性能,但是对于现在的情况,就算加了读写分离,作用应该也不大,我们应该将单体多部署几台,提升程序的吞吐量。
③引入 MySQL 读写分离
![]()
这就是将数据库改造成读写分离之后的架构,读操作和写操作分别在不同的库中,这样,查询和写入就不会那么长的时间了,因为在读库中没有写操作,写库中没有读操作。
由于我们一般是读的操作比较多,所以这个时候我们我们可以将读库的配置设置的好一点,写库的设置的差一点,均衡分配。
但仅仅这样是也是不能支撑那么大流量的,所以这个时候我们还需要将服务器做集群。
④引入服务器集群
![]()
这就是我们单体的最终架构,改造完成之后性能确实得到了很大的提升,因为服务做了集群之后,分散了很多的请求。
比如一个 Tomcat 能支持的最高并发是 200,那现在三个服务就能支持 600 的并发,性能提升了 3 倍,最终扩充了多少台服务器我也不清楚,因为这个是运维做的。
集群算是做完了,总算可以满足领导的要求了,为了搞定这一套一套的升级,不知道熬了多少夜,看到电脑旁边掉落的那几根头发,我满意的点了点头。
![]()
在后面的两个月的时间里,我们在不停的做迭代更新,几乎每周都会有版本上线,两个月过后版本终于稳定下来了,不怎么有更新了,所以又来到了程序猿的空闲时间。
同事们每天上班都做着自己的事情,有学习的,有逛淘宝的,有玩游戏的,更夸张的是居然有个同事闲着没事居然去撩产品小姐姐,握草,这是想要自掘坟墓吗?
大概空闲了一周的时间左右,我们的技术总监说话了,今天下午 3 点,所有后端开发人员会议室开会,听到这个消息,我就知道,有活干了,难道是接了新的项目?
到了下午 3 点,我们来到会议室,只见技术总监已经提前到了,并且屏幕上写着五个大字,看到这五个字,我心里想,该来的还是会来,躲不过去的,那就是:分布式架构。
分布式架构
因为我知道,我们产品注册人数已经高达几十万,以我们现在的架构肯定会有撑不住的一天,这个产品肯定会被重构,并且是以分布式的架构进行重构,果然,今天技术总监就召开了这个会议。
技术总监:我们的产品现在比较火热,不管是注册人数还是日活跃人数都是比较高的,为了让程序能有更好的健壮性,我希望我们可以对这个项目进行重构,以分布式的架构,今天开会就是我们一起来做个技术选型,你们对分布式熟悉吗?
同事 A:分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
技术总监:嗯,不错,不过这个解释比较官方,还有没有比较通俗易懂的解释?
同事 B:分布式将一个大的系统拆分成无数个细微的子系统,让每一个系统都负责一定的职责,他们相互独立,但是又相互联系。
技术总监:哟,不错哦,这个同事可以,晚上加鸡腿,那有人可以举个例子吗?
Me:从前有一个有一个饭店,里面只有老板和一个员工,这个员工负责饭店所有的事情,包括但不限于:厨师、服务员、收银员、清洁工等,在炒菜的时候就不能去收钱,在打扫卫生的时候就不能炒菜,这个员工干了一个月之后,突然有一天,他病倒了,餐厅的生意就停滞了,这个时候老板就想到了一个人不行,那我多招几个人,一个人负责一个职位,这样即使某个人请假或者离职了,对我的生意影响不是很大,比如:清洁工离职了,虽然没有人打扫卫生,但是这并不影响我开门做生意,分布式就是这个道理。
技术总监:这个例子讲的不错,你晚上不用加班了,如果你要是能画一个分布式的基础图出来,我今晚请大家撸串。
Me:我专治各种不服,于是我就给技术总监"上了一课",请看图:
![]()
为什么要使用分布式架构
技术总监:不错,画的很好,但是你们知道我们为什么要将单体的服务重构为分布式吗?答对有鸡腿。
同事 C:
-
Spring Cloud 专注于提供良好的开箱即用经验的典型用例和可扩展性机制覆盖
-
分布式/版本化配置
-
服务注册和发现
-
路由
-
Service-to-Service 调用
-
负载均衡
-
断路器
-
分布式消息传递
这是分布式的优点,这样看起来可能比较抽象,举个例子来说,对于单体服务来说,如果我想更新订单中的某个功能,我是不是需要重启整个服务。
这个时候就会导致整个项目都处于不可用状态,或者在处理订单的时候由于程序代码写的有问题,导致死锁了,这个时候也会导致整个服务处于宕机专改,容错率很差。
但是分布式不同,如上图所示,订单服务、售后服务、用户服务都是独立的服务,如果需要更新订单服务或者订单服务发生死锁,受影响的只会是订单服务,售后服务与用户服务还是可以正常工作的,这就是分布式相对单体来说最大的优势之一。
技术总监:想不到我们这个团队人才辈出啊,不错不错,看来我都没有讲下去的必要了啊,大家对分布式都相当熟悉了啊,那分布式架构存在缺点或者不足吗?
同事 D:
![]()
这是我平时刷博客的时候看到的,觉得总结的不错!
分布式基础组件
技术总监:既然大家对分布式都这么熟悉了,那我也就不在多说了,我们接下来直接来说说关于分布式组件的选型吧,大家有什么意见都可以提出来,首先谁来说一下分布式组件都有哪些?请开始你们的表演。
![]()
同事 E:那我就不客气了,由于我们都是对 Spring Cloud 比较熟悉,现在他也是比较主流,那我介绍一下 Spring Cloud 的基础组件吧。
Spring Cloud Config:配置管理工具包,让你可以把配置放到远程服务器,集中化管理集群配置,目前支持本地存储、Git 以及 Subversion。
Spring Cloud Bus:事件、消息总线,用于在集群(例如,配置变化事件)中传播状态变化,可与 Spring Cloud Config 联合实现热部署。
Eureka:云端服务发现,一个基于 REST 的服务,用于定位服务,以实现云端中间层服务发现和故障转移。
Hystrix:熔断器,容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。
Zuul:Zuul 是在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。Zuul 相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门。
Archaius:配置管理 API,包含一系列配置管理 API,提供动态类型化属性、线程安全配置操作、轮询框架、回调机制等功能。
Consul:封装了 Consul 操作,Consul 是一个服务发现与配置工具,与 Docker 容器可以无缝集成。
Spring Cloud for Cloud Foundry:通过 Oauth2 协议绑定服务到 CloudFoundry,CloudFoundry 是 VMware 推出的开源 PaaS 云平台。
Spring Cloud Sleuth:日志收集工具包,封装了 Dapper 和 log-based 追踪以及 Zipkin 和 HTrace 操作,为 Spring Cloud 应用实现了一种分布式追踪解决方案。
Spring Cloud Data Flow:大数据操作工具,作为 Spring XD 的替代产品,它是一个混合计算模型,结合了流数据与批量数据的处理方式。
Spring Cloud Security:基于 Spring Security 的安全工具包,为你的应用程序添加安全控制。
Spring Cloud Zookeeper:操作 Zookeeper 的工具包,用于使用 Zookeeper 方式的服务发现和配置管理。
Spring Cloud Stream:数据流操作开发包,封装了与 Redis、Rabbit、Kafka 等发送接收消息。
Spring Cloud CLI:基于 Spring Boot CLI,可以让你以命令行方式快速建立云组件。
Ribbon:提供云端负载均衡,有多种负载均衡策略可供选择,可配合服务发现和断路器使用。
Turbine:Turbine 是聚合服务器发送事件流数据的一个工具,用来监控集群下 Hystrix 的 Metrics 情况。
Feign:Feign 是一种声明式、模板化的 HTTP 客户端。
Spring Cloud Task:提供云端计划任务管理、任务调度。
Spring Cloud Connectors:便于云端应用程序在各种 PaaS 平台连接到后端,如:数据库和消息代理服务。
Spring Cloud Cluster:提供 Leadership 选举,如:Zookeeper,Redis,Hazelcast,Consul 等常见状态模式的抽象和实现。
Spring Cloud Starters:Spring Boot 式的启动项目,为 Spring Cloud 提供开箱即用的依赖管理。
我们常用的组件:
-
Spring Cloud Config
-
Spring Cloud Bus
-
Hystrix
-
Zuul
-
Ribbon
-
Feign
![]()
技术总监:不错,组件分析的不错,但是你的讲解比较官方,下面我们来一个一个的讲解一下我们经常使用的这些组件。
①Eureka
Eureka 属于 Spring Cloud Netflix 下的组件之一,主要负责服务的注册与发现,何为注册与发现?
在刚刚我们分析的分布式中存在这一个问题,那就是订单服务与用户服务被独立了,那么他们怎么进行通信呢?比如在订单服务中获取用户的基础信息,这个时候我们需要怎么办?
如果按照上面的架构图,直接去数据库获取就可以了,因为服务虽然独立了,但是数据库还是共享的,所以直接查询数据库就能得到结果,如果我们将数据库也拆分了呢?这个时候我们该怎么办呢?
有人想到了,服务调用,服务调用是不是需要 IP 和端口才可以,那问题来了,对于订单服务来说,我怎么知道用户服务的 IP 和端口呢?在订单服务中写死吗?如果用户服务的端口发生改变了呢?
这个时候 Eureka 就出来了,他就是为了解决服务的通信问题,每个服务都可以将自己的信息注册到 Eureka 中,比如 IP、端口、服务名等信息,这个时候如果订单服务想要获取用户服务的信息,只需要去 Eureka 中获取即可。
请看下图:
![]()
这就是 Eureka 的主要功能,也是我们使用中的最值得注意的,他让服务之间的通信变得更加的简单灵活。
②Spring Cloud Config
Spring Cloud Config 为分布式系统中的外部配置提供服务器和客户端支持。使用 Config Server,您可以在所有环境中管理应用程序的外部属性。
客户端和服务器上的概念映射与 Spring Environment 和 PropertySource 抽象相同,因此它们与 Spring 应用程序非常契合,但可以与任何以任何语言运行的应用程序一起使用。
随着应用程序通过从开发人员到测试和生产的部署流程,您可以管理这些环境之间的配置,并确定应用程序具有迁移时需要运行的一切。
服务器存储后端的默认实现使用 Git,因此它轻松支持标签版本的配置环境,以及可以访问用于管理内容的各种工具。可以轻松添加替代实现,并使用 Spring 配置将其插入。
简单点来说集中来管理每个服务的配置文件,将配置文件与服务分离,这么多的目的是什么?
举个简单的栗子,我们配置文件中肯定会存在数据库的连接信息,Redis 的连接信息,我们的环境是多样的,有开发环境、测试环境、预发布环境、生产环境。
每个环境对应的连接信息肯定是不相同的,难道每次发布的时候都要去修改一下服务中的配置文件?
我能不能将这些变动较大的配置集中管理,不同环境的管理者分别对他们进行修改,就不需要再服务中做改动了,Config 就做到了。
![]()
这就是 Config 的大致架构,所有的配置文件都集中交给 Config 管理,拿 Config 怎么管理这些配置文件呢?
你可以将每个环境的配置文件存放再一个位置,比如 Lgitlab、SVN、本地等等,Config 会根据根据你设置的位置读取配置文件进行管理,然后其他服务启动的时候直接到 Config 配置中心获取对应的配置文件即可。
这样开发人员只需要关注 -dev 的配置文件,测试人员只需要关注 -test 的配置文件,完全和服务解耦,你值得拥有。
③Netflix Zuul(网关)
这个时候技术总监突然提了一个问题,他说:既然我们将一个服务拆分成了很多微服务,那岂不是要暴漏很多接口给浏览器?这样会不会造成安全隐患呢?有谁可以来说说这个问题。
同事 A:我们可以通过 Nginx 反向代理,开放二级域名,然后将域名映射到微服务中。
技术总监:这个方案也可以,也是不需要使用的,但不是最完善的,还有没有更好的方案?
Nginx 虽然把端口隐藏了,如果我们的服务都是需要一些权限的校验,Nginx 是无法替我们完成的,这个时候我们难道要在每个服务中都添加一套权限校验的逻辑吗?
同事 B:我觉得我们可以使用网关,它既可以做分流转发,也可以做权限控制,使用 Nginx+网关,我觉得是比较好的一种方案,以下是网关 Zuul 的介绍。
路由在微服务体系结构的一个组成部分。例如,/可以映射到您的 Web 应用程序,/api/users 映射到用户服务,并将 /api/shop 映射到商店服务。Zuul 是 Netflix 的基于 JVM 的路由器和服务器端负载均衡器。
Netflix 使用 Zuul 进行以下操作:
-
认证 -洞察
-
压力测试
-
金丝雀测试
-
动态路由
-
服务迁移
-
负载脱落
-
安全
-
静态响应处理
-
主动/主动流量管理
我们在日常开发过程中并不会使用那么多,基本上就是认证、动态路由、安全等等,我画了一张关于网关的架构图,请看:
![]()
技术总监:你们真的太优秀了,没错,Nginx 只能为我们做反向代理,不能做到权限认证,网关不但可以做到代理,也能做到权限认证、甚至还能做限流,所以我们要做分布式项目,少了他可不行。
④Spring Cloud Bus
application.yml
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/test
driver-class-name: com.mysql.cj.jdbc.Driver
技术总监:比如上面这行配置大家都应该很熟悉,这是数据库的连接信息,如果它发生改变了怎么办呢?
我们都知道,服务启动的时候会去 Config 配置中心拉取配置信息,但是启动完成之后修改了配置文件我们应该怎么办呢,重启服务器吗?
同事 C:我们可以通过 Spring Cloud Bus 来解决这个问题,Spring Cloud Bus 将轻量级消息代理链接到分布式系统的节点。然后可以将其用于广播状态更改(例如,配置更改)或其他管理指令。
该项目包括 AMQP 和 Kafka 经纪人实施。另外,在类路径上找到的任何 Spring Cloud Stream 绑定程序都可以作为传输工具使用。
这个需要我们有一点的 MQ 基础,不管是 RabbitMQ 还是 Kafka,都可以。
Bus 的基本原理就是:配置文件发生改变时,Config 会发出一个 MQ,告诉服务,配置文件发生改变了,并且还发出了改变的哪些信息,这个时候服务只需要根据 MQ 的信息做实时修改即可。
这是一个很简单的原理,理解起来可能也不会怎么难,画个图来理解一下:
![]()
大致流程就是这样,核心就是通过 MQ 机制实现不重启服务也能做到配置文件的改动,这方便了运维工程师,不用每次修改配置文件的时候都要去重启一遍服务的烦恼。
⑤Feign
技术总监:漂亮,和你们讲技术就是省事,刚才我们说到了注册中心可以方便服务于服务之间的通信,但是他们具体是怎么通信的你们有谁知道吗?
同事 D:由于我们刚刚讲的分布式架构是 Spring Cloud,所以这里推荐使用:Feign。
Feign 是一个声明式的 Web 服务客户端。这使得 Web 服务客户端的写入更加方便 要使用 Feign 创建一个界面并对其进行注释。
它具有可插入注释支持,包括 Feign 注释和 JAX-RS 注释。Feign 还支持可插拔编码器和解码器。
Spring Cloud 增加了对 Spring MVC 注释的支持,并使用 Spring Web 中默认使用的 HttpMessageConverters。
Spring Cloud 集成 Ribbon 和 Eureka 以在使用 Feign 时提供负载均衡的 HTTP 客户端。
![]()
Feign 基于 Rest 风格,简单易懂,他的底层是对 HttpClient 进行了一层封装,使用十分方便。
技术总监:不错,那如果服务的调用出现问题怎么办?比如调用超时,这个时候后我们如何处理?
⑥Netflix Hystrix(熔断)
同事 E:这个 Cloud 也给我们考虑到了,我们只需要引入熔断即可。
Hystrix 支持回退的概念:当电路断开或出现错误时执行的默认代码路径。要为给定的 @FeignClient 启用回退,请将 Fallback 属性设置为实现回退的类名。
我们可以改造一下刚刚的调用架构:
![]()
在这里我部署了一台备用服务器,当用户服务宕机了之后,订单服务进行远程调用的时候可以进入备用服务,这样就不会导致系统崩溃。
技术总监:分布式大致架构差不多了,还有一些组件这里也不做做介绍了,使用的时候可以自己了解一下,不是很难。
我们接着往下说,我现在这里有一个需求,修改密码,修改密码需要发送短信验证码,发送短信在短信服务中,修改密码在用户服务中,这个时候就会出现服务调用。
而且我们知道,发送短信一般都是调用第三方的接口,那比如阿里的,既然牵扯到调用,那么就会存在很多不确定因素,比如网络问题。
假如,用户再点击发送短信验证码到时候用户服务调用短信服务,但是在短信服务中执行调用阿里的接口花费了很长的时间。
这个时候就会导致用户服务调短信服务超时,会返回给用户失败,但是,短信最后又发出去了,这种问题怎么解决呢?
MQ(消息中间件)
同事 B:我们可以通过消息中间件来实现,使用异步讲给用户的反馈和发送短信分离,只要用户点了发送短信,直接返回成功,然后再启动发送验证码,60 秒重发一下,就算发送失败,用户还可以选择重新发送。
![]()
分布式事务
技术总监:漂亮,MQ 不但可以解耦服务,它还可以用来削峰,提高系统的性能,是一个不错的选择。
既然我们使用了分布式架构,那么有一点是我们必须要注意的,那就是事务问题。
如果一个服务的修改依赖另外一个服务的操作,这个时候如果操作不慎,就会导致可怕的后果。
举个例子,两个服务:钱包服务(用于充值提现)、交易钱包服务(用于交易),我现在想从钱包服务中转 1000 元到交易钱包服务中,我们应该如何保证他们数据的一致性呢?
同事 C:我这里有两种方案,第一种是通过 MQ 来保证一致性,另外一种就是通过分布式事务来确保一致性。
①MQ 确保一致性
钱包服务分为三步:
-
生成一个订单表,记录着转入转出的状态。
-
向 MQ 发送一条确认消息。
-
开启本地事务,执行转出操操作,并且提交事务。
交易钱包服务:接收 MQ 的消息,进行转入操作(此操作需要 Ack 确认机制的支持)。
系统中会一直定时扫描订单中状态,没有成功的就做补偿机制或者重试机制,这个不是唯一要求。
![]()
以上就是 MQ 确保分布式事务的大致思路,不是唯一,仅供参考。
②Seata(分布式事务)
Seata 有三个基本组成部分:
-
事务协调器(TC):维护全局事务和分支事务的状态,驱动全局提交或回滚。
-
事务管理器 TM:定义全局事务的范围:开始全局事务,提交或回滚全局事务。
-
资源管理器(RM):管理分支事务正在处理的资源,与 TC 进行对话以注册分支事务并报告分支事务的状态,并驱动分支事务的提交或回滚。
![]()
Seata 管理的分布式事务的典型生命周期:
-
TM 要求 TC 开始一项新的全球交易。TC 生成代表全局事务的 XID。
-
XID 通过微服务的调用链传播。
-
RM 将本地事务注册为 XID 到 TC 的相应全局事务的分支。
-
TM 要求 TC 提交或回滚 XID 的相应全局事务。
-
TC 驱动 XID 对应的全局事务下的所有分支事务以完成分支提交或回滚。
完整的分布式架构
完整的分布式架构如下图:
![]()
这就是一套分布式基本的架构,请求从浏览器发出,经过 Nginx 反向代理到 Zuul 网关。
网关经过权限校验、然后分别转发到对应的服务中,每个服务都有自己独立的数据库,如果需要跨库查询的时候就需要用到分布式的远程调用(Feign)。
虽然这里我将服务拆分了,但是有一点需要注意的是网关,网关承载着所有的请求,如果请求过大会发生什么呢?
服务宕机,所以一般情况下,网关都是集群部署,不止网关可以集群,其他的服务都可以做集群配置,比如:注册中心、Redis、MQ 等等都可以。
那我们将这个流程图再改良一下:
![]()
现在这套架构就是比较程数的一套了,不管是性能还是稳定能,都是杠杠的,技术选择性的会也开得差不多了,最后技术总监做了一个总结。
总结
①单体服务与分布式服务区别
单体服务与分布式服务对比如下图:
![]()
②什么时候使用分布式/集群?
总结如下几点:
-
单机无法支持的时候。
-
想要更好的隔离性(功能与功能)。
-
想要更好用户体验的时候。
-
想要更好的扩展性。
-
想要更快的响应,更搞得吞吐量。
③使用分布式注意事项
虽然现在分布式技术已经十分成熟,但是里面的坑不是一点两点,比如:==如何保证分布式事务的一致性、如何保证服务调用的幂等性、如何保证消息的幂等性、如何设置熔断(服务的降级),如何保证服务的健壮性等等,==这些都是一直需要关注的问题,只有解决了这些问题,你的分布式架构才能真正的立于不败之地。
④关于组件停更消息
目前注册中心 Eureka、网关 Zuul,Feign 都相继停更了,停更不代表不能使用,只是除了 Bug 可能不会主动修复,所以这个时候我们可能就需要选择另外的组件了。
注册中心可以使用 Consul、Nacos,Zookeeper,网关则可以通过 Gateway 替换,OpenFeign 替换 Fiegn。
所以也没必要听到组件停更的消息就担心 Cloud 会不会凉,放心,它至少最近几年是不会凉的。
![]()
技术总监总结完之后,就离开了会议室,也到了下班时间,由于我在会上出色的表现,今天晚上不用加班了,终于可让我的头发掉的慢一点了。