语义分割——UNet / UNet++【论文笔记】
Contents
-
- 1 网络整体结构
- 2 Key points
-
- 2.1 Overlap-tile Strategy
- 2.2 Decode中的上采样
-
- 2.2.1 UnPooling
- 2.2.2 UpSampling
- 2.2.3 反卷积
- 3 UNet++
- 4 深度监督(Deep supervision)
开始之前学习一个单词热热身:
contracting
收缩,缩小;(肌肉)收缩;感染(疾病);
论文地址:https://arxiv.org/pdf/1505.04597.pdf
1 网络整体结构
UNet论文中对于网络结构总结最好的一句话:
The architecture consists of a contracting path (理解为降采样路径,编码)to capture context and a symmetric expanding path (理解为上采样路径,编码)that enables precise localization.
神经网络层数约深,其特征图尺寸越小,其包含的语义信息越丰富,而损失了物体的位置信息;再结合FPN的思想把大特征图中包含的位置信息与小特征图中包含的语义信息concat起来,这样就弥补了定位精度与语义信息间的tradeoff,多好。

从图片中看到整体的网络结构类似U型,其左边和右边分别为Encoder和Decoder过程:
- Encoder:左半部分,由两个3x3的卷积层(ReLU)+2x2的max polling层(stride=2)反复组成,每经过一次下采样,通道数翻倍;
- Decoder:右半部分,由一个2x2的上采样卷积层(ReLU)+ Concatenation(crop对应的Encoder层的输出feature map然后与Decoder层的上采样结果相叠加)+ 2个3x3的卷积层(ReLU)反复构成;
- 最后一层通过一个1x1卷积将通道数变成期望的类别数。
整体网络没什么复杂的,注意的是该网络是用于语义分割的,而分割任务是像素级别的分类任务,故网络的输出层大小应该为[W, H, num_cls + 1],其中W、H为输入图片(overlap_tile前)的大小,num_cls为图片的前景类别个数,因为图片还有背景,所以还需要加1。接下来具体总结下这篇论文的创新点,值得学习。
2 Key points
2.1 Overlap-tile Strategy
在对图片进行训练或预测时,使用overlap-tile策略。策略的思想是:对图像的某一块像素点(黄框内部分)进行预测时,需要喂入网络的图片必须是篮色框大小的图片(因为网络采用valid卷积,输出一定会比输入小!)。这样的策略会带来一个问题,黄框的图像边界周围没有像素,相比于边界补0操作,对周围像素进行镜像扩充更能够弥补丢失的边缘信息。篮框中的像素是通过以黄框边界为中心线镜像操作填充的。

为什么要这样做呢?第一,为了使得网络预测出的mask图片与原图尺寸相同,而网络结构采用valid卷积,所以一定要想办法把输入图片变大一些,如果采用padding 0的操作,那仅仅是将尺寸大小对上,并没有引入有用特征;反正都要将输入变大一些,通过镜像扩充代替补0操作岂不是更好些,会补充一些边缘细节信息。
论文中提到,这样操作可以使得在单个图进行完分割而合并的时候,可以实现所谓的"无缝"。个人理解"无缝"的意思,就是没有padding 0,而用的是自身图片的镜像。
2.2 Decode中的上采样
之前学习目标检测仅仅接触过UpSampling的上采样方式,在这里总结下了解到的上采样的三种方式。
2.2.1 UnPooling

即UnPooling操作与MaxPooling操作是对应的,在MaxPooling时记录每一个保留元素的位置,在UnPooling时将元素在之前保留的位置填充,其余位置补0即可。
2.2.2 UpSampling
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
-
size 是要输出的尺寸,数据类型为tuple: ([optional D_out], [optional H_out], W_out);
-
scale_factor 在高度、宽度和深度上面的放大倍数,即

注意参数size和scale_factor不可以同时设置; -
mode 上采样的方法,包括最近邻(nearest),线性插值(linear),双线性插值(bilinear),三次线性插值(trilinear),默认是最近邻(nearest);
-
align_corners如果设为True,输入图像和输出图像角点的像素将会被对齐(aligned),这只在mode = linear, bilinear, or trilinear才有效,默认为False。
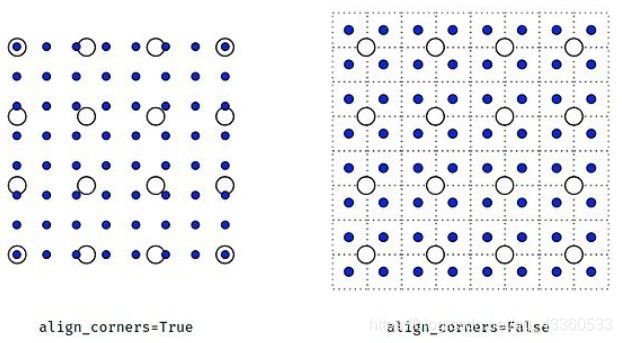
2.2.3 反卷积


上面两张图一张为正常卷积操作,一张为反卷积操作,总之只要提到卷积操作,一定是将大的特征图在经过卷积核的遍历之后变成小的特征图(无padding情况下),那么反卷积操作一定是先将小的特征图通过一定的插值方式变为大的特征图,再进行正常卷积,那首先怎么获得这个大的特征图呢?——interpolation
假设:
原特征图:width、height
输入的卷积核:kernel_size = size 和 stride、padding
插值后的新特征图大小:
Height_in = height + (stride - 1) × (height-1) 、Width同理。
对于插值,第一,插0;第二,位置在原特征图两两数字中间插入stride - 1列。
新的卷积核:kernel_size = Size 和 Stride = 1、Padding = Size - padding - 1
反卷积后的特征图大小:
Height_out = (Height_in + 2 * Padding - Size) / stride + 1 ,该式中参数均针对于插值后的特征图大小,利用原始输入特征图参数代入得到:
Height_out = ( height+ (stride - 1) × (height-1)+ 2 * (Size - padding - 1) - size) / 1 + 1
一个例子:


pytorch中对应的反卷积函数:
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
3 UNet++
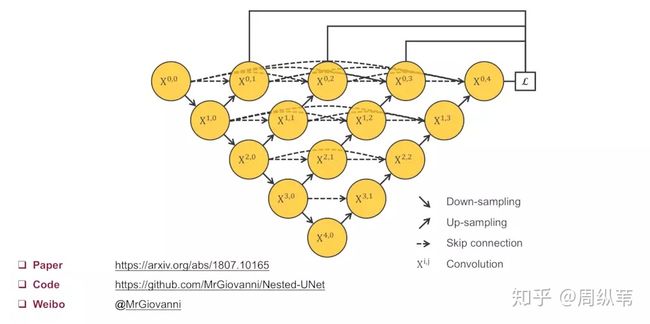
强烈推荐这篇博客,一位博士分享如何从毫无思绪的想法一步一步从初始的UNet演进为UNet++,感觉整个流程一气呵成,十分顺畅。
博客地址:https://zhuanlan.zhihu.com/p/44958351
1、思考UNet的编码解码深度为什么是4层,通过做实验发现网络深度与数据集的难度是很有关系的,实验发现对于较为简单的数据集,使用更深的网络对结果会产生negtive effect;
2、第一眼看UNet引入的仅仅有FPN机制,但在UNet++中类似于引入了ResNet的shortcut和DenseNet的稠密连接,这样一来更加充分利用了不同层次的特征;
3、可以在训练阶段进行剪枝,通过尾部灵活的网络结构配合深监督,让参数量巨大的深度网络在可接受的精度范围内大幅度的缩减参数量。即在训练整个网络后,针对测试集的难度在测试阶段对网络进行剪枝,即删除沿45°方向卷积节点,使得网络更浅、参数更少、检测更快。
4 深度监督(Deep supervision)
最后再提一下深度监督(Deep supervision),毕竟它用在了UNet++的尾部。
深度监督相当于给神经网络的某些层添加一些辅助的分支分类器来解决训练深度网络中的梯度消失问题。这种辅助的分支分类器能够起到一种判断隐藏层特征图质量好坏的作用。UNet++中也提到使用深度监督的好处是可以返回梯度,进而更新模型参数,最终达到解决梯度消失的问题。
带有深监督的一个8层深度卷积网络结构如下图所示。
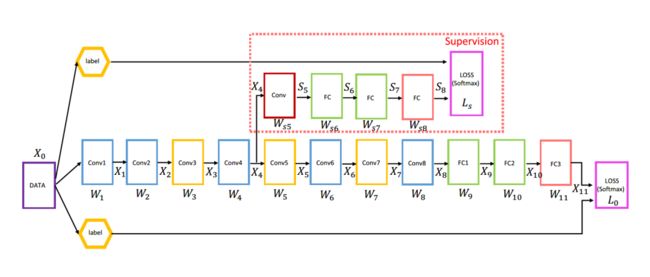
带有深监督的一个13层深度卷积网络结构如下图所示。

其中各个模块含义如下:
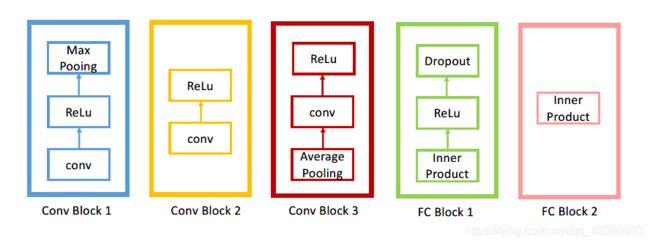
可以看到,图中在第四个卷积块之后添加了一个分支,相当于直接接一个预测头进行预测。与真实标签计算出的Loss作为整个网络训练中LOSS的一部分。带有深监督的网络结构训练过程的损失函数构成如下(以第一个带深监督的8层卷积神经网络为例):
以W和Ws分别表示主干网络和深监督分支的权重,则有:

输出层softmax表示为:

主干网络的损失函数为:
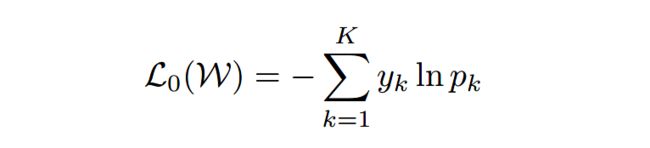
深监督分支的softmax输出表示为:

深监督分支的损失函数为:

因为分支结构中倒数第二层的S8特征图关联到主干网络的卷积权重W1-4。所以,联合损失函数可以表示为:

其中,其中α_t可以表示为随训练epoch_t衰减的一个值,即随着训练epoch的增加,α_t逐渐减小,即深监督分支的损失占比逐渐减少。
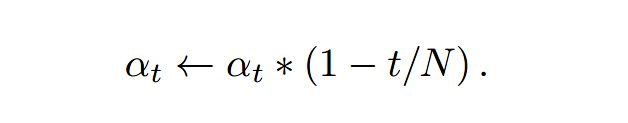
欢迎关注【OAOA】
