redis学习一redis介绍及NIO原理介绍
redis介绍及NIO原理介绍
-
-
- 常识
- redis简介
- redis安装
- epoll介绍
-
常识
磁盘:
1、寻址:ms
2、带宽:G/M(单位时间有多少数据流过去,G或者兆级别)
内存:
1、寻址:ns
2、带宽:非常大
秒>毫秒>微秒>纳秒 磁盘比内存在寻址上慢了10w倍
I/O buffer : 成本问题
磁盘有磁道和扇区,一个扇区512Byte带来一个成本变大:索引
磁盘读数据默认4K 操作系统:无论你读多少,都是最少4k从磁盘拿
随着文件的变大,访问速度变慢,磁盘的I/O成为瓶颈。

如何让它访问变快呢,从而引出数据库,数据库里面有一个data page的概念,每个大小是4k,数据库表
数据就是拆为很多4k的段来存储。4k是保证每次读取的时候正好为一次I/O,如果全是分开的datapage的
话会很慢,因为相当于是走的全量的IO,不会提速。
从而引出索引:
索引也是使用的4k的存储模型,前面的4k是放的一行一行的数据,那么索引对应的4k的 data page
面向行数据的某一列的数据,然后让那一列的数据指向4k中某一行的数据,随着索引的数据量变大
那么data page也会很多。
建关系型数据库表的时候,必须给出schema(这个表的每个列的类型是啥,有多少列)
类型:字节宽度,这样的话就知道表里面每一行数据的宽度
存的时候更倾向于行级存储。就算是某列是空的,也会填入对应大小的数据,便于后面的更新
,就不用换data page了。
数据和索引都是存在硬盘中的,查的时候还需要在内存里面准备一个B+树,B+树的偏移是在内存
**(指的是树干(或者是区间),这样做的目的是索引存数据充分利用磁盘的空间,而树干存在内存则是为了快速找到这个索引对应的datapage,最终目的是减少IO的流量)**里面的,查询的时候如果命中索引了,B+树会走树干将某个列代表的datapage的数据读到内存空间里面,解析完了以后,再将那行记录读取到内存里面。
数据在磁盘和内存体积不一样: 数据在磁盘中没有指针的概念的,是通过索引来的,而索引又占用磁盘空间,数据在内存中则不用去建立一套索引,所以能放更多的数据。(但是内存类型的关系型数据库很贵)
所以引出一个折中的方案:缓存
如果2个基础设施出现了那么则不需要用到缓存机制了,但是没有实现
1、冯诺依曼体系的硬件,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,因此程序指令和数据的宽度相同
2、网络,潜台词就是不稳定,会带来数据不一致双写的问题。
redis简介

redis value 类型的意义:
如果我的客户端想通过一个缓存系统(key value)取回value中的某一个元素,memcached需要返回所有的
数据到client,server 网卡IO,client要有实现的代码去解码,又两个复杂度,如果换成redis,
类型不是很重要,重要的是redis的server中对每种类型都有自己的方法。

计算向数据移动:redis根据value类型来获取计算,并将计算的少量结果返回给client。
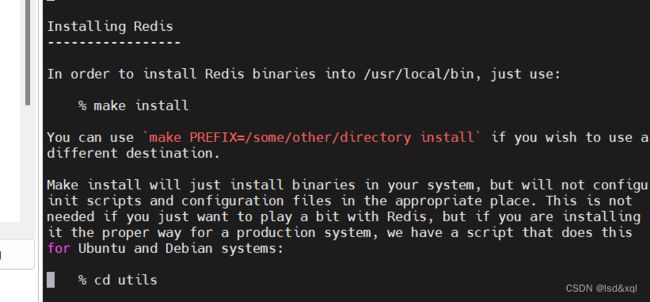
redis安装
先yum install wget
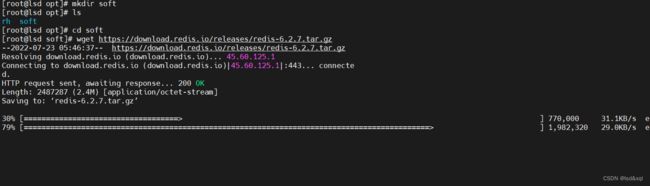
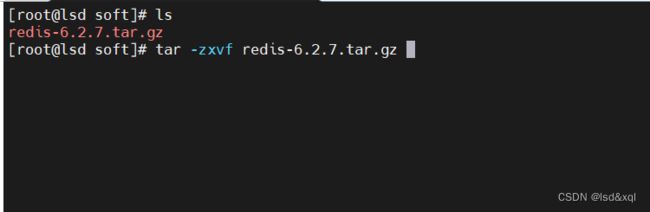
解压后可以看readme.md
编译:

运行:
安装
查看makefile文件


在此目录下执行make 命令,注意这里是需要先装 yum install gcc,
如果redis安装出错可以使用 make disrclean 这个命令去清除一下错误的包
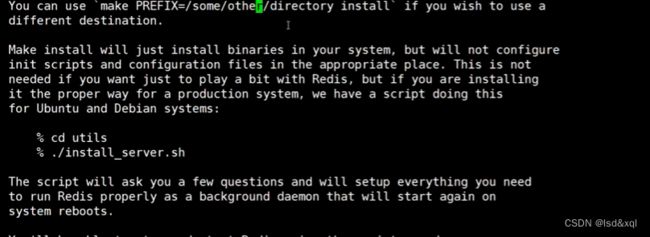
再执行make install,然后进入src目录
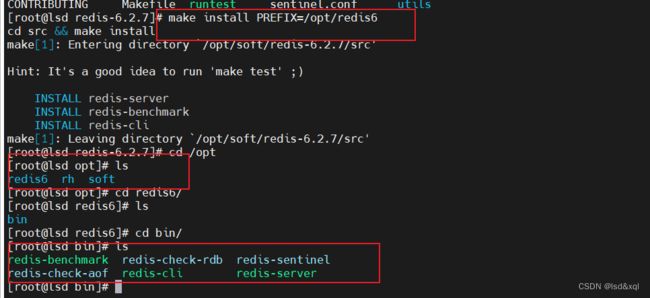
这样的目的是为了把可执行程序放在我特定的目录下
此时要把它安装成服务

发现是unit没有配置,进入unit去执行安装脚本,但是安装之前需要对redis进行环境变量的配置,
vi /etc/profile

配置完成以后可以看到如下环境变量是有了


此时redis的命令就可以在任何地方使用了。
就可以执行redis里utils文件里的install-server脚本了


如上创建的几个文件依次为redis配置文件,redis日志文件redis数据文件(做持久化),redis数据文件,
以及redis执行程序的路径(环境变量对应的配置)【注:创建的时候也可以创建多个实例及副本,再执行这个脚本则ok了】

首先拷贝redis到临时目录中,然后将配置文件放在etc下的某个目录下,并且启动redis(启动的原因是在etc/init.d/redis_6379下写了启动脚本)

这个时候就可以任意目录执行 service redis的命令
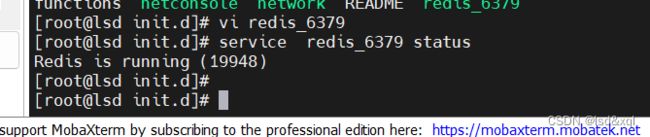
再创建一个实例:

此时看到两个进程对应两个redis的实例:

epoll介绍
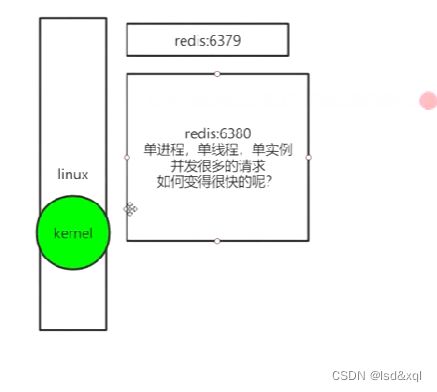
客户端链接通过三次握手先到达linux操作系统的kernel内核,redis进程和内存之间
使用的是epoll(非阻塞多路复用概念)

epoll是啥
加一个插曲(BIO,NIO):
首先计算机有很多客户端连接,然后连接到达内核,每个连接都有一个文件
描述符。

此处如果fd8先读还没返回的话,此处的fd9是阻塞等待的,会有很多资源浪费
此时演变为内核发生变化
fd中0是标准输入,1是标准输出,2是错误输出

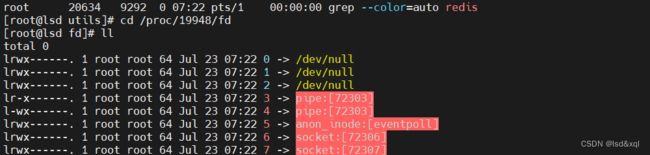
如上0是标准输入,1是标准输出,2是错误输出,且redis调用了pipe和epoll以及socket
再查看soket的说明
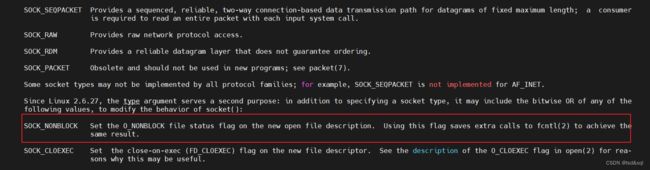
发现有个Non-block的说明
此时引出如下模型:

因为是轮询,然后都由它自己来处理,所以是同步非阻塞时期,但是调用连接的用户数很多的话
就会造成成本大的问题。
为了解决成本问题,再演变为内核增强:
增加系统调用select
执行man 2 select


允许一个程序去监控一个或多个文件描述符,直到一个或多个文件描述符进入ready状态
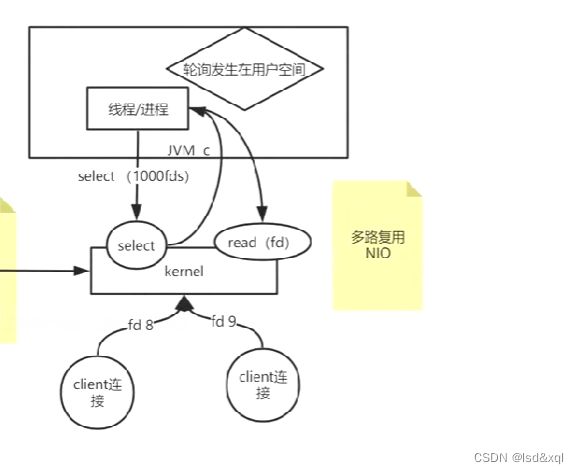
每次调用select查询哪些能用,然后返回再调用read依次执行文件描述符。
问题:
首先fd相关数据在拷贝来拷贝去,无法实现零拷贝,且因为是系统调用,用户进程还要从用户态和内核态切换。
所以演变为下面这种情况:


mmap可以开一个共享空间,是在内核里面的,这个共享空间里面放了一些数据结构,
我的进程就不再存文件描述符了,而是通过epoll将文件描述符写入到共享空间中,


从而引出如下模型:
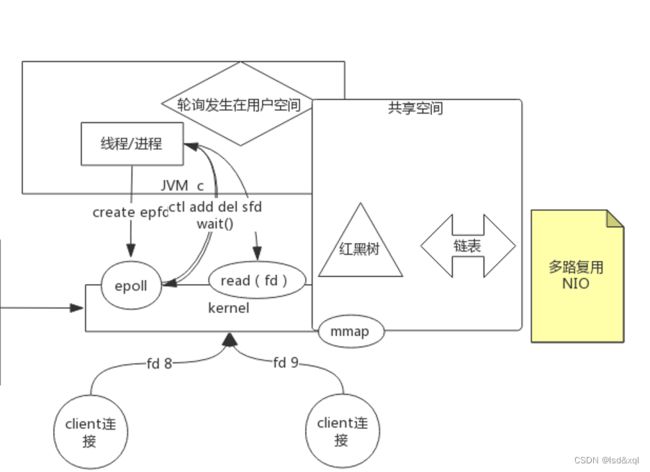
首先用户空间中可以使用create epfd,返回一个epoll的文件描述符,(未来有连接进来了,会将这个连接交给epoll的文件描述符,epoll会准备一个共享空间mmap),mmap里的增删改是内核来完成的(ctl的调用add,del,sfd还有一个wait():是等待内核返回之前注册的事件通知),查询时用户态和内核态都有的。
如果要保证事务的话,对同一个key做crud的话应该让同一个线程发出连接,而不能负载多个。
0拷贝:
输入 man sendfile
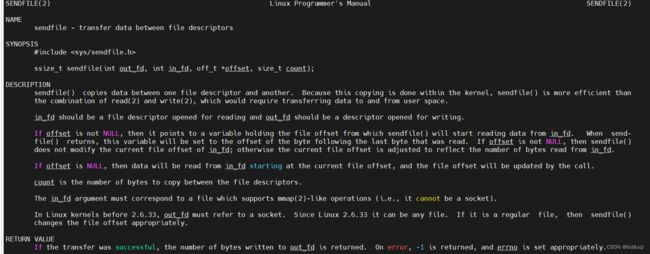
开始时你的数据先到内核,缓冲区,再由read拷贝到用户空间,然后
用户空间再调用write写回来,再发出去。
而0拷贝则是用户空间直接调sendfile,由内核的缓冲区直接发出去,不用发来发去了

sendfile 加上mmap可以组成kafka
