ACL'22 | 使用对比学习增强多标签文本分类中的k近邻机制
每天给你送来NLP技术干货!
来自:南大NLP

01
—
研究动机
多标签文本分类(简称MLTC)是自然语言处理领域中一个十分重要的任务,其旨在从一个给定的标签集合中选取出与文本相关的若干个标签。MLTC可以广泛应用于网页标注,话题识别和情感分析等场景。
迄今为止已有许多工作研究如何解决多标签文本分类这一任务。一些方法提出使用深度神经网络[1,2]以及标签特定的注意力网络[3,4]来增强文本的表示,同时一些其他的方法尝试通过序列化预测[5,6],迭代式推理[7]以及图神经网络[4]等技术来建模标签之间的关联性。
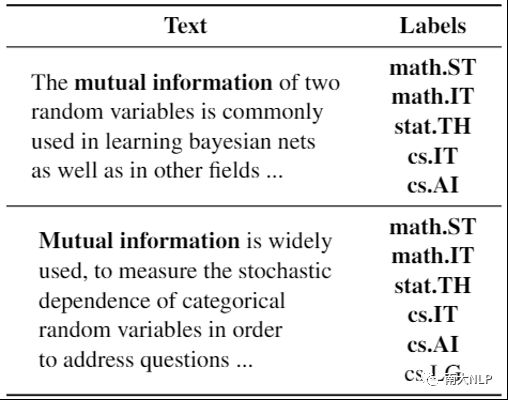
然而,这些方法在推理阶段均忽略了已有训练样本中可以直接获得的丰富知识,而这些知识可以有效帮助模型进行更精确的预测。例如,表1展示了arXiv上的两篇学术论文,从中可以看出他们都是研究“互信息”(Mutual Information)的,与此同时他们所含的标签几乎完全一致,其中包含了统计理论(math.ST,stat.TH),信息论(math.IT,cs.IT)以及人工智能(cs.AI)等标签。因此,当预测一个给定文本的标签时,模型可以通过参考已有相似训练样本的标签来获取这种知识,从而有效的提升自身的性能。
表1:arXiv上的两篇论文及其对应的标签
因此,为了有效的获取和利用已有训练样本中所含的知识,我们提出使用k近邻机制来解决MLTC任务。具体来说,我们的方法首先基于模型提取的文本表示向量检索出多个邻居样本并使用他们的标签对模型的预测结果进行插值。此外,为了使得模型能够意识到k近邻机制并提升检索到邻居样本的质量,我们又提出使用对比学习目标来训练模型。已有的对比学习方法[8,9]都使用的是传统的多类别分类设置,其中两个样本要么是正样本对(positive)要么是负样本对(negative)。然而在MLTC任务中,两个样本之间可能会存在一些共有的标签,并且同时存在一些各样本独有的标签,如何应对这种情况成为了在MLTC任务中使用对比学习的关键。为了建模MLTC任务中这种更加细粒度的样本相关性,我们设计了一种多标签对比学习目标,基于标签的相似度为每个样本对都计算了一个动态的对比学习系数。这样的对比学习目标会鼓励模型对于相似度越高的两个样本输出越为相近的文本表示向量,并且拉远含有完全不同标签的样本对的表示向量。最终在测试阶段,k近邻机制将会检索出含有更多相关标签的样本,从而进一步提升模型的分类性能。我们的方法具有高度的通用性并且可以直接运用在多数已有的MLTC模型上。
02
—
贡献
1. 我们针对MLTC任务提出了一个k近邻机制来显式的利用已有训练样本中所含的知识。
2. 为了减少k近邻机制引入的噪声,我们设计了一个多标签对比学习目标来训练模型。与已有的对比学习算法不同,我们的方法考虑了MLTC任务中样本间更为复杂的相关性并为每个损失项都计算了一个动态的对比学习系数。
3. 我们实施了多项实验,显示出我们的方法可以稳定有效的提升多个MLTC模型的性能,其中包括了目前基于预训练或非预训练模型的SOTA方法。
03
—
解决方案
我们方法的总体算法流程如图1所示,首先使用监督学习+多标签对比学习训练得到一个收敛的MLTC模型(Step1),接着使用该模型对每个训练样本都生成一个文本表示并与相应的标签向量一同存入一个数据仓库中(Step2),最后基于MLTC模型和数据仓库进行k近邻预测(Step3)。
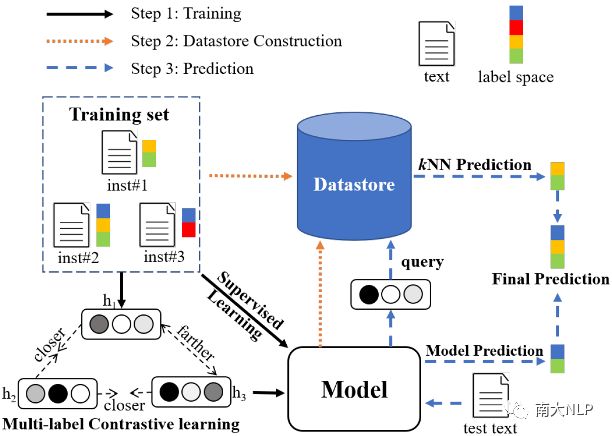
图1:总体算法流程
MLTC任务中的k近邻机制
我们提出的k近邻机制包括两个步骤:构建训练样本的数据仓库(图1的Step2)以及基于这个数据仓库进行k近邻预测(图1的Step3)。
在数据仓库的构建阶段,对于每个训练样本i,我们可以将它的文本输入一个MLTC模型来获得其表示向量,假设设该操作为f(x),则数据仓库D’可以通过对训练集的单次前向传播操作来离线构建,其中xi,yi是每个样本的文本和0/1标签向量:
![]()
![]()
在推理阶段,给定一个输入文本x,模型会输出对该文本的预测标签yMo和表示向量f(x),表示向量可以基于欧几里得距离去查询之前离线构建的数据仓库D’来检索得到k个最近的邻居:
![]()
则可以使用以下的算法进行该样本的k近邻预测:
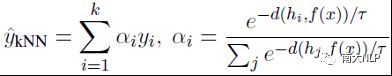
其中d是欧几里得距离函数,τ是k近邻算法中的温度参数来控制分布的平滑性,αi是每个邻居所占的权重。直观上来看,一个邻居距离测试样本越近,则该邻居的标签所占预测结果的权重也越大。最终对于该测试样本的预测结果由k近邻预测和模型预测结果组合而成,其中λ是k近邻预测结果所占的比重参数:
![]()
多标签对比学习
为了建模MLTC任务中更细粒度的关联性,我们设计了一个动态的对比学习系数来构成我们的多标签对比学习目标,即基于样本之间的标签相似性计算出为每个对比学习损失项的系数。考虑一个大小为b的数据批次,则我们方法中对于每个样本对(i,j)的对比学习损失可以由以下公式计算:
![]()
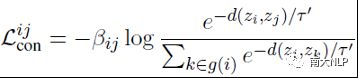
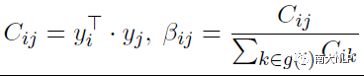
其中τ’是对比学习中温度参数,zi=f(xi)为每个样本的表示向量,样本对之间可以通过标签向量的点积计算出标签相似度Cij,则对比学习的动态系数βij为一个样本批次中Cij归一化后的结果。则整个数据批次的对比学习损失可以由所有样本对的损失相加得到:
![]()
对于一个样本对(i,j)来说,越大的标签相似度将会带来越大的对比学习系数,从而增大该样本对的损失值,最终他们文本表示向量之间的距离就会被优化的相靠近。与此同时,如果一个样本对之间没有共享的标签(即βij=Cij=0),那他们损失项的值也会为0,则它们之间的距离只会出现在其他样本对损失项的分母上,最终他们文本表示之间的距离将会是负的梯度并且被优化的相远离。
04
—
实验
数据集
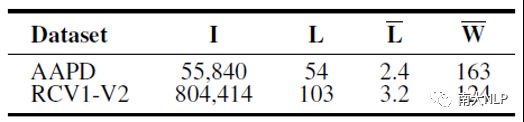
本文的实验是在学术领域的AAPD和新闻领域的RCV1-V2这两个数据集上进行的。数据集的统计信息如表2所示。
表2: 数据集统计信息,后四列分别代表样本个数、标签个数、平均每个样本的标签数和词数
主实验
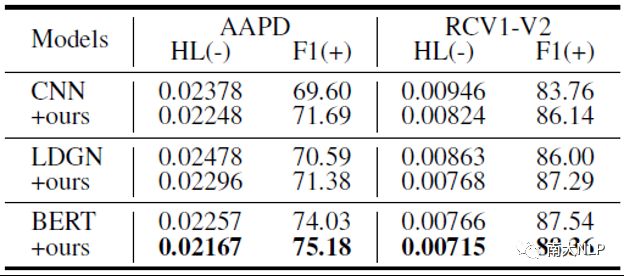
我们在三个常用的MLTC模型上都使用了我们的方法,其中CNN是1维卷积神经网络,LDGN是MLTC任务上基于双向LSTM的SOTA方法,BERT是最著名的大规模预训练语言模型,从实验结果中可以看出我们的方法在所有的模型上都带来了明显的性能提升。
表3:主要实验结果。HL为汉明损失,值越低模型性能越好;F1为精准率和召回率的调和平均,值越高模型性能越好
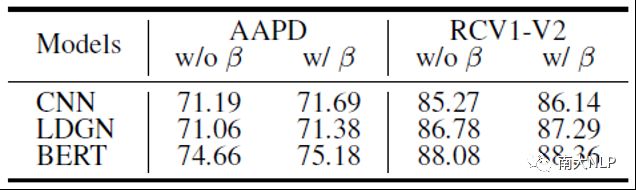
消融实验
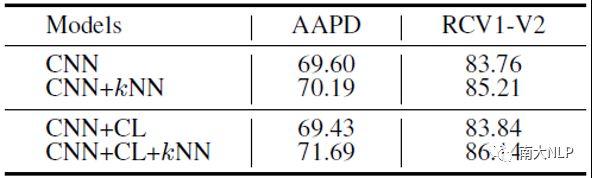
如上文所述,我们的方法由k近邻机制(kNN)和多标签对比学习目标(CL)组成,我们分析了各个模块对于性能的影响。从表4中可以看出,首先,kNN机制可以稳定的提升CNN模型的性能。此外,当使用了我们的对比学习目标训练模型后,虽然CNN模型的性能没有明显的变化,但是kNN机制所带来的性能提升有着较大程度的增长。这也验证了我们的对比学习算法确实有效的增强了k近邻机制。
表4:CNN模型上的消融实验(F1值)
k近邻机制的参数分析
我们分析了k近邻机制中的邻居个数和k近邻预测所占比重这两个参数。从图2中可以看出各模型性能都呈现先增后降的趋势,并且使用k近邻预测的情况下(k>0, λ>0)的性能都优于仅仅使用模型的预测(k=0, λ=0)。这进一步验证了MLTC任务中利用已有训练样本知识的必要性。
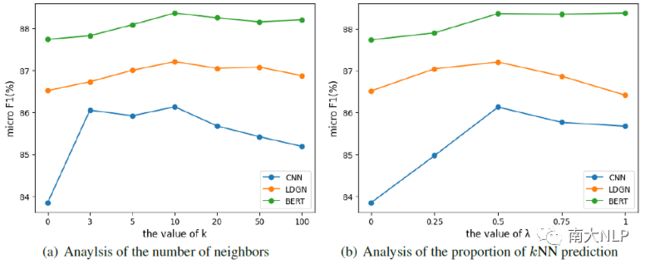
图2:k近邻机制的参数分析
动态对比学习系数的分析
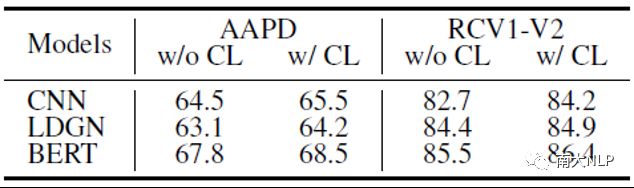
在已有的对比学习方法中,两个样本互为正样本对或负样本对。为了建模MLTC任务中更加复杂的样本相似度,我们提出了动态的对比学习系数β。为了验证β的必要性,我们将现有的对比学习方法简单的应用在了MLTC任务上,也就是将有标签重合的样本对都看做正样本对。从表5中可以看出我们的方法比起现有对比学习的简单应用在所有情况下都有着性能优势,这也验证了MLTC任务中考虑细粒度样本相似度的重要性。
表5:在使用/不使用动态对比学习系数的情况下,我们方法的性能(F1值)
对比学习的影响
为了进一步分析我们提出的对比学习目标的作用,对于每个测试样本我们都统计了其k个最近邻居带来的共享标签占所有标签的比重。如表6所示,在使用我们的对比学习目标训练了模型之后,检索到的邻居含有了更多与测试样本相关的标签。
表6:在使用/不使用对比学习的情况下,k近邻机制检索到的邻居样本带来的与测试样本共享标签的平均比重(%)
在图3中,我们使用了TSNE技术可视化了CNN模型对于一个测试样本以及离它最近的80个邻居训练样本的表示向量。如左图所示,在没有使用对比学习的情况下,距离最近的邻居大多只与测试样本含有1个共享的标签(绿叉)。然而在右图中,当使用了我们的对比学习目标训练模型后,测试样本周围基本都是相似度更高的邻居样本(蓝圆)。以上两个实验验证了我们的对比学习目标确实可以提高k近邻机制中检索到邻居的质量。
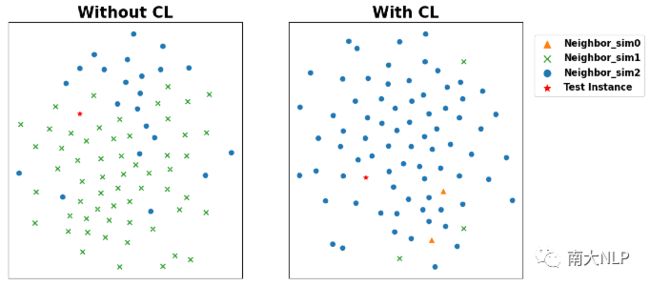
图3:样本表示向量的TSNE可视化。红星代表测试样本,与测试样本相似度不同的邻居样本使用了不同的标记
算法开销分析
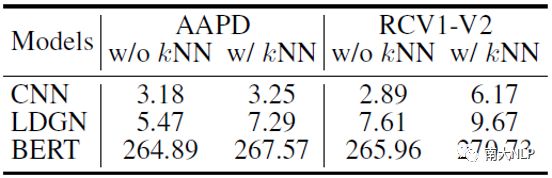
我们算法的开销主要在于k近邻机制,其中对比学习算法的时间和空间开销比起监督学习都可以忽略不计。表7记录了每个数据仓库所占的磁盘空间。使用/不使用k近邻机制的模型推理时间如表8所示,从中可以看出我们方法所带来的额外推理时间均不会超过5毫秒。
表7:各个数据仓库的磁盘占用。
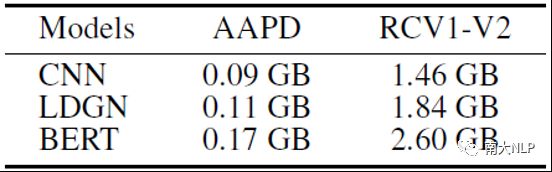
表8:不同模型使用/不使用k近邻机制对于每个文本的推理时间(ms)
05
—
总结
本文提出了基于k近邻机制和对比学习的多标签文本分类算法。我们使用k近邻机制来有效利用已有训练样本的知识,并针对于MLTC任务中样本间更加细粒度的相关性设计了一个多标签对比学习目标。我们通过实验结果证明了我们的方法可以有效提升多个MLTC模型的性能,并通过实验进一步分析了我们方法带来性能提升的原因。
References
[1] Gakuto Kurata, Bing Xiang, and Bowen Zhou. 2016. Improved neural network-based multi-label classification with better initialization leveraging label co-occurrence.
[2] Pengfei Liu, Xipeng Qiu, and Xuanjing Huang. 2016. Recurrent neural network for text classification with multi-task learning.
[3] Lin Xiao, Xin Huang, Boli Chen, and Liping Jing. 2019. Label-specific document representation for multi-label text classification.
[4] Qianwen Ma, Chunyuan Yuan, Wei Zhou, and Songlin Hu. 2021. Label-specific dual graph neural network for multi-label text classification.
[5] Jinseok Nam, Eneldo Loza Mencía, Hyunwoo J. Kim, and Johannes Fürnkranz. 2017. Maximizing subset accuracy with recurrent neural networks in multi-label classification.
[6] Pengcheng Yang, Xu Sun, Wei Li, Shuming Ma, Wei Wu, and Houfeng Wang. 2018. SGM: sequence generation model for multi-label classification.
[7] Ran Wang, Robert Ridley, Xi’ao Su, Weiguang Qu, and Xinyu Dai. 2021. A novel reasoning mechanism for multi-label text classification.
[8] Beliz Gunel, Jingfei Du, Alexis Conneau, and Veselin Stoyanov. 2021. Supervised contrastive learning for pre-trained language model fine-tuning.
[9] Linyang Li, Demin Song, Ruotian Ma, Xipeng Qiu, and Xuanjing Huang. 2021. KNN-BERT: fine-tuning pre-trained models with KNN classifier.
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!