精华推荐 |【深度挖掘RocketMQ底层源码】「生产故障排查系列」深度挖掘RocketMQ底层那些导致消息丢失的汇总盘点透析(TIMEOUT_CLEAN_QUEUE)broker busy
前提概要
在阅读本片文章之前,建议大家先阅读以下这两篇文章:
- 【深度挖掘RocketMQ底层源码】「底层问题分析系列」深度挖掘 RocketMQ 底层那些导致消息丢失的汇总盘点透析([REJECTREQUEST]
- 【深度挖掘RocketMQ底层源码】「底层问题分析系列」深度挖掘 RocketMQ 底层那些导致消息丢失的汇总盘点透析([Broker Busy 和 To Many Request]
相信大家阅读完,基本上对于常见的RocketMQ的问题分析,由了对应的一定的了解和认识。那么接下来我们针对于另外一个较为头疼的以及棘手的问题进行分析,那就是(TIMEOUT_CLEAN_QUEUE)broker busy。这个时候你就会好奇的问,为什么不把所有的问题直接采用一篇文章进行分析和梳理呢?
此问题我在4.8版本左右的时候提交了PR,但是发现了,官方做了开放性的问题,并且被官方给Rejection了,原因是由于性能导致的重试可能会导致更大的集群隐患,造成问题无法及时发现。
为什么单独介绍TIMEOUT_CLEAN_QUEUE
问题引发原因
针对之前的两篇文章中所出现的 [XXX - broker busy] 问题主要是由于Broker在追加消息时持有的锁时间超过了阈值(默认为1s),Broker为了自我保护,会实现快速失败->抛出错误,客户端会选择其他Broker服务器进行重试。
之前方案的解决手段
除非是银行或金融级的业务服务,否则个人建议将transientStorePoolEnable = true,可以有效缓解和避免之前的 【XXX - broker busy】 问题 。
方案运行原理
发送的消息数据,首先会存储在DirectBuffer(堆外内存)中,而且RocketMQ提供了内存锁定的功能,文件顺序读写的性能没有什么问题,因此实现了分流处理,做到在内存使用层面的读写分离,
- 写消息是直接写入DirectBuffer堆外内存
- 读消息直接从PageCache中读
- 定时将堆外内存的消息写入PageCache。
但随之带来的就是可能存在消息丢失,如果对消息非常严谨的话,建议扩容集群,或迁移topic到新的集群。
TIMEOUT_CLEAN_QUEUE]broker busy
了解了上面的错误信息之后,我们接下来需要看一下TIMEOUT_CLEAN_QUEUE]broker busy的问题是什么原因导致的以及如何进行避免!
MQBrokerException:CODE:2 DESC:[TIMEOUT_CLEAN_QUEUE]broker busy,start flow control for a while,period in queue:
235ms,size of queue:875
问题探索分析
当Broker端由于性能问题以及服务端积压的请求太多从而得不到及时处理,会极大的造成客户端消息发送的时间延长。
案例背景
假设RocketMQ写入一条消息需要100ms,此时由于TPS过高引发队列中积压了2000条数据,而消息发送端的默认超时时间为3s,如果按照这样的速度,这些请求在轮到Broker执行写入请求时,客户端已经将这个请求超时了,这样不仅会造成大量的无效处理,还会导致客户端发送超时。
TIMEOUT_CLEAN_QUEUE的由来
RocketMQ为了解决这种由于性能锁带来的频发问题,引入Broker端快速失败机制,即开启一个定时调度线程,每隔10毫秒去检查队列中的第一个排队节点,如果该节点的排队时间已经超过了200ms。就会取消该队列中所有已超过 200ms 的请求,立即向客户端返回失败。
结合客户端重试机制创造数据补偿体系
客户端能尽快进行重试,因为Broker都是集群部署,下次重试可以发送到其他 Broker 上,这样能最大程度保证消息发送在默认 3s 的时间内经过重试机制,能有效避免某一台 Broker 由于瞬时压力大而造成的消息发送不可用,从而实现消息发送的高可用。
源码流程分析
如果要分析问题,我们首先还是需要进行分析和探索以下源码。

上面的方法是定义在org.apache.rocketmq.broker.latency.BrokerFastFailure中,可以看出来该方法的设计目的是Broker端快速失败机制。
Broker端快速失败其原理
我们具体定位到对应的代码,主要是用于比较对应的时间戳的差值是否大于我们的定义的阈值maxWaitTimeMills。
final long behind = System.currentTimeMillis() - rt.getCreateTimestamp();
if (behind >= maxWaitTimeMillsInQueue) {
if (blockingQueue.remove(runnable)) {
rt.setStopRun(true);
rt.returnResponse(RemotingSysResponseCode.SYSTEM_BUSY, String.format("[TIMEOUT_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d", behind, blockingQueue.size()));
}
}
其实也就是说当rt,请求的时间的时间戳已经超过了我们的最大等待处理时间,说明处理速度已经跟不上了,所以导致等待的消息已经超时无法及时进行处理了。我们才开启了此问题的快速失败,为了更好的理解这个问题我们分析一下总体的执行流程。
消息的发送流程
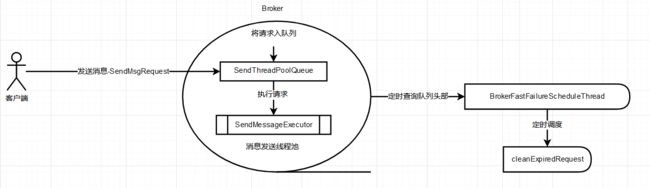
- 消息发送者向Broker发送消息写入请求,Broker端在接收到请求后会首先放入一个队列中(SendThreadPoolQueue),默认容量为10000,如下的源码调用部分
启动线程定时执行cleanExpiredRequest
public void start() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
if (brokerController.getBrokerConfig().isBrokerFastFailureEnable()) {
cleanExpiredRequest();
}
}
}, 1000, 10, TimeUnit.MILLISECONDS);
}
执行cleanExpiredRequest的方法
private void cleanExpiredRequest() {
while (this.brokerController.getMessageStore().isOSPageCacheBusy()) {
try {
if (!this.brokerController.getSendThreadPoolQueue().isEmpty()) {
final Runnable runnable = this.brokerController.getSendThreadPoolQueue().poll(0, TimeUnit.SECONDS);
if (null == runnable) {
break;
}
final RequestTask rt = castRunnable(runnable);
rt.returnResponse(RemotingSysResponseCode.SYSTEM_BUSY, String.format("[PCBUSY_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d", System.currentTimeMillis() - rt.getCreateTimestamp(), this.brokerController.getSendThreadPoolQueue().size()));
} else {
break;
}
} catch (Throwable ignored) {
}
}
cleanExpiredRequestInQueue(this.brokerController.getSendThreadPoolQueue(),
this.brokerController.getBrokerConfig().getWaitTimeMillsInSendQueue());
cleanExpiredRequestInQueue(this.brokerController.getPullThreadPoolQueue(),
this.brokerController.getBrokerConfig().getWaitTimeMillsInPullQueue());
cleanExpiredRequestInQueue(this.brokerController.getHeartbeatThreadPoolQueue(),
this.brokerController.getBrokerConfig().getWaitTimeMillsInHeartbeatQueue());
cleanExpiredRequestInQueue(this.brokerController.getEndTransactionThreadPoolQueue(), this
.brokerController.getBrokerConfig().getWaitTimeMillsInTransactionQueue());
}
- Broker会专门使用一个线程池(SendMessageExecutor)去从队列中获取任务并执行消息写入请求,为了保证消息的顺序处理,该线程池默认线程个数为1。

将线程池注册到对应的processor处理器上面。

问题总结归纳
综上所述,可以看出来在broker还没有发生“严重”的PageCache的broker busy问题,也就是消息追加以及加锁的最大时延没有超过阈值1s。
但如果出现一个超过200ms的追加时间,导致排队中的任务等待时间超过了200ms,则此时会触发broker端的快速失败,让请求快速失败,便于客户端快速重试。但是这种请求并不是实时的,而是每隔10s 检查一遍。
存在的忽略的问题@
从Broker端快速失败机制引入的初衷来看,快速失败后会发起重试,但是实际情况下所出现的ResponseCode是不是进行自己重试的的,为什么?我们来看一下源码。
processSendResponse处理相应信息
从下面的源码中我们可以看出来快速失败TIMEOUT_CLEAN_QUEUE的值进行返回的code为RemotingSysResponseCode . SYSTEM_BUSY。

MQClient消息发送端首先会利用网络通道将请求发送到 Broker,然后接收到请求结果后并调用 processSendResponse 方法对响应结果进行解析,如下图所示:
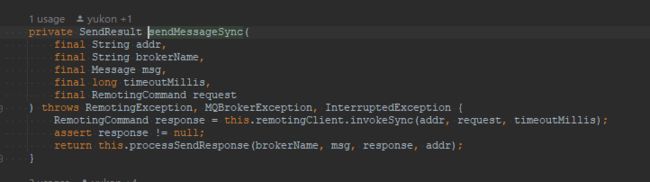
从proccessSendResponse方法中可以得知如果code为SYSTEM_BUSY,该方法会抛出MQBrokerException,响应code为 SYSTEM_BUSY,其错误描述为开头部分的错误信息。
DefaultMQProducerImpl 的 sendDefaultImpl
DefaultMQProducerImpl 的 sendKernelImpl -> sendDefaultImpl方法路径流程。
} catch (MQBrokerException e) {
endTimestamp = System.currentTimeMillis();
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, true);
log.warn(String.format("sendKernelImpl exception, resend at once, InvokeID: %s, RT: %sms, Broker: %s", invokeID, endTimestamp - beginTimestampPrev, mq), e);
log.warn(msg.toString());
exception = e;
if (this.defaultMQProducer.getRetryResponseCodes().contains(e.getResponseCode())) {
continue;
} else {
if (sendResult != null) {
return sendResult;
}
throw e;
}
从这里可以看出RocketMQ消息发送高可用设计一个非常关键的点,重试机制,其实现是在 for 循环中 使用 try catch 将 sendKernelImpl 方法包裹,就可以保证该方法抛出异常后能继续重试。
重试retryResponseCode的集合
public class DefaultMQProducer extends ClientConfig implements MQProducer {
/**
* Wrapping internal implementations for virtually all methods presented in this class.
*/
protected final transient DefaultMQProducerImpl defaultMQProducerImpl;
private final InternalLogger log = ClientLogger.getLog();
private final Set<Integer> retryResponseCodes = new CopyOnWriteArraySet<Integer>(Arrays.asList(
ResponseCode.TOPIC_NOT_EXIST,
ResponseCode.SERVICE_NOT_AVAILABLE,
ResponseCode.SYSTEM_ERROR,
ResponseCode.NO_PERMISSION,
ResponseCode.NO_BUYER_ID,
ResponseCode.NOT_IN_CURRENT_UNIT
));
从上文可知,如果SYSTEM_BUSY会抛出 MQBrokerException,但发现只有上述几个错误码才会重试,因为如果不是上述错误码,会继续向外抛出异常,此时 for 循环会被中断,即不会重试,这是 RocketMQ 的一个BUG。
解决方案
- 针对于DefaultMQProducer添加对于Broker Busy的问题的兼容进行客户端重试功能。
/**
* Add response code for retrying.
*
* @param responseCode response code, {@link ResponseCode}
*/
public void addRetryResponseCode(int responseCode) {
this.retryResponseCodes.add(responseCode);
}
- 如果是低版本的客户端并且还不行升级版本解决方案就是增加
waitTimeMillsInSendQueue的值,该值默认为 200ms,例如将其设置为1000s等等,适当提高该值能有效的缓解。
最后分析
对于RocketMQ的5.0版本希望大家可以多多尝试以下,解决了低版本的很多bug,小编目前已经在探索源码的路上,希望后面可以继续参与到RocketMQ的PR过程中。