【Mo 人工智能技术博客】CNN实现表情识别
作者:魏祖昌
一、背景介绍
2020年1月29日,教育部有关负责人在接受采访时表示,防控新型冠状病毒肺炎是当前头等重要的大事,各级教育部门正按教育部和当地党委政府统一部署要求,全力防控,坚决防止疫情在学校蔓延,延期开学是其中的一项重要举措。与此同时,各地教育部门也为服务保障防控疫情期间中小学校“停课不停教、不停学”做了大量工作。线上教学随即由此出现了。
但是随着网络教学的升入进行,教师不能通过像教室一样能及时的知道学生的学习状态,学生也不会像在教室一样严肃对待学习。既然是线上教学,我们就可以借助一些我们深度学习技术来帮助老师观察学生表情以此来解决这个问题。本文以CNN入手,实现了一个对人脸表情的识别的深度模型。
二、数据集
Fer2013人脸表情数据集由35886张人脸表情图片组成,其中,测试图(Training)28708张,公共验证图(PublicTest)和私有验证图(PrivateTest)各3589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,分别对应于数字标签0-6,具体表情对应的标签和中英文如下:0 anger 生气; 1 disgust 厌恶; 2 fear 恐惧; 3 happy 开心; 4 sad 伤心;5 surprised 惊讶; 6 normal 中性。
同时,我们需要对图片数据进行数据翻转、数据旋转、图像缩放、图像剪裁、图像平移、添加噪声。看到这里有些人就会好奇了,我们不是已经有数据了吗?为什么还要这样操作呢?接下来我就来在介绍一下为什么要这么操作。
其实这种操作叫做数据增强。在深度学习中,一般要求样本的数量要充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强。但是实际中,样本数量不足或者样本质量不够好,这就要对样本做数据增强,来提高样本质量。关于数据增强的作用总结如下:
- 增加训练的数据量,提高模型的泛化能力
- 增加噪声数据,提升模型的鲁棒性

图一:数据增强中的操作
三、模型结构
我们先读取Fer2013的数据,由于他是一个由灰度图像组成的csv文件,所以和常规训练数据读取起来有些区别。首先我们需要读取csv文件:
def read_data_np(path):
with open(path) as f:
content = f.readlines()
lines = np.array(content)
num_of_instances = lines.size
print("number of instances: ", num_of_instances)
print("instance length: ", len(lines[1].split(",")[1].split(" ")))
return lines, num_of_instances
在读取完文件之后,我们需要对读取数据进行一定处理,把48*48图片灰度进行Reshape,并且还需要对总的数据进行数据划分,划分出x_train, y_train, x_test, y_test四个部分:
def reshape_dataset(paths, num_classes):
x_train, y_train, x_test, y_test = [], [], [], []
lines, num_of_instances = read_data_np(paths)
# ------------------------------
# transfer train and test set data
for i in range(1, num_of_instances):
try:
emotion, img, usage = lines[i].split(",")
val = img.split(" ")
pixels = np.array(val, 'float32')
emotion = keras.utils.to_categorical(emotion, num_classes)
if 'Training' in usage:
y_train.append(emotion)
x_train.append(pixels)
elif 'PublicTest' in usage:
y_test.append(emotion)
x_test.append(pixels)
except:
print("", end="")
# ------------------------------
# data transformation for train and test sets
x_train = np.array(x_train, 'float32')
y_train = np.array(y_train, 'float32')
x_test = np.array(x_test, 'float32')
y_test = np.array(y_test, 'float32')
x_train /= 255 # normalize inputs between [0, 1]
x_test /= 255
x_train = x_train.reshape(x_train.shape[0], 48, 48, 1)
x_train = x_train.astype('float32')
x_test = x_test.reshape(x_test.shape[0], 48, 48, 1)
x_test = x_test.astype('float32')
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = y_train.reshape(y_train.shape[0], 7)
y_train = y_train.astype('int16')
y_test = y_test.reshape(y_test.shape[0], 7)
y_test = y_test.astype('int16')
print('--------x_train.shape:', x_train.shape)
print('--------y_train.shape:', y_train.shape)
print(len(x_train), 'train x size')
print(len(y_train), 'train y size')
print(len(x_test), 'test x size')
print(len(y_test), 'test y size')
return x_train, y_train, x_test, y_test
模型主要使用三层卷积层,两层全连接层,最后通过一个softmax输出每个类别的可能性。主要模型代码如下:
def build_model(num_classes):
# construct CNN structure
model = Sequential()
# 1st convolution layer
model.add(Conv2D(64, (5, 5), activation='relu', input_shape=(48, 48, 1)))
model.add(MaxPooling2D(pool_size=(5, 5), strides=(2, 2)))
# 2nd convolution layer
model.add(Conv2D(64, (3, 3), activation='relu'))
# model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(AveragePooling2D(pool_size=(3, 3), strides=(2, 2)))
# 3rd convolution layer
model.add(Conv2D(128, (3, 3), activation='relu'))
# model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(AveragePooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
# fully connected neural networks
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
return model
四、训练结果
实验设置steps_per_epoch=256,epoch=5,对数据进行了增强,实验结果如下图:
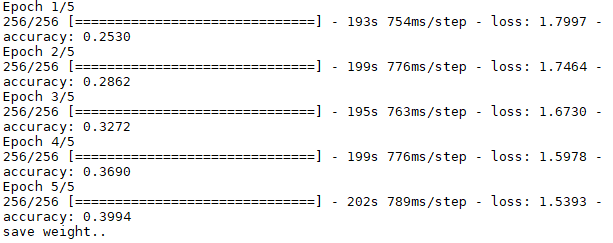
图二:数据增强的训练结果
对数据没有进行增强,实验结果如下图:
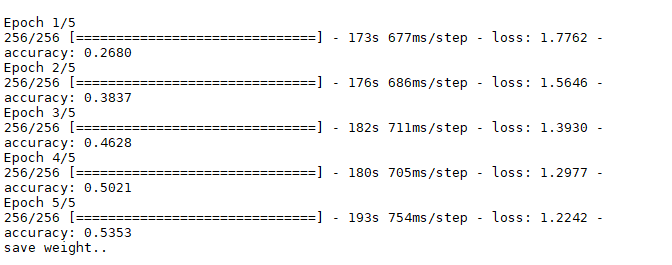
图三:没有数据增强的训练结果
我们可以我们明显看到,确实是没有增强准确率更高,也确实是如此,我们增强了模型的泛化能力能力,必然会降低模型训练时的准确率,但是我们可以通过以下的几张额外的图片,来观察两种模型的区别。效果如下(左边是数据增强,右边是数据没有增强):
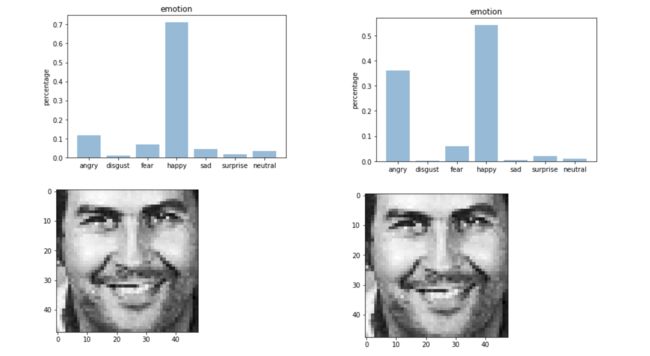
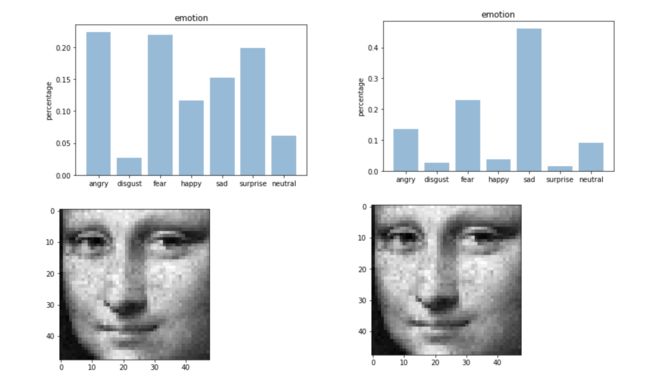
图四:效果对比
我们可以通过上图实验结果发现,开心的图中,用数据增强数据判断出来的会比没有用判断出来的更加准确,同时用数据增强的模型判断蒙娜丽莎时,更符合蒙娜丽莎的神秘感的常识。
五、总结
本文中,我们只是简单的使用的CNN网络,虽然准确率没有那么高。但是我们可以利用我们现有的技术来助力线上教学,帮助老师来分析学生的听课状态。同时学生如果知道有一双无形的眼睛盯着他,可能学生也会以在课堂上课的态度来对待网上教学,提高网上教学的授课效率。
项目地址:https://momodel.cn/workspace/5e6752dd8efa61a905fef694?type=app (推荐在电脑端使用Google Chrome浏览器进行打开)
引用
- 深度学习:为什么要进行数据增强?
- 参考代码:https://github.com/naughtybabyfirst/facial
##关于我们
Mo(网址:https://momodel.cn) 是一个支持 Python的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
近期 Mo 也在持续进行机器学习相关的入门课程和论文分享活动,欢迎大家关注我们的公众号 MomodelAI 获取最新资讯!
同时,欢迎使用 「Mo AI编程」 微信小程序
以及登录官网,了解更多信息:Mo 平台
Mo,发现意外,创造可能