MySQL多表查询
多表查询
含义
显示的数据不仅仅来自一张表中,可能是来自两张甚至更多。
分类
- 连接条件分
- 等值连接
- 非等值连接
- 按其他连接方法分
- 外连接
- 内连接
笛卡尔积
含义
显示的记录数量是各个查询表中记录数的乘积
产生原因
多表连接查询中缺少有效的关联的条件
处理方案
多表连接查询中添加有效的关联的条件,如果M张表查询至少需要M-1个有效的关联条件
案例
-- select *from emp; -- 14
-- select *from dept; -- 4
-- 笛卡尔积
-- 产生条件
-- 在多表关联查询中
-- 缺少有效的关联条件
-- 处理方案
-- 添加有效的关联条件 M张表关联查询,有效条件至少M-1个
select *from emp,dept
等值连接
含义
有效关联添加是等值比较的
案例
-- 查询员工信息、部门名称、工作地点
select emp.*,dept.dname,dept.loc from emp , dept where emp.deptno = dept.deptno;
-- 给表添加别名 [效果和上面一样]
select e.*,d.dname,d.loc from emp e,dept d where e.deptno = d.deptno;
-- 现在只想查询 工作地点在NEW YORK的 员工编号,姓名,部门编号,工作地点
select e.empno,e.ename ,d.dname,d.loc from emp e,dept d where e.deptno = d.deptno and d.loc = 'NEW YORK'
-- 写一个查询,显示所有工作在CHICAGO并且奖金不为空的 员工姓名,工作地点,奖金
select e.comm,e.ename,d.loc from emp e,dept d where e.deptno = d.deptno and d.loc = 'CHICAGO' and e.comm is not null;
--写一个查询,显示所有姓名中含有A字符的员工姓名,工作地点。
select e.ename,d.loc from emp e,dept d where e.deptno = d.deptno and e.ename like '%A%'
-- 查询顾客购买的商品id
SELECT c.name,o.itemid FROM customer c, order o,item i WHERE c.custid = o.custid and o.ordid = i.ordid;
非等值连接
含义
有效关联添加不是使用等值比较的
案例一
select e.*,g.grade from emp e,salgrade g where e.sal BETWEEN g.losal and g.hisal;
select e.*,g.grade from emp e,salgrade g where e.sal >=g.losal and e.sal <= g.hisal;
自身连接
相同表之间做关联查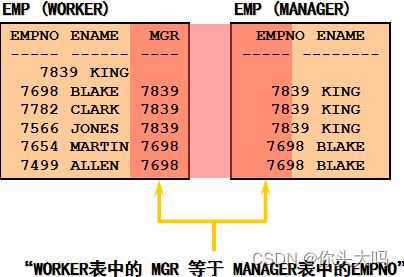
-- 查询员工姓名,员工编号,以及他们的经理姓名,经理编号。
SELECT
e.ename,
e.empno,
m.ename AS managerName,
m.empno AS managerNo
FROM
emp e,
emp m
WHERE
e.mgr = m.empno
-- 查询所有工作在NEW YORK和CHICAGO的员工姓名,员工编号,以及他们的经理姓名,经理编号。
SELECT
e.ename,
e.empno,
m.ename AS managerName,
m.empno AS managerNo
FROM
emp e,
emp m,
dept d
WHERE
e.mgr = m.empno
AND e.deptno = d.deptno
AND d.loc = 'NEW YORK'
OR d.loc = 'CHICAGO'
ANSI标准 连接语句
所有关系型数据都要支持的语法
-
交叉连接 【了解】
select *from emp cross JOIN dept -
自然连接 【了解】
select *from emp NATURAL join dept -
using连接 【了解】
select *from emp join dept using(deptno) -
inner join … on 子句
-
left join … on 子句
-
right join … on 子句
inner join
内连接
语法
select ... from 表1 [inner] join 表2 on 有效关联条件 [where 其他条件]
好处
-
将有效关联条件和其他条件分开
-
提高可读性
案例
-- select *from emp e,dept d where e.deptno = d.deptno and d.loc = 'DALLAS';
select *from emp e inner join dept d on e.deptno = d.deptno where d.loc = 'DALLAS';
select *from emp e join dept d on e.deptno = d.deptno where d.loc = 'DALLAS';
left join
左外连接(不管左边有没有和右边匹配都要显示)
语法
select ... from 表1 left [outer] join 表2 on 有效关联条件 [where 其他条件]
案例
-- 列出员工的名称和部门编号
select e.ename from emp e left join dept d on e.deptno = d.deptno
-- 上面的案例发现有一个不属于任何部门的员工没有显示出来,所以可以使用左外连接,不管左边是否满足要求都要显示
-- 列出员工姓名和部门名称,如果员工不属于任何也要显示
select e.ename from emp e left outer join dept d on e.deptno = d.deptno
select e.ename from emp e left join dept d on e.deptno = d.deptno
right join
右外连接(不管右边有没有和左边匹配都要显示)
语法
select ... from 表1 left [outer] join 表2 on 有效关联条件 [where 其他条件]
案例
-- 列出员工的名称和部门编号
select e.ename,d.deptno from emp e join dept d on e.deptno = d.deptno
-- 上面的案例发现有一个id为40的部门编号没有显示出来,所以可以使用右外连接,不管右边是否满足要求都要显示,
select e.ename,d.deptno from emp e right outer join dept d on e.deptno = d.deptno
select e.ename,d.deptno from emp e right join dept d on e.deptno = d.deptno
分组函数
分数函数也叫多行参数,是将多行作为参数
常见
-
min
MIN([DISTINCT|ALL] column|expression)
-
max
MAX([DISTINCT|ALL] column|expression)
-
avg
AVG([DISTINCT|ALL] column|expression)
-
sum
SUM([DISTINCT|ALL] column|expression)
-
count
COUNT ( * | { [DISTINCT|ALL] column})
语法
SELECT [column,] group_function(column)
FROM table
[WHERE condition]
[GROUP BY column]
[HAVING group_function(column)expression
[ORDER BY column| group_function(column)expression];
分组函数位置:
select
having
order by
注意点
- 除了count(*)之外,其他的分组函数都会忽略null值
案例
-- 查看最早入职之间
select min(hiredate) from emp;
-- 查看最晚入职时间
SELECT max(hiredate) from emp;
-- 查看最少的奖金
select min(comm) from emp;
-- 查看最高的奖金
select max(comm) from emp;
-- 为什么有些记录是null?因为null参数算术运算结果都是null
select sal + comm from emp;
-- 计算所有员工的月薪综合,计算所有员工的奖金综合
select sum(sal),sum(comm) from emp;
-- 计算员工的工资平均值,计算员工的奖金平均值
select avg(sal),avg(ifnull(comm,0)) from emp;
-- count( * | [DISTINCT] 列名 )
-- 计算员工数量
select count(*) from emp;
-- 计算员工数量,建议使用该方案
select count(empno) from emp;
-- 计算岗位种类数量
select count(DISTINCT job) from emp;
-- 计算有员工的部门数量
select count(distinct deptno) from emp;
思考
请问如下结构多少?
select count(comm) from emp;
请问是否报错?
select count(DISTINCT deptno) from emp;
group by 语句
含义
按照指定条件将数据分组
示意图

语法
SELECT deptno, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression] deptno
[ORDER BY column];
注意点
使用了group by 之后,select 后面不可以写可以写分组函数、分组的依据列
案例
-- 查询每个部门的编号,平均工资
select deptno,avg(sal) from emp group by deptno;
select avg(sal) from emp group by deptno;
-- 查询每个部门每个岗位的工资总和。
select concat('部门',deptno,'的岗位',job,'的工资总和是',sum(sal)) from emp group by deptno,job order by deptno asc;
having
含义
对分组后进一步的过滤
示意图

语法
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];
案例
-- 询每个部门最高工资大于3000的部门编号,最高工资
select max(sal),deptno from emp GROUP BY deptno HAVING max(sal) >= 3000;
-- 询每个部门最高工资大于3000的部门编号,最高工资
select max(sal) as maxSal ,deptno from emp GROUP BY deptno HAVING maxSal >= 3000;
-- 询每个部门最高工资大于3000的部门编号,最高工资,并且按照最高工资升序
select max(sal) as maxSal ,deptno from emp GROUP BY deptno HAVING maxSal >= 3000 order by maxSal;
执行顺序
- from
- where
- group by
- select字段
- having
- order by
- limit
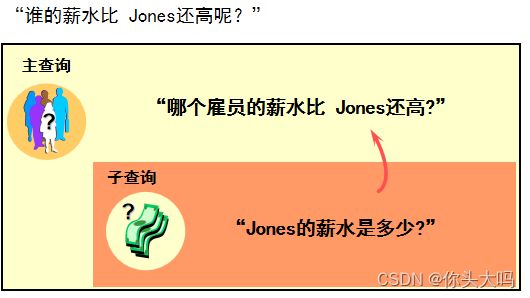
子查询
含义
查询语句中的查询语句,也称从查询、内部查询
示意图
规范
- 用(子查询)包裹起来
- 放到比较运算符的右边
- 使用适当的比较运算符
- 单行运算符:>、=、>=、<、<>、<=
- 多行运算符: IN、ANY、ALL
使用地方
- where
- from
- having
案例一
在where中使用子查询
-- 查询出工资 比JONES的还要高 的其他雇员
select *from emp where sal >= (select sal from emp where ename = 'JONES');
-- 显示 和雇员7369从事相同工作 并且工资大于雇员7876的 雇员的姓名和工作。
SELECT
ename,
job
FROM
emp
WHERE
job = ( SELECT job FROM emp WHERE empno = 7369 )
AND sal > ( SELECT sal FROM emp WHERE empno = 7876 );
-- 查询 工资最低的 员工姓名,岗位及工资
select ename,job,sal from emp where sal = (select min(sal) from emp);
-- 查询部门最低工资比20部门最低工资高的部门编号及最低工资
SELECT
deptno,
min( sal )
FROM
emp
GROUP BY
deptno
HAVING
min( sal ) > ( SELECT min( sal ) FROM emp WHERE deptno = 20 );
-- 查询 入职日期最早的 员工姓名,入职日期
select ename,hiredate from emp where hiredate = (select min(hiredate) from emp);
-- 查询 工资比SMITH工资高并且工作地点在CHICAGO的 员工姓名,工资,部门名称
SELECT
e.ename,
e.sal,
d.dname
FROM
emp e
JOIN dept d ON e.deptno = d.deptno
WHERE
e.sal > ( SELECT sal FROM emp WHERE ename = 'SMITH' )
AND d.loc = 'CHICAGO';
-- 查询 入职日期比 20部门入职日期 最早的员工还要早的 员工姓名,入职日期
select ename,hiredate from emp where hiredate > (select min(hiredate) from emp where deptno = 20)
案例二
在from和having使用子查询
-- 查询部门人数大于所有 部门平均人数 的的部门编号,部门名称,部门人数
-- 思路
-- 查询出每个部门的人数,语句如下
select count(e.empno) as totalCount,e.deptno from emp e where e.deptno is not null group by e.deptno
-- 计算每个部门的平均人数,语句如下
select avg(t.totalCount) from (
select count(e.empno) as totalCount,e.deptno from emp e where e.deptno is not null group by e.deptno
) t
select count(e.empno) as yy ,e.deptno from emp e where e.deptno is not null group by e.deptno having yy >
(select avg(t.totalCount) from (
select count(e.empno) as totalCount,e.deptno from emp e where e.deptno is not null group by e.deptno
) t);
案例三
在from中使用子查询
-- 查找员工名字、薪水、部门编号
select e.ename,e.sal,e.deptno from emp e;
-- 查找每个部门的平均工资、部门编号
select avg(e.sal) xx,e.deptno from emp e group by e.deptno;
-- 查询 比自己部门平均工资高的 员工姓名,工资,部门编号 以及部门平均工资
-- 思路
-- 查询员工姓名,工资,部门编号
-- 查找每个部门的平均工资、部门编号,并当做一张表,给个别名比如:t
-- 和t表做关联查询即可
select e.ename,e.sal,e.deptno,t.xx from emp e,(select avg(e.sal) xx,e.deptno from emp e group by e.deptno) t
where e.deptno = t.deptno and e.sal > t.xx